논문 및 이미지 출처 : https://arxiv.org/pdf/2206.07669v2.pdf
Ting Chen† Saurabh Saxena† Lala Li†
Tsung-Yi Lin∗ David J. Fleet Geoffrey Hinton
Google Research, Brain Team
Abstract
NLP 분야는 단일 통합 모델링 프레임워크로 표현할 수 있지만 computer vision 분야에선 아직 없다.
결과로, 서로 다른 vision task 에 대한 아키텍처와 loss function 이 급증하고 있다.
이에 저자는 computer vision 의 다양한 핵심 task 들은 공유된 pixel-to-sequence interface 형태로 나타내면, 통합될 수 있다고 한다.
그리고 bounding box 나 dense mask 와 같은 다양한 타입의 출력을 가진 task 인 object detection, instance segmentation, keypoint detection 및 image captioning 과 같은 네 가지 task 에 초점을 둔다.
각 출력을 통합된 interface 와 discrete token 의 시퀀스로, 특정 task 에 커스터마이징 없이 단일 모델 아키텍처와 모든 task 에 대한 loss function 으로 모델을 학습시킨다.
특정 task 에 풀기 위해, short prompt 를 task description 으로 사용하고 시퀀스 출력을 prompt 에 적응하여 특정 task 의 output 을 생성한다.
이러한 모델로 task 별로 잘 알려진 모델과도 갱쟁력 있는 성능을 보였다.
1. Introduction
다양한 task 를 수행할 수 있는 단일 신경망을 훈련하는 것은 인공 지능의에서 중요한 진전이다.
최근 몇년간, Transformer 을 사용한 큰 언어 모델의 등장으로, 서로 다른 언어 및 관련 task 들이 단일 모델링으로 통합되었다. 이러한 언어 모델은 주어진 task description 으로 해결책을 예측하도록 훈련된다.
이것이 가능한 이유는 이러한 task 들은 동일한 rich language interface 에서 표현할 수 있기 때문이다.
이는 image captioning 이나 visual question answering 처럼 computer vision 쪽으로 확장 가능하나, "핵심" computer vision task 에는 자연어로 쉽게 표현할 수 없다는 것이다.
- object detection : bounding boxes, class label
- instance segmentation : segmentation mask, image regions
- keypoint detection : keypoints
이러한 복잡한 tasks 들은 각각 따로 특화된 아키텍처나 loss function 이 개발된다.
서로 다른 vision 을 통합하기 한다는 것은 아키텍처 및 loss function 설계를 간소화하고 task 간의 feature/representation 공유를 촉진하여, task 간의 정교한 output head 를 필요로 하지 않도록 하는 것이다.
또한 기존 모델을 새 task 에 적응시키는 것을 용이하게하고, zero, few 의 새로운 기능을 잠재적으로 열 수 있다.
끝으로, 저자는 네 가지 서로 다른 task 를 단일 pixel-to-sequence interface 로 통합하는 방법을 제시한다.
네 가지 vision task는 object detection, instance segmentation, human keypoint detection, image captioning 이며,
먼저 이 task 들을 single shared interface 로 통합하는 방법을 보여준다.
이후, shared architecture 와 object function 이 있는 뉴럴 네트워크를 훈련한다.
특정 task 에 적용하기 위해선, specific head 사용과, prompt 를 사용하여 task 를 지정하며, sequence output 을 prompt 에 적응시킨다.
이로서, 주어진 task description 으로 특정 task 의 output 을 생성한다.
2. Approach

저자는 computer vision task 를 pixel input (task 의 description 과 함께) 을 별개의 tokensequence 로 변환하는 task 중 하나로 캐스팅한다.
저자는 다음 4 가지 task 에 초점을 둔다.
- object detection
- instance segmentation
- keypoint detection
- image captioning
2.1 A unified interface with tokenization
서로 다른 task 는 각각 다음 output 을 가진다.
- object detection : bounding boxes, class label
- instance segmentation : segmentation mask, image regions
- keypoint detection : keypoints
- image captioning : natural language description, sequence
위와 같이 각각의 task 는 출력 형태가 차이가 있어, 전용 모델 아키텍처와 loss function 이 필요하다.
