워드 임베딩(Word Embedding)
- 텍스트 데이터를 수치형 데이터로 변환하는 기법으로, 자연어 처리(NLP) 모델에서 핵심적으로 사용된다.
- 워드 임베딩은 어휘의 단어나 구문을 고정 크기의 실수 벡터로 매핑하며, 이를 위해 언어 모델링 및 특징 학습 기술을 활용한다.
- 단어와 구문을 임베딩 형태로 표현하면 구문 분석, 감정 분석 등 다양한 NLP 작업에서 성능이 크게 향상되는 것으로 알려져 있다.
원-핫 인코딩 (One-Hot Encoding)
-
설명:
-
단어 집합(vocabulary)의 각 단어를 고유한 인덱스로 매핑한 뒤, 이를 기반으로 벡터를 생성한다. 이 벡터는 해당 단어의 위치에만 1을 표시하고, 나머지 위치는 모두 0으로 채운다.
-
복잡한 아이디어나 언어적 의미를 반영하려는 목적이 아니라, 컴퓨터가 텍스트 데이터를 수치적으로 표현하고 처리할 수 있도록 만드는 단순한 방식에서 시작했다.
-
vocabulary = {apple, banana, cherry}
'apple' → [1, 0, 0]
'banana' → [0, 1, 0]
'cherry' → [0, 0, 1]-
장점 :
- 단순하고 직관적이며, 구현이 쉽다.
- 각 단어가 독립적으로 표현되기 때문에 표현 방식이 직관적이고 해석이 용이하다.
-
단점 :
- 단어 간 유사성이나 관계를 전혀 포함하지 못한다.
- 희소 벡터(Sparse Vector)로 인해 메모리 사용량이 증가하고 계산 효율이 낮아진다.
- 단어 집합이 커질수록 차원이 증가하여 계산 비용이 급격히 증가한다.
-
활용 분야 :
- 소규모 데이터나 기본적인 텍스트 분류 작업
- 단어 임베딩(예: Word2Vec, GloVe)을 학습하기 전, 단어를 수치화하는 기본 단계로 활용
카운트 기반 임베딩 (Count-Based Embedding)
1. Co-occurrence Matrix (공기 발생 행렬)
-
단어 집합(vocabulary) 내 단어들이 문맥(Context)에서 함께 등장하는 횟수를 기반으로 행렬을 생성하는 워드 임베딩 방식이다.
-
각 행과 열은 단어 집합의 단어를 나타내며, 셀의 값은 특정 윈도우 크기(예: 주변 n개의 단어) 내에서 두 단어가 함께 등장한 횟수로 계산된다.
-
단어를 독립적인 개체로 보지 않고, 문맥(Context) 속에서 단어의 의미를 빈도 기반 상관관계로 정의한 초기 시도의 결과물이다.
-
예문: "I like deep learning and deep learning likes me"
- 단어 집합(vocabulary): {I, like, deep, learning, and, likes, me}
- 윈도우 크기: 1 (주변 단어 1개까지 고려)
I like deep learning and likes me I 0 1 0 0 0 0 0 like 1 0 1 0 0 0 0 deep 0 1 0 2 1 0 0 learning 0 0 2 0 1 0 0 and 0 0 1 1 0 1 0 likes 0 0 0 0 1 0 1 me 0 0 0 0 0 1 0
-
장점:
-
1. 단어 간 통계적 연관성: 단어가 함께 등장하는 빈도를 기반으로 의미를 유추할 수 있음.
-
2. 전역적 정보 반영: 말뭉치 전체에서 계산되므로 문맥의 전반적인 정보를 포함.
-
3. 해석 가능성: 행렬 값을 통해 단어 간 관계를 직관적으로 파악 가능.
-
-
단점:
-
1. 고차원 문제: 단어 집합이 커질수록 행렬 크기가 매우 커져 메모리 사용량과 계산 복잡도가 급격히 증가.
-
2. 희소 행렬(Sparse Matrix): 대부분의 값이 0이므로 비효율적.
-
3. 문맥 한계: 단순 공기 발생 빈도만 반영되며, 단어 순서와 세밀한 문맥 정보를 고려하지 못함.
-
4. 차원 축소 필요: 행렬의 크기를 줄이기 위해 추가적인 차원 축소(예: SVD)가 필요하며, 이 과정에서 계산 비용이 증가.
-
-
활용 분야:
- 말뭉치 내 단어 간의 연관성을 파악(키워드 추출, 단어 간 유사도 분석)
- 차원 축소를 통한 임베딩 생성, LSA(Latent Semantic Analysis)
- 주제 모델링(Topic Modeling)의 사전 처리.
