선형회귀분석 프로젝트 : 보험 청구료 예측을 통한 보험금 책정
-
24.08.26 ~ 24.09.16(총 2주)까지 스터디에서 진행한 프로젝트에 대한 회고록이다.
-
사용 데이터는 kaggle의 Medical Cost Personal Datasets이다.
-
자세한 코드 및 발표자료는 github에 정리되어 있다.
-
프로젝트를 진행한 과정을 간략하게 살펴보며 배운점, 개선점, 피드백을 확인해보자.
데이터 확인 및 cleansing
-
컬럼별로 특징을 확인한다.
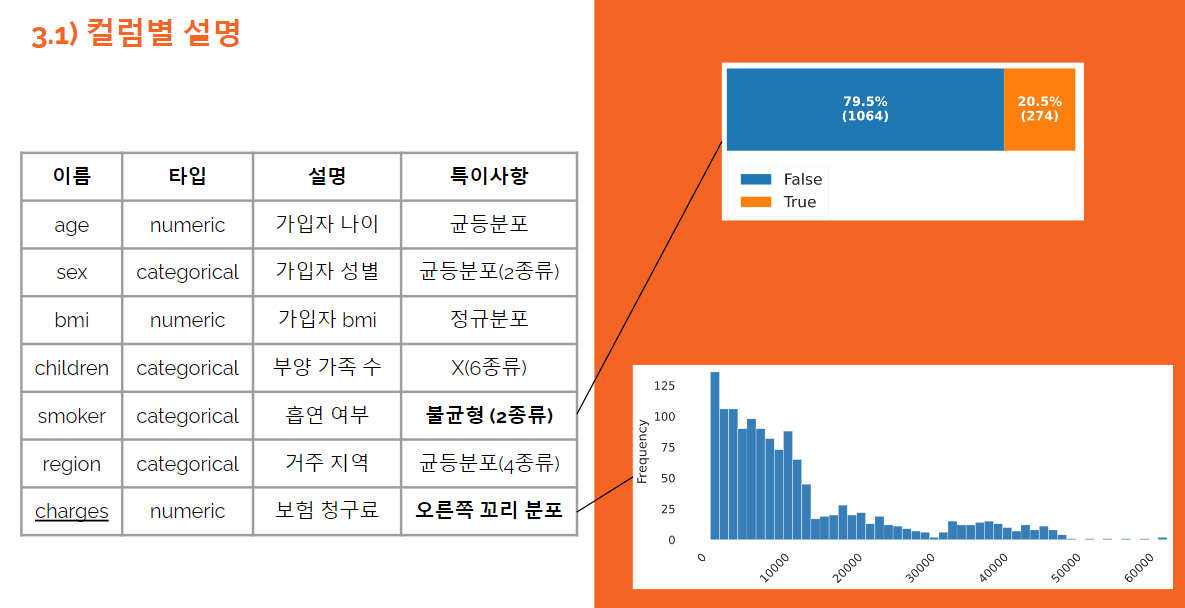
-
중복 컬럼은 전산상 오류로 가정하여 삭제.
