논문 및 이미지 출처 : https://arxiv.org/abs/2203.14940
Yu Du1 Fangyun Wei2† Zihe Zhang1 Miaojing Shi3† Yue Gao2 Guoqi Li1
1Tsinghua University 2Microsoft Research Asia 3King’s College London
Abstract
최근, vision-language pre-training 은 open-vocabulary object detection 에서 큰 잠재력을 보여준다. 여기서, class 에 기반하여 훈련된 detector 는 새로운 class 를 감지하는데 사용된다.
class text embedding 은 먼저, pre-trained vision language model 의 text encoder 에 prompt 를 줌으로써 생성된다.
그러고 난후 이는 detector 의 학습을 지도하기 위해 region classifier 처럼 사용된다.
이 모델을 성공적으로 이끌기 위한 주요 요소는 세심한 단어 tuning 과 독창적인 설계를 요구하는 proper prompt (올바른 프롬프트)이다.
힘든 prompt engineering 을 피하기 위해, image classification task 에 대해 제안된 몇몇 prompt representation learning methods 가 있다. 그러나 이 방법은 detection task 에 적용됐을 때 차선책의 솔루션일 수 밖에 없다.
본 논문에서, 저자는 새로운 방법인 detection prompt (DetPro) 을 도입하며, pre-trained vision-language model 을 기반으로 한 open-vocabulary object detection 에 대한 continuous prompt representations 를 배우기 위해 도입한다.
이전의 classification 지향적 method 와 달리, DetPro 는 두 가지 하이라이트가 있다.
- 이미지 백그라운드의 proposals 를 prompt training 에 포함시키기 위한 background interpretation scheme
- prompt 맞춤형 training 을 위해 이미지 포그라운드의 proposals 를 분리하는 context grading scheme
저자는 최근에 SOTA 인 open-world object detector 의 ViLD 와 DetPro 를 조합하고 LVIS 을 비롯한 Pascal VOC, COCO, Object365 데이터셋의 transfer learning 에서 실험을 했다.
실험 결과, DetPro 는 baseline ViLD 의 모든 설정에서 보다 우수한 성능을 보여주었다.
예로, 와 는 LVIS 의 새로운 클래스에서 개선을 보였고, 코드와 모델은 https://github.com/dyabel/detpro 에서 확인 가능하다.
1. Introduction
Object detection 은 이미지 내 객체의 bounding boxes 를 찾고 레이블을 할당하는 것을 목표로 한다.
지난 몇년 간, object detection 은 closed-set 문제 즉, detector 가 training set 에 포함된 classes 를 감지할 수 있는 것을 해결하는 데 큰 성과를 거두었다.
detection vocabulary 를 증가시키기 위해, 일반적인 관행은 희망하는 class 가 있는 더 많은 데이터를 모으는 것이다. 외에는 비용적으로 비싼 라벨링 과정이 있고, 이는 object class 의 long-tailed distribution 을 야기 한다.
이에 detector 는 데이터셋의 자주 발생하는 category 의 overfitting 을 피하기 위해 세심한 설계가 필요하다. 대조적으로, detection vocabulary 증가에 대한 대체적인 방법으로는 open-vocabulary object detection (OVOD) 가 있다. 여기서 detector 는 base class 로 학습되며 새로운 class 를 감지하기 할 수 있는 능력을 갖춘다.
최근에, ViLD 는 OVOD 에 대한 프레임워크를 도입했으며, 이 프레임워크는 pre-trained vision-language model 의 지식을 추출하여 detector 에 활용한다.
이는 최근 vision-language pretraining (e.g. CLIP, ALIGN) 의 발전에 영감을 받았다. 이러한 기술은 주로 image encoder 와 text encoder 로 별개의 두 가지 encoder 는 image 와 대응하는 text 사이의 정렬을 극대화 하는데 사용된다.
ViLD 의 구현에서, class text embedding 을 생성하기 위해 prompt 로 알려진 base class 의 text 설명을 CLIP 의 encoder 에 제공한다.