2. TF-IDF (Term Frequency-Inverse Document Frequency)
- "중요한 단어는 반복된다"는 명제를 기반으로 단어의 중요도를 정량적으로 측정하지만,
"반복되는 단어는 중요하다"는 항상 성립하지 않음을 반영한 임베딩 기법이다.
-
TF-IDF는 문서 내 단어의 빈도와 전체 문서에서 해당 단어의 중요도를 동시에 고려하여 단어의 가중치를 계산하는 기법이다.
-
TF(Term Frequency)는 단어가 특정 문서에서 얼마나 자주 등장하는지를 나타내며,IDF(Inverse Document Frequency)는 단어가 전체 문서에서 얼마나 희귀한지를 나타낸다.
-
예시:
-
문서 1: "I like machine learning"
-
문서 2: "I like deep learning"
-
문서 3: "I enjoy programming"
TF 계산:
-
TF("I", 문서 1)= 1/4 = 0.25 -
TF("machine", 문서 1)= 1/4 = 0.25IDF 계산:
-
IDF("I")= log(3 / 3) = 0 (모든 문서에 등장) -
IDF("machine")= log(3 / 1) = log(3)TF-IDF:
-
TF-IDF("machine", 문서 1)= 0.25 * log(1) -
TF-IDF("machine", 문서 1)= 0.25 * log(3)단어 집합 (Vocabulary) :{I, like, machine, learning, deep, enjoy, programming}
단어 문서 1: I like machine learning문서 2: I like deep learning문서 3: I enjoy programmingI 0.25 0.25 0.25 like 0.25 0.25 0 machine 0.25 0 0 learning 0.25 0.25 0 deep 0 0.25 0 enjoy 0 0 0.5 programming 0 0 0.5
-
- 장점:
- 단어 중요도 반영: 빈번히 등장하는 단어와 드물게 등장하는 단어를 구분하여, 의미 있는 단어에 높은 가중치를 부여.
- 간결하고 효과적: 계산이 비교적 간단하며, 다양한 NLP 작업에 바로 적용 가능.
- 노이즈 감소: 문서에 자주 등장하는 불용어(stop words)의 영향을 줄임.
- 단점:
- 문맥 정보 부족: 단어의 위치나 순서를 고려하지 않아, 문맥적 의미를 반영하지 못함.
- 고정된 값: TF-IDF는 특정 말뭉치에 고정된 값으로 계산되므로, 새로운 문서나 단어가 추가되면 재계산이 필요.
- 단순 빈도 기반: 단어 간의 관계나 상호작용을 고려하지 않음.
- 고차원 문제
- 희소 행렬(Sparse Matrix):
- 활용 분야:
- 문서 검색 및 정보 검색 엔진(예: 검색 랭킹)
- 텍스트 분류 및 군집화
- 키워드 추출
예측 기반 임베딩 (Prediction-Based Embedding)
1. CBOW (Continuous Bag of Words)
- 문장에서 특정 단어의 의미는 주변 단어(Context words)들로부터 결정된다는 아이디어를 따름.
- 한 문장에서 주어진 주변 단어들의 집합이 있을 때, 그 문맥에서 가장 적절한 단어가 무엇인지 예측하는 방식.
- 설명:
- CBOW는 Word2Vec 모델의 한 종류로, 주변 단어(Context)를 입력으로 받아 중심 단어(Target)를 예측하는 방식이다.
- 단어를 고정된 크기()의 실수 벡터로 매핑하는 분산 표현(distributed representation) 기법 중 하나로, NLP에서 널리 사용된다.
- 입력이 주변 단어의 집합이므로, 단어 순서는 무시되며 문맥의 의미를 반영한 임베딩을 생성한다.
