
Jetson Nano 개념 및 구조 Q&A
Q. jetson nano가 뭔가요?
A. 아두이노나 라즈베리 파이 같은 임베디드 컴퓨터 혹은 시스템이라고 말할 수 있다. 아두이노와 다른 점은 우분투와 같은 가상환경을 올릴 수 있다는 점이며, (window도 가능) 임베디드 시스템인데도 불구하고, 작은 nano GPU가 달려있어서 병렬 연산이 가능하다. 작은 컴퓨터임에도 Deep Learning 학습이 가능하기 때문에, 간단한 인공지능 모델을 올릴 수 있다.
Q. jetson nano를 열어보니 많은 device input이 있는데, 각자 어떤 역할을 하나요?
일단 먼저 아래의 사진을 참고하자.

1번은 전원을 연결하는 포트다. 노트북처럼 전원을 연결한다.
2번은 HDMI를 연결하는 포트로, 컴퓨터 모니터 역할을 하게 된다. 여기에 ubuntu가 깔려있으므로, 실제 컴퓨터처럼 코딩이나, 인터넷 접속이 가능하다.
3번은 usb 포트로 마우스, usb 등등 연결이 가능하다.
4번은 이더넷 연결포트로 유선 인터넷을 연결할 때 이용할 수 있다.
5번은 CSI Camera 포트로, USB 카메라를 이용하지 않을 때 CSI 카메라를 연결하려면 이 포트를 위로 열어서 밴드를 넣는다.
6번은 컴퓨터 본체라고 생각하면 된다. 여기에 gpu, cpu, memory 모두 존재한다. 발열이 심하기 때문에 fan을 사는 것을 추천한다. (아니면 아래처럼 선풍기를 옆에 놓자..)

Q. 연결은 어떻게 하나요?
A. 모니터, 마우스, 키보드를 연결하면 컴퓨터처럼 이용할 수 있지만, 없는 경우 원격으로 연결해야 한다. USB와 jetson 보드를 연결하여 해당 선을 HDMI 선, UEFI 선처럼 이용할 수 있다.
Q. Wifi 연결하는 방법을 알려주실 수 있나요?
A. Ubuntu Wifi 연결하는 것과 똑같이 연결하면 된다. 근데 아까 jetson nano의 구조 중 5번에서 2번째 칸에 무선 마우스 같은 usb가 꽂여 있는것을 알 수 있는데, 이는 와이파이 연결을 도와주는 usb이다. 해당 제품을 구입하거나 휴대폰 테더링을 통해서 인터넷에 연결하자.
Q. CSI 카메라를 이용하려 하는데, 연결 상태를 확인할 수 있나요?
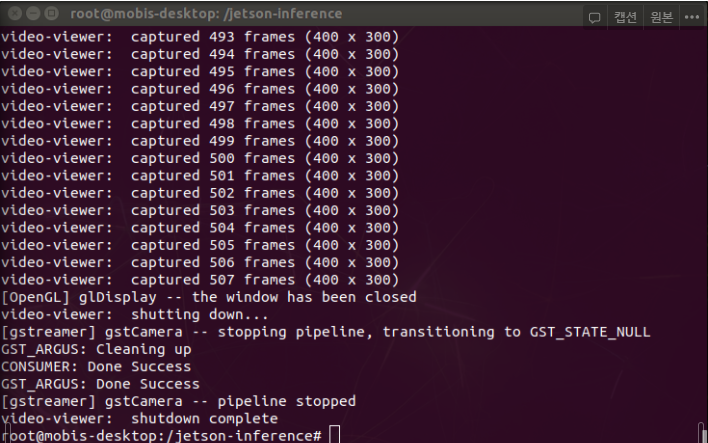
A. 다음과 같은 코드를 입력한다.
gst-launch-1.0 nvarguscamerasrc sensor_mode=0 ! 'video/x-raw(memory:NVMM),width=3820, height=2464, framerate=21/1, format=NV12' ! nvvidconv flip-method=0 ! 'video/x-raw,width=400, height=300' ! nvvidconv ! nvegltransform ! nveglglessink -e그러면 다음과 같이 terminal에서 여러 줄이 뜨면서 카메라가 실행되게 된다.
Jetson nano 에서 object detection
하기전에 Docker를 만들어보자.
우리는 jetson에서 deep learning model을 돌리기 위해 jetson-inference라는 github code를 받아와서 이용할 것이다.
git clone --recursive https://github.com/dusty-nv/jetson-inference이후에 docker/run.sh를 실행하여 docker를 켜보자.
