Introduce
다음과 같은 csv 파일이 주어졌을 때 해당 data에서 DeliveryTime을 예측하면 되는 문제입니다.

또한 배달 시간을 예측하는 문제이기 때문에, 예측시간이 실제로 배달을 완료하는 시간보다 빠르면 손님이 만족하지 못 할 것입니다.
여기에서 Column은 Restaurant, Location, Cuisines, AverageCost, MinimumOrder, Rating, Votes, Reviews 가 있습니다.
Summary
데이터 전처리 과정 중 AverageCost와 Rating은 numeric으로 변환하였고, Location은 One Hot Encoding, 그리고 Restaurant와 Cuisines는 이용하지 않고 drop 하였습니다.
이후 RandomForestRegressor, k-fold cross validation, RandomSearchCV를 이용해서 훈련 및 평가를 진행하였습니다.
최종적으로 MSE는 10, MAE는 6이 나왔고 Under Prediction은 26%가 나왔습니다.
데이터 전처리
1. 회귀 데이터 범주로 만들기
deliver["cut_MinimumOrder"] = np.digitize(deliver["MinimumOrder"], bins=[0, 30, 60, 100])
deliver["cut_MinimumOrder"].value_counts()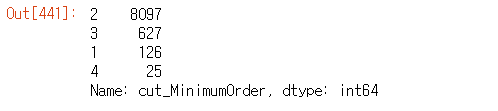
이 column은 다음과 같은 그래프를 가졌었다.
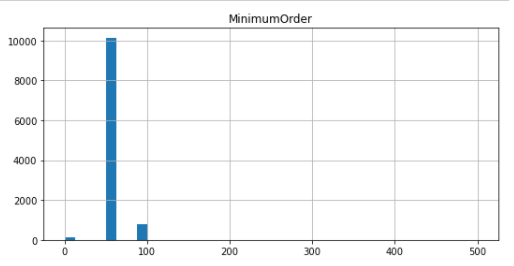
즉, 여러 곳에 값이 분리되어있는 것이 아닌 어떤 구간에 값이 집중되어 있는 것을 알 수 있었다. 따라서, 범위를 0, 30, 60, 100으로 나눴고 총 3개의 구간이 생성되었다.
pd.cut을 이용하지 않은 이유는 해당 Column의 type이 categorical 하게 바뀌면 나중에 column 값 사이의 연산을 진행할 수 없기 때문이다.
2. 새로운 특성 만들기
deliver["votes_per_minimum"] = deliver["Votes"]/deliver["cut_MinimumOrder"] #Good
deliver["votes_per_rating"] = deliver["Votes"]/deliver["Rating"] #Good
deliver["reivews_per_rating"] = deliver["Reviews"]/deliver["Rating"] #Good
deliver["votes_per_average"] = deliver["Votes"]/deliver["AverageCost"] #Good총 4가지의 특성을 새로 만들었는데, 이 4가지를 선정하는 값으로 corr_matrix = deliver.corr()를 이용하였다. Target과 연관성이 높은 것들 4개를 뽑은 것이다.
3. Location One Hot Encoding
총 35개의 Location이 존재해서, 이들은 그냥 One Hot Encoding 시켜버렸다.
왜냐하면 유효한 결과를 추출하기 힘들었기 때문이다. 그래서 새로 Column이 35개가 늘었다.
Transformer PipeLine
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")), #Null 값 대체 (median으로)
('attribs_adder', CombinedAttributesAdder()), #새로운 feature 추가
('std_scaler', StandardScaler()), #표준화
])손실함수와 훈련 모델 선정
1. 손실함수
loss function으로는 Root Mean Square Error를 이용하였다. 여기에서 구해야 하는 값은 배달 시간인데, 그러면 예측한 값과 배달 시간의 차이를 구해야 하는 것이기 때문이다. 다른 손실함수도 있지만 익숙한 것을 쓰기로 했다.
2. 훈련 모델
머신 러닝 회귀 모델 중 가장 뛰어나다고 생각하는 RandomForestRegressor를 이용하였다. 자세한 설명은 다음에 설명하기로 하겠다.
from sklearn.metrics import mean_squared_error
deliver_predictions = forest_reg.predict(deliver_prepared)
forest_mse = mean_squared_error(deliver_target, deliver_predictions)
forest_rmse = np.sqrt(forest_mse)
forest_rmse3. 최적화
모델에서 가장 최적의 estimator와 max_feature을 찾기 위해서 RandomSearchCV를 이용하였다. 코드는 다음과 같다.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {
'n_estimators': randint(low=1, high=200),
'max_features': randint(low=1, high=8),
}
forest_reg = RandomForestRegressor(random_state=42)
rnd_search = RandomizedSearchCV(forest_reg, param_distributions=param_distribs,
n_iter=10, cv=5, scoring='neg_mean_squared_error', random_state=42)
rnd_search.fit(deliver_prepared, deliver_target)평가
평가지표는 위에서 말한 것과 같이 총 3개를 썻는데, 2개는 공식 평가 지표이고 1개는 커스텀한 평가지표이다.
MSE
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)#Root MSE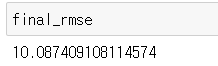
MAE
from sklearn.metrics import mean_absolute_error
final_mae = mean_absolute_error(y_test, final_predictions)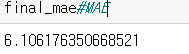
Under Predictions(Custom)
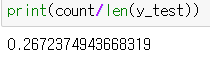
count = 0
for gt, pr in zip(y_test, final_predictions):
if gt > pr:
count += 1