- 예시:
- 예문: "The fat cat sat on the mat"
- 윈도우 크기: 2 (주변 단어 2개를 고려)
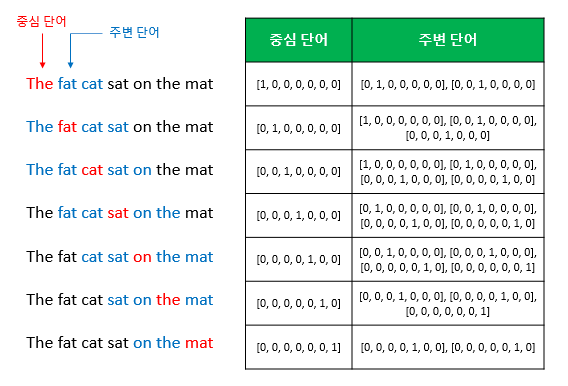
-
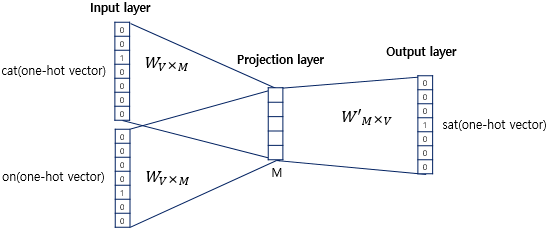
입력/출력:
- 윈도우 크기 내의 주변 단어들을 원-핫 벡터(One-Hot Vector)로 변환하여 입력한다.
- 출력층(Output layer)에서는 예측 대상인 중심 단어를 원-핫 벡터로 레이블로 사용한다.
-
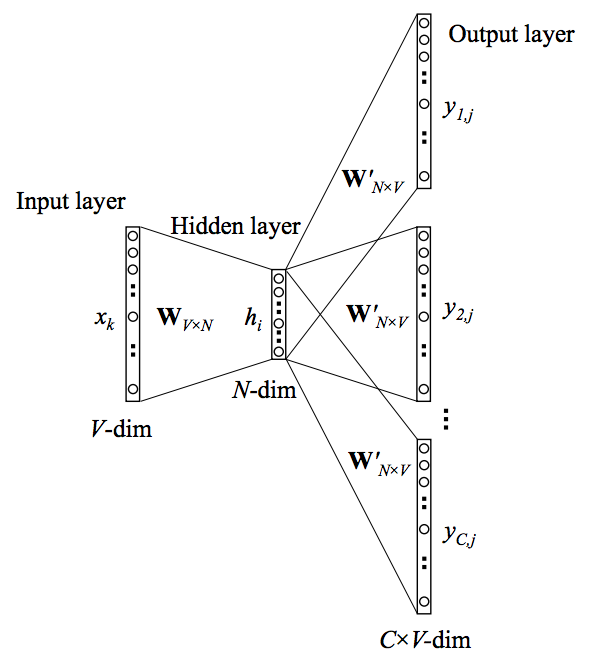
투사층(임베딩 층):
- 입력층과 투사층 사이의 가중치 는 크기의 행렬이다.
- V: 단어 집합(Vocabulary)의 크기 (원-핫 벡터 차원).
- M: 임베딩 벡터의 차원 (고정된 임베딩 차원).
- 임베딩 층을 통과하면, 각 원-핫 벡터는 벡터로 매핑되며, 윈도우 크기만큼 () 벡터가 생성된다.
- 입력층과 투사층 사이의 가중치 는 크기의 행렬이다.
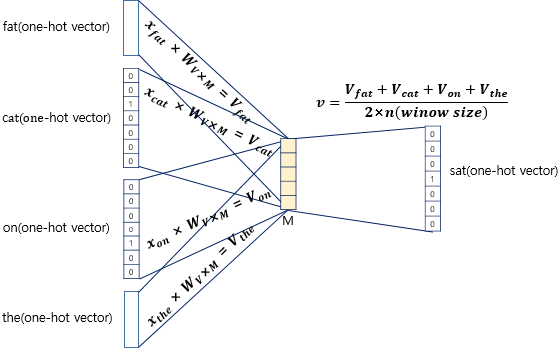
- 평균 벡터 계산:
- 윈도우 내 생성된 벡터의 평균을 계산하여 문맥(Context)을 하나의 벡터로 압축한다.
- 이 평균 벡터는 투사층(임베딩 층)과 출력층 사이의 가중치 와 곱해진다.
- 는 크기의 행렬로, 의 전치행렬이 아니다.
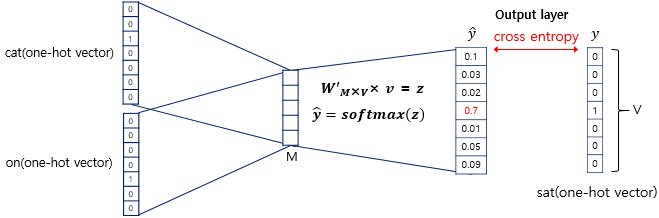
-
Softmax와 예측:
- 평균 벡터와 의 곱으로 얻어진 크기의 벡터는 Softmax를 통과하여 스코어 벡터()로 변환된다.
