논문 및 이미지 출처 :
https://arxiv.org/pdf/2203.02155.pdf
https://openai.com/blog/chatgpt
논문 제목 : Training language models to follow instructions
with human feedback
ChatGPT Blog
Abstract
큰 규모의 language 모델은 허위나 toxic 을 유저에게 생성할 수 있다.
다시 말해, 모델이 사용자의 원하는 답과 일치하지 않음을 뜻한다.
본 논문에서는 다음 방법을 제안한다.
- 라벨러가 쓴 prompt 와 OpenAI API 로 제출된 prompt 의 셋으로 입증된 데이터셋을 모음
- 지도 학습으로 GPT-3 를 supervised fine-tune 한다.
- 모델 output 에 랭킹을 매김
- human feedback 으로 강화 학습을 진행하여 지도 학습된 모델을 fine-tune
위 과정을 통해 나오는 결과 모델을 InstructGPT 라 칭한다.
이 모델은 175B GPT-3 보다 100배 적은 1.3B 파라미터로 허위가 줄고, 신뢰있도록 개선되었다.
1. Introduction
최근의 Large language models (LMs) 는 인터넷의 정보들을 토큰으로 예측하기 때문에 사용자가 원하는 지시와는 다를 수 있다. 따라서 이는 모델과 유저의 목표가 불일치하다고 할 수 있다.
따라서 사용자의 지시와 일치하는 행동을 하도록 훈련을 하여 aligning 한 언어 모델을 만든다.
여기에 aligning language model 를 위해 fine-tune 접근법에 초점을 맞춘다.
특히, broad class (instructions) 로 GPT-3 를 fine-tune 하기 위해 human feedback 으로 강화학습을 한다. ( RLHF )
이 모델 (InstructGPT) 과정은 다음과 같다.
- 40명의 라벨러로부터 입증된 데이터셋을 모아 GPT-3 를 supervised fine-tune (SFT)
- 라벨러가 선호하던 output 으로 예측할 수 있도록 reward model (RM) 으로 훈련
- 이 RM 을 PPO optimization 으로 강화 학습
이 모델은 GPT-3 를 사용했으며, 사이즈가 1.3B, 6B, 175B parameter 를 가진다.
주요 결과는 다음과 같다.
- 라벨러가 GPT-3 결과보다 InstructGPT 결과를 더 선호
- InstructGPT 가 GPT-3 의 truthfulness 를 개선
- InstructGPT 가 GPT-3 의 toxicity 를 조금 개선, 그러나 bias 는 개선을 보이지 않음
- RealToxicityPrompt 데이터셋으로 toxicity 를 측정
- GPT-3 보다 25% 더 적은 toxic output 을 생성
- Wingogender 와 CrowSPairs 데이터셋은 GPT-3 보다 나은 개선은 보이지 않았다.
- RLHF 를 수정하여 공개 데이터셋의 성능 저하를 최소화
- RLHF fine-tuning 하는 동안 SQuAD, DROP, HellaSwag, WMT 2015 데이터셋에서 GPT-3 와 비교하여 성능 저하를 관찰했다.
- PPO 와 pretraining 분포의 log-likelihood 의 증가를 혼합하여 성능 저하를 감소
- 데이터를 생성하지 않은 보류중인 라벨러의 선호도를 일반화
- 공개 데이터셋에는 InstructGPT 에 사용된 방식을 반영하지 않음
- InstructGPT 는 RLHF fine-tuning 에 벗어난 명령에도 좋은 일반화를 보임
- InstructGPT 는 여전히 약간의 실수가 있음
2. Related Work
3. Methods and experimental details
3.1 High-level methodology
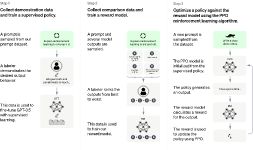
방법론은 다음 세 가지 스텝을 따른다.
