늘상 하듯 아이패드의 노타빌리티로 녹음동기화된 필기를 하려다가,
AMBA의 경우 필기보다는 타이핑을 통한 저장이 더 유리할 듯 하여 Velog에 필기를 하도록 하였다.
강의출처
P.S. - 3년간 게임을 안하다가, 블루아카이브를 최근에 시작했는데, 그덕분에 3일을 정말 쓰레기처럼 살았다. 이 게임은 해로운 게임이다. 하지만 난 월정액권을 결제했다. 크아아악
Bus란?
여러 블럭들이 상호데이터를 전송하기 위해 전기적으로 연결한 공유신호선
Protocol이란?
버스를 통해 데이터를 전송하기 위한 규칙
이번 강좌에서는, BUS보단 protocol 구현에 대해 공부하게 될 것.
어떻게 신호를 전송하고 수신하는가?
모듈 A가 B로 신호를 보낸다 치자.
과연 이걸로 될까?
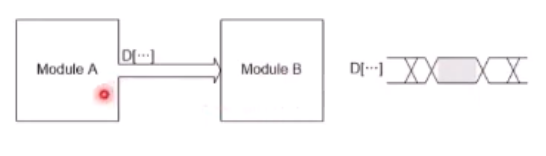
B는 어디서 끊어서 읽어야할지를 어떻게 알까?!
A->B로 VALID 신호를 함께 주는 것이 요구된다.
{kind=link}
A는 B가 제대로 수신했는지, 아니면 다시 한 번 더 보내줘야 하는지를 어떻게 알까?
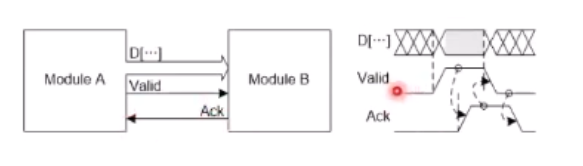
B->A로 ACK 신호를 회신하는 것이 요구된다.
이를 Handshake 라고 한다.
B가 여러 신호선일 때, 즉 병렬 또는 다Lane 일 때, B에 동일한 시점에 도착한다는 보장이 없지않는가?
이를 skew 라고 한다.
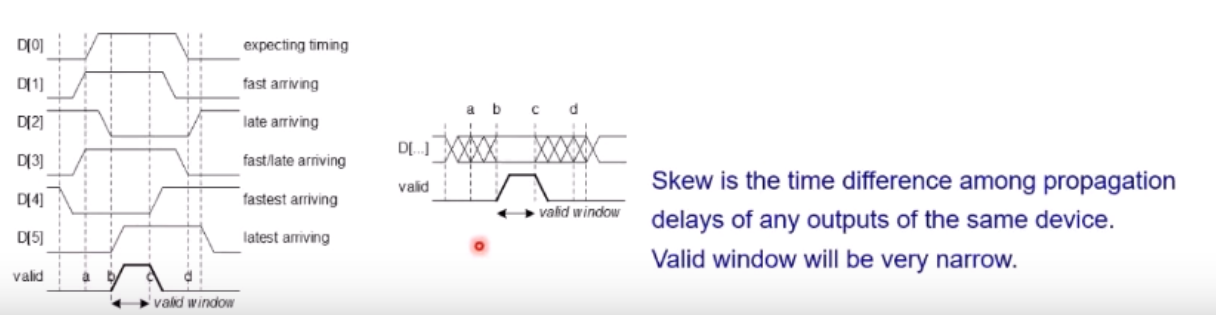
이것은 Bus 설계에 있어서 major 한 문제인데,
Valid 신호를 d0~5까지 모두 안정화되었을 때 ON 시켜줘야 한다.
B의 ACK 신호를 보낼거라 치자. B는 이게 제대로 수신된 정보가 맞는지를 스스로 어떻게 판단할건데?
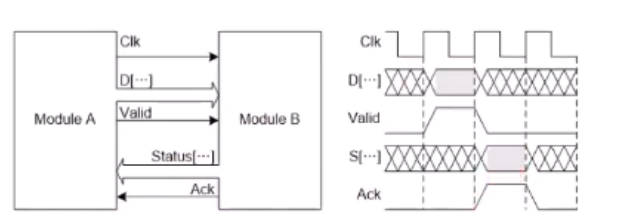
ACK는 받았다는 사실자체만 의미하지 "제대로" 받았는지를 의미하지는 않는다.
