RNN (Recurrent Neural Network)
- 시계열 데이터나 순차적 데이터를 처리하는 데 특화된 딥러닝 모델
- 현재 단계의 예측이 단순히 현재 입력에만 의존하지 않고, 이전 입력도 고려한다
- 고정 크기의 데이터가 아닌 가변적인 시퀀스의 입력 또는 출력을 처리할 수 있다
- Recurrent는 '반복되는'이라는 뜻으로, RNN이 시간 단계마다 동일한 구조를 반복적으로 사용하는 모델임을 나타낸다
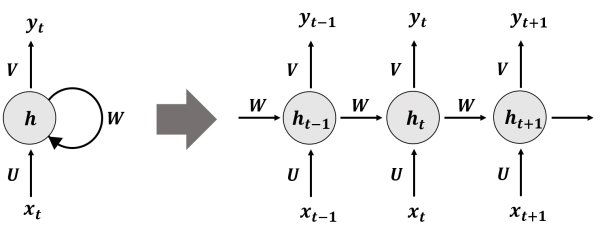
-
왼쪽 그림 (순환 구조를 표현) :
- 는 특정 시간 단계의 입력값을 나타낸다
- 는 모든 시간 단계에서 재사용하는 가중치 집합()을 나타낸다
- 는 시간 축을 따라 이전 정보를 축적하며 갱신되는 상태를 나타낸다.
- 는 특정 시간 단계의 출력값을 나타낸다
-
오른쪽은 왼쪽 그림을 시간 단계(Time Step)마다 펼쳐서 입력, 출력, 가중치를 표현한 그림이다.
시퀀스와 종속적인 데이터 처리
-
RNN의 순환 구조는 다음 두 가지 주요 특징을 제공한다.
-
시퀀스 데이터 처리 :
- 입력/출력의 크기가 고정되어 있지 않아도 처리할 수 있다.
-
종속적인 데이터 처리 :
- 시간 축을 따라 이전 정보를 은닉 상태에 축적하며 갱신하여 데이터 간의 종속성을 학습할 수 있다.
-
-
CNN과 RNN을 비교해보면 다음과 같다
| 특징 | CNN (One-to-One) | RNN (다양한 구조) |
|---|---|---|
| 입력 크기 | 고정 크기 입력 (예: 단일 벡터, 정해진 이미지 크기) | 시퀀스 입력 가능 |
| 출력 크기 | 고정 크기 출력 (예: 단일 값 또는 클래스) | 시퀀스 출력 가능 |
| 시간/순서 고려 | 독립적인 데이터 처리 (시간적 문맥 정보 없음) | 종속적인 데이터의 시퀀스를 처리 (순서 중요) |
| 적용 분야 | 고정 구조 데이터 (이미지, 정적인 피처 벡터) | 순차 데이터 (텍스트, 음성, 비디오, 시계열 데이터 등) |
RNN 종류
- RNN은 입출력 구조에 따라 RNN의 종류를 나눌 수 있다.
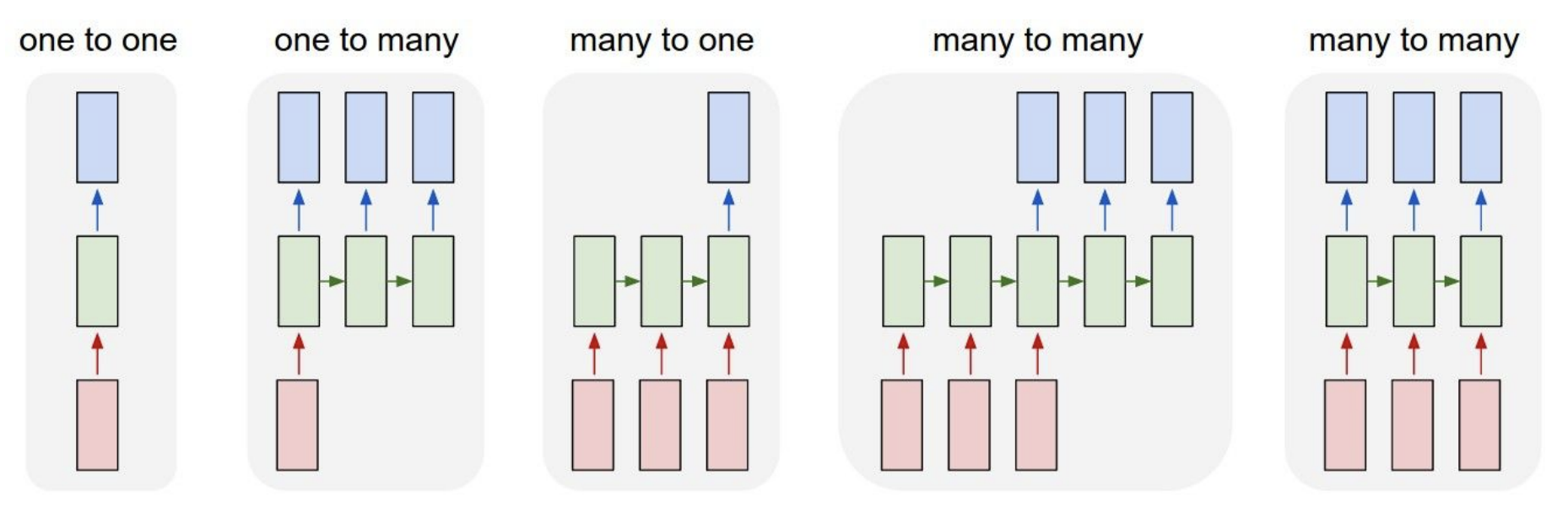
source : Convolutional Neural Networks for Visual Recognition
-
0) One-to-One (고정 입력 -> 고정 출력)
- 예: ANN, CNN
-
1) One-to-Many (고정 입력 -> 시퀀스 출력)
-
예: 이미지 캡셔닝
-
입력: 하나의 고정 크기 이미지
-
출력: 이미지의 내용을 설명하는 단어들의 시퀀스
- RNN이 이미지의 특징 벡터를 입력으로 받아, 이를 반복적으로 처리하여 단어 시퀀스를 생성
-
-
2) Many-to-One (시퀀스 입력 -> 고정 출력)
-
예: 감정 분류, 액션 예측
-
입력: 단어의 시퀀스(텍스트) 또는 비디오 프레임의 시퀀스
-