-
입증된 데이터를 모아, supervised policy 훈련
- 라벨러로부터 입증된 데이터 수집
- pretrained GPT-3 를 supervised learning 하여 fine-tuning
-
비교 데이터를 모아, reward model 훈련
- 모델 output 을 비교하여, 라벨러가 어떤 것을 선호하는지 랭킹 부여
- 이후 reward model 을 훈련
-
PPO 로 reward model 에 대한 policy 를 최적화
- RM 에 PPO 알고리즘을 사용하여 supervised policy 를 최적화하며 fine-tuning
3.2 Dataset
본 논문의 데이터셋에는 OpenAI AIP 로 제출된 text prompt 가 포함되어 있디.
처음 InstructGPT 를 학습할 때, 라벨러에게 스스로 prompt 를 작성하라고 요청했다. 이 이유는 모델이 스스로 작동하기 위한 instruct-like prompt 초기 자원이 필요하다.
또한 라벨러에게 다음의 3가지 종류의 prompt 를 작성하길 요청했다.
- Plain : 간단한 arbitrary task 을 생산하면서도 다양성을 가지도록 함
- Few-shot : instruction 과 이에 대응하는 질의응답 생산
- User-based : OpenAPI API 의 application 사용사례를 가지고 있으므로, 라벨러에게 사용 사례에 대응하는 prompt 를 생산하도록 요청
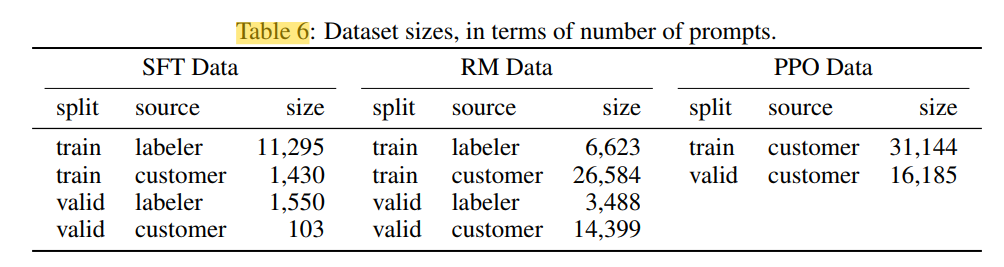
세 가지의 데이터셋을 생산하여 fine-tuning 에 사용한다.
- SFT 모델의 훈련으로 사용할 SFT dataset (13k)
- RM 모델의 훈련으로 사용할, 모델의 출력에 라벨러가 랭킹을 매긴 RM dataset (33k)
- 라벨러 없이, RLHF fine-tuning 을 위한 input 으로 사용될 PPO dataset (31k)
3.3 Task
훈련 task 는 두 가지의 형태를 지닌다.
- 라벨러가 작성한 promtpt dataset
- API 로 InstructGPT 에 제출된 prompt dataset
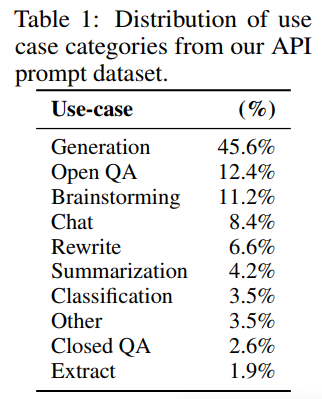
위의 prompt 는 generation, question, answer, dialog, summarization, extraction, other natural language task 를 포함하고 있다.
3.4 Human data collection
Upwork 및 ScaleAI 에서 40명과 계약 하여 정보 수집을 위한 팀을 고용
3.5 Models
먼저, pretrained language model 인 GPT-3 로 시작한다.
GPT-3 는 인터넷 데이터를 훈련한 것으로, 넓은 범위에서 downstream task 로 사용된다.
본 논문에서는 GPT-3 를 세 가지의 기술로 훈련한다.
-
Supervised fine-tuning (SFT)
- supervised learning 으로 입증된 데이터를 통해 GPT-3 를 fine-tuning 한다.
- 다음 사항들로 훈련을 진행한다.
