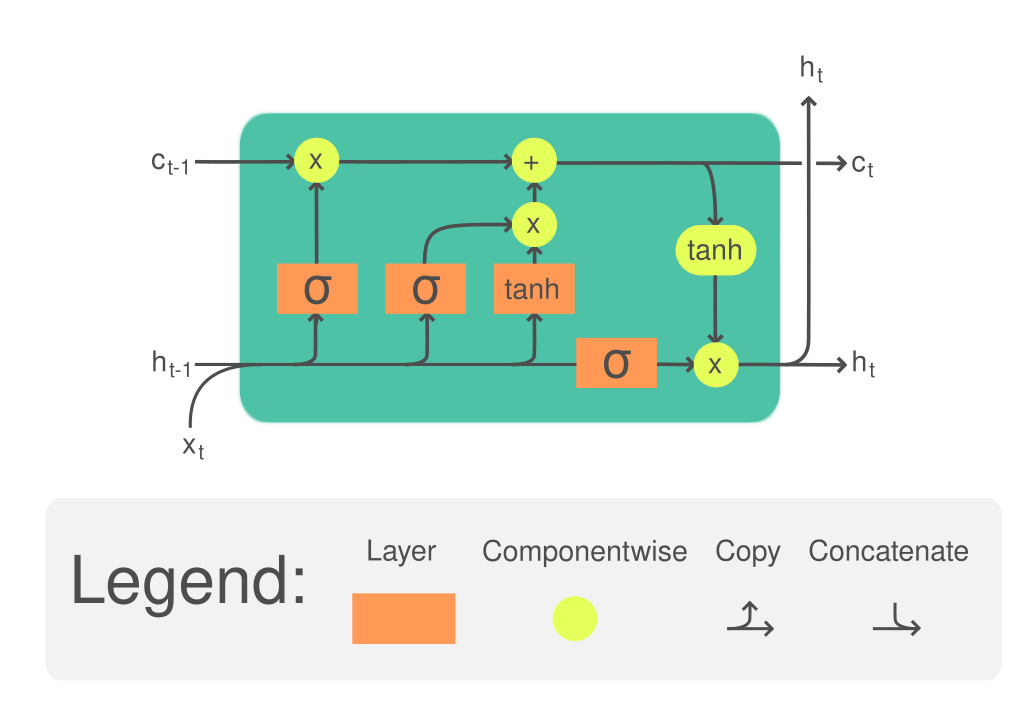
LSTM
- LSTM(Long Short-Term Memory) : 순환 신경망(RNN)의 구조를 기반으로 발전된 신경망으로, 셀 상태와 입력 게이트, 출력 게이트, 망각 게이트를 통해 기존 RNN이 가진 기울기 소멸 문제(vanishing gradient)를 완화하고, 장기 의존성 문제를 효과적으로 해결하는 데 초점을 맞춘다.
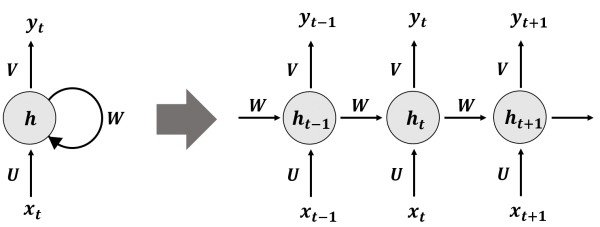
RNN과 LSTM의 공통점
-
순환 구조 (Recurrent) : 하나의 구조를 반복적으로 재사용하여 시퀀스 입력 및 출력을 처리할 수 있다. 입력 시퀀스의 길이에 따라 네트워크의 깊이가 동적으로 결정된다.
-
은닉 상태 (Hidden State) : 이전 시점의 정보를 은닉 상태를 통해 현재 시점으로 전달하며, 특정 시점의 예측을 수행할 때 과거의 문맥을 반영한다. 이를 통해 순서가 중요한 데이터(텍스트, 음성, 주가 등)를 효과적으로 모델링 할 수 있다.
RNN과 LSTM의 차이점
-
장기/단기 정보 저장 구분:
-
RNN은 은닉 상태()는 장기/단기 정보를 모두 저장한다.
-
따라서, 입력 시퀀스의 길이가 길어질수록, 과거의 정보가 현재 시점까지 제대로 전달되지 못하는 장기 의존성 문제(Long-Term Dependency Problem)가 발생할 수 있다.
-
이는 RNN이 과거 정보를 은닉 상태로 계속 전달하면서, 기울기 소실(Vanishing Gradient) 문제로 인해 과거의 중요한 정보가 학습 과정에서 사라지기 때문이다.