이를 단일 모델로 해결하기 위해, 저자는 task input 및 output 을 unified interface 로 transformation/tokenization 하는 것을 주장한다.
이 연구에서, sequence interface 를 제안하며, tkas description 및 output 은 다양한 작업의 시퀀스로 표현된다.
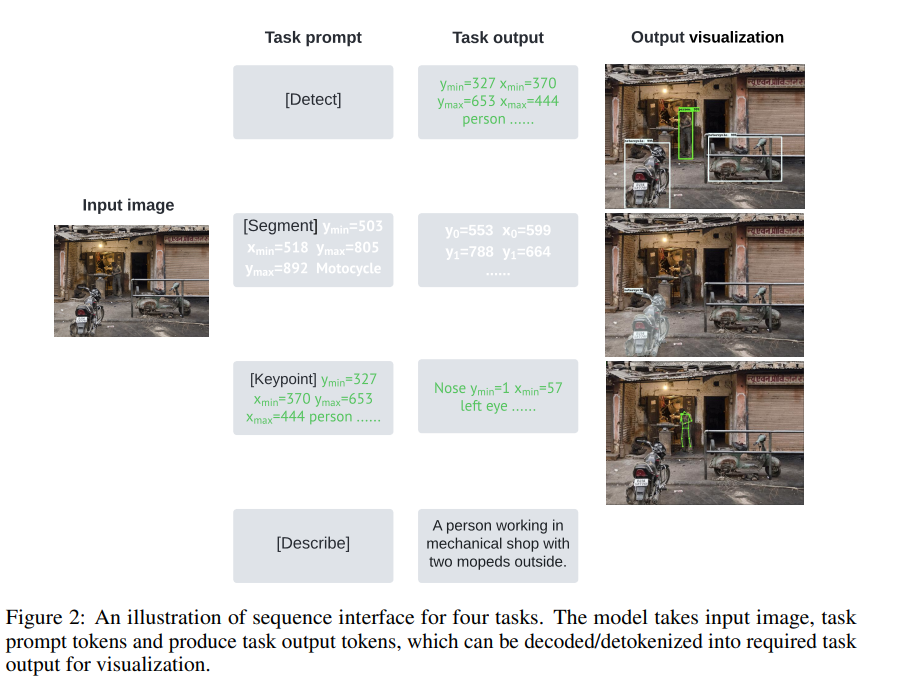
-
Object Detection
- bounding boxes 와 object description 을 연속적인 이미지 좌표를 quantizing 하여 다양한 토큰 의 시퀀스 로 변환
- object 는 와 같은 5 개의 discrete token 의 시퀀스 로 표현
- multiple object 는 훈련 이미지를 샘플링할 때마다 주막위로 정렬되어 하나의 시퀀스 로 직렬화
-
Instance Segmentation
- 픽셀 단위의 마스크 대신, 해당 instance mask 에 대응하는 polygon 을 개별 객체 인스턴스에 조건화된 이미지 좌표의 시퀀스로 예측하고
- 또한, polygon 을 시퀀스로 바꾸기 위해, 훈련용 이미지가 샘플링될 때마다 시작 토큰에 대한 시작점을 무작위로 선택
- 동일한 인스턴스에 여러 polygon 이 있다면, 각 polygon 의 시퀀스를 연결하여 모든 인스턴스에 대해 하나의 대응하는 시퀀스를 얻도록 한다.
-
Keypoint Prediction
- 주어진 사람 인스턴스에 조건부로 양자화된 이미지 좌표의 시퀀스로 keypoint 를 예측
- keypoint 의 시퀀스는 로 인코딩
- 각 좌표에 keypoint label (예; 코, 왼쪽 눈, 오른쪽 눈)을 사용할 수 있지만, 간단함을 위해 고정된 순서는 필요하지 않음
- 일부 keypoint 가 가려져 있는 경우, 좌표 토큰을 특수한 가림 토큰 (occlusion token) 으로 대체
-
Captioning
- discrete token 의 시퀀스로 주어진 caption 의 text token 을 직접 예측
네 가지 task 는 모두 동일한 단일 vocabulary 를 가진다.
