기본 활성화 함수 정리
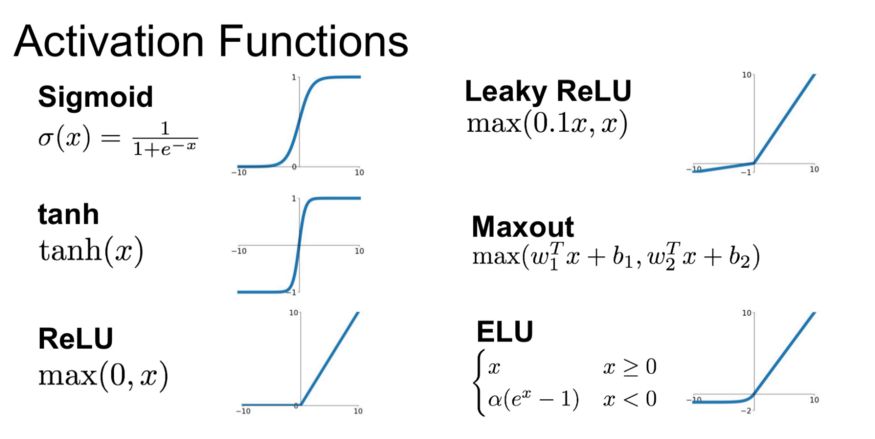
| 활성화 함수 | 주요 활용처 | 함수 원형 | 계산 비용 | Vanishing Gradient | Exploding Gradient | 미분 가능성 | Output Centering |
|---|---|---|---|---|---|---|---|
| Sigmoid | 이진 분류 출력층 | 낮음 | 높음 | 낮음 | 전 구간 | 중심화 안 됨 | |
| ReLU | 은닉층 | 매우 낮음 | 낮음 | 낮음 | x=0 제외 | 중심화 안 됨 | |
| Leaky ReLU | Dying ReLU 해결 | ) | 낮음 | 낮음 | 낮음 | x=0 제외 | 중심화 안 됨 |
| ELU | Smooth 학습 필요 시 | 중간 | 낮음 | 낮음 | 전 구간 | 중심화 | |
| Tanh | 연속 값 예측 | 중간 | 높음 | 낮음 | 전 구간 | 중심화 | |
| Softmax | 다중 클래스 분류 출력층 | 중간 | 없음 | 낮음 | 전 구간 | 중심화 안 됨 |
Gradient Flow
- 역전파(Backpropagation) 과정에서 Gradient(기울기)가 네트워크의 각 층을 통해 원활하게 전달되는 상태를 의미한다.
- 활성화 함수에 대한 모든 논의는 Gradient Flow를 원활하게 유지하기 위한 다양한 문제 해결 방안을 다루는 데 초점이 맞춰져 있다.
-
Vanishing Gradient
-
네트워크의 가중치 값이 적당하다고 가정할 때, 활성화 함수의 미분값이 지나치게 작아지면서 역전파 과정에서 특정 뉴런의 기울기가 0에 가까워지는 현상(Gradient Saturation)
-
특정 뉴런의 가중치가 사실상 고정되어 학습에 기여하지 않음(Dead Neuron과 유사)
-
학습 속도가 매우 느려지고, 최적화가 어렵거나 불가능
-
학습 과정에서 지역 최소점(Local Minima) 또는 평평한 지역(Plateau)에 빠질 가능성이 높아짐
-
-
Exploding Gradient
-
네트워크의 가중치 값이 적당하다고 가정할 때, 활성화 함수의 출력값이 지나치게 커져 역전파 과정에서 기울기가 폭발적으로 커지는 현상 (출력 범위)
-
모델이 최적화되지 않고, 전역 최소점(Global Minimum) 주변에서 진동
-
손실 함수 값이 발산하거나, 수렴하더라도 잘못된 방향으로 수렴할 가능성이 큼
-
-
Output Centering
-
활성화 함수가 자체적으로 출력값의 평균을 0에 가깝게 조정할 수 있는지 여부
-
안정적인 학습을 위해 중요하며, 자체적으로 Output Centering이 이루어지지 않는 활성화 함수의 경우 Batch Normalization과 같은 정규화 기법을 활용해야 한다
-
- NOTE) 기본 활성화 함수의 한계점을 보안하거나, 더욱 복잡한 패턴을 학습하기 위해 Swish, Mish, GELU, Maxout과 같은 발전된 활성화 함수도 존재한다.
ReLU, Leaky ReLU, ELU
-
ReLU는 간단하면서도 계산 효율이 뛰어나고, gradient flow 문제를 어느 정도 해결했기 때문에 가장 많이 사용되는 활성화 함수 중 하나지만, 두가지 문제가 남아있다.
-
문제점 1 : Dying ReLU
-
ReLU는 음수 입력에 대해 항상 0을 출력한다.
-
학습 도중 특정 뉴런이 음수 값만 받게 되면, 그 뉴런의 gradient가 0이 되어 업데이트되지 않는 죽은 뉴런(dead neuron) 문제가 발생한다.
-
이로 인해 해당 뉴런은 학습에 더 이상 기여하지 못하며 네트워크의 표현력이 저하 및, 학습 효율이 줄어들 수 있다.
-
해결 방법 : Leaky ReLU
- 음수 입력에 대해 작은 기울기 (α)를 부여하여 뉴런이 완전히 죽지 않도록 만든다.
- 일반적으로 α는 0.01로 설정하지만, 데이터에 따라 조정 가능하다.
-
-
문제점 2 : 미분 가능성 문제
-
ReLU는 에서 미분값이 불연속이므로, 수학적으로 미분 가능하지 않다.