이 embedding 은 object proposals 를 분류하기 위해 활용되며 detector training 을 지도한다.
open-set object detection 을 수행하기 위해, base class text embedding 은 base 와 novel class 의 embedding 으로 대체된다.
prompt engineering 으로 알려진 prompt 설계는, 약간의 단어 변화만 있어도 detection 성능에 명백히 긍정적이거나 부정적인 영향을 미침을 관찰하는 것과 같은 과정에 있어서 중요하다.
proper prompt 설계는 domain expertise 와 ViLD 논문과 같이 인간으로 부터의 세심한 단어 tuning 이 필요하다.
이러한 고급 기술 및 인간의 상대적으로 번거로운 요구를 피하기 위한 대안 방법은 continuous representations 를 사용하여 prompt 의 내용을 자동적으로 학습하는 것이다.
저자는 작업물 내에서 이를 prompt representation learning 이라 명명하였다.
본 논문에서, 저자는 prompt representations 를 학습하기 위해 pre-trained vision-language model (OVOD-VLM) 이 있는 open-vocabulary object detection 의 세팅에서, detection prompt (DetPro) 라는 새로운 방법을 제시한다.
pre-trained vision-language model 에 기반하는 image classification 정확도 개선을 목표로 하는 CoOp 와 같은 prompt representations learning 에 초점을 맞춘 최근 작업들이 몇몇 있다.
OVOD-VLM 에 직접적으로 CoOP 를 적용하는 것은 현실적이지 않다.
image classification 은 input image 의 올바른 라벨 인식만 필요한 반면 object detection 은 background 로부터 foreground 를 구별하기 위한 감지기를 필요하며, 서로 다른 object class 에서 foreground 의 region proposals 를 분류하기 때문이다.
그래서 저자는 image 의 ground truth 에 대한 positive proposals 과 negative proposals 에 기반한 OVOD-LVM 에서 prompt representations 를 자동적으로 학습하기 위해 새로운 Detection Prompt (DetPro) 를 도입한다.
object detection 의 Prompt learning 은 두 가지 중요한 이슈에 대해 직면한다.
- Negative proposals 는 object detection 에 매우 중요함에도 불구하고, object class 를 명시하는데에는 부합하지 않다. 그러므로 prompt learning process 에 쉽게 포함될 수 없다.
- image classification 의 중심이 되는 object 와 이미지가 큰 것과 달리, positive proposals 의 object 는 종종 다른 수준의 contexts 와 연관되어, 이러한 proposals 에 대한 하나의 prompt context 를 배우는 것은 충분하지 않다.
이를 해결하기 위해 다음을 도입한다.
- 다른 모든 class embedding 으로 부터 멀리 떨어지도록 negative proposals 의 embedding 을 최적화하는 negative proposals 포함을 위한 background interpretation scheme
- 서로 다른 context 수준에 해당하는 다른 positive proposal sets 에 대한 prompt representation learning 을 조정하는 tailored positive proposals 가 있는 context grading scheme
저자는 ViLD 와 DetPro 을 조합과 일련의 LVIS 실험을 포함 및 VOC, COCO, Object365 를 포함하는 다른 데이터셋에 LVIS-trained model 을 transfer 했다.
모든 세팅에서, DePro 는 ViLD 보다 좋은 성능을 냈다. 예로 와 는 LVIS 의 새로운 class 에서 개선을 보였다.
2. Related Work
Prompt Learning
최근에, 큰 사이즈의 vision-language model (VLM, 예: CLIP, ALIGN) 의 개발이 생겨났고 few-shot 또는 zero-shot learning tasks 에서의 응용을 발견했다.
VLM 은 web 에서 모은 image-text 쌍의 거대한 양에서 학습되었으며 contrastive learning 은 image 와 text embedding 을 정렬하기 위해 채택되었다.
pretrained VLM 은 finetuning 또는 prompt engineering 두 downstream tasks 에 대한 transfer 을 할 수 있다.
작업별 prompt 는 성능을 크게 향상시킬 수 있지만 힘든 prompt engineering 이 요구된다.
language tasks 의 prompt learning 에 의해 영감을 얻은 CoOp 는 few-shot classification 에 대한 prompt engineering 자동화를 위해 context 최적화를 제시한다.