2.2 Unified architecture and objective function
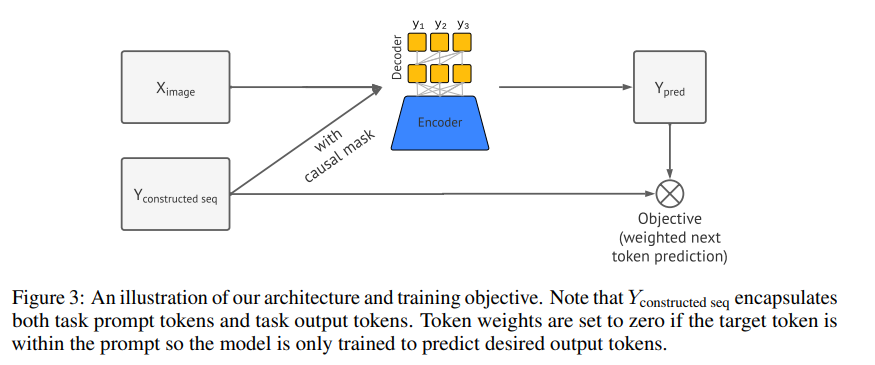
저자는 복잡한 image input 과 sequence output 을 유연하고 표현력 있는 아키텍처가 필요하다.
따라서 image encoder 와 sequence decoder 가 있는 encoder-decoder 아키텍처를 사용한다.
- image encoder : 픽셀 인식 및 hidden representation 으로 매핑
- 여기서 hiden representation 은 ConvNet, Transforer 이나 이들의 조합으로 구현 가능
- sequence decoder
- transformer 기반 디코더는 하나의 토큰을 생성하며, 이전 토큰과 인코딩된 image representation 에 의존한다
- 이는 여러 vision task 에 대한 현대 뉴럴 네트워크의 아키텍처에 대한 복잡성과 커스터마이징을 제거해준다.
단일 object detection task 에서 디코더가 output token 을 직접적으로 생성하는 것과 달리, 여기선 task prompt 를 조정하여 모델이 관심 task 에 적합한 output 을 생성하도록 한다.
훈련 중엔, prompt 와 원하는 output 을 하나의 시퀀스로 연결하지만, token weighting 체계를 활용하여 디코더가 원하는 output 뿐만 아니라 prompt token 도 예측하도록 훈련된다.
추론 중엔, prompt 가 주어지고 고정되므로, 디코더는 나머지 시퀀스만 생성하면 된다.
훈련 목표는 이미지와 이전 토큰에 조건화된 토근의 likelihood 를 최소화하는 것이다.
는 input image
는 와 관련한 시퀀스 길이 , 언급했듯이 시퀀스 의 초기 부분은 prompt 이다.
를 0 으로 설정하여 loss 에 포함하지 않도록 한다.
2.3 Training
각 task 는 image-sequence 쌍의 훈련 데이터를 가진다. 두 가지 방법으로 task 를 결합하고 합동으로 훈련을 수행할 수 있다.
Data mixing
서로 다른 task 에서 가져온 mixed image-sequence 쌍으로 dataset 을 만들 수 있으며, 서로 다른 dataset 크기와 task 어려움에 대한 균형을 맞출 수 있다.
이 구성은 개념적으로 매우 간단하지만, image augmentation 은 관련된 시퀀스를 쉽지 않은 방법으로 변경해야할 수 있어 통합하기 어려울 수 있다.
Batch mixing
각 배치에서, 단일 task 에 대한 annotation 을 가진 이미지를 샘플링하고, 이 task 에 적합한 image augmentation 을 수행하고, 증강된 데이터를 image-sequence 쌍으로 변환한다.
이 모델은 각 task 에 대한 loss 와 gradient 를 계산한 수 있고, 특정 task batch 의 gradient 를 적절한 weighting 을 결합할 수 있다.

Algorithm 1 과 2 에서 요약 및 전략을 보여준다.