- 16 epochs
- cosine learning rate decay
- residual dropout 0.2
- 검증셋의 RM score 를 기반으로 최종 SFT 모델을 선택
- SFT 모델이 1 epoch 이후의 검증 loss 가 overfit 하는 것을 발견
- overfit 에도 불구하고, 더 많은 에폭을 훈련하면 RM score 와 라벨러의 선호도 랭킹에 도움이 되는 것을 발견
-
Reward modeling (RM)
- SFT 모델의 마지막 unembedding layer 를 제거하여 시작
- prompt 와 response 를 사용하여 scalar reward 를 출력하도록 훈련시킨다.
- 175B RM 은 불안정하여 6B RM 을 사용
본 논문에서는 reward model 에 다음 loss function 을 사용한다.
-
- 는 prompt 에 대한 RM 의 scalar output, 파라미터 와 완성값
- 는 와 의 쌍 중에서 선호되는 완료값
- 는 사람이 비교한 데이터셋
-
RM loss 가 변하지 않아, bias 로 RM 을 normalization 한다.
-
Reinforcement learning (RL)
- 과도한 optimization 을 막기 위해 SFT 모델로부터 토큰 당 KL 패널티를 추가
- 이 value function 은 RM 에서 초기화 된다. 이러한 모델을 PPO 라 칭한다.
- PPO 로 SFT 모델을 fine-tuning 한다.
- 공개 NLP 데이터셋에 성능 저하를 고치기 위해, PPO gradient 에 pretraining gradient 를 혼합한다. 이를 PPO-ptx 라 칭한다.
RL learning 에 objective function 을 결합하여 maximize 한다.
- 는 학습된 RL policy
- 는 supervised trained model
- 는 pretraining distribution
- 는 KL reward 계수, 0.02
- 는 pretraining loss 계수
- PPO 에선 를 0, PPT-ptx 에선 를 27.8
- 본 논문에서 InstructGPT 는 PPO-ptx 모델을 선호
-
Baselines
- SFT 모델과 GPT-3 를 PPO 모델 성능을 비교
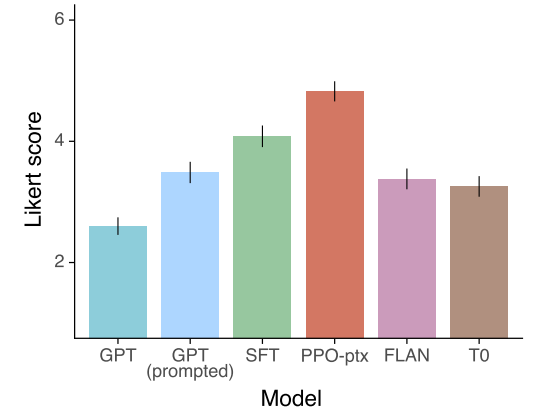
- 또한 InstructGPT 를 FLAN, TO 데이터셋에서 175B GPT-3 를 fine-tuning 한 것과 비교
3.6 Evaluation
aligned 모델을 평가 하기 위해선 context 에서 alignment 의 의미가 무엇인지 명확할 필요가 있다.
하지만 alignment 의 정의는 역사적으로도 애매하고 혼란스러운 주제이기도 하다.
결국 목표는 유저의 의도에 따르는 행동을 하는 훈련 모델인 것이다.
이전에 연구된 논문에서는 모델이 helpful, honest, harmless 하다면 aligned 한 모델이라 정의한다.
- helpful
- 모델이 helpful 하기 위해선 지시를 잘 따르고 의도를 잘 추론해야만 한다.
- 라벨러의 판단에 전적으로 의존하고, 주요 기준은 라벨러의 선호도를 따른다.
- honest
- 모델이란 큰 black box 이기 때문에 진실에 대한 추론을 할 수 없다.
- 대신 다음 두 가지 기준으로 진실함을 측정한다.