이는 적은 데이터 셋에서 end-to-end 로 학습된 continuous representation 으로 prompt 의 context 를 모델링 한다.
본 논문은 이미지 내의 foreground proposals 와 background proposals 를 처리하기 위해 특정 전략을 설계 함으로써 CoOP 를 OVOD 로 확장한다.
CoOP 가 모든 categories 의 샘플로 prompt 를 학습하는 반면 DetPro 는 base classes 에서만 훈련되고 novel class 로 일반화될 것으로 예상된다.
Open-Vocabulary Object Detection
computer vision 분야에서 DNN 의 주목할만한 성공에도 불구하고, object detection 의 만족스러운 결과를 얻기 위해 종종 annotated data 의 많은 양을 요구한다.
큰 데이터와 정교한 annotation 에서 DNN 의 신뢰성을 완화하기 위해서, semi-supervised learning, few-shot learning, zero-shot learning, self-supervised learning, open-set learning 및 advanced training 전략과 같은 서로 다른 파라다임들을 도입한다.
특히, zero-shot detection task 에 대해, (bounding box annotations 이 있는) seen classes 에서 unseen classes 로 일반화하는 것을 목표로 한다.
약간의 진전이 있었음에도, 전체 성능은 여전히 fully-supervised method 에 한참 뒤쳐져 있다. 그러므로 이에 대한 연구는 아직 번창하지 않았다.
최근에, open-vocabulary object detection 은 zero-shot detection 보다 stage 에서 더 일반적이고 실용적인 파라다임으로 부상한다.
concepts 의 unbounded vocabulary 는 먼저 image-text 쌍에서의 훈련으로 얻는다. 그후 detector 는 다수의 base class 의 bounding box annotations 를 사용하여 novel class 를 감지하는 것이 요구된다.
전형적인 해결책은 OVR-CNN 및 ViLD 를 포함하는 것이다. OVR-CNN 은 image-caption 쌍의 corpus 를 사용하여 백본을 pretrain 했고 few object categories 의 annotation 만으로 detector 를 finetune 하는 반면 ViLD 는 pretrained open-vocabulary classification model 의 지식을 직접적으로 추출하여 two-stage detector 에 사용한다.
저자는 OVOD 설정으로 작업을 배치하고 ViLD 를 기반으로 솔루션을 구축한다.
ViLD 는 class embedding 생성에 대해 hand-crafted prompt 를 사용하는 반면, 저자 fine-grained 자동 prompt learning 과 특정 background interpretation 을 설계하여 원하는 prompt 를 찾는다.
3. Problem Setting
DetPro 의 목표는OVOD-VLM 에 대한 continuous prompt representations 을 학습하는 것이다.
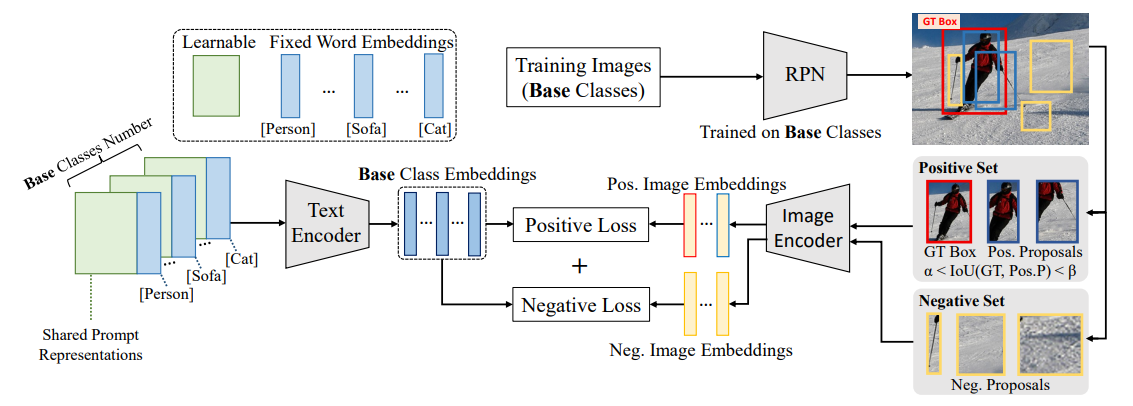
위 그림은 DetPro 의 개요를 보여주며,두 가지 주요 요소를 포함하고 있다.