B가 받은 정보의 상태를 회신하기 위해 Status 신호를 회신한다.
이 때, B로부터 Status나 ACK이 오지 않으면 A는 1번 더 보내야하거나 에러처리를 별도로 할 수 있게끔 설계해야한다(당연)
Bus는 굉장히 중요한 자원이다. 만일 A,B 모듈이 독점해버리는걸 어떻게 예방할 것인가?

Wait 시간동안 다른 자원이 Bus를 활용가능하도록 설계해야하며,
이러한 것은 Bus Utilization 향상이라고 말한다.
그리고 그 구현법은 여러가지가 있다.
Bus Overlapping
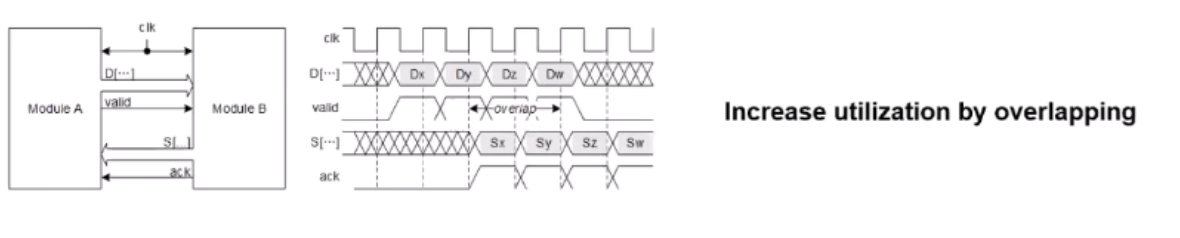
Burst Operation

묵시적으로 address가 ++로써 매우 간단한 동작일 때, 즉 인접한 주소면 시전가능하다.
보다시피 a는 첫 data를 1번만 보내고, module b가 알아서 처리하고있다.
Multiple Outstanding && Out Of Order Completion

CPU는 3GHz대인데 비해 DDR은 300MHz대이다.
그러므로 무지성으로 설계하면 CPU는 메모리에 읽거나 쓰는동안 메모리를 기다리게 된다.
따라서 CPU는 A0라는 주소를 요청날리고 다른 데이터에 대한 작업을 할 수 있게 해야한다.
Operation이 끝나지 않았는데도, 즉 ACK가 회신되지 않았는데도 다른 data에 access할 수 있게 하는 기능을 Multiple Outstanding이라고 한다.
별도로, Request 한 순서와 동일하지 않게 data return 을 수행하는 기능을 Out of Order Completion 이라고 한다.
Slave가 1개냐?
당연히 아니다.
그럼, 어떻게 Slave 를 선택할 것이냐?
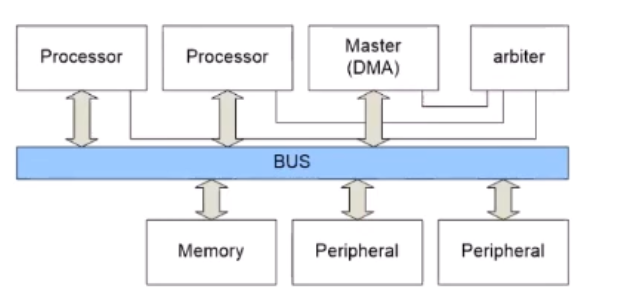
Central 한 방법
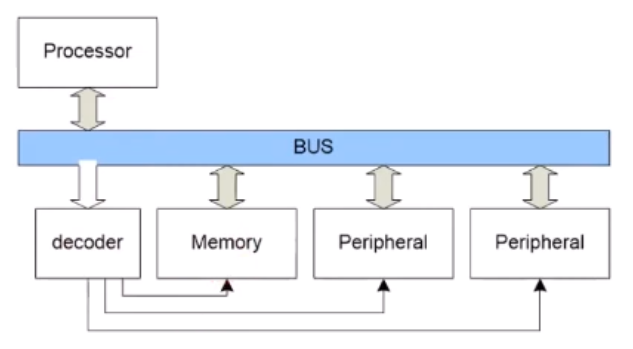
Decoder가 Centralized됨
Distributed 한 방법
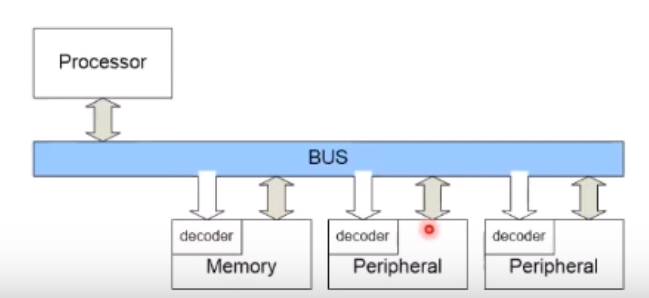
Decoder가 Slave마다 Distributed됨
Decoder 의 역할이 뭔데?
