Neurons
-
뉴런은 신경계의 기본 단위로, 우리 뇌와 신경 시스템의 정보 처리와 전달을 담당한다.
-
뉴런의 구조
-
수상돌기 : 다른 뉴런이나 외부로부터 전기적 신호를 받아들이는 부분이다. 수상돌기는 여러 신호를 받아들이며, 이를 뉴런의 세포체로 전달한다
-
세포체 : 수상돌기를 통해 받아들인 전기적 신호의 합을 처리한다. 세포체에서 입력 신호의 총합이 특정 임계값을 넘을 경우 활성화되어 축삭을 통해 신호가 전달된다.
-
축삭 : 세포체에서 처리된 신호를 다른 뉴런이나 근육 세포로 전달하는 출력 경로이다.
-
Neurons and Perceptron (binary classification)
- Perceptron은 생물학적 뉴런의 특성을 수학적으로 모델링하여 기계 학습에 사용할 수 있도록 만들어진 방법론이다. 인공 신경망(Artificail Neural Network, ANN)과 머신러닝의 기초가 되는 개념으로 이진 분류 문제를 해결하는 데 사용되는 가장 기본적인 단위이다.
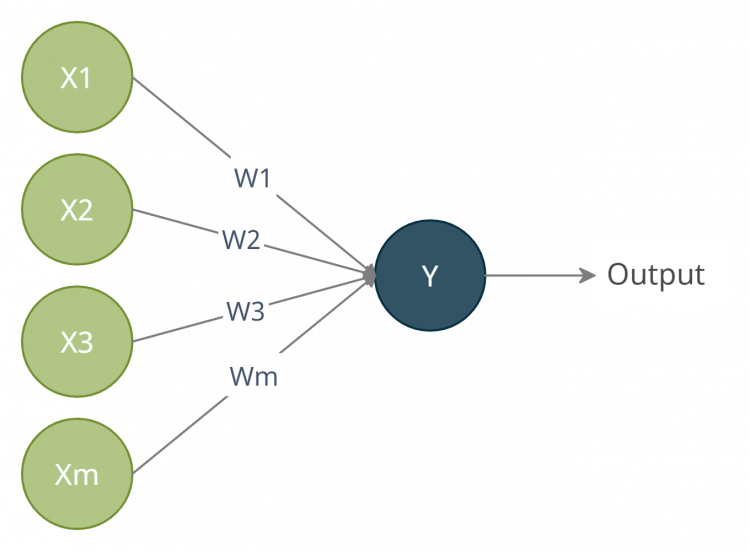
- 뉴런의 구조와 Perceptron의 비교
| 뉴런 | 상응하는 Perceptron 요소 | 설명 |
|---|---|---|
| 수상돌기 | 수상돌기가 외부로부터 신호를 받아들이듯, Perceptron은 여러 피처를 받아들인다 | |
| 세포체 | 세포체가 신호의 합을 처리하듯, Perceptron은 입력의 가중합을 구한다 | |
| 활성화 | 입력 신호의 합이 임계값을 넘을 때 활성화되듯, Perceptron은 활성화 함수를 사용하여 가중합이 임계값을 넘는지를 판단한다 | |
| 축삭 | 이진 분류 결과 | 축삭이 신호를 전달하듯, Perceptron은 활성화 함수의 결과를 클라스(0,1)로 출력한다 |
Perceptron의 수학적 표현
-
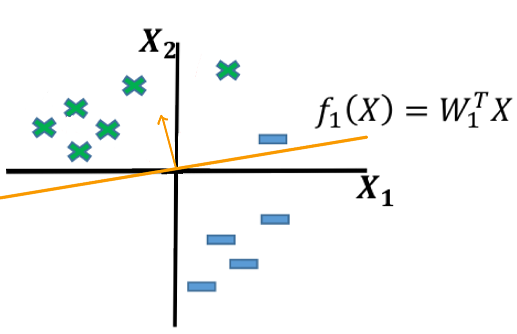
간단한 예시로 축 위에서 기울기가 이며 원점을 지나는 직선을 가정해 보자. 이때 직선의 방정식은 다음과 같다
우변을 좌변으로 옮기면 다음과 같다
위 식은 기울기 벡터()와 피처 벡터()의 내적으로 나타낼 수 있다
결국, 이 성립하기 때문에 와 는 서로 직교하는 관계이다. 분류 직선이 피처 벡터가 투영되는 공간에서 직각을 형성하며, 이로 인해 직선이 피처 공간을 두 개의 영역으로 나누게 된다.