- negative proposal 포함에 대한 background interpretation
- tailored positive proposals 가 있는 forground context grading
위 두 가지는 그림 내에서 positive losses 와 negative losses 를 전담한다.
그 뒤, 저자는 아래 그림의 최근 OVOD pipeline ViLD 에서 DetPro 를 고안했다. 여기서 DePro 는 ViLD 의 proposal classifier 를 대체하여 자동 prompt engineering 을 실현한다.
Data Split
저자는 detection dataset 의 categories 를 base classes 와 novel classes 에 대한 두 개의 분리된 세트로 나눈다.
저자는 와 을 base 와 novel classes 각각을 나타내기 위해 사용한다.
이에 상응하여, 저자는 training 과 inference 데이터셋 각각에 대한 와 를 가진다.
는 training 에 대한 annotation 과 base class 를 포함하는 반면, 는 와 두 object 를 인식하기 위해 trained model 에 대한 와 를 모두 포함한다.
Pre-trained Vision-language Model
저자는 CLIP 을 vision-language model 로 사용하며, 이 모델은 text encoder 과 image encoder 을 포함한다.
는 class 의 prompt representation 인 input 을 사용하며 해당하는 text embedding 을 출력한다. 이는 저자의 작업에서 class embedding 이라고도 한다.
은 사이즈의 이미지를 input 으로 사용하며 해당하는 image embedding 을 출력한다.
Detection Framework
저자는 ResNet-50 및 FPN 을 detector 로 사용하는 Faster-RCNN 을 채택한다.
4. Method
저자는 먼저 image classification 에서의 prompt representation learning 을 검토하고 난 후, object detection 에서 DetPro 를 제시한다. 마지막으로 OVOD 에 ViLD 를 결합한다.
4.1. Preliminaries: Prompt
기존 CLIP 은 image classification 을 위한 class embedding 을 생성하기 위해서 사람이 정의한 prompt (예로, 'a photo of '') 를 text encoder 로 제공한다.
특정한 겨우, 는 'person' 및 'cat' 과 같은 class name 으로 대체된다.
proper prompt 를 식별하는 것은 사소하지 않은 task 며, word tuning 에 대한 막대한 양의 시간이 필요하다.
이를 우회하기 위해, CoOp 는 prompt representations 자동 학습을 제시한다.
주어진 class 에 대한 학습가능한 prompt representation 는 다음과 같이 정의된다.
여기서 는 -th 학습가능한 context vector 를 나타내며, 는 base class 의 고정된 class token, 은 context 길이다.
은 사람이 정의한 prompt (예로, 'a photo of') 의 context 와 유사할 수 있는 반면, 는 class name 와 유사하다.
는 word embedding (여기선 512) 와 동일한 차원을 가지기 위해 무작위로 초기화된다.
학습 가능한 prompt context 는 class 간에 공유되며, 새로운 class 가 왔을 때, 이의 prompt representation 은 식 (1) 에 의해 쉽게 얻을 수 있다.
class 의 class embedding 는 를 CLIP text encoder 로 제공함으로써 생성될 수 있다.
image classification task 에서 주어진 이미지 가 있으며, 저자는 image embedding 을 추출하기 위해 먼저 이것을 CLIP image encoder 에 제공하였다.
이 이미지가 class 에 속한다고 가정하면, class 로 분류될 의 확률은 다음과 같이 계산된다
여기서 는 temperature 파라미터이고, 은 코사인 유사도를 나타낸다.
cross entropy loss 는 를 최적화하기 위해 사용하는 반면, 과 는 고정된다.