-
결과적으로, RNN은 긴 시퀀스의 데이터를 학습하는 데 한계를 가진다.
-
-
LSTM은 셀 상태()를 통해 장기 정보를 저장하며, 은닉 상태()는 현재 시점의 정보를 요약하고 예측에 사용한다.
-
LSTM은 셀 상태()를 통해 정보를 선형적으로 전달하며, 장기적으로 유지할 정보와 삭제할 정보를 망각 게이트와 입력 게이트로 조정한다.
-
이를 통해 장기 의존성 문제를 해결하고, 긴 시퀀스의 데이터를 학습하는 데 유리합니다.
-
-
LSTM 게이트 구조
1. 망각 게이트
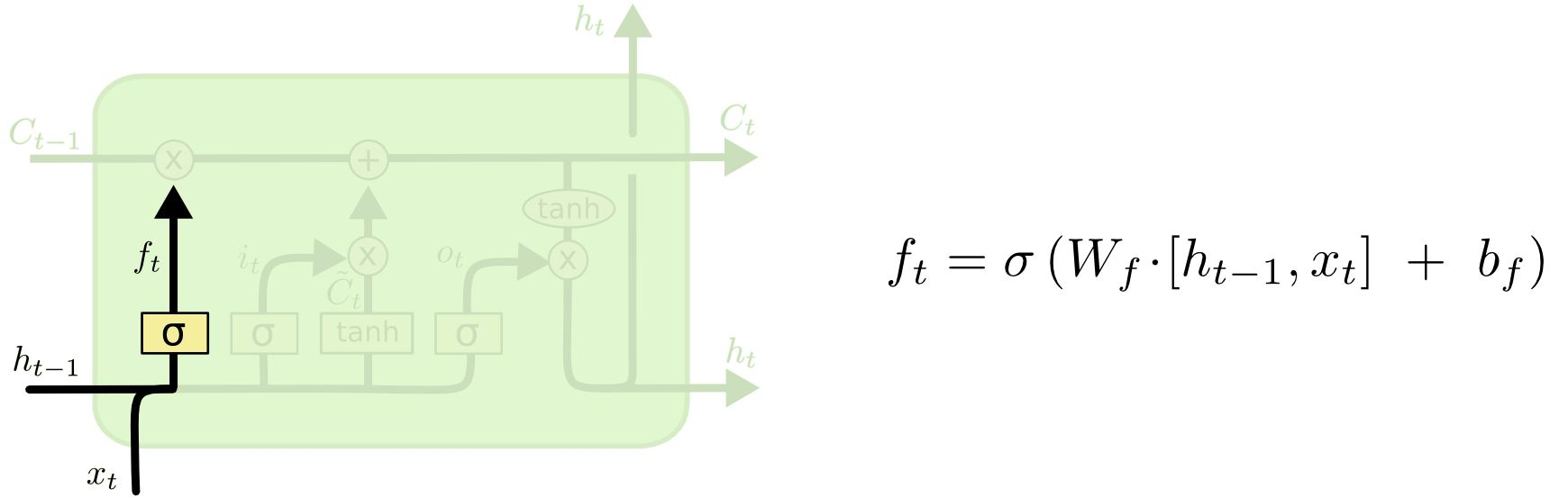
-
망각 게이트(Forget Gate)에서는 이전 시점의 셀 상태()를 현재 시점의 셀 상태()로 얼마나 전달할지 결정한다.
-
시그모이드 함수()를 사용하여 의 값을 0에서 1 사이로 제한하며, 이를 통해 어떤 정보를 유지할지(값이 1에 가까움) 또는 버릴지(값이 0에 가까움)를 확률적으로 결정한다.
변수 설명 망각 비율 망각 게이트 가중치 이전 시점의 은닉 상태 현재 시점의 입력 망각 게이트의 편향
-
망각 게이트의 직관적 이해
-
망각 게이트는 축적된 정보를 "필요한 것"과 "불필요한 것"으로 필터링한다.
-
예를 들어, "The cat sat on the mat."라는 문장이 있을 때, "The"와 같은 일반적인 단어는 망각 게이트를 통해 삭제되고, "cat"과 같은 핵심 단어는 유지된다.