주소를 받아서 decoded address 로 바꿔준다.
종합하면 이러한 꼴이 된다.
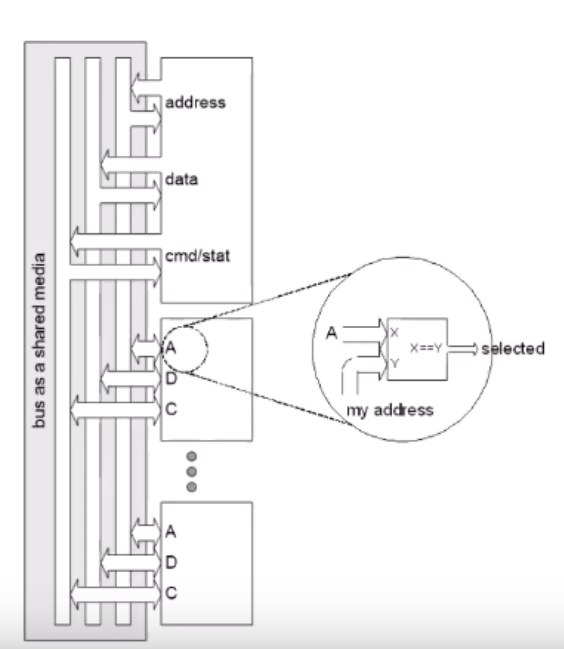
Processor가 여러 개 있으면 어떻게 하냐?
DMA의 경우는 메모리를 옮기는 기능이므로 Master 의 일종으로 분류된다.
여러 Master가 있는데, 그 중 누가 쓸지를 "중재"해줘야 한다.
이를 Arbiter 가 한다.
마찬가지로,
Central
Distributed
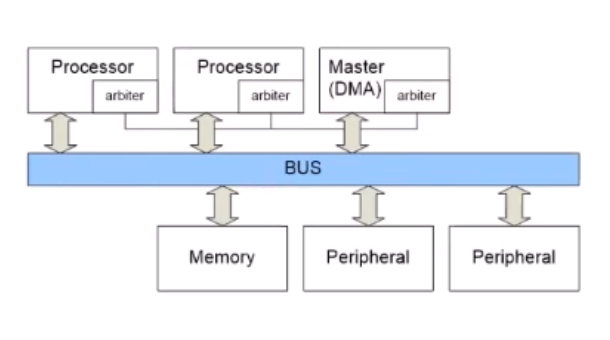
한 방법이 각각 있다.
Arbitration 의 Policy 는 상당히 세분화가능한데,
대략 아래 그래프와 같이 분류가능하다.
