Bias-variance decomposition
-
Bias-variance decomposition(편향-분산 분해)를 사용하여 실제값과 예측값의 차이(예측 오차)를 구성하는 세 가지 요소를 찾아보자
-
사용할 표기법을 정리하면 아래와 같다
표기 설명 실제값, true function 노이즈가 포함된 실제값, oberved value 모델에 의해 추정된 예측 함수, predicted function 예측 함수의 기대값, expected prediction | 조건부 평균 제곱 오차, conditional MSE
(2), (3)을 (1)에 대입하면
- : 추정값 자체의 분산. 추정계수들과 절편의 분산과 비례한다
- : 실제값()과 모델의 평균 예측값(의 차이를 나타낸다.
- 가 높은 경우 : 복잡한 비선형 관계를 가진 데이터를 linear regression 모델로 학습할 경우 bias가 높다(선형 회귀 분석의 가정 중 선형성에 위배되는 경우). 모델이 데이터의 복잡한 패턴을 제대로 학습하지 못하고 지나치게 단순화된 예측을 해 underfitting 문제가 발생한다.
- 가 낮은 경우 : 모델이 실제 데이터의 패턴을 잘 학습하고 있다는 것을 의미한다. 하지만 이 경우, 모델이 데이터의 noise까지 학습하는 overfitting의 가능성을 생각해야 한다.
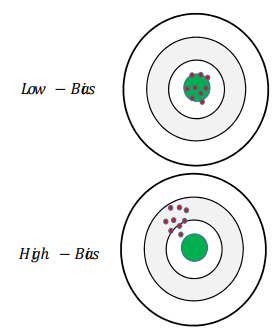
- : 데이터 자체에 내재된 변동성을 의미하며, 이는 종속 변수 y와 실제 함수 f(x)간의 근본적인 차이에서 비롯된다. 이 변동성은 데이터에 포함된 랜덤한 오차나 잡음으로, 모델이 학습을 통해 극복할 수 없는 요소이다.
OLS Matrix From
-
다중 선형 회귀 모델은 아래와 같이 표현 가능하다
종속 변수의 벡터 Y, 독립변수의 행렬 X, 회귀 계수의 벡터 W는 다음과 같다
-
선형 회귀 모델은 로 표현 가능하다
-
OLS의 목표는 의 제곱합을 최소화하여 의 추정값을 알아내는 것이다
를 전개(1)하고 편미분(2)해 0이 되는 값이 의 제곱합의 최솟값이 된다
(2)를 에 대해 정리해준다
- 위에서 구한 W는 다음과 같은 특징을 갖는다
- 유일성: OLS 해는 로 표현되며, 이는 일 경우(역행렬을 가질 경우) 유일하다.
- 시간복잡도 : 의 역행렬을 계산하는 과정이 가장 비용이 크기 때문에 일반적으로 이다.
선형 회귀 : 확률적 접근
-
지금까지 살펴 본 OLS의 경우는 deterministic approach이다. 이번에는 선형 회귀 모델을 probabilistic approach로 살펴보자.
-
probabilistic approach에서는 데이터가 확률 분포에서 발생한다고 가정하고, 이를 기반으로 회귀 계수를 추정한다(=MLE)
-
선형 회귀 모델은 다음과 같이 가정한다
- : 확률적으로 발현된 종속 변수 (scalar)
- : i번째 데이터 포인트의 독립 변수 벡터 (n x 1)
- : 회귀 계수 벡터 (n x 1)
- : 독립적이고 동일하게 분포된(i.i.d.) 정규분포 를 따르는 오차 항 (scalar)
-
이 가정 아래에 가 성립한다
-
MLE를 적용해 주어진 데이터가 관측될 확률을 최대화하는 를 찾는다.
우도함수는 다음과 같다
이므로, 우도함수를 아래와 같이 표현 가능하다
계산의 편의성을 위해 로그 우도 함수를 사용한다
로그 우도 함수를 에 대해 편미분(1)하고, 그 결과를 0으로 설정(2)하면 우도가 최대화 된다
(2)를 에 대해서 정리해준다
-
MLE를 통한 회귀 계수의 추정은 OLS와 동일한 해를 제공한다
선형 회귀의 기하학적 해석
-
우선 간단한 예시(독립 변수 2개, , 절편 = 0)인 를 생각해보자
-
종속 변수 를 의 선형 결합으로 표현하는 것은 를 ()가 형성하는 평면의 한 점으로 나타낸다는 의미이다.
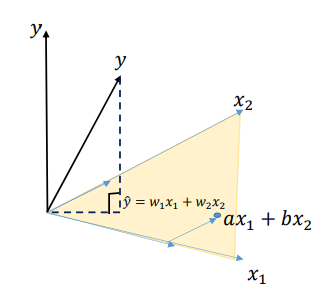
-
이는 3차원 벡터 를 의 Column Space로 투영하여 를 구하는 것과 동일하다. 이때 는 와 가 직교하도록 해주는 벡터이다.
-
선형 회귀의 기하학적 해석을 일반화(데이터 row수 m, 독립변수 n개)하면 다음과 같다
- 공간의 벡터 를 공간의 에 최소 거리로 투영(최소 오차 근사)한 벡터 을 구하는 것.
- 이때, 이고, 는 잔차 벡터 가 와 직교하도록 하는 회귀 계수 벡터이다.
-
를 구하는 과정은 아래와 같다
와 잔차 벡터가 직교해야 하므로 의 기저인 (과 잔차 벡터가 모두 직교해야 한다
위 식을 전개하고 에 대해 정리해준다
-
기하학적 해석 또한 동일한 해를 제공한다.
회귀계수의 형태
-
마지막으로 MSE/MLE/기하학적 해석을 통해 구한 회귀계수의 해를 풀면 어떤 형태인지 확인해보자
-
독립변수가 2개인 간단한 예시에서 시작해보자
에 (1), (2)의 값을 대입한다
공분산, 분산식을 사용해 위 행렬을 변환한다
행렬곱을 풀어 주면 (a), (b), (c)의 식을 얻을 수 있다
-
(a), (b), (c)를 사용하여 값을 찾아보자
-
정리하자면, 독립변수가 2개인 경우 회귀계수 는 아래와 같다.
-
회귀계수 는 이 에 미치는 직접적인 영향()을 나타내야한다. 독립변수 사이에 선형적인 상관관계가 있을 경우 가 에 영향을 미치게 된다. 즉, 인 경우 가 에 영향을 주어 에 미치는 간접적인 영향()을 제거해야 우리가 필요로 하는 을 정확하게 구할 수 있다. 이를 반영한 회귀계수가 위에서 정리한 이다.
-
마찬가지로, 독립 변수가 n개인 경우 i번째 회귀 계수를 구할 때 를 제외한 나머지 독립 변수들의 영향을 모두 제거해준다.
-
독립변수 사이에 선형적인 상관관계가 없을 경우 이고, 회귀 계수들은 단일 선형 회귀의 그것과 같아진다