이 연구에선 image augmentation 을 단순하게 처리하기 위해 batch mixing 전략을 사용한다.
data mixing 과 batch mixing 은 각 task 에 대한 부분 또는 weightinh 을 지정해야 한다.
이는 경험적인 문제이며, 저자는 한 번에 하나의 task 를 추가하여 greedy 전략을 사용한다.
task 추가할 때마다마다, 저자는 기존 task 에 따른 상대적인 weighting 을 유지하면서 new task 의 weighting 을 조절한다.
모든 task 에 걸친 weight 의 합을 하나로 고정한다.
2.4 Inference and de-tokenization
추론할 땐, 시퀀스 시작 시 prompt 가 주어진 모델의 likelihood (예; ) 로부터 토큰을 샘플링한다.
nucleus sampling 을 사용하고 있지만 beam search 와 같은 다른 기술 또한 사용된다.
토큰이 생성되면, 각 task 에 대한 토큰을 디코딩할 수 있다. 서로 다른 task 가 토큰 시퀀스를 생성하기 위해 특정 tokenization scheme 를 필요로 하는 것과 동일하게, 디코딩 (de-tokenization) 프로세스 또한 각 task 에 고유하다.
각 task 의 추론 디코딩에 대한 자세한 설명은 다음과 같다.
- bounding boxes : 예측된 시퀀스를 5 개 토큰의 tuple 로 분할하여 좌표 토큰과 클래스 토큰을 얻고, 좌표 토큰을 dequantizing 하여 bounding box 를 얻는다.
- instance segmentation : 각 polygon 에 해당하는 좌표 토큰을 dequantize 한 다음, dense mask 로 변환한다.
모델은 정규화로 훈련되지 않아, output polygonal mask 는 다소 노이즈가 있을 수 있다.
노이즈를 줄이기 위해, multiple sequence 를 샘플링하고 mask 를 평균화한 다음, single binary mask 를 얻기 위해 간단하게 임계값으로 나눈다. - keypoint detection : keypoint 의 이미지 좌표 토큰을 직접적으로 dequantizing 한다
- captioning : 예측된 discrete token 을 바로 text 로 매핑한다
3. Experiments
3.1 Experimental settings and implementation details
118k 훈련용 이미지와 5k 검증용 이미지를 포함하는 MS-COCO 2017 dataset 으로 평가를 하며 이 데이터셋으로 4가지 task 를 고려한다.
해당 데이터셋의 이미지는 object bounding box 를 위한 annotation, object instance 를 위한 segmentation mask, person instance 를 위한 keypoint, 그리고 few captions 을 포함한다.
이전 논문 Pix2Seq 을 따라, Vision Transformer (ViT-B) encoder 와 Transformer autoregressive decoder를 사용한다.
이 모델의 총 132M 파라미터를 가지고 있다. 초기화를 위해, Objects365dataset 에서 object detection 을 훈련한 pretrained checkpoint 를 사용했다.
- COCO 가 상대적으로 작아, task 에 덜 특화된 사전 지식을 가져서 유용
- COCO 훈련의 경우
- 128 이미지 배치 사이즈
- 의 lr
- 100 epochs
- 35k single vocabulary 및 32K text tokens
- 1K coordinate quantization bins 및 few other class label
- 최대 시퀀스 길이는 512
- 백본은 640x640 이미지 사이즈 pretrain 및 finetuning 은 640x640 또는 1024x1024 해상도
Object detection
Pix2seq 에 따라 훈련 중 sequence augmentation 을 사용하고, 추론 시 class token 확률을 사용하여 점수를 매긴다.
또한 Pix2seq (가로 세로 비율이 변하지 않고 무작위로 영상 스케일링, 고정된 크기 영역을 무작위로 자른 다음 최대 크기로 패딩) 처럼 scale jittering 을 사용한다.
Instance segmentation
polygon 의 최대 점수를 128 로 설정한다.
모델에게 추론 시 여러 샘플을 생성하도록 요청하고, 생성된 마스크를 평균내는 것이 이득이라는 것을 발견했다.
구체적으로, 각 샘플을 독립적으로 추출하여 이를 prompt 된 객체의 semantic mask 로 변환한다. 그 후, 50% 임계값을 설정하여 마스크를 평균내고, 50% 이상의 픽셀은 해당 인스턴스를 위해 선택된다.