-
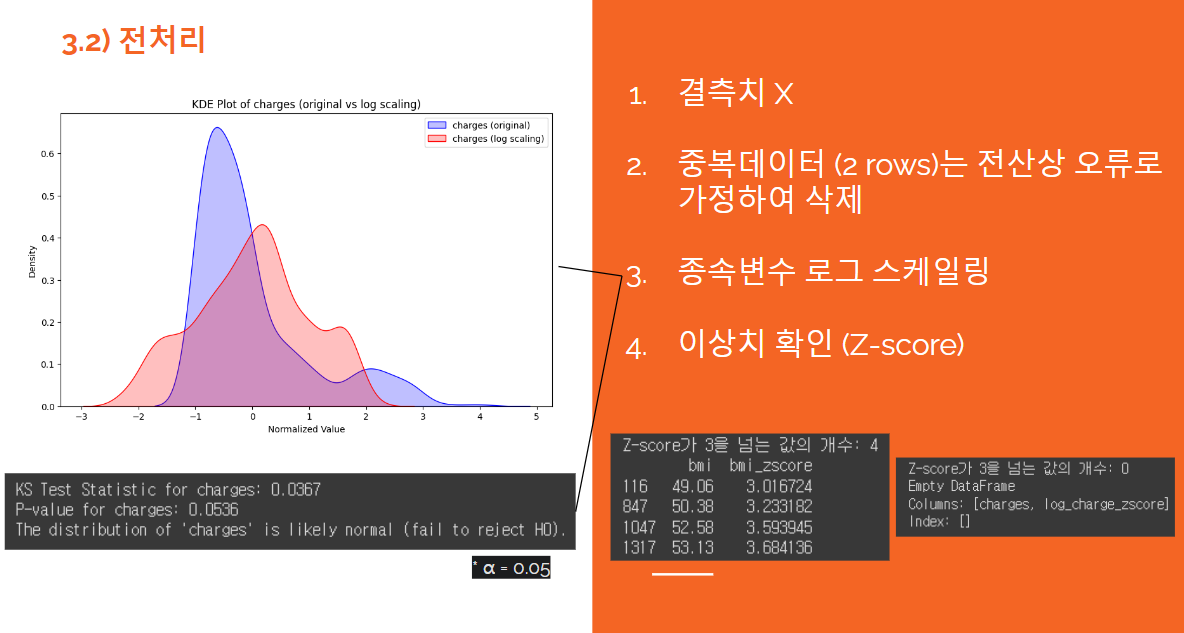
종속변수인 charges의 경우 로그스케일링 후 KS-정규성 테스트를 통과했다.
- 배운점 : 종속변수가 정규성을 갖는 것은 매우 중요하다. 이는 회귀 분석의 가정 중 하나로, ANOVA나 모수 추정 기법과 같은 통계적 분석 방법을 신뢰성 있게 사용할 수 있게 한다. 또한, 종속변수가 정규성을 가지면 오차의 분포가 정규성을 가질 가능성이 높아지고, 오차의 등분산성 가정을 만족할 가능성도 높아진다. 이러한 이유로, 종속변수의 정규성은 모델의 정확도와 신뢰도를 높이는 데 중요한 역할을 한다
-
이상치의 경우 Z-score를 사용하여 간단하게 판별했다. 이상치가 없거나 수가 작아 따로 처리하지 않고 분석을 진행했다.
simple linear regression
-
선형회귀로 회귀계수들을 확인해봤다. 이때, children에 대해서는 label encoding, region에 대해서는 binary encoding을 진행했다.
-
smoker, region_0, children의 회귀계수가 상대적으로 큰 것을 확인.
-
binary encoding이 진행된 region에 대해 region_0과 region_1~region_2에 대해 강한 상관(Crammer's V 값이 0.6에 가까움)이 확인되어, 인코딩 방식을 바꿀 필요성을 느꼈음.
독립변수와 종속변수의 관계 확인
-
BMI의 경우 종속변수와 선형관계가 없었다. WHO가 제공하는 범주로 나누어 Kruskal-Wallis H Test를 진행해 봤다.
-
배운점 : 연속형 데이터를 범주로 나누는 경우 정보손실이나 변형의 정도를 확인해야 한다. 이때, 엔트로피를 사용할 수 있다.
-
개선점 : 종속변수가 정규성이 확보되었다. 범주별 종속변수의 분포는 정규분포에서 추출한 표본이므로 정규성을 갖는다. 따라서 등분산성을 확인해 보고 one-way ANOVA를 진행하는 것도 좋을 것 같다.
-
-
age의 경우 산점도를 확인해 봤을 때 종속변수와 선형관계가 3종류의 범주로 나눠져 있다고 판단했다.