-
뉴런에 정확하게 이 입력으로 들어오는 경우는 매우 드물기 때문에 일반적으로 에서의 미분값을 0으로 처리한다.
-
그러나, 근처의 입력값은 작은 변화로 미분값이 1에서 0으로 (또는 0에서 1로) 급격하게 바뀔 수 있다.
-
이로 인해 뉴런의 활성화 여부가 변경되어 학습 기여 상태가 달라질 수 있지만, 대부분의 경우 실제 학습에서 큰 영향을 미치지 않는다.
-
해결 방법 : ELU(Exponential Linear Unit)
-
영역에서 지수적 변환을 사용해 에서도 미분 가능해진다.
-
또한, 음수 입력에서도 뉴런이 기여하므로 Dying ReLU 문제가 발생하지 않는다.
-
-
Sigmoid
-
Vanishing Gradient의 영향이 적은 얕은 모델(Shallow Network)의 은닉층에서 사용 가능하지만, 대부분의 경우 사용하지 않음.
-
출력값을 확률로 해석할 수 있기 때문에 이진 분류 문제의 출력층에서 주로 사용
-
Multi Class, Multi Label 문제에서 각 클라스에 대한 독립적인 확률 값을 계산하는 문제의 출력층에서도 사용 가능.
tanh
-
출력 중심화로 안정적인 학습 가능
- 출력값이 평균적으로 0에 가까워 역전파 과정에서 편향 업데이트가 안정적으로 이루어짐
-
출력값 범위 확장
- Sigmoid보다 표현력이 뛰어나며, 음수와 양수를 모두 포함하는 데이터에서 유리
-
대체제가 많음
- Vanishing Gradient 및 계산 효율 문제, 그리고 ReLU, GELU, Swish 등의 대체법이 많아 거의 사용하지 않는다
Softmax
-
Multi class, Single Label 문제에서 자주 사용하는 활성화 함수로, 입력값(logit)을 확률값으로 변환하여 각 클래스의 확률 분포를 생성한다.
-
-
3개의 클라스에 대한 변환값 예시는 다음과 같다
데이터 포인트 클라스1 클라스2 클라스3 0 0.2 0.1 0.7 1 0.1 0.8 0.1 2 0.6 0.3 0.1 -
변환값의 범위는 [0,1]이며, 하나의 데이터 포인트에 대한 변환값의 합은 항상 1이다.
-
-
Softmax의 특징
-
확률질량함수(PMF) 모델링
- Softmax는 연속적인 입력값(logit)을 확률값으로 변환하여 이산 확률 분포를 생성하며, 이를 통해 확률 해석이 가능하다.
-
Cross-Entropy Loss
-
Softmax는 보통 Cross-Entropy Loss와 함께 사용한다
클라스 개수
인코딩(OHE)된 실제 레이블
Softmax를 통해 계산된 예측 확률
-
-
상대적인 확률 기반 분류
- 상대적인 크기를 기반으로 확률을 계산하므로, 추가적인 임계치(threshold) 설정이 필요하지 않다
-
재미로 보는 Gradient Flow를 위한 개선안의 역사
1) Sigmoid와 Tanh 시대
- 문제점: Gradient Saturation으로 인해 깊은 신경망에서 학습이 불가능(Vanishing Gradient).
- 교훈:
- 포화 영역(입력값이 극단적인 범위로 가면서 출력값이 특정 값(0)으로 수렴하는 구간)을 줄이는 것이 중요하다.
- 출력 중심화가 학습 속도에 긍정적 영향을 미친다.
2) ReLU의 등장
-
특징:
- 비포화 함수로, Gradient Saturation 문제를 해결.
- 계산량이 적고 Gradient Flow를 잘 유지.
-
문제점:
- Dead Neuron 문제(Dying ReLU) 발생.
- 에서 미분 불가능.
-
교훈:
- Gradient Flow를 유지하려면 음수 영역에서도 기울기를 제공하는 것이 중요하다.
3) Leaky ReLU, PReLU
-
특징:
- 음수 영역에서도 작은 기울기(α)를 부여하여 Dead Neuron 문제를 완화.
-
교훈:
- Dead Neuron 문제를 해결하면서도 계산 효율성을 유지해야 한다.
4) ELU
-
특징:
- 음수 영역에서 지수적 변환을 통해 미분 연속성과 Gradient Flow를 동시에 확보.
- 출력값 중심화로 Batch Normalization 없이도 안정적 학습 가능.
-
문제점:
- 계산량이 증가하여 효율성이 떨어질 수 있음.
-
교훈:
- 출력 중심화와 Gradient Flow의 균형이 중요하다.
5) Swish와 GELU
-
특징
- Swish : ReLU보다 매끄러운 Gradient Flow 제공.
- GELU: 입력값의 확률적 중요성을 반영해 Gradient를 부드럽게 전달.
-
문제점:
-계산량이 ReLU보다 증가.
-
교훈:
- 계산 효율성과 Gradient Flow의 조화를 고려해야 한다.
새로운 활성화 함수를 평가할 수 있는 요소
-
Gradient Flow를 얼마나 잘 유지하는가?
-
Vanishing Gradient와 Dead Neuron 문제를 해결했는가?
-
미분값이 0에 가까워지는 영역이 있는가?
-
-
계산 효율성은 어떠한가?
- 복잡한 계산이 필요한가, 간단한 연산으로 구현 가능한가?
-
출력 중심화 문제를 해결했는가?
- 출력값이 0에 가까운지, 아니면 특정 범위에 치우쳐 있는지 확인.
-
실제 모델에서의 성능은 어떠한가?
- 특정 데이터셋이나 모델 구조에서 유리한가? 보편적으로 사용 가능한가?
