0. 데이터 기반 제품 개선
-
데이터 과학자의 역할 중 하나는 데이터를 기반으로 제품을 개선하는 것이다 (Product Science)
-
이떄 데이터 과학자는 머신러닝을 통해 사용자들의 경험을 개선한다.
-
데이터 과학자에게 필요한 스킬셋은 다음과 같다.
- 머신러닝/AI에 대한 깊은 지식과 경험
- Python / SQL 코딩능력
- 통계 및 수학 지식
- 끈기와 열정
1. 일반적인 모델 개발 과정
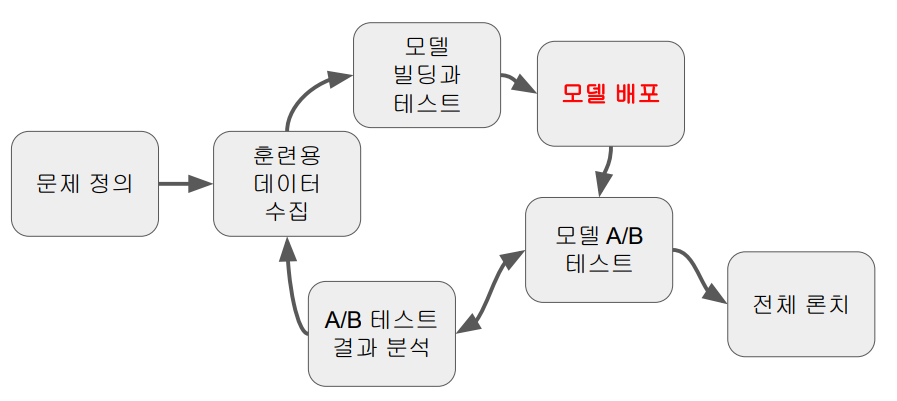
-
일반적인 모델 개발 과정은 위 그림과 같다.
-
Waterfall 방식이 아닌, Agile의 형식으로 모델을 개발한다.
-
짧은 사이클로 단순하게 시작하여 점전적으로 머신러닝 모델을 고도화
데이터 기반 제품 개선의 예시
- 가장 유명한 예시 중 하나는 넷플릭스의 시네매치(Cinematch)이다. 사용자의 [시청목록, 평점, 검색어, ..]등의 여러 데이터를 기반으로 사용자를 그룹화하고, 협업적 필터링 (Collaborative Filtering)을 통해 특정 사용자가 좋아할 만한 컨텐츠를 추천해준다.
머신러닝 기초
머신러닝이란?
- 배움이 가능한 기계. 데이터의 패턴을 보고 이를 흉내내는 방식이다.
- 미국의 저명한 컴퓨터 사이언티스트이자, AI 분야의 선구자인 Arthur Samuel은 머신러닝을 다음과 같이 정의한다.

"A field of study that gives computers the ability to learn without being
explicitly programmed"
- "직접적인 프로그래밍을 하지 않고 컴퓨터를 학습할 수 있게 해주는 분야"라고 번역 해 볼 수 있다.
머신러닝 모델이란?
- 머신 러닝을 통해서 결과적으로 만들어내는 산출물이다.
- 특정 정보를 입력받았을 때, 머신 러닝을 통해 학습한 방식으로 예측을 해주는 블랙박스
머신러닝의 종류
- 크게 3가지로 종류를 나누어 볼 수 있다
- 지도 기계 학습 (Supervised Machine Learning) : 레이블이 지정된 데이터셋(train set)에 대해 훈련을 진행한다. 이는 입력 데이터가 해당 출력 레이블과 함께 제공되는 것을 의미한다. 모델은 입력에서 출력으로의 매핑 함수를 학습하여 새로운 데이터에 대한 예측이나 분류를 수행한다.
- ex) Classification, Regression
- 비지도 기계 학습 (Unsupervised Machine Learning) : 레이블이 없는 데이터셋에서 모델을 훈련시킨다. 알고리즘은 명시적인 출력 레이블의 도움 없이 데이터 내의 패턴이나 구조를 찾아낸다.
- ex) Clustering
- 강화 학습 (Reinforcement Learning) : 강화 학습은 에이전트(기계)가 일련의 결정을 내리도록 훈련하는 데 중점을 둔 형태의 머신러닝이다. 에이전트는 환경과 상호 작용하며 보상이나 패널티의 형태로 피드백을 받아 학습한다. 목표는 에이전트가 시간이 지남에 따라 누적 보상을 최대화하는 정책을 학습하는 것이다.
- ex) AlphaGO, Autonomous Vehicle
- 지도 기계 학습 (Supervised Machine Learning) : 레이블이 지정된 데이터셋(train set)에 대해 훈련을 진행한다. 이는 입력 데이터가 해당 출력 레이블과 함께 제공되는 것을 의미한다. 모델은 입력에서 출력으로의 매핑 함수를 학습하여 새로운 데이터에 대한 예측이나 분류를 수행한다.