- 이 스코어 벡터는 각 단어가 중심 단어일 확률을 나타낸다.
-
손실(Loss) 계산 및 가중치 학습:
- 스코어 벡터()와 정답 레이블() 간의 Cross-Entropy Loss를 계산하여, 역전파를 통해 가중치 와 를 최적화한다.
-
학습 완료 후 워드 임베딩 활용:
- 학습 완료 후, 가중치 행렬()은 임베딩 벡터(look-up table)로 동작하며, 단어의 분산 표현(distributed representation)을 저장하는 사전과 같은 역할을 한다.
- 장점:
- 효율성: Skip-gram보다 계산 효율이 높아, 대규모 데이터셋에서도 빠르게 학습 가능.
- 문맥 정보 학습: 중심 단어를 문맥으로부터 예측하여 단어의 의미를 반영한 벡터를 생성.
- 의미적 관계 표현:단어 간 유사성과 관계를 벡터 공간에 반영.
- 예:
King - Man + Woman ≈ Queen
- 예:
- 동적 임베딩 차원: 임베딩 벡터의 크기(M)는 사용자가 설정할 수 있는 하이퍼파라미터이다.
- 단점:
- 단어 순서 정보 손실: 주변 단어의 집합을 입력으로 사용하므로 단어 순서를 고려하지 못함.
- 희귀 단어 학습 한계: 희귀 단어의 임베딩 품질이 낮을 수 있음.
- 단순한 맥락 처리: 주변 단어를 단순 평균으로 처리하므로 복잡한 문맥을 학습하기 어려움.
- 활용 분야:
- 사전 학습 임베딩 생성:
- CBOW로 학습된 워드 임베딩을 다양한 NLP 작업(예: 감정 분석, 문서 분류)에서 초기 입력으로 사용.
- 단어 유사도 분석:
- 학습된 단어 벡터를 이용해 단어 간 유사성을 계산.
- 문서 의미 표현:
- 단어 벡터의 평균이나 합을 통해 문서의 전반적인 의미를 표현.
- 정보 검색 및 추천 시스템:
- 단어 임베딩을 기반으로 검색 랭킹을 개선하거나, 추천 알고리즘에 활용.
- 사전 학습 임베딩 생성:
2. Skip-gram
- 공기 발생 행렬(Co-occurrence Matrix)의 아이디어를 학습 방식으로 변환한 모델이라고 볼 수 있음.
- 특정 단어가 주어졌을 때, 그 주변 단어들이 어떻게 분포되는지를 학습하는 과정.
- 설명:
- Skip-gram은 Word2Vec 모델의 한 방식으로, 중심 단어(Target)를 입력으로 받아 주변 단어(Context)를 예측하는 방식이다.
- CBOW와는 반대로 동작하며, 한 단어를 사용해 문맥을 학습하는 구조로 단어 간 의미적 관계를 반영한 임베딩 벡터를 학습한다.
-
예시:
- 예문: "The fat cat sat on the mat"
- 윈도우 크기: 2 (주변 단어 2개를 고려)
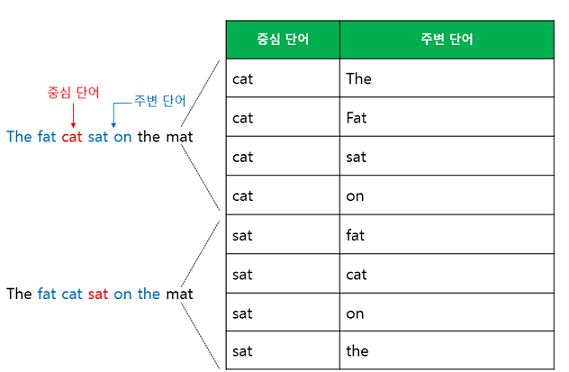
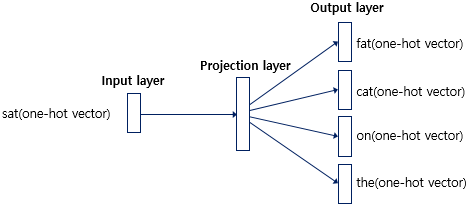
- 전반적인 학습 과정은 CBOW와 같지만, 큰 구조에서
one-to-many인지,many-to-one인지가 차이점이다.
- 장점:
- 희귀 단어 학습:
- 희귀 단어의 문맥 정보를 더 잘 학습할 수 있어, 단어 집합에 포함된 모든 단어의 임베딩 품질을 높임.