4.2. Detection Prompt
Naïve Learning
Object Detection 은 object 의 ground truth bounding boxes 에서 제공된 class labels 을 가지고 있는 각 훈련용 이미지와, object 의 bounding boxes 의 localize 를 필요로 하고 class labels 을 예측하는 각 테스트용 이미지에 대해서는 image classification 과 다르다.
prompt representation learning 전략 CoOP 를 detection task 로의 채택을 위해서, 간단한 방법은 classification 시나리오를 시뮬레이션하는 것이다.
주어진 이미지 가 있고, 저자는 대신 잘게 잘려진 ground truth bounding boxes 를, 각각의 box embedding 를 얻기 위해서 CLIP image encoder 에 제공한다.
각 ground truth box 는 하나의 object class 에만 속한다.
저자는 이미지 상의 모든 ground truth bounding boxes 를 로 표시한다. 그후 의 region-level classifier 를 학습하기 위해 (3, 4) 와 같은 식을 따를 수 있다.
이 classifier 는 설립된 object detection pipeline (예로 Faster R-CNN) 과 조합될 수 있다.
이러한 단순한 적용은 일정 수중까지는 작동할 수 있지만, 차선책의 솔루션일 뿐이다.
- bround boxes 외의 이미지의 풍부한 정보는 foreground 와 background proposals 를 포함하여 제거되었기 때문
- 하지만 이것은 detection 을 위한 강력한 region-level (proposals) classifier 를 학습하는데 필수적이다
Fine-grained Solution
image proposals 의 활용하기 위해서, 저자는 에서 추출하기 위해 먼저 base classes 에서 PRN 을 학습한다.
Foreground proposals 은 임계값 (예: 0.5)보다 큰 의 한 ground truth 에 대한 IoU 인 반면, background proposals 는 임계값보다 작은 의 모든 ground truth 에 대한 IoU 의 negative proposals 이다.
저자는 와 의 합집합은 positive proposals set (예: ) 을 형성하고 는 negative proposal set (예: ) 을 형성한다.
의 proposals 경우, target object 내부에 타이트하게 bounding 된 ground truth 가 아닌 한, 일반적으로 주변의 많은 context 가 있는 object 의 큰 부분을 포함한다.
따라서 positive proposals 는 ground truth 에 대한 IoU 에 따라 context 가 많이 다르다. 이는 에 입력할 때 visual embedding 이 다르게 생성된다. 따라서 서로 다른 prompt representations 도 다른 prompt context 에 전용으로 학습되어야 한다.
이러한 이슈를 해결하기 위해, 저자는 맞춤형 positive proposals 와 context grading scheme 를 도입한다.
반면에, 에서의 proposals 경우, 대부분이 target object 의 작은 부분이 포함될 가능성이 있는 background 이 포함되어 있다.
background 는 특정 class name 이 없으며, 따라서 이의 prompt representation 은 직접적으로 얻을 수 없다 (식 1 에 가 없음), 또한 class embedding 도 없다.
Negative proposals 은 object detection 의 중요한 역할을 한다. 저자의 detection prompt 에 활용하기 위해, negative proposal inclusion 을 위한 background interpretation scheme 를 도입한다.
negative proposal inclusion 에 대한 Background interpretation 에서 Background 내부에 몇몇 object classes 를 포함할 수도 있지만, 일반적으로 너무 작거나, 너무 불완전하거나, 너무 막연한 결과로 인식될 수 없다.
다른 말로, negative proposals 이 주어지면, 의 image embedding 은 의 다른 classes 의 어떠한 text embedding 와 유사하지 않아야 한다.
class 로 분류될 의 확률 은 식 3 을 통해 계산될 수 있다. 저자는 가 작기를 원한다.
- 관행적으로, 는 크기 때문에, 간단하게 어떤 를 로 최적화할 수 있다.
- 이는 negative proposal 이 어떤 object classes 와 동일하게 되도록 강제한다.
따라서 loss function 은 다음과 같이 공식화한다.
background interpretation 에 대한 대안 방법은 class 에 대한 와 유사하지만 class token 이 없는 독립형의 background prompt representation 를 학습하는 것이다.