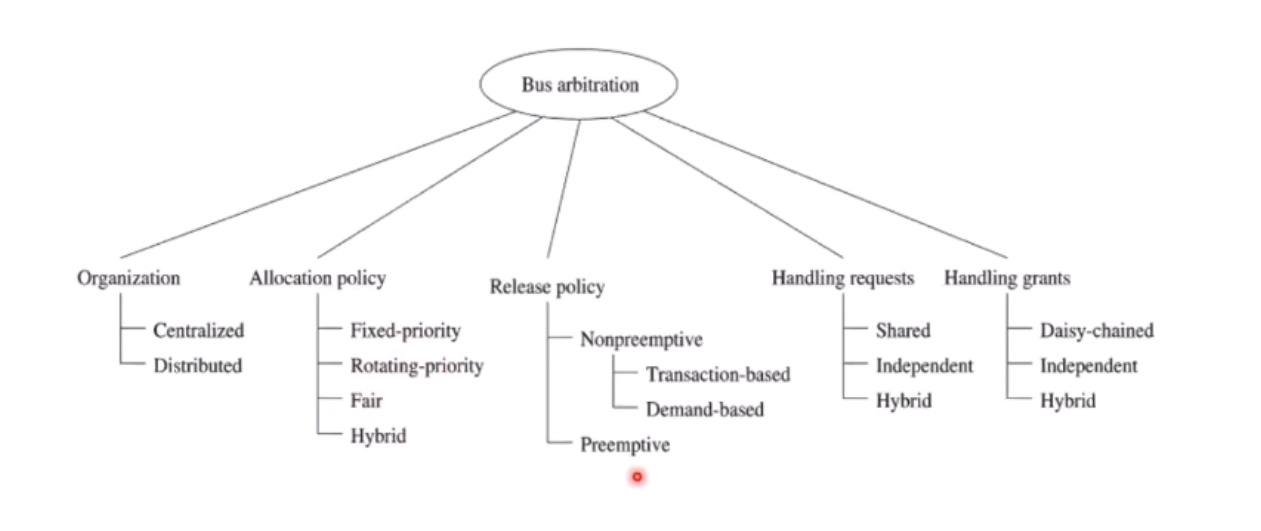
OS시간의 자원분배 이슈와 비슷한 고려사항을 안고있는 듯 하다.
Arbitration의 Issue들
- Fairness
- Starvation(계속 자원을 손에 넣지 못함)
- Live-Lock(열심히 일은 하는데 진전이 없음)
ex) 캐시에서 계속 invalidation - Dead-Lock(한발짝도 나아갈 수 없음) -> 최악의 상황, Reboot 또는 극단적인 조치를 취하게 됨
Starvation
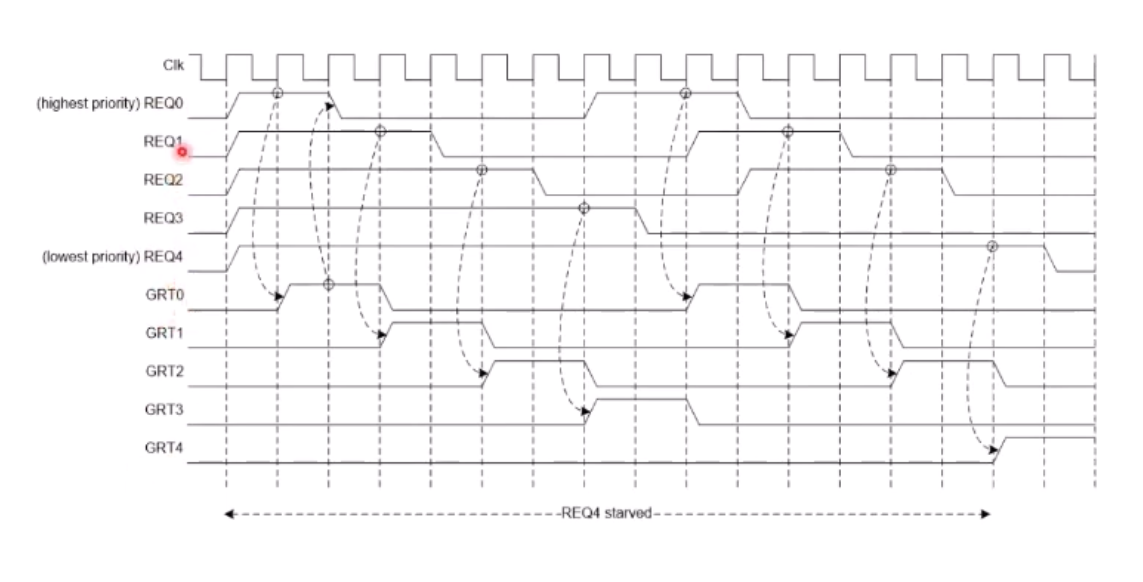
대략 REQ 받으면 GRANT 신호가 떨어지고, GRANT 되면 버스를 점유할 수 있는 권리를 얻는, 저번시간에 배운 AMBA구조의 약식이다.
그러나 이 경우 Starvation이 발생하는데 REQ4는 REQ1에 의해 우선순위가 밀려서 GRT4가 GRT1에 ON을 뺏긴다.