이때 피처 벡터()는 주어진 데이터에서 고정된 값이며, 가변 가능한 값은 기울기 벡터()이다. 따라서, Perceptron에서는 기울기 벡터를 조정하여 데이터를 잘 분류할 수 있는 분류 직선을 찾아낸다.
분류 방법
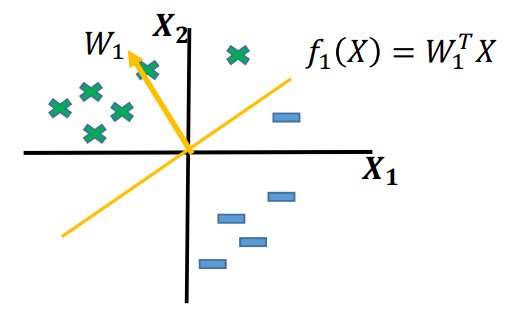
- 아래 그림에서 X로 표현된 점은 클라스 1, -로 표현된 점은 클라스 0이라고 하자. 이때, 클라스 1은 분류 직선의 위쪽에, 클라스 0은 분류 직선의 아래쪽에 위치한다.
-
분류 직선보다 위쪽에 있는 데이터 포인트, 즉 기울기 벡터와 같은 방향을 갖는 데이터 포인트를 분류 직선의 식에 대입하면 양의 값이 나오고, 아래에 있는 데이터 포인트를 대입하면 음의 값이 나온다.
- 간단하게 생각해 보자. 보다 위쪽에 있는 점 (0, 1)을 대입하면 양수, 아래쪽에 있는 점 (1, 0)을 대입하면 음수가 나온다. 이를 통해 직선의 위쪽과 아래쪽에서 결과 값이 어떻게 달라지는지 직관적으로 이해할 수 있다.
-
이와 같이 Perceptron에서 데이터를 분류 할 때 데이터 포인트의 값을 분류 직선()에 대입하고, 해당 값()이 0보다 크면 클라스 1, 0보다 작다면 클라스 0으로 분류한다.
기울기 벡터를 수정하는 방법 (가중치 학습 방법)
-
기울기 벡터를 수정하는 방법은 오분류의 종류에 따라 두가지로 나눠서 생각할 수 있다
-
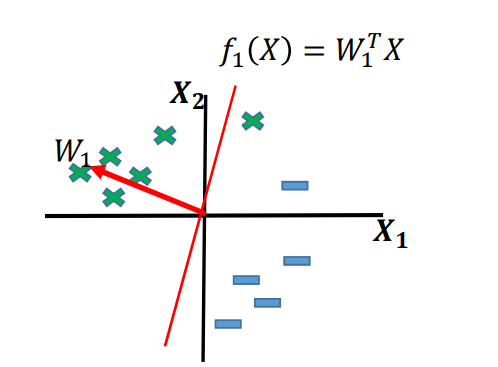
오분류 1) 분류 직선보다 위쪽에 있는 점이 아래쪽으로 잘못 분류된 경우 ()
- 기울기 벡터에 오분류된 벡터를 더하면 분류 직선이 시계방향(CW)으로 회전하게 된다. 적절한 시계방향 회전을 통해 오분류된 데이터를 올바르게 분류할 수 있다.