유사하게, 저자는 background embedding 를 생성하기 위해 식 2 를 사용하고 을 생성하기 위해 negative proposal 을 에 제공한다.
확률 는 다음과 같이 계산된다.
netagive loss 는 다음과 같이 계산된다.
이 대안법은 첫 번째 방법보다 못하다. background content 는 매우 다양할 수 있으며, 두 번째 방법은 모든 negative proposals 이 근접하도록 명시적인 background embedding 을 학습하지만, 충분하지 않다.
대조적으로 첫 번째 방식에서는 각 negative proposal 이 다른 모든 class embedding 으로부터 멀어지도록 암시적으로 해석되며, 이는 더 강력해질수있다.
Context grading with tailored positive proposals 에서, positive proposal 은 target object 에 대한 서로 다른 context 를 포함할 수 있다. 이 차이는 prompt context 에서 유사할 수 있다.
- object class 의 ground truth bounding box 가 주어졌을 때, 'a photo of 라 할 수 있다.
- 반면 object 일부의 foreground proposal 이 주어졌을 때, 대신에 'a photo of partial 이라 할 수 있다.
'a photo of' 와 'a photo of partial' 에 대한 학습된 prompt context representations 는 다를 것이며, 두 유형의 prompt 에 대한 서로 다른 class embedding 으로 끝날 것이다. 이는 각각 다른 수준의 context 에 해당하는 positive proposals 로 최적화 되어야 한다.
저자는 이러한 목적을 위해 tailored positive proposals 와 foreground context grading scheme 를 도입한다.
구체적으로, 저자는 IoU 범위 의 positive propsals 를 와 같이 IoU 간격이 인 K 의 분리 그룹으로 나눈다.
foreground context 는 다른 그룹으로 등급이 매질 것이며, 각 그룹 내의 positive proposals 은 각 ground truth 에 대한 유사한 context level 을 가진다.
그러므로 저자는 그룹에서 prompt representations 를 독립적으로 학습한다.
-th 그룹 내에서, 저자는 class 안의 어떠한 positive proposals 에 대한 visual embedding , 을 추출하고, 확률 을 계산 및 positive loss 를 최적화 하기위해 동일한 식 (3,4) 을 따른다.
동일한 negative proposal set 은 각 그룹을 포함하므로, 각 그룹 내의 최종 loss function 은 다음과 같다.
prompt representation 는 class 에 대한 각 그룹에서 학습된다.
마지막으로, 학습된 representations 는 와 같이 평균함으로써 그룹 상에서 앙상블 된다.
4.3. Assembling DetPro onto ViLD
ViLD 는 OVOD 에 대한 최근 프레임워크다.
이는 CLIP 의 지식을 두 가지 stage detector (예: Faster R-CNN) 으로 사용한다.
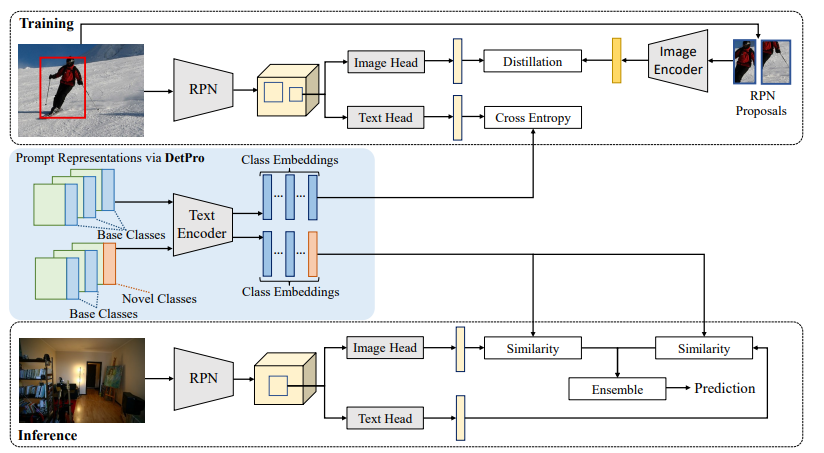
그림 2 에서 ViLD 이 있는 DetPro 의 조합을 보여준다.