저자는 8개의 샘플이 충분히 좋은 성능을 제공하며 (단일 샘플 사용 시보다 약 6 AP 높음), 12개 이상의 샘플에서는 성능 형상이 보이지 않는 다는 것을 발견했다.
또한 추론 과정에서 prompt 된 object instance 를 포함하는 이미지의 cropped region 에서도 평가를 한다.
이 경우엔, 입력 이미지를 cropped region 만 포함하는 새 이미지로 대체한다. 640x640 크기의 작은 이미지에서는 1.3 AP 로 개선이 이루어졌지만, 1024x1024 크기의 큰 이미지에서는 큰 효과가 없었다.
Keypoint detection
저자는 person instance 을 포함하는 이미지의 copped region 에서 훈련 및 평가한다.
학습 중엔, 이 region 들이 ground-truth annotation 에 의해 제공되며
추론 중엔, 이 region 들은 object detection model 에 의해 제공된다.
이 region 에 제공된 bounding box 의 두 배 크기로 선택한다. 이런 최적의 crop 을 사용하여, 매우 큰 crop (bounding box 크기의 약 20배, 전체 이미지 사용에 근접한 것으로 간주)을 사용하는 것보다 약 9 AP 향상을 얻었다.
또한, quantized sequence 에서 보이지 않는 토큰 좌표를 나타내는 특수 토큰을 사용한다.
학습 시, 이런 토큰에 대한 작은 loss weight 0.1 을 사용한다.
더 큰 가중치를 사용하더라도 AP 에 큰 영향을 미치지 않지만(가중치 1.0 에서 1 낮아짐), 가중치 0.0 을 사용하면 훨씬 나쁜 결과가 나온다 (12 AP 낮음).
추론 시에는 보이지 않는 토큰을 모델이 keypoint 좌표의 최선의 추측값으로 대체한다.
Four-tasks joint training
object detection, instance segmentation, image captioning 및 keypoint detection 각각 0.1782, 0.7128, 0.099, 0.01 의 mixed weighting 을 사용한다.
이러한 weight 의 셋은 한 번에 하나의 task 를 추가하여 greedy 탐색을 한다.
Baselines
object detection 의 경우 strong 2-stage detector 인 Faster R-CNN 및 보다 최신인 Transformer-based detector 인 DETR 와 비교한다.
Faster R-CNN 및 DRET 는 모두 Faster R-CNN 의 non-maximum suppression 및 DRET 의 일반화된 IoU 과의 biparite graph matching 같은 설계에서 task 별 사전 설정을 사용한다.
커스터마이징된 아키텍처 및 loss function 때문에, 넓은 범위의 task 로 확장하는 것은 간단하지 않으며 새로운 모델을 설계할 필요가 있다.
Mask RCNN 은 Faster R-CNN 을 확장하여 segmentation 및 keypoint 를 통합하는 설계를 지지한다.
Mask RCNN 은 네 가지 작업 중 세 가지를 수행할 수 있지만, 여전히 Faster R-CNN 과 동일한 task 기반 세팅이 필요하다. 또한 Transformer 와 유사한 attention 메커니즘을 통합하는 non-local 아키텍처가 있는 Mask R-CNN 의 개선된 버전도 고려한다.
위 방법들은 image captioning 을 할 수 없으므로, task 에 특화된 Transformer 기반의 caption model 을 훈련한다.
이 모델은 caption single task 을 위해 제안된 방법으로 훈련된 것과 유사하지만, 높은 dropout rate 이 있는 사전 훈련된 visual encoder 를 사용하고 있다.
3.2 Quantitative results

위 테이블 1 에 결과가 요약 돼있으며, 다음 베이스라인과 두 가지의 모델을 소개 한다.
- single task 에 대해 훈련된 single task model (여전히 동일한 아키텍처 및 objective function).