-
오분류 2) 분류 직선보다 아래쪽에 있는 점이 위쪽으로 잘못 분류된 경우 ()
- 기울기 벡터에 오분류 벡터를 빼면 분류 직선이 반시계방향(CCW)으로 회전하게 된다. 적절한 반시계방향 회전을 통해 오분류된 데이터를 올바르게 분류할 수 있다.
-
기본적인 원리는 위와 같지만, 예시처럼 분류 직선으로 데이터를 완전하게 나눌 수 있는 경우는 매우 한정적이며, "적절한 회전"의 크기를 특정하는 것도 어렵다. 따라서 Perceptron에서는 1회 당 회전 정도(학습률)를 사전에 설정하고, 반복적으로 기울기 벡터를 수정하는 학습 방법을 사용한다. 이를 수식으로 나타내면 아래와 같다.
-
: i번째 반복에서의 기울기 벡터
-
: 1회 당 회전 정도 (=learning rate)
-
: i번째 데이터 포인트 벡터
-
: 기울기 벡터 회전 방법
- : 정확하게 분류한 데이터 포인트. 회전 하지 않음
- : 오분류 1)의 경우. 를 더해준다 (CW회전)
- : 오분류 2)의 경우. 를 빼준다 (CCW회전)
-
절편의 학습
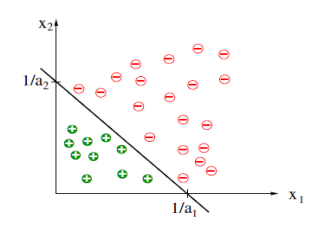
- 지금까지는 원점을 지나는 분류 직선에 대해서 살펴보았지만, 실제 데이터는 원점을 기준으로 대칭적으로 분포하지 않아 절편(bias)이 있어야만 데이터를 올바르게 분류할 수 있는 경우가 많다.
-
Perceptron의 절편은 결정 경계가 원점에 대칭되지 않는 경우에 분류 직선을 상하로 이동시켜 최적 결정 경계를 형성한다.
-
절편도 가중치와 마찬가지로 학습 과정에서 수정되며, 기본적인 원리는 기울기 벡터의 학습방법과 같다.
-
: 절편 (bias)
-
: 1회당 절편 수정 정도 (=learning rate)
-
: 절편 수정 방법
- : 정확하게 분류한 데이터 포인트. 절편을 수정하지 않음
- : 오분류 1)의 경우. 분류 직선을 위쪽으로 이동한다
- : 오분류 2)의 경우. 분류 직선을 아래쪽으로 이동한다
-
Perceptron의 한계
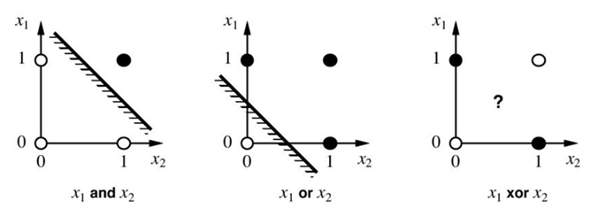
- 비선형 구조 학습 불가 : Perceptron은 선형적으로 분리 가능한 문제만 해결할 수 있기 때문에, XOR 문제처럼 비선형적으로 분리되는 데이터를 학습할 수 없다. 이를 해결하기 위해서는 비선형 활성화 함수(ReLU, Sigmoid 등)를 사용하는 다층 구조(MLP)가 필요하다.
-
학습 속도의 한계 : Perceptron은 단순히 오분류된 데이터에 따라 가중치를 조정하는 방식이기 때문에 데이터의 차원이 높아질수록 적절한 결정 경계를 찾기 위한 반복 횟수가 크게 증가하여 학습 속도가 매우 느려질 수 있다.