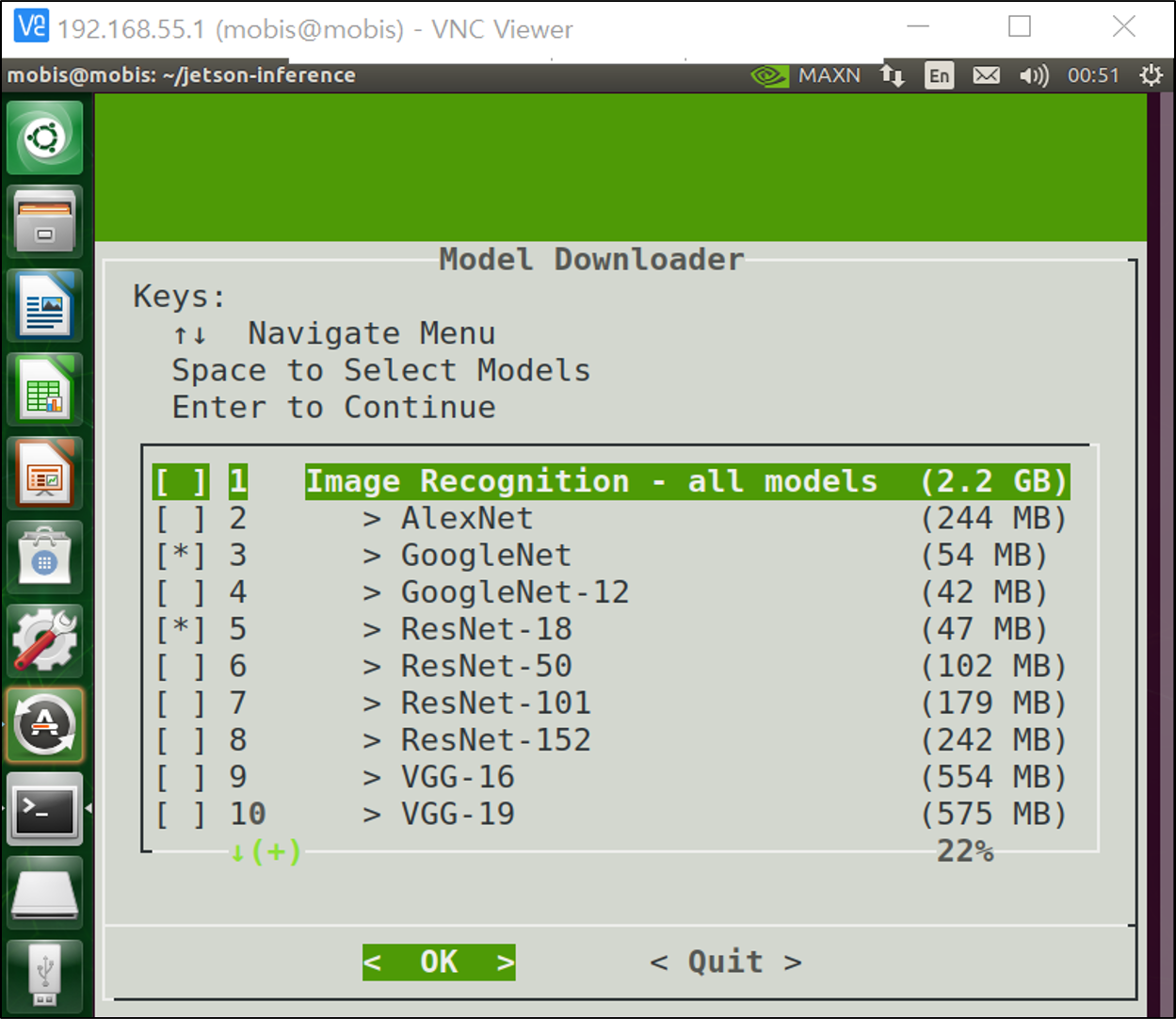
첫 실행에 배부를 순 없다. 설치하고 싶은 인공지능 모델을 체크하고 OK를 누르면 해당 모델이 다운로드 된다.
docker에서 Realtime 으로 카메라를 켜보자.
video-viewer --input-width=400 --input-height=300 csi://0다음과 같이 카메라가 켜지게 된다.
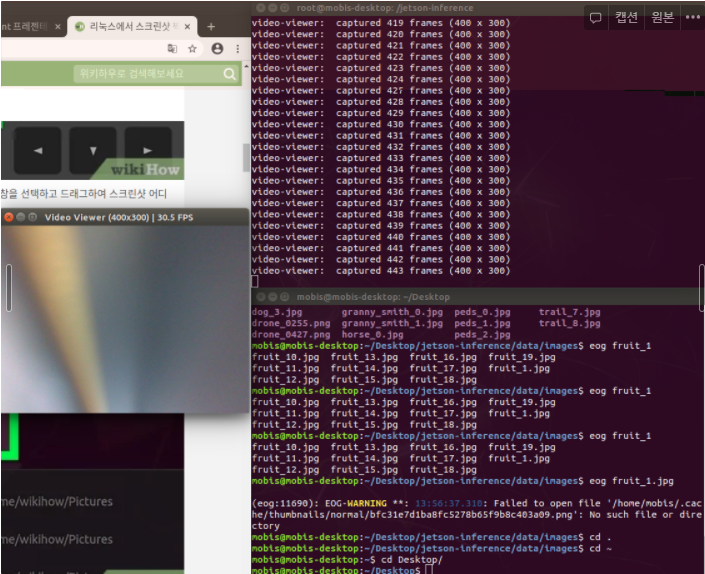
Object Detection
환경설정을 완료했으니, object detection을 해보자.