따라서 각 task 는 자체의 network weight 를 가진다. - sinle network weight 의 셋이 4 가지 task 에 대해 사용된 multi-task model
특정 task 에 대한 아키텍처나 loss function 의 사전 지식 없음에도, 저자의 모델은 여전히 각 개별적인 task 에 대한 결과가 경쟁력 있다고 한다 (심지어 이미지 사이즈가 작을 때도).
모든 task 에 대해 single model 로 훈련했을 때, 모델 사이즈를 동일하게 유지 했음에도 각각의 task 를 해결할 수 있었다. 또한, 이미지 사이즈를 크게 하면 성능 향상도 관찰했다.
한 예외로는 keypoint detection 인데, 감지한 key point 에 대한 cropped interest region 을 이미 사용하여, 이미지 사이즈를 키우는 것이 반드시 유용한 것은 아니며 labeld data 에 제한된 경우 과적합으로 이어질 수 있다.
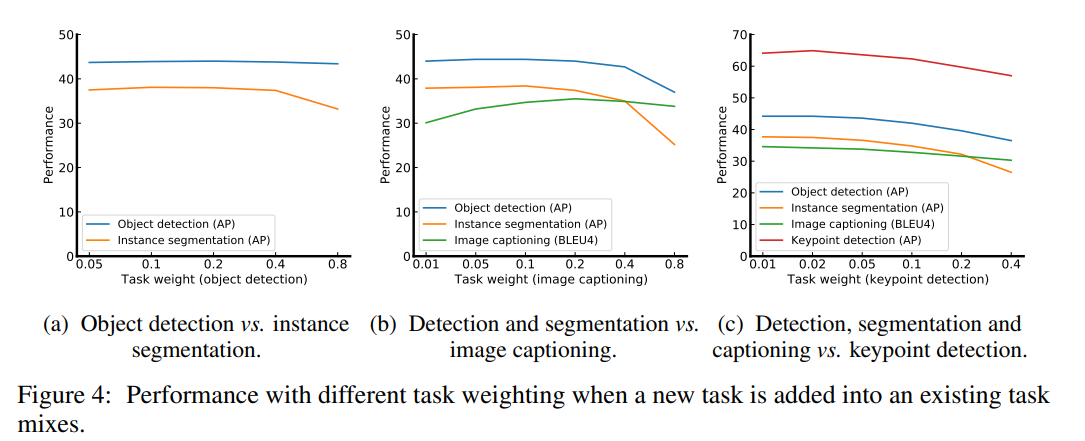
greedy 을 각 task 에 사용하여 적합한 loss weighting 을 선택한 것을 Figure 에서 볼 수 있다.
Figure 4a 에서 object detection 과 instance segmentation 간의 weight 비율을 탐색한다.
광범위한 weight 비율의 경우 두 작업의 성능이 모두 피크에 가까워서 두 작업에 대해 2:8 weight 비율을 선택한다.
이후, image captioning task 를 추가하고, captioning task 의 서로 다른 weighting 에서의 성능을 Figure 4b 에서 확인할 수 있으며, 여기서 기존 task 와 image captioning task 에 대한 9:1 weighting 비율이 적절하다는 것을 알 수 있다.
마지막으로, keypoint detection task 를 추가하면, Figure 4c 에서, 이 weight 가 상대적으로 작게 설정될 수 있으며 0.01 을 사용하기로 선택한다.
3.3 Qualitative results
보다 시각적이고 직관적인 방식으로 모델의 기능과 성능을 입증하기 위해, object detection, instance segmentation, keypoint detection 및 image captioning 과 같은 네 가지 각 task 에 대해 COCO 검증셋으로부터 선택된 이미지에 대한 multi-task 모델의 출력을 보여준다.

Figure 5 에서 object detection task 결과를 보여 준다.
이 모델은 어수선한 장면에서도 크기가 다른 물체들을 성공적으로 감지한다.


instance segmentation 과 keypoint detection 에 대한 경험적 결과는 Figure 6, 7 에서 보여준다.
두 task 에서 multi-task 모델은 localized 및 정확한 예측을 생성한다.