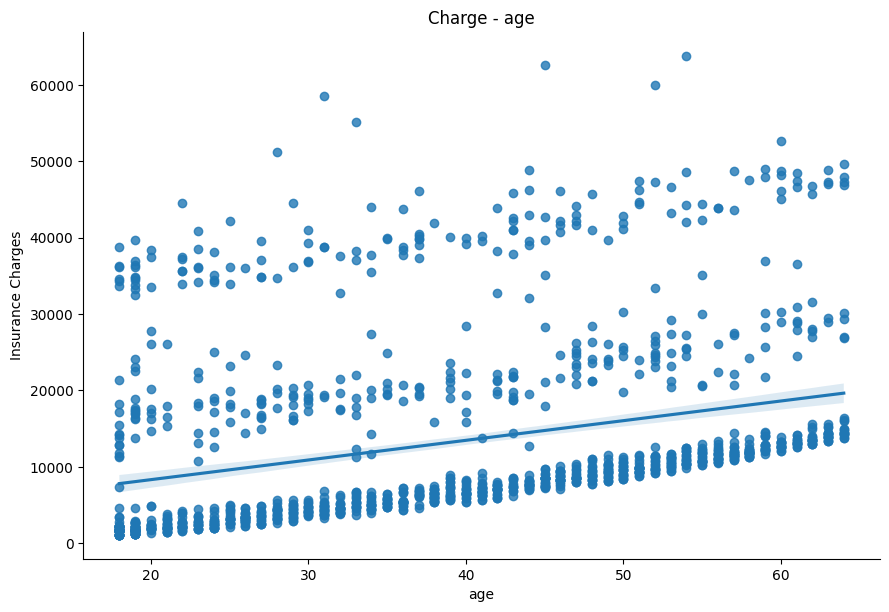
- 세개의 범주를 k-means clustering 후 기준을 확인한 결과, bmi와 smoker를 기준으로 나눠 볼 수 있었다.
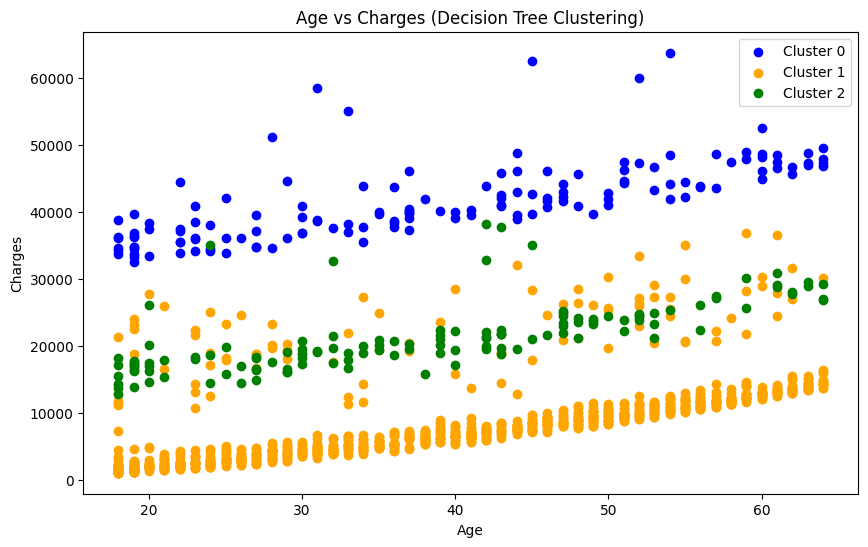

-
피드백 : 군집화가 처음 상상한 것과 같이 완벽하게 진행되지 않아 독립변수들이 선형 군집에 대해 충분한 설명력을 제공하지 못한다고 판단하였다. 따라서, 군집에 따라 다른 회귀직선을 만드는 내용은 폐기하려고 했지만, 불완전하더라도 세개의 회귀직선을 만들어 보고 발표를 해보라고 하셨다.