우리는 ssd-mobilenet v2 모델을 돌릴 것이다. 따라서 이미 존재하는 dataset image를 object detection 해보자.
아래 코드는 docker가 실행된 이후에 진행해야 한다.
detectnet.py --network=ssd-mobilenet-v2 data/images/(원하는 image).jpg data/images/test/output.jpg그러면 아래와 같은 결과가 나온다.
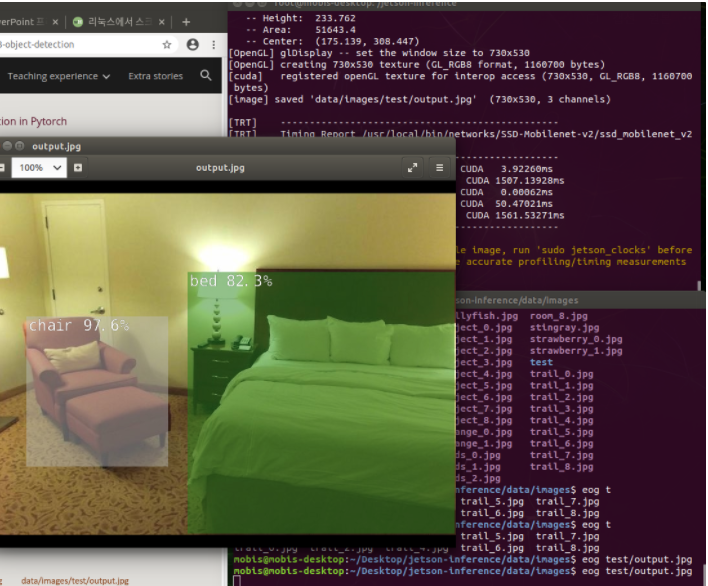
잘 나오는 것을 확인할 수 있다. 첫 실행에는 train 시간이 오래 걸리니 잘 확인해 보자.
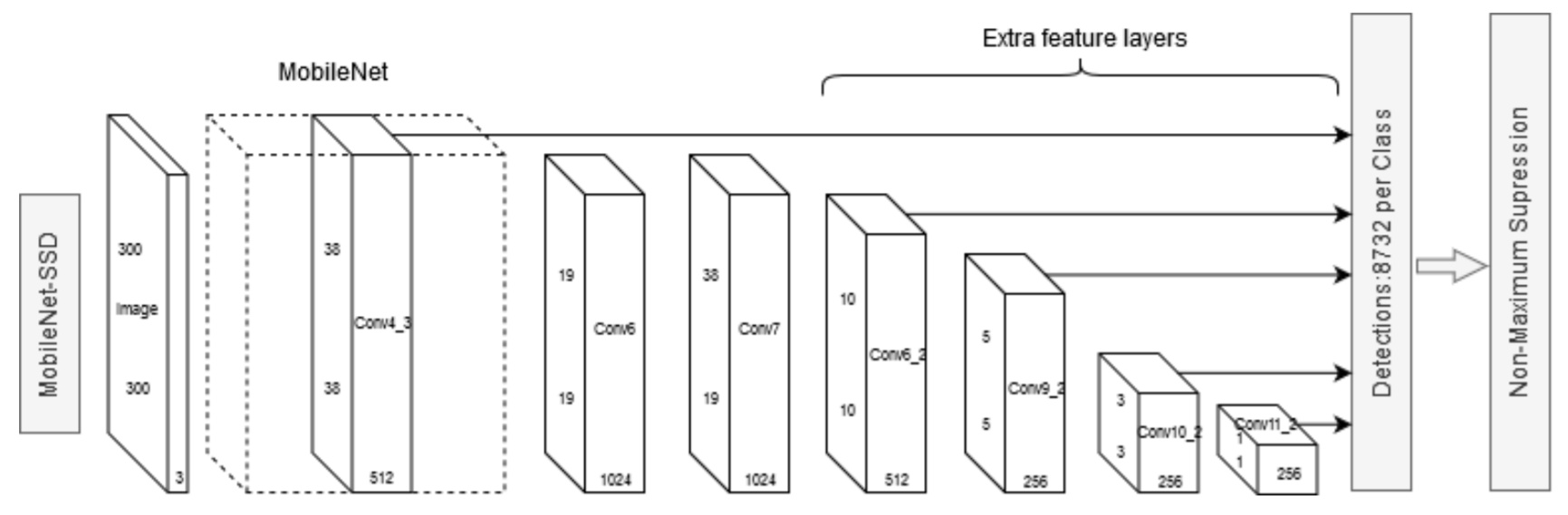
ssd mobilenet의 구조이다. 이는 나중에 논문 리뷰로 다시 찾아오겠다. (github code 리뷰도 진행할 예정)
만약 카메라를 이용해서 detection 하고 싶으면 다음과 같은 코드를 입력한다.