그럼, 어떻게 Fairness하게 하는가?
여러 방법이 있지만,
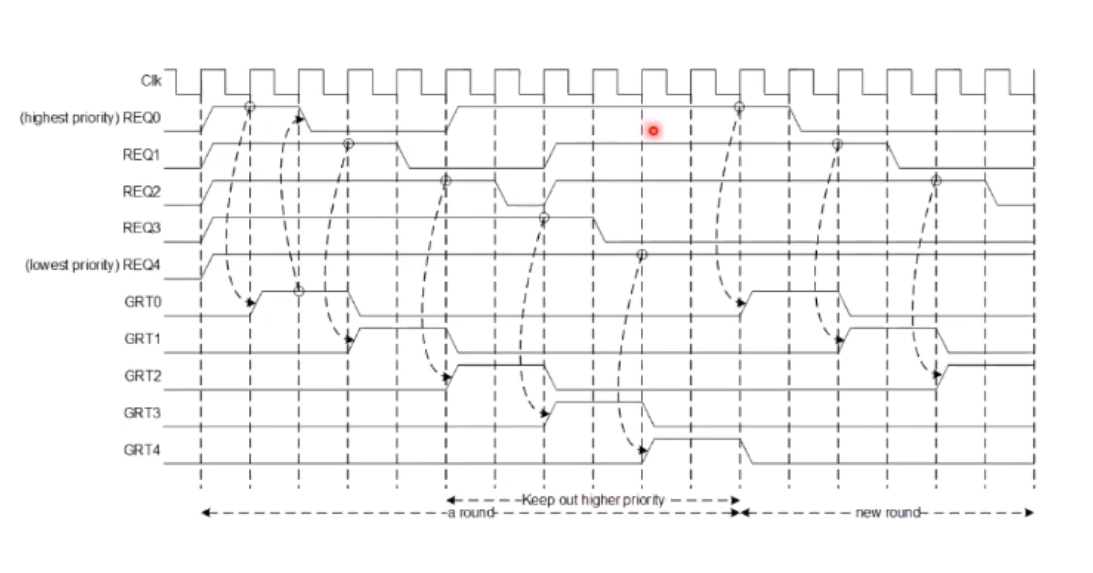
한 번 버스를 쓴 상황이 있다면, 그 Request 는 Masking 을 해서 Priority 가 높더라도 기다리게끔 HW적으로 구현하는 방법이 있다.
Live-Lock 은 생략
Dead-Lock
Bus A의 M0이 Bus B의 Sy에, Bus B의 M3이 Bus A의 Sx에 접근하고자 한다.
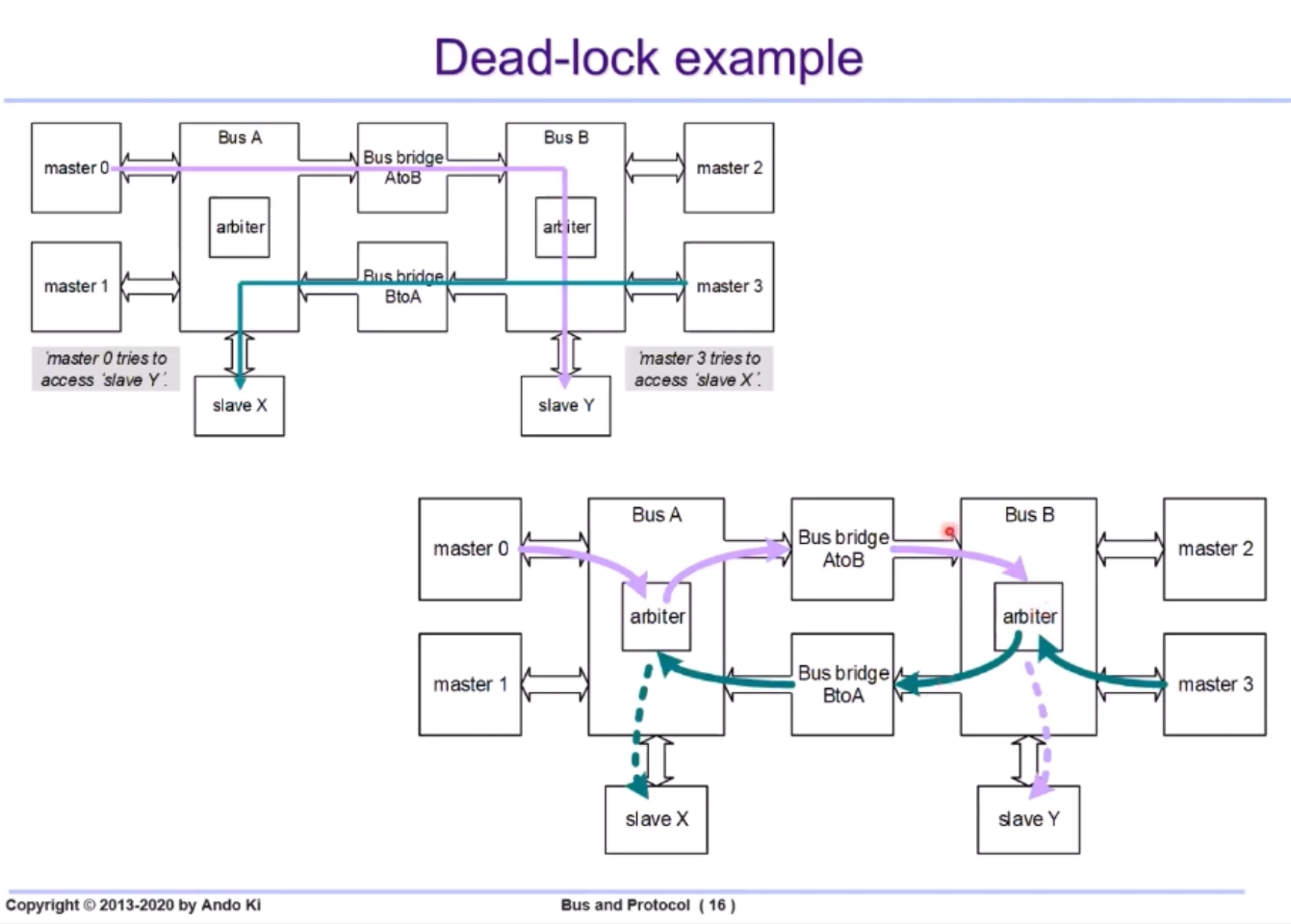
이렇게 설계하면, HW적인 데드락이 발생할 수 있다.
Transfer Type
버스를 효율적으로 쓰고자 할 때, 파이프라이닝이나 Overlapping 의 안이 나왔는데,
성능에 대한 관점을 다르게 하여
Latency 를 가능하면 줄이는 방향 또는 Bus가 데이터를 옮기는데 소요되는 Throughput을 줄이는 방향으로 초점을 다르게 맞춰 접근할 수도 있을 것이다.
만약 모듈이 빨리 움직여야 하면 Latency(=Speed).
DMA같이 대용량의 데이터 처리의 경우 Throughput
이 중요시되게 될 것이다(=Bandwidth).
이러한 사양의 요구유형을 Transfer Type 라고 하며 아래와 같다.

이는 Bus가 어떤 의도로 동작을 하는지를 구분할 수 있도록 한다.
예를 들어, 메모리로부터 데이터를 읽어서 프로세서의 캐시에 쓰고자 할 때는
버스입장에서는 Read지만, 결국 그 Read 는 Processor의 캐시에 쓰기 위함이기 때문에 Read For Write 라고 할 수 있다.
마찬가지로, AHB의 경우 NONSEQ냐 SEQ냐로 구분하며
SINGLE이냐 INCR이냐 WRAP이냐로 구분하여 Bus에 알려주어야만 하게끔 되어있다.
이렇게 하는 이유는 뭐냐면,
현재 수행중인 Data Type 을 버스가 알면 조금 더 효율적으로 관리가능하며 현재 무슨일이 벌어지는지를 버스에 연결된 다른 모듈이 인지하게 됨으로써 시스템 전체의 최적화에 도움이 되기 때문이다.
Access Intention
말그대로 참조하려고 하는 의도가 무엇인지를 Bus가 아는 방법을 의미한다.