-
배운점 : 생성된 군집이 불만족스러워서 k-means clustering이 아닌, 선형 군집화에 적합한 다른 방법들을 찾아봤다. 해당 프로젝트에서는 k-means와 크게 다를 것이 없어 이들을 사용하는 것은 폐기했다.
키워드 : GMM, Spectral Clustering (with Linear Kernel).
사용 모델 및 metric
-
보험사의 입장에서 생각해 볼 때, 예측값(charges)이 실제보다 낮게 나오는 경우는 보험금(premium)을 과소 책정하게 되어 재정적 손실로 이어질 수 있다. 반면, 예측값이 실제보다 높게 나오는 경우는 보험료를 과대 책정하여 손실을 방지할 수 있어, 실무적으로 유리할 수 있다.
-
따라서 custom MSE를 정의하여, 이를 손실함수로 사용하는 경사하강법과 전통적인 MSE를 손실함수로 사용하는 OLS, Lasso, Ridge 방식을 모두 적용해 비교해 보았다.
def asymmetric_loss(y_true, y_pred):
# 과소평가 시 2배 페널티, 과대평가 시 일반 페널티 적용
loss = tf.where(y_pred < y_true,
2 * tf.square(y_true - y_pred), # 과소평가 시 2배 페널티
tf.square(y_pred - y_true)) # 과대평가 시 일반 페널티
return tf.reduce_mean(loss)-
배운점 : custom MSE와 비슷한 평가지표를 찾아보다가 pinball loss라는 지표에 대해 알게 되었고, quantile regression에 대해 알게 되었다. 프로젝트를 보완하며 더 자세한 내용을 찾아보도록 하자.
키워드 : pinball loss, quantile regression. -
피드백 : 경사하강법을 사용할때는 독립변수들을 항상 같은 스케일로 맞춰야한다.
경사하강법은 각 피처(feature)의 기울기(gradient)를 계산하여 가중치를 업데이트한다. 피처의 스케일이 다르면 각 피처가 모델 학습에 주는 영향이 다르게 된다. 큰 값의 피처는 작은 값의 피처보다 더 큰 기울기를 만들어내므로 경사하강법이 큰 값의 피처에 더 집중하게 되고, 학습 과정이 비효율적이거나 비정상적으로 느려질 수 있습다.
feature 사용 방법
-
region
-
simple linear regression을 진행했을 당시 binary encoding을 진행한 region은 결과의 해석이 어려우며 인코딩된 값에 대한 높은 상관계수가 크다는 문제가 있었다.
-
region은 총 네가지 [southeast, southwest, northeast, northwest]의 범주로 이루어져있기 때문에, 'south', 'west'라는 컬럼을 추가하여 binary encoding을 진행하여 해석의 용의성을 높이고 상관계수는 줄일 수 있었다.

-
-
children
-
원본데이터에 있는 그대로 label encoding을 사용한다.
-
피드백 : 선형회귀모델에서 독립변수와 종속변수 간에 선형 관계가 중요하다. "children"이라는 범주형 변수가 종속변수와 선형관계가 없다면 라벨 인코딩처럼 선형적인 관계를 암시하는 인코딩 방식은 적합하지 않을 수 있다. 원핫인코딩, 이진인코딩과 같은 선형성이 암시되지 않은 방식을 사용하는 것이 성능적, 분석적 측면에서 유리하다
-
-
smoker
-
종속변수와 가장 큰 상관계수를 가진 독립변수이지만, 클라스 불균형 문제가 있어 이를 해결하는 방법에 대해 알아보았다.
-
배운점 : 대부분의 상황에서 독립변수의 클래스 불균형은 크게 신경쓰지 않아도 된다. 꼭 문제를 꼭 해결해야하는 경우(매우 드문 값이 중요한 예측 인자를 가지고 있지만, 그 값을 충분히 학습하지 못하는 경우)에는 데이터의 크기를 직접 조정하는 방식(over/under sampling)이 아닌 피처 엔지니어링으로 해결할 수 있다.