-
2. 입력 게이트
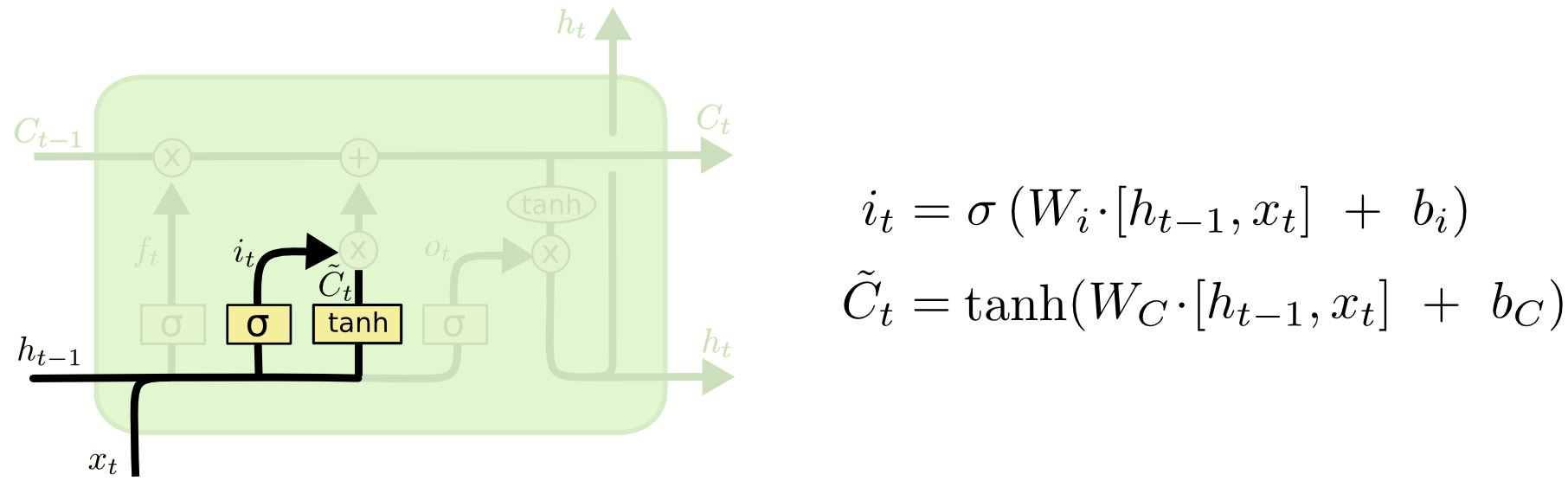
-
입력 게이트(Input Gate)에서는 현재 입력 데이터()와 이전 은닉 상태()를 기반으로, 셀 상태()에 추가할 정보를 결정한다.
-
시그모이드 함수()를 사용하여 값을 0에서 1 사이로 제한한다.
-
하이퍼볼릭 탄젠트 함수(tanh)를 사용하는 이유는 다음과 같다.
-
비선형성 추가 : 복잡한 패턴을 학습할 수 있도록 도움
-
중심 경향성이 있는 스케일링 : 안정적인 학습을 도움 (Gradient Flow를 유지)
-
방향과 크기의 표현 : 정보의 방향성과 크기를 동시에 학습할 수 있음
변수 설명 입력 게이트 활성화 값 입력 게이트 가중치 이전 시점의 은닉 상태 현재 시점의 입력 입력 게이트의 편향 셀 상태 후보 셀 상태 후보 생성 가중치 셀 상태 후보 생성 편향 -
-
입력 게이트의 직관적 이해
-
입력 게이트는 새로운 정보를 "필요한 것"과 "불필요한 것"으로 필터링한다.
-
예를 들어, "The cat sat on the mat."라는 문장이 있을 때, 새로운 단어 "sat"이 문맥상 중요한 정보로 판단되면 입력 게이트는 이를 반영하도록 설정한다.