Training ViLD with DetPro
학습된 DetPro 는 base classes 에 대한 식 1 을 기반으로 prompt representations 을 생성한다. 여기서, base class embedding 을 생성하기 위해 에 제공할 수 있다. embedding 은 detector 에 대한 proposal classifer 로 사용된다.
ViLD 에 따라, 주로 image head 와 text head 인 두 가지 R-CNN heads (sub-branches) 를 채용한다.
image herad 는 CLIP image endoer 의 지식을 추출하면서, text head 는 기존 R-CNN classifier 을 base class embedding (고정됨) 과 학습 가능한 background embedding (그림 2) 로 대체한다.
저자는 논문 ViLD 의 훈련 과정을 간단히 설명해 준다.
- 각 region proposal 은 RPN 에 의해 생성되며, 각각의 text head 와 image head 로 통과하여 후속의 loss 계산을 위해 두 개의 RoI feature 를 추출한다.
여기에 두 가지 losses 가 있다.- text head 의 경우, RoI feature 와 base class embedding 간의 코사인 유사도는 classification 을 위해 계산되며 표준 cross entropy 를 채택했다.
- image head branch 의 경우, RPN 으로 생성된 proposals 를 잘게 자르고 리사이징하여 image embedding 을 생성하기 위해 에 제공한다.
- loss (예: ) 는 image head 에 의해 추출된 image embedding 과 해당하는 RoI feature 간의 거리를 최소화하기 위해 적용됐다.
- image embedding 의 생성은 pre-trained RPN 을 사용하여 오프라인으로 수행될 수 있다.
- 전체 classification loss 는 와 의 가중치 합이다.
추가적으로, 2 stage class 별 bounding box regression 및 mask prediction layer 를 class 독립 모듈로 대체한다. 표준 regression loss 와 mask prediction loss 또한 훈련 중에 사용된다.
Inference ViLD with DetPro
inference 단계에서, base 와 novel classes 에 대한 prompt representation 을 생성하기 위해 식 6 을 사용한다. 그리고 class embedding 은 prompt representation 을 에 줌으로써 추출된다.
공유된 context vector 덕분에, DetPro 에 의해 최적화된 prompt representations 는 base class 에서만 훈련했지만 novel class 에도 잘 일반화될 수 있다.
text image 가 주어질 때, RPN 은 먼저 proposals set 을 생성한다. DetPro 는 text head 와 image head 를 통해 각 proposal 을 전달하여 두 개의 RoI features 를 추출한다. (그림 2 참조)
각각의 경우, confidence score 를 얻기 위해 모든 class embedding 과의 코사인 유사도를 계산한다. 에 대한 최종 확률은 두 confidence score 의 기하학적 평균이다.
5. Experiment
5.1. Dataset and Evaluation Metrics
LVIS v1 데이터셋에서 주 시험을 수행한다.
DetPro 와 이의 open-vocabulary object detector 는 LVIS base classes 에서 훈련되고 DetPro approch 의 평가는 LVIS novel classes 에서 진행한다.
그 동안, 저자의 접근법인 생성 기능을 입증하기 위해 transfer 시험을 수행하고 Pascal VOC test set, COCO 검증셋 그리고 Object 검증셋에서 LVIS-trained model 을 평가한다.
LVIS V1 Dataset
Pascal VOC Dataset
COCO
Object365 Dataset
Evaluation Metrics
저자는 object detection 과 segmentation 의 성능을 평가하기 위해 AP (average precision) 을 사용한다.
LVIS 시험의 경우, 은 주요 indicator 이며, 와 의 결과도 보고한다.
Pascal VOC, COCO, Object365 에서 transfer 시험을 하면서, , , , , , 을 평가지표로 사용한다.
5.2.2 Implementation Details
DetPro
ViLD and Object Detector
Vision-Language Model
5.3. Main results
Experiment on LVIS v1 Dataset
Transfer to Other Datasets