-
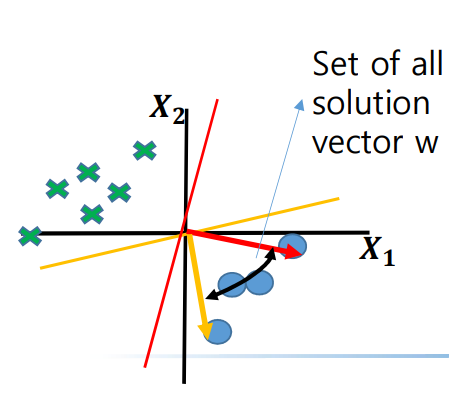
일반화 성능의 한계 : Perceptron은 선형 분리 가능한 데이터셋에 대해 적절한 결정 경계를 찾을 때까지 반복 학습을 진행하며, 오분류가 없을 때 학습을 종료한다. 동일한 데이터셋에 대해 여러 종류의 분류 직선이 선형적으로 데이터를 나눌 수 있지만, Perceptron이 어떤 결정 경계를 학습할지는 학습 과정과 학습 데이터의 순서에 따라 다를 수 있다. 이로 인해 Perceptron이 학습한 결정 경계는 학습 데이터에는 적합하더라도 새로운 데이터에 대한 일반화 성능이 떨어질 위험이 있다.
-
일반화 성능 개선 방법
-
정규화 : 가중치의 크기를 제한하는 정규화 기법을 도입하면 결정 경계가 지나치게 넓어지는 문제를 방지할 수 있다. 이는 모델이 데이터에 과도하게 적합하지 않도록 하여 일반화 성능을 향상시킨다.
-
SVM(Support Vector Machine) : Perceptron과 유사한 방식으로 선형 결정 경계를 학습하지만, 마진(결정 경계와 데이터 포인트 간의 거리)을 최대화하여 결정 경계를 최적화한다. 이를 통해 가장 안정적인 결정 경계를 선택하고, Perceptron보다 새로운 데이터에 대해 더 강건한 모델을 제공한다.
-
데이터 셔플링 및 교차 검증 : Perceptron의 결정 경계는 학습 데이터의 순서에 민감하기 때문에, 학습 전에 데이터를 셔플링하여 다양한 결정 경계를 학습하도록 도와줄 수 있다. 또한 교차 검증을 통해 모델의 일반화 성능을 확인하고, 데이터의 편향으로 인해 결정 경계가 치우치는 것을 방지할 수 있다.
-
간단한 Perceptron 구현
-
Perceptron의 기본적인 기능들을 간단하게 구현 해 봤다. 전체 코드는 simple perceptron에서 확인 가능하다.
-
구현한 기능은 다음과 같다.
-
기본적인 perceptron 학습 과정
-
interval : 출력 주기 설정
-
random_state : 가중치 초기화 옵션. 0으로 초기화할지, 작은 랜덤 값으로 초기화할 지 결정 가능
-
best_weights : accuracy를 기준으로 최고 성능의 가중치를 저장
-
- 두가지 테스트 케이스를 통해 구현한 Perceptron의 결과를 살펴보자.
Test Case 1
- test data : 깔끔하게 선형 분리를 할 수 있는 데이터로, 100%의 accuracy를 기대해 볼 수 있다.