- 폐쇠적인 도메인 작업에 대한 모델의 경향 평가
- TruthfulQA 데이터셋 사용
- harmless
- 라벨러가 Playground API 에서 수집된 정보에서 유해한 것인지 평가
- 또한 RealToxicityPrompt, CrowS-Paris 같은 bias 와 toxicity 를 측정하기 위한 데이터셋을 벤치마킹
4. Result
4.1 Results on the API distribution
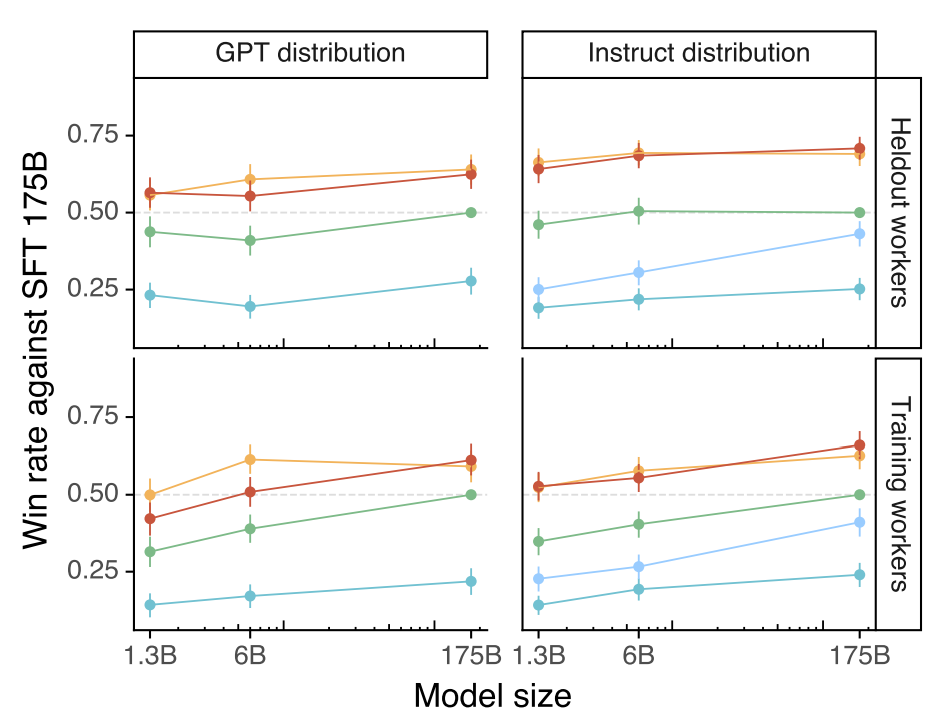
- 라벨러는 GPT-3 의 출력보다 InstructGPT 의 출력을 더 선호
- 훈련 데이터를 생성하지 않은 보류된 라벨러 의 선호도를 일반화
- 공개 NLP 데이터셋에는 InstructGPT 의 방식을 반영하지 않음
4.2 Results on public NLP datasets
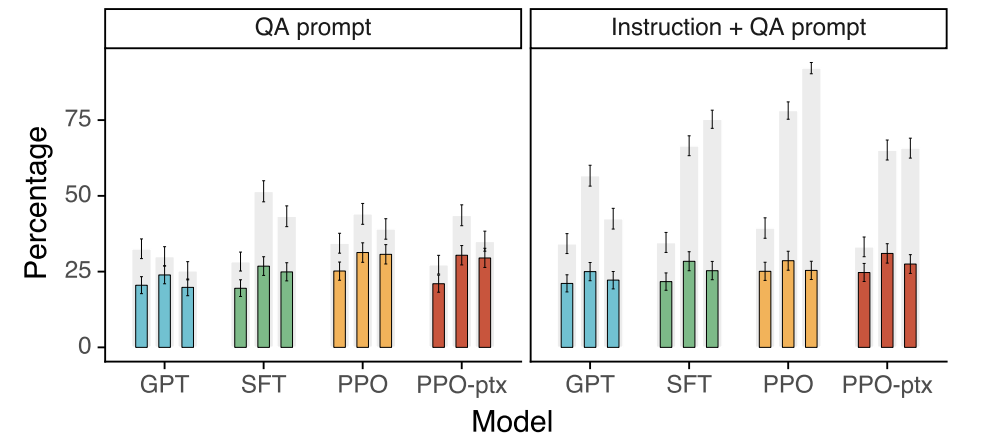
- InstructGPT 모델은 GPT-3 보다 진실함에서 개선됨

-
InstructGPT 모델은 GPT-3 보다 toxicity 는 조금 개선했으며, bias 에선 개선점이 없음
-
RLHF fine-tuning 을 개선하여 공개 NLP 데이터셋의 성능 저하를 최소화
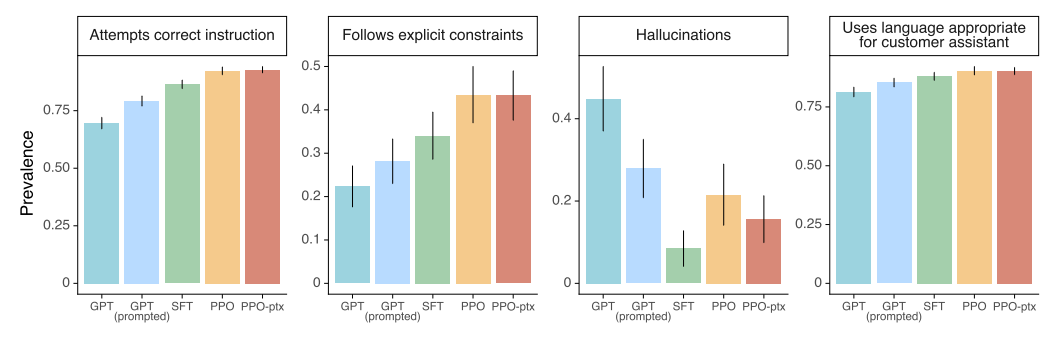
4.3 Qualitative results
- InstructGPT 는 RLHF fine-tuning 분포에서 벗어난 지시에 대해서도 일반화를 잘 함

- 위와 같이 InstructGPT 은 여전히 간단한 실수를 함
- 잘못된 전제를 가정하는 지시에 대해 혼동
- 질문에 대한 간단한 대답보다는 과도하게 얼버무림
- 지시에 여러 제약 조건이 있거나 언어 모델에 어려움이 있을 때 성능 저하를 일으킴
5. Discussion
5.1 Implications for alignment research