-
3. 셀 상태 업데이트
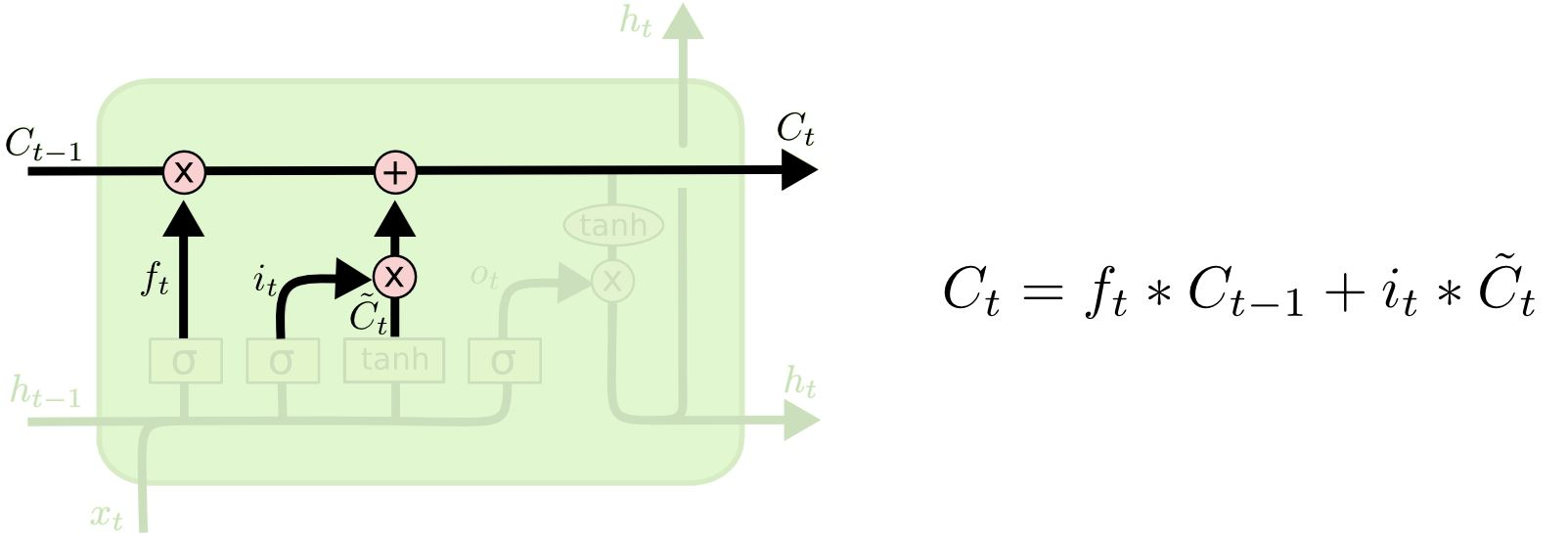
-
망각 게이트와 출력 게이트의 결과값()을 활용하여 이전 시점의 셀 상태()를 현재 시점의 셀 상태()로 업데이트 한다.
- 이전 셀 상태에서 유지할 정보()와 새로운 입력에서 추가할 정보()을 결합하여 셀 상태를 구성한다.
4. 출력 게이트
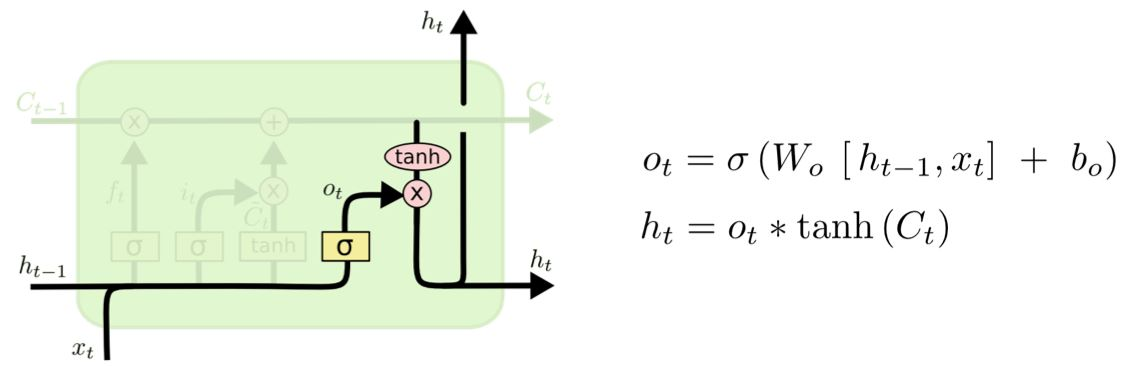
-
출력 게이트(Output Gate)는 현재 입력 데이터()와 이전 은닉 상태()를 기반으로, 셀 상태()에서 어떤 정보를 은닉 상태()로 출력할지 결정한다.
-
시그모이드 함수()를 사용하여 의 값을 0에서 1 사이로 제한한다.
변수 설명 출력 비율 출력 게이트 가중치 이전 시점의 은닉 상태 현재 시점의 입력 출력 게이트의 편향 현재 은닉 상태 현재 셀 상태
-
출력된 은닉 상태()는 두 가지 역할을 수행한다:
-
다음 시점의 LSTM 셀로 전달.
-
현재 시점의 결과 예측(Output Prediction)에 사용.