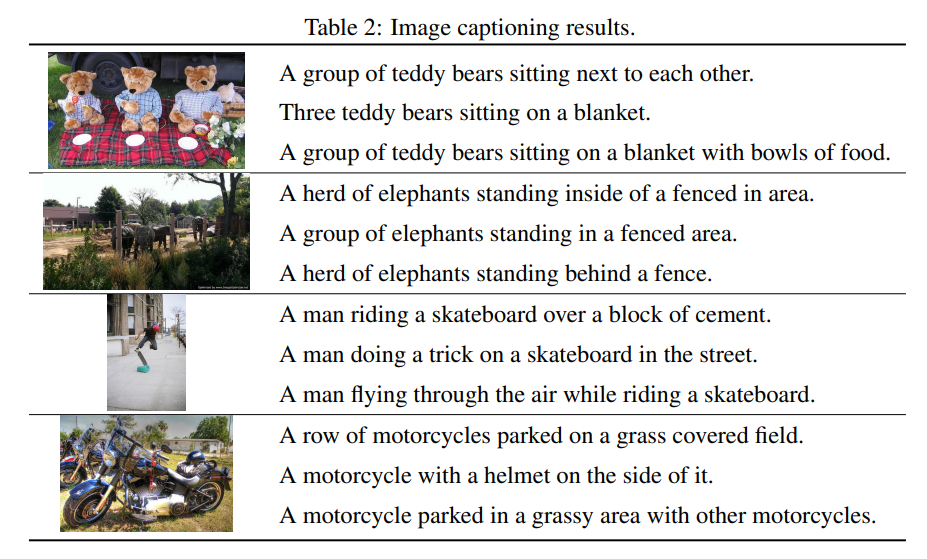
또한 Table 2 에서 생성된 몇 가지 caption 을 보여준다.
이러한 결과로, 저자는 모델이 대규모 이미지 텍스트 데이터셋을 사용하여 사전 훈련되지 않았다는 것에 주목하며, 이는 모델의 captioning 성능이 크게 향상될 것으로 예상된다.
5. Conclusion
본 연구에서, task description (prompt) 과 task output 모두 토큰의 discrete sequence 로 표현되는 다양한 "핵심" vision task 의 다양한 셋을 해결하기 위한 통합 시퀀스 인터페이스를 탐구한다.
이는 아키텍처 및 loss function 이 task 간에 공유된다는 점에서 multi-task vision model 의 기존 규범에서 크게 벗어난다는 것으로, 이러한 모델이 잘 확립된 task-specific model 에 비해 경쟁력 있는 성능을 달성 할 수 있음을 보여준다.
이 연구에는 제한이 없으며, 기존 접근법에서 크게 벗어났기 때문에 이 아키텍처와 다른 훈련법 모두가 특화된 시스템의 SOTA 에 더 개선됬다고 믿는다.
또한 더 큰 데이터셋(예; image-text pairs) 에 대한 pretraining 또는 더 큰 모델 사이즈를 사용하는 것 모두에서 확장의 이점을 크게 얻을 수 있다고 믿는다.
다른 한계는 접근법이 autoregressive 모델링에 기반하여 특화된 시스템에 비해 추론 속도가 잠재적으로 느릴 수 있다.
효율성을 향상시키는 몇 가지 방법이 있는데, 여기에 non-autoregressive sequence 모델링 사용이 포함된다.
본 연구에서, 모델 추론 속도를 높이기 위해 병렬 쿼리를 활용한다. 예로, 여러 사람의 포즈를 예측하는 것은 독립적인 (모델 자체로 감지되거나 미리 주어진) bounding box 로 모델에 prompt 를 표시하여 독립적으로 수행할 수 있어, 유일한 순차적 예측은 몇 개의 keypoint 를 가진 single person 으로 제한된다.
instance segmentation 에도 동일한 전략을 적용할 수 있다.
통합 인터페이스의 최적 구현에는 여전히 더 많은 연구가 필요하고 이 task 에서 탐색된 시퀀스 인터페이스는 잠재적인 구현 중 하나에 불과하지만, 저자는 다양한 task 들이 표현되는 방식의 인터페이스가 향후 범용 인공지능 시스템에서 점점 중요한 역할을 할 것이라 믿고 있다.