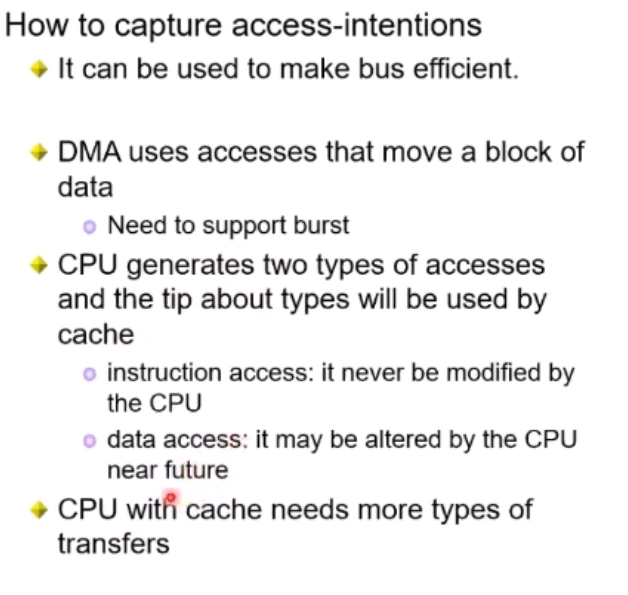
DMA라면 burst 를 지원해야할테고,
CPU는 명령어 접근/데이터 접근에 따라 두 종류의 access 를 구분가능할테고, 따라서 더 세분화된 캐시가 필요할 것이다.
Burst Transfer
목적: Higher Throughput
수단: 인접한 데이터의 경우 한 번의 transfer로 시전가능하다.
필요정보:
- Burst Length: 한 Burst의 beat 갯수
- Burst Size: 한 beat(bit가 아니다!) 전송때릴때마다의 크기
- Addressing Mode - How Stride? WRAP? INCR? or FIXED?
- 기타정보: Partial Burst Size, 즉 burst size 가 data bus width 보다도 작을 때의 예외처리
Burst Locked(for AHB)
One Address for Burst(for AXI)
이외에도 여러 기술이 있다.
Multiple outstanding bursts
out-of-order complete
=>요청한 순서와 회신된 순서가 안맞으면, 회신된 순서대로 버스 사용
Data interleaving
=>공유자원인 Bus를 효율적으로 사용하기 위해 회신된 순서대로? 버스사용
(=>Out of Order Complete 와 무슨 차이인지 모르겠다. 일단 넘어감)
Pipeline Bus control
Split Bus control
Bus에서 자체적으로 Byte Ordering 까지 해주는 경우도 있다.
Justified Bus란?
Bus가 data 를 어떻게 보내느냐에 따라 Justified/Nonjustified Bus로 구분된다.
Justified Bus(for Wishbone Bus)
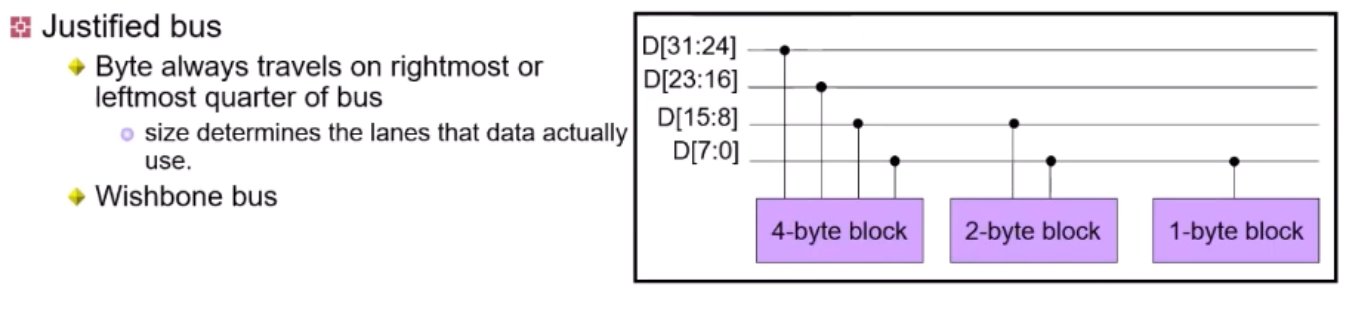
문서작성시 왼쪽맞춤, 오른쪽맞춤처럼 align시키는 것.
그림처럼, 4-byte block이 아니라면 D[31:24]는 사용하지않음을 볼 수 있다.