출력: 하나의 정적 결과(예: 감정 라벨, 액션 라벨)
- 입력 시퀀스를 처리하면서 RNN은 은닉 상태를 업데이트해 최종 단계에서 하나의 결과를 생성
-
-
3-1) Many-to-Many (시퀀스 입력 -> 시퀀스 출력)
-
예: 번역, 비디오 요약
-
입력: 한 언어로 된 문장 시퀀스(예: 영어 문장)
-
출력: 다른 언어로 된 문장 시퀀스(예: 프랑스어 문장)
- RNN이 입력 시퀀스를 처리한 후, 디코더(decoder)가 새로운 시퀀스를 생성
-
-
3-2) Many-to-Many (시퀀스 입력 -> 시퀀스 출력, 동기적)
-
예: 비디오 분류(프레임 수준에서)
-
입력: 비디오의 프레임 시퀀스
-
출력: 각 프레임에 대한 라벨 시퀀스
- 이 경우, 모델은 현재 프레임뿐 아니라 이전 프레임의 문맥 정보도 활용해 각 프레임을 분류
-
RNN 학습 과정
-
RNN은 입력 시퀀스를 처리하면서 은닉 상태(hidden state)를 업데이트한다.
-
입력 벡터는 각 시점(timestep)마다 RNN에 제공되며, 은닉 상태는 입력과 이전 상태를 기반으로 갱신된다
1. Foward Pass
frame 1부터 n까지를 입력으로 받는 RNN모델의 foward pass는 다음과 같이 작동한다.
-
Timestep 1 (frame 1) :
- 입력 : (첫 번째 프레임)
- 은닉 상태 업데이트 :
- 출력 :
-
Timestep 2 (frame 2) :
- 입력 : (두 번째 프레임)
- 은닉 상태 업데이트 :
- 출력 :
-
Timestep n (frame n) :
- 입력 : (마지막 프레임)
- 은닉 상태 업데이트 :
- 출력 :
-
: 입력-은닉 상태 가중치 (input size x unit size)
- 입력 벡터를 현재 은닉 상태로 변환한다
- 입력 데이터를 은닉 상태 공간으로 투영(embedding)하여 RNN의 내부 상태에서 활용 가능하게 만들어 준다
- 예: "고양이"라는 단어가 입력으로 들어오면, 를 통해 단어의 벡터 표현이 은닉 상태 공간으로 전달된다
-
: 은닉 상태-은닉 상태 가중치 (unit size x unit size)
- 이전 은닉 상태가 현재 은닉 상태로 영향을 미치도록 한다
- RNN이 시간적 문맥과 이전 정보를 기억할 수 있게 해주는 핵심 가중치이다
- 예: 이전 단어("The cat")가 현재 단어("is")의 문맥을 형성하는 데 기여
-
: 은닉 상태-출력 가중치 (unit size x output size)
-
현재 은닉 상태를 출력 벡터로 변환하는 데 사용한다
- 예: 은닉 상태가 "고양이가 잔다"라는 정보를 담고 있다면, 이를 출력("The cat is sleeping")으로 변환한다
-
-
RNN Foward Pass의 문제점 :
- 는 계속해서 이전 단계의 은닉 상태()를 기반으로 갱신되는데, 1보다 작은 값이 지속적으로 곱해지는 상황에서는 가 점점 작아지고, t가 커질수록 초기 은닉 상태의 영향이 소멸한다.