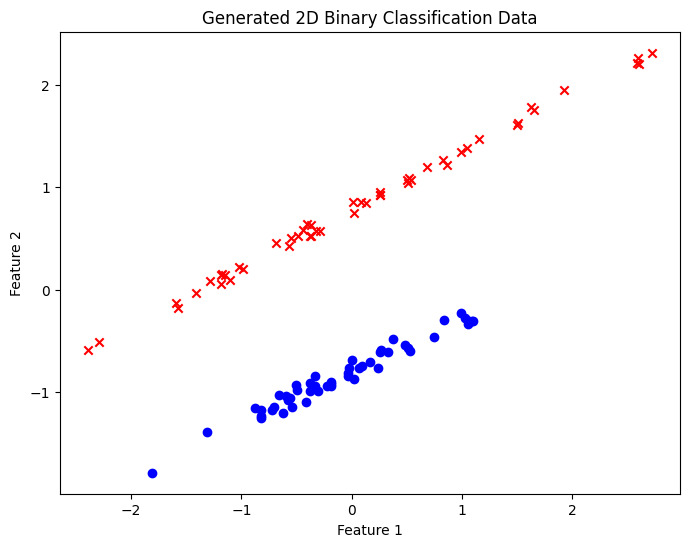
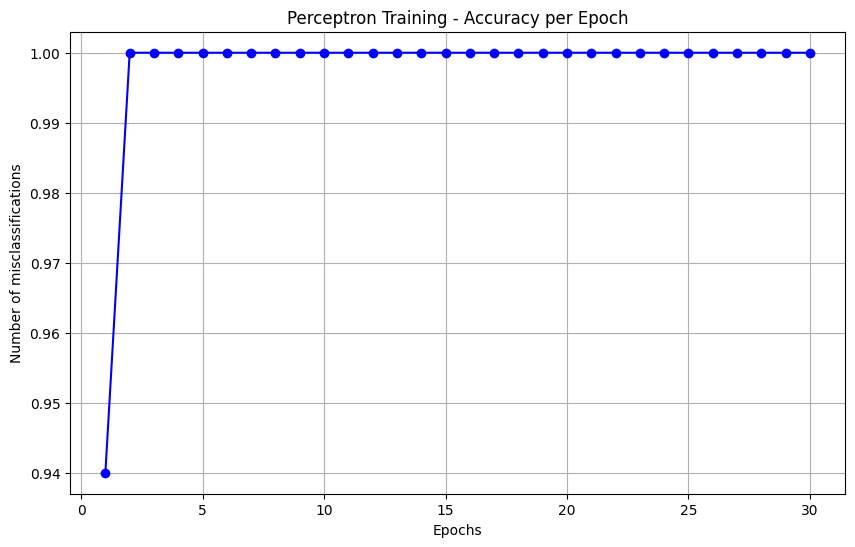
- 빠르게 최적 결정 경계가 결정되며, 이후 오분류된 데이터가 없기 때문에 결정 경계의 변화가 없다.
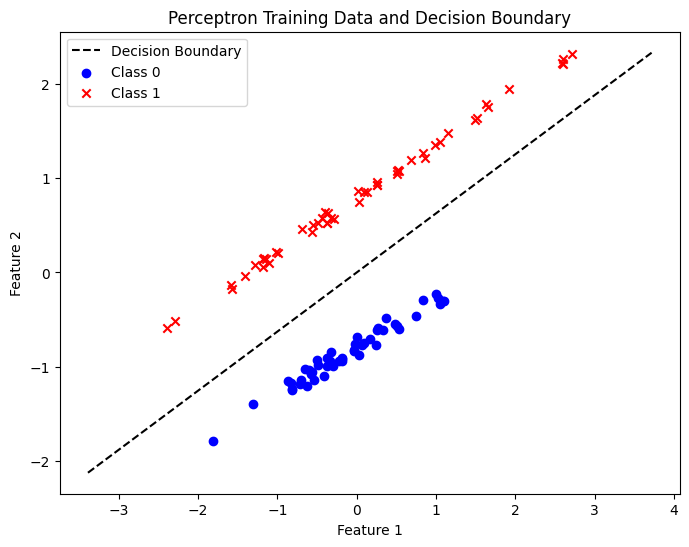
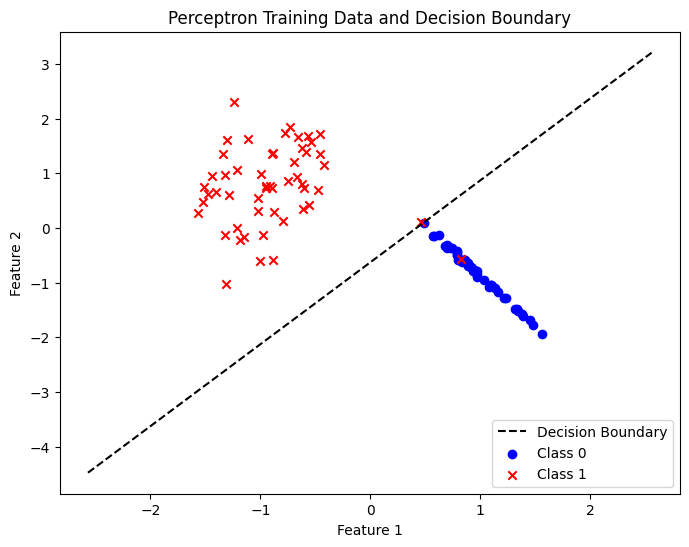
- 결정 경계가 두 클라스를 잘 분류하는 모습을 확인할 수 있다
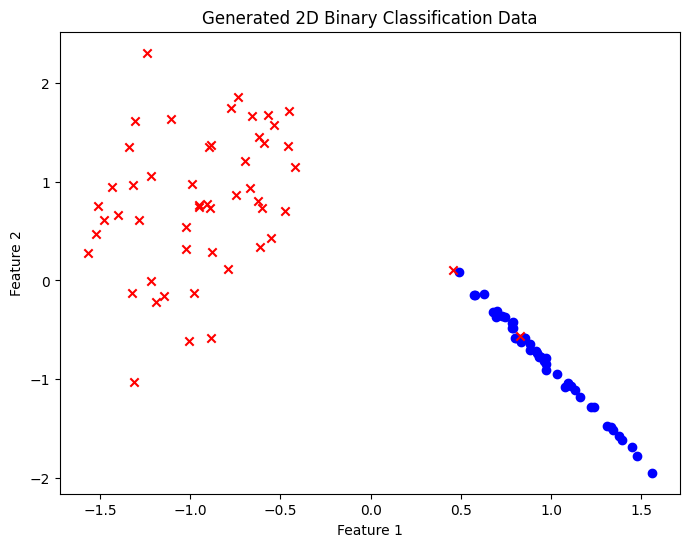