-
유사한 카테고리를 합치기 : 유사한 특성을 가진 다른 범주들과 합쳐서 새로운 카테고리로 만들기
-
rare categroy encoding : 희귀한 몇개의 카테고리를 하나의 "Rare" 카테고리로 묶어주기
-
target encoding : 범주형 변수의 값에 대해 종속변수와의 관계를 반영한 숫자로 변환하는 방법으로, 클래스 불균형 문제를 해결하는 데 도움이 될 수 있습니다.
-
-
모델 구축 및 평가
- 다양한 방법을 시도했지만, 군집에 따른 세가지 최고 성능 회귀직선에 대해서만 첨부한다.
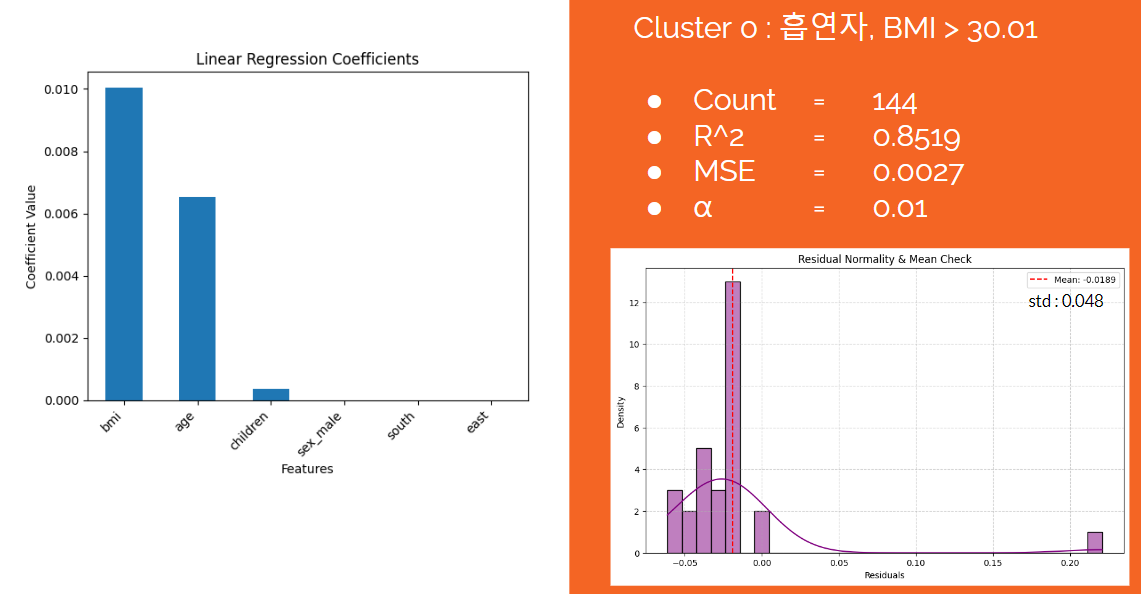
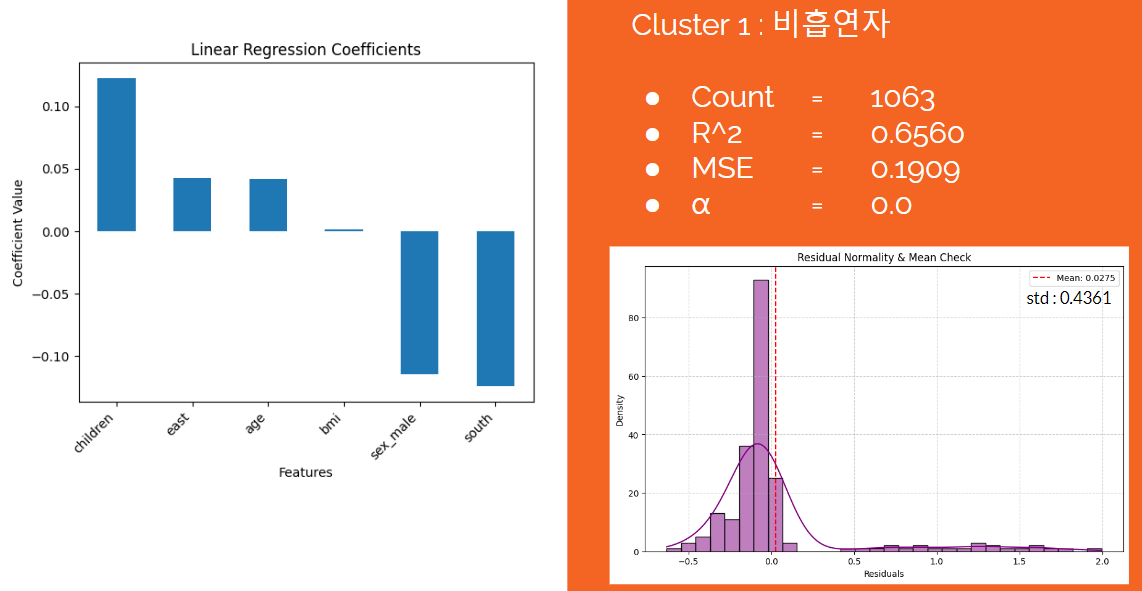

-
개선점 : 모든 군집의 회귀직선에 대해 잔차의 분포가 정규분포를 따르지 않았다. 이는 선형회귀 결과에 대한 신뢰도가 떨어진다는 뜻이다. 잔차의 정규성을 확보하는 방법들을 적용해 신뢰성 있는 해석 결과를 얻는 것이 중요하다.
-
변수 변환 : Box-Cox, 로그 변환, 제곱근 변환
-
비선형 모델 사용
-
아웃라이어 제거
-
강건 회귀 사용
-
결론 : 보험금 책정

-
모든 보험금 책정 식은 회귀 식을 기반으로 하고 있으나, 보험사에서 이익이 있어야 하기 때문에 영업이익인 EBTI를 추가한다.
-