위의 접근법은 무엇에 work 하고 무엇을 하지 않을지의 feedback loop 이 실증적이란 것을 제공한다.
이 feedback loop 는 alignment 기술을 개선하기 위해 필수적이다.
이러한 alignment 기술인 RLHF 는 초인적인 시스템을 align 하기 위한 몇몇 제안에서 중요한 building block 이다.
이러한 작업들로, 저자는 더 일반적으로 align 연구를 끌어당길 수 있다고 한다.
- 모델 align 을 증가시키는 비용은 pretraining 보다 상대적으로 적다.
- 64.9 petaflops/s-days (175B SFT + 175B PPO-ptx) vs 3,640 petaflops/s-days (GPT-3)
- InstructGPT 에게 지도하지 않은 설정에도 지시를 잘 따라 일반화
- fine-tuining 으로 인한 성능 저하 대부분을 완화
5.2 Who are we aligning to?
5.3 Limitations
-
InstructGPT 의 행동은 계약자(라벨러)로부터 얻은 human feedback 에 의해 결정된다
→ value judgment 는 라벨러의 성향, 신념, 개인의 살아온 역사 등에 의해 영향을 받는다는 한계
-
InstructGPT 는 완전히 aligned 이거나 완전히 안전하진 않음
→ 분명한 prompt 가 없다면 여전히 toxic, violent, make up fact 를 생성함
-
InstructGPT 의 최대 한계는 실제 세계에 해롭더라도 유저의 지시에 따른다는 것이다
→ 모델이 최대로 bias 되도록 지시하는 프롬프트에 대해, InstructGPT 는 동등한 크기의 GPT-3 보다 더 toxic 한 출력을 생성한다
ChatGPT
ChatGPT 는 InstructGPT 의 형제와 같은 모델로서, prompt 의 지시에 따라 자세한 응답을 제공하는 모델
Method