- 문맥의 풍부한 표현:
- 중심 단어를 기준으로 다양한 문맥을 학습하여 단어 간의 관계를 풍부하게 반영.
- 의미적 유사성 표현:
- 단어 벡터 간 의미적 관계를 벡터 공간에서 효과적으로 나타냄.
- 예:
King - Man + Woman ≈ Queen.
- 희귀 단어 학습:
- 단점:
- 높은 계산 비용:
- 중심 단어와 주변 단어 각각을 학습하기 때문에 CBOW에 비해 학습 속도가 느림.
- 희소 데이터 문제:
- 대규모 데이터에서 학습 속도를 보완하기 위해 Negative Sampling이나 Hierarchical Softmax와 같은 기법이 필요.
- 모델 학습 난이도:
- 문맥을 예측하기 위해 더 많은 파라미터를 학습해야 하므로, 계산 자원이 부족한 환경에서는 비효율적일 수 있음.
- 높은 계산 비용:
- 활용 분야:
- 단어 임베딩 생성:
- 학습된 단어 임베딩 벡터를 다양한 NLP 작업(예: 텍스트 분류, 감정 분석)의 입력으로 사용.
- 단어 유사도 계산:
- 단어 간 유사성을 계산하거나 단어의 의미적 관계를 분석하는 데 활용.
- 추천 시스템:
- 단어 벡터를 활용하여 유사한 콘텐츠(예: 문서, 제품 등)를 추천.
- 의미 네트워크 분석:
- 단어 임베딩을 이용해 의미 네트워크를 구축하고 분석.
- 정보 검색 및 검색 엔진:
- 검색 쿼리와 문서 간 유사도를 계산해 검색 품질 향상.
- 단어 임베딩 생성:
Word2Vec 학습 트릭
- Word2Vec에서 학습 속도와 품질을 개선하기 위해 사용되는 두 가지 주요 학습 기법을 알아보자
Subsampling Frequent Words
- TF-IDF에서 "반복되는 단어는 항상 중요하지 않다"는 개념을 반영하듯, 자주 등장하는 단어의 빈도를 줄여 학습을 더 효과적으로 만드는 기법이다.
-
일반적으로 "the", "is", "and" 같은 불용어(Stop Words)는 텍스트에서 매우 자주 등장하지만, 의미적으로 중요한 정보를 제공하지 않는다.
-
불필요한 단어들이 학습 과정에서 많이 사용되면 편향(일종의 클래스 불균형)이 발생하거나, 중요한 단어의 학습이 지연될 수 있다.
-
따라서, "반복되지만 중요하지 않은 단어"와 "반복되면서 중요한 단어"를 구별하는 과정이 필요하다.
-
Subsampling Frequent Words은 특정 빈도 이상으로 등장하는 단어들을 확률적으로 제거(Downsampling)하여, 모델이 더 유의미한 단어에 집중하도록 유도하는 기법이다.
-
: 단어 가 학습에서 제외할 확률
: 단어 의 상대 빈도 (전체 말뭉치에서 등장한 횟수 / 총 단어 수)
: 다운 샘플링 임계값
-
-
CBOW : 문맥을 구성할 때 빈도가 높은 단어를 제거
Skip-gram : 중심 단어로 사용할 단어에서 빈도가 높은 단어를 제거
Negative Sampling
- 의미 있는 단어 관계를 학습하기 위해서 모든 단어를 고려할 필요는 없다.
- 의미 있는 단어 관계를 학습하려면, 실제 문맥 단어(Positive Sample)와 무관한 단어(Negative Sample)를 함께 비교하는 과정이 필요하다.
-
일반적으로 단어 집합의 크기()는 매우 크며, 이를 Softmax 변환하는 것은 매우 비효율적이다.
-
Negative Sampling은 불필요한 계산을 줄이면서도, 의미 있는 단어 관계를 학습하는 기법이다.
-
기존 Softmax 기반 다중 분류 문제를, 중심 단어의 문맥(Positive Sample)과 중심 단어와 연관되지 않은 무작위 단어(Negative Sample)만 사용하는 이진 분류(Binary Classification) 문제로 변환한다.
-
손실함수 (Binary Classification Loss) :
-
: 중심 단어의 임베딩 벡터
: Positive Sample의 임베딩 벡터
: Negative Sampling으로 샘플링된 단어 집합
: 시그모이드 함수
-
-
-
CBOW: 중심 단어(Target)를 예측할 때, Negative Sample을 추가하여 학습.
Skip-gram: 주변 단어(Context)를 예측할 때, Negative Sample을 추가하여 학습.