머신러닝/AI의 위험성
- ITU(United Nations Specialized Agency for ICT)에서 발표한 "Trustworthy AI"를 통해 머신러닝/AI의 위험성 및 이를 사용할 때 주의할 점에 대해서 알아보자.
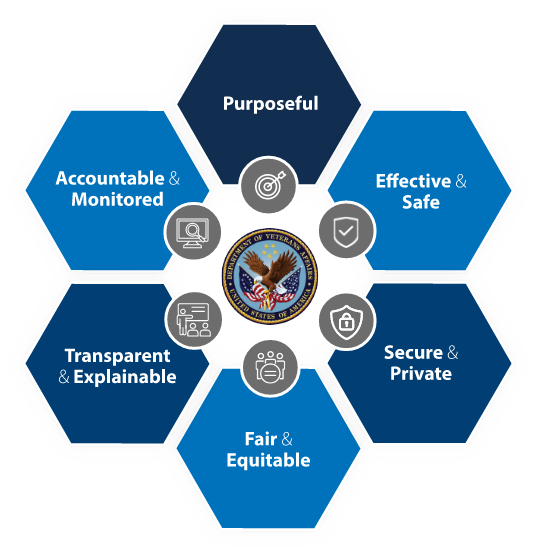
- 사람의 감독과 모니터링이 필요하다
- AI의 견고성과 안전성이 보장되어야 한다.
- 개인의 정보를 보호해야 한다.
- AI가 어떠한 방식으로 작동하는지 설명 가능해야 한다. (ML Explainability)
- 다양성과 비차별성과 공정성이 있어야 한다. (편향성이 없어야 한다)
- 사회/환경 친화적이어야 한다. (GenAI의 경우 저작권문제 해결 등)
- 문제 발생시 책임 소재가 명확해야 한다. (자율주행 자동차의 사고 등)
MLOps(Machine Learning Operation) 직군은 무엇을 할까?
-
모델을 빌드하고 시간이 지나면, 훈련에 사용한 데이터는 변하지 않지만 실제 환경의 데이터가 변화한다.
-
이러한 변화에 의해 기존 모델의 성능이 저하되는 현상을 Data Drift라고 한다.
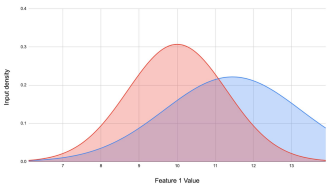
-
모델의 성능을 유지/발전 하기 위해서는 지속적으로 성능을 모니터링하고, 모델을 리빌딩(CT)해야 할 필요가 있다.
CT(Continuous Testing) : ML 모델의 성능을 보장하기 위해 배포 전/후에 여러 테스트를 하는 것4. 간단하게 ML 체험해 보기
-
Simple ML for Sheets : Google Spreadsheet에서 사용 가능. Spreadsheet에 존재하는 데이터를 train set으로 삼아 간단한 모델을 만들 수 있다.
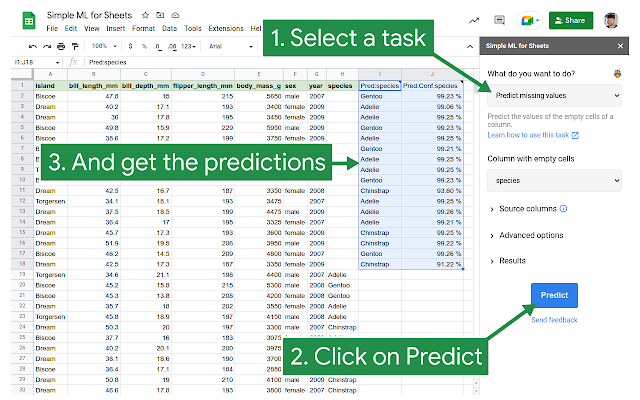
-
해당 확장프로그램을 통해 species에서 비어있는 cell의 데이터를 예측해 보았다.
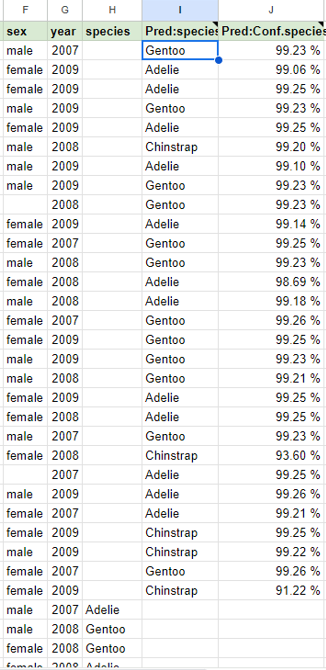
Pred:species : Spreadsheet의 다른 데이터로부터 예측한 data
Pred:Conf.species : 예측한 데이터가 얼마나 정확한지 예측
4. 마무리
- 3일차 공부도 마무리되었다. 첫 주차 남은 2일도 계속 열심히 따라가자!

개인 공부용 블로그입니다