건강 고위험군의 경우 예측 변동성이 매우 작고, 약한 과대평가를 하기 때문에 보험금 책정을 기본 회귀식으로 설정해도 손해가 날 가능성이 적다. 또한, 베이스 금액이 타 segment에 비해 월등히 높다는 특징이 있기 때문에 EBTI를 높게 설정할 경우 가입자가 부담을 느낄 수 있다. 따라서, 건강 고위험군은 영업이익을 가장 낮게 설정하여 타 보험사에 비해 가격적으로 부담이 없도록 하는, 박리다매의 형식으로 영업이익을 취해야한다.
-
건강 위험군의 경우 예측 변동성이 작고, 강한 과대평가를 한다. 건강 고위험군과 비슷한 특징을 가지고 있어 박리다매 형식을 적용해야 하지만, 베이스 금액이 높지 않아 건강 고위험군의 영업이익보다 높게 설정하여도 가입자들의 부담이 적을 것으로 예상된다.
-
일반 가입자는 가장 많지만, 회귀식이 청구비용을 과소평가를 하는 경향이 있다. 과소평가를 하는 것은 보험사의 손해와 직결될 가능성이 높다. 또한, 예측의 변동성이 높기 때문에 최악의 경우를 가정하고 충분히 큰 EBTI를 설정해야 합니다. EBTI를 크게 설정하여도 베이스 금액이 낮기 때문에 보험 가입자는 큰 부담을 느끼지 않을 것이다.
-
피드백 : 발표의 흐름이 매끄럽지 않다. "내가 이렇게 저렇게 시도해 봤다"를 얘기하기 보다 결론을 중심으로 잡고 관련된 핵심 내용만 설명하는 것이 좋다.
느낀점
-
지금까지 선형회귀분석의 기초도 모르는 상태로 대충하고 있었다는 생각이 들었다.
-
배운점, 개선점, 피드백을 반영하여 프로젝트 내용을 개선해보자.