Nonjustified Bus(for AMBA)
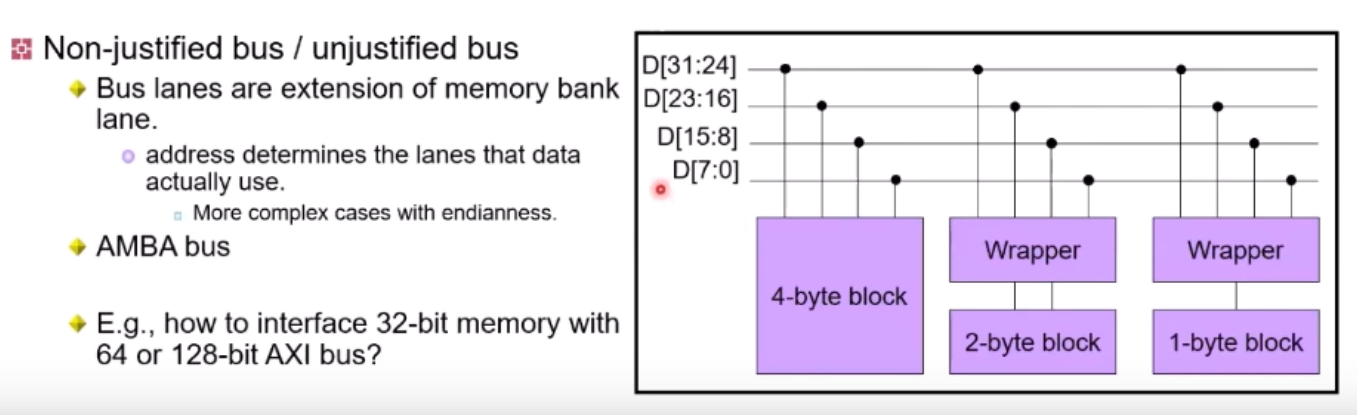
0번째 Byte를 Access할 때, Address에 관련있는 Byte Ring 만
1-byte bus에도 전부 물려있기 때문에 Wrapper가 필요하다.
Partial/Narrow Access
1Byte를 보낼 때, 4바이트 중 어느 바이트가 의미있는지 어케 아는가?
Partial Access
Byte Enable
Byte Enable을 같이 보내서, 어느 바이트가 유효하고 안유효한지 표시
data[32]당 be[4] 필요
Size and Address
주소와 크기를 같이 보낸다.
data[32]당 size[2]와 addr[2]필요
Narrow Access
생략
Alignment of Access
CPU 자체가 안나눠떨어지는 주소의 접근을 허용할 것인지?
아니면 컴파일러가 애초에 그런 주소를 안주게끔 할 것인지?
Atomic && Mutual Exclusion
예를 들어, 은행서버에 동시에 read 및 돈 인출명령 request 를 내렸는데 1회만 차감되면 안될 것이다.
그러한 개념이다.
이러한 개념을 Bus에서도 지원해줘야 한다.
읽고쓰는 동안, 값을 바꾸는 동안의 타인의 접근을 차잔하기 위해
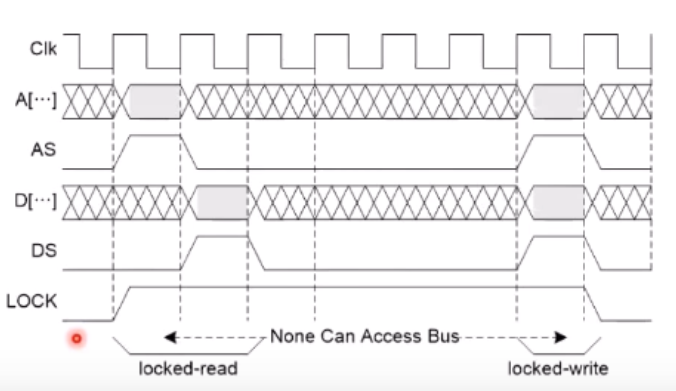
위와같이 LOCK 이라는 신호를 추가적으로 두게 된다.
이러한 신호를 위해 대부분의 Processor는 atomic 을 위한 명령어를 보유한다.
ex) ARM - SWAP, LDREX, STREX
Intel - lock inc, lock dec, ...