-
기울기 소실로의 연결 :
- 이는 RNN이 긴 시퀀스를 처리할 때 초기에 입력된 데이터의 정보를 잃게 만들며, RNN 역전파 (BPTT)에서 기울기 값이 지수적으로 감소하게 되어, 가중치 업데이트가 효과적으로 이루어지지 않는 문제를 유발한다.
2. Calculate Loss
-
RNN은 지도 학습(Supervised Learning) 모델이며, 학습 과정에서 정답 라벨을 사용한다.
-
각 시간 단계의 출력()과 정답 라벨()간의 차이를 기반으로 손실()을 계산한다.
3. Backward Pass (BPTT)
- BPTT (Backpropagation Through Time) : 시간적으로 펼쳐진 RNN에서 역전파를 통해 각 시점에서 손실 기울기를 계산한다.
-
왼쪽 그림과 같이 순차적인 순환 구조를 가진 RNN을 오른쪽 그림처럼 시간을 축으로 펼쳐주면 모든 레이어의 뉴런이 1개이고, 레이어의 개수는 시퀀스의 길이()와 같은 ANN과 같은 모습이 된다.
-
시간 축을 거슬러 올라가며( → ... → ) 기울기(손실 기여도)를 계산한다(체인 룰)
- : 특정 시간 단계 에서의 손실함수
- : 시간 단계 의 은닉 상태
- : RNN 학습 가중치 ()
-
기울기를 이전 단계로 전달하며 시간 단계의 기울기를 누적한다
- 우변 첫 번째 항 : 앞 단계()의 기울기
- 우변 두 번째 항 : 현재() 은닉 상태가 앞 단계()의 은닉 상태에 미친 영향
결과적으로, 모든 시간 단계의 기울기를 누적한다
RNN의 핵심 비유 : 밀 크레프
- 밀 크레프 : 흔히 크레이프 케이크라고 부르며, 여러장의 크레이프 사이에 생크림이나 커스터드 크림, 과일 등을 넣으며 겹겹이 쌓아 만든다.

-
시퀀스 :
- RNN은 입력/출력을 가변적으로 처리할 수 있다.
이는 밀 크레프의 층 수가 정해져 있지 않아, 필요한 만큼 쌓아올릴 수 있는 모습과 유사하다.
- RNN은 입력/출력을 가변적으로 처리할 수 있다.
-
은닉 상태 :
- RNN에서는 각 입력 데이터를 가공하여 새로운 정보를 기존 은닉 상태에 더한다.
이는 크레이프 한 장을 기본 층으로 쌓고, 크림을 얹어 새로운 층을 만드는 것과 유사하다.
- RNN에서는 각 입력 데이터를 가공하여 새로운 정보를 기존 은닉 상태에 더한다.
-
활성화 함수 :
- RNN의 활성화 함수는 은닉 상태 업데이트 과정에서 입력 데이터와 이전 은닉 상태를 정교하고 조화롭게 연결한다.
이는 밀 크레프의 중간에 생크림, 과일을 추가하여 각 층을 더 풍부하고 조화롭게 만드는 것과 유사하다.
- RNN의 활성화 함수는 은닉 상태 업데이트 과정에서 입력 데이터와 이전 은닉 상태를 정교하고 조화롭게 연결한다.
-
시간 단계 :
- RNN은 각 시간 단계에서 입력을 받아 은닉 상태를 업데이트한다.
이는 밀 크레프의 각 층을 순차적으로 쌓아 올리는 과정과 유사하다.
- RNN은 각 시간 단계에서 입력을 받아 은닉 상태를 업데이트한다.
-
최종 출력 :
- RNN의 출력은 해당 시간 단계의 은닉 상태를 기반으로 생성한다.
이는 크레이프 케이크를 완성한 후, 겉면에 데코레이션(출력층 가중치 적용)을 추가하여 결과물을 만드는 과정과 유사하다.
- RNN의 출력은 해당 시간 단계의 은닉 상태를 기반으로 생성한다.