detectnet.py --network=ssd-mobilenet-v2 --input-width=400 --input-height=300 csi://0Transfer learning
다 인식을 잘한다고 해도, 특정 이미지를 훈련시킬 수 있어야 한다. 이미 학습되어 있는 모델만 이용하는 것은 큰 의미가 없으므로, Transfer Learning을 진행한다.
Transfer learning
전이학습(transfer learning)은 미리pretrained된 모델의 가중치 값을 가져와서 내가 가지고 잇는 새로운 데이터 셋과fine tuning을 통해 가중치 값을 다시 맞춰나가는 것을 의미한다.
전이학습을 통해, 큰 네트워크를 직접학습시키지 않아도, 작은 네트워크 만으로 좋은 결과를 낼 수 있도록 만든다.
Transfer learning을 하기 전에, 우리는 커스텀 데이터 셋을 얻어야 한다. 그래서 나는 ssd를 준비했다.
docker에 ssd를 mount하기 위해서 다음과 같은 코드를 입력한다.
docker/run.sh --volume /media/mobis/(소문자 영어로된 사용자 usb이름):/media/mobis/(소문자 영어로된 사용자 usb이름)그러면 docker안에서도 마운트된 메모리에 접근할 수 있게 된다. run.sh에는 docker를 키는 명령어가 존재하지만, 만약에 내가 직접 docker image를 실행시키고 싶다면 volume대신 v옵션을 넣고 실행할 수 있도록 한다.
docker에서는 image를 저장할 때save, export를 이용하고 이를cloud or docker cloud에 올린 후 다른 컴퓨터에서 받아올 때load및import를 통해서 받아올 수 있도록 한다.
save는 image로 저장하고tar로 바꿀 수 있도록 하고,export는container안에서 바로tar로 바꿔준다.또한
docker는commit을 통해서image의 현재 상황을commit한다.
이후 pip3 install boto3로 boto3를 설치한 후,
cd jetson-inference/python/training/detection/ssd
wget https://nvidia.box.com/shared/static/djf5w54rjvpqocsiztzaandq1m3avr7c.pth -O models/mobilenet-v1-ssd-mp-0_675.pth로 기존pretrained된 모델을 다운 받는다.
open image dataset를 다운 받기 위해 다음과 같은 코드를 입력한다.
python3 open_images_downloader.py --max-annotations-per-class=10 --class-names "Apple" --data=/media/mobis/(마운트한 usb이름, 저장소 이름)많은 이미지를 다운 받기 때문에, --max-images=(다운받을 image 수)를 option에 추가해서 다운 받을 수도 있다.
그리고 전이 학습을 위해 data 옵션을 끼워 넣는 것이다.
이때 train-ssd.py를 실행해야 한다.
python3 train_ssd.py --data=/media/(username)/(usb name) --model-dir=models --batch-size=4 --epochs=5그렇게 되면 알아서 훈련을 시킨 후 best accuracy를 가진 모델을 pythorch file로 만든다. (epoch마다 best accuracy 선정)
이후 onnx 파일을 만들어주는 프로그램을 실행한다.
python3 onnx_export.py --model-dir=models만약 이미지를 예측하고 싶으면, 다음과 같은 코드를 이용하고,
detectnet.py --model=models/ssd-mobilenet.onnx --labels=models/labels.txt --input-blob=input_0 --output-cvg=scores --output-bbox=boxes "$IMAGES/testImage(*.jpg)" $IMAGES/output.jpg카메라를 켜서 알고 싶으면 다음과 같은 코드를 이용한다.
detectnet.py --model=models/ssd-mobilenet.onnx --labels=models/labels.txt --input-blob=input_0 --output-cvg=scores --output-bbox=boxes --input-width=800 --input-height=400 csi://0Transfer Learning 완료!!
한번 해보고 싶어서 Car를 10장 정도 epoch 7로 학습시켜보았는데, 다음과 같은 영상이 나왔다.

외국 차만 Training 된 것도 있고, dataset이 적어서 네모만 보이면 car로 취급을 해버렸다. dataset을 늘린 후에 다시 시도해 보겠다.