Test Case 2
- test data : 빨간 x로 표시된 클라스 2개가 오분류되어 있는 모습을 통해 perceptron으로는 최대 98%의 accuracy를 기대해 볼 수 있다.
- 선형 분류가 불가능한 데이터 포인트가 몇개 있어, 학습을 진행함에 따라 accuracy가 떨어지는 구간을 확인할 수 있다.
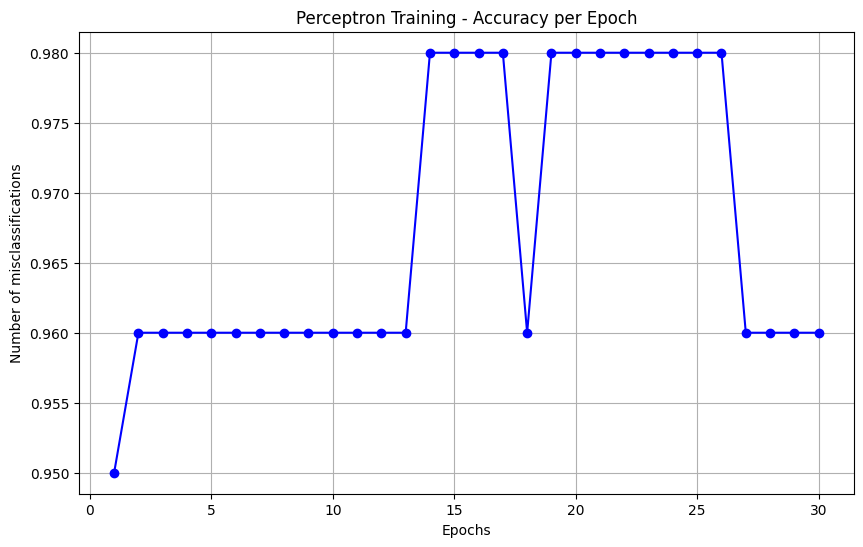
- 처음에 기대한 98%의 accuracy를 갖는 best_weights를 통해 결정 경계를 구하면 아래와 같다
이미지 출처