-
: 현재 시점의 예측값
: 출력 가중치
: 출력 편향
: 활성화 함수
-
-
-
출력 게이트의 직관적 이해
-
출력 게이트는 셀 상태를 기반으로 다음 단계로 전달할 정보를 선택적으로 출력한다.
-
예를 들어, "The cat sat on the mat."라는 문장이 있을 때, "sat"이 현재 시점에서 중요하다고 판단되면, 출력 게이트는 "sat"과 관련된 정보를 은닉 상태로 반영한다.
-
LSTM 역전파
-
LSTM 가중치/편향
- 순환 구조를 통해 가중치와 편향을 재사용한다
변수 설명 편향 설명 망각 게이트 가중치 망각 게이트 편향 입력 게이트 가중치 입력 게이트 편향 셀 상태 후보 생성 가중치 셀 상태 후보 생성 편향 출력 게이트 가중치 출력 게이트 편향 출력 가중치 출력 편향
- 손실 함수에 대한 기울기 정의
-
손실 함수 에 대해, 시점 에서의 기울기를 계산하기 위해 다음을 정의한다
-
출력값에 대한 손실 기울기:
-
셀 상태에 대한 손실 기울기:
-
게이트 값에 대한 손실 기울기:
-
- 역전파 단계
-
(1) 은닉 상태()의 기울기는 다음과 같이 계산한다:
-
(2) 출력 게이트()의 기울기는 은닉 상태와 셀 상태의 관계를 통해 계산한다:
-
(3) 셀 상태()는 은닉 상태와 망각 게이트를 통해 영향을 받는다:
-
(4) 망각 게이트()의 기울기는 이전 셀 상태()를 기반으로 계산한다:
-
(5) 입력 게이트()와 셀 상태 후보()의 기울기는 다음과 같다:
- 가중치와 편향의 기울기
-
각 게이트의 기울기를 통해 가중치와 편향에 대한 기울기를 계산한다:
-
가중치 기울기:
- 예: 망각 게이트 가중치()
- 예: 망각 게이트 가중치()
-
편향 기울기:
- 예: 망각 게이트 편향()
- 예: 망각 게이트 편향()
-
효과
-
기울기 소실 문제 완화 :
-
RNN의 BPTT는 시퀀스 전체에 대해 기울기를 곱하기 때문에 기울기 소실 문제에 민감하다.
-
LSTM의 BPTT는 국소적인 경로에서 계산된 기울기를 더하는 방식으로 동작한다.
따라서 시퀀스 길이가 길어져도 기울기 소실 문제를 크게 완화할 수 있다.
-
-
장기 의존성의 효율적 학습 :
-
RNN은 기울기가 시퀀스의 길이에 따라 점점 약해져, 장기 의존성을 학습하기 어렵다.
-
LSTM에서 셀 상태의 선형 경로는 장기 정보를 유지하면서도 필요한 정보를 선택적으로 업데이트할 수 있다. 역전파 과정에서도 셀 상태의 선형 경로를 통해 기울기가 유지되며, 중요한 장기 정보를 효과적으로 전달할 수 있다.
-
-
기울기 계산의 독립성 :
- LSTM의 구조는 각 게이트가 독립적으로 학습될 수 있도록 하며, 특정 게이트의 오류가 전체 학습에 미치는 영향을 최소화한다. 이로 인해 학습 안정성을 높일 수 있다.
한계
-
기울기 소실 문제의 잔존 가능성 :
-
게이트 값이 극단적으로 작아지는 경우 셀 상태의 정보가 약화될 수 있다.
-
활성화 함수(sigmoid, tanh)의 입력값이 극단적으로 크거나 작을 때 도함수가 0에 가까워진다.
-
시퀀스가 극단적으로 긴 경우 잦은 게이트 업데이트 과정에서 정보가 점차 희석될 가능성이 있다.
-
-
메모리 사용 방식의 한계
- LSTM은 "장기 메모리"를 제공하지만, 메모리 사용 방식이 제한적이며 특정 데이터에서는 효율적으로 정보를 저장하지 못할 수 있다.
LSTM의 확장
- Bidirectional LSTM: 순방향(forward)과 역방향(backward)으로 데이터를 처리하여, 전체 시퀀스 정보를 활용하는 확장형 LSTM.
- Stacked LSTM: 여러 LSTM 레이어를 쌓아 더 깊은 구조로 구성하여, 복잡한 패턴을 학습할 수 있는 모델.
- Attention Mechanism: 모든 시점의 정보를 가중합산하여, 특정 시점에서 중요한 정보를 동적으로 선택하도록 설계된 기법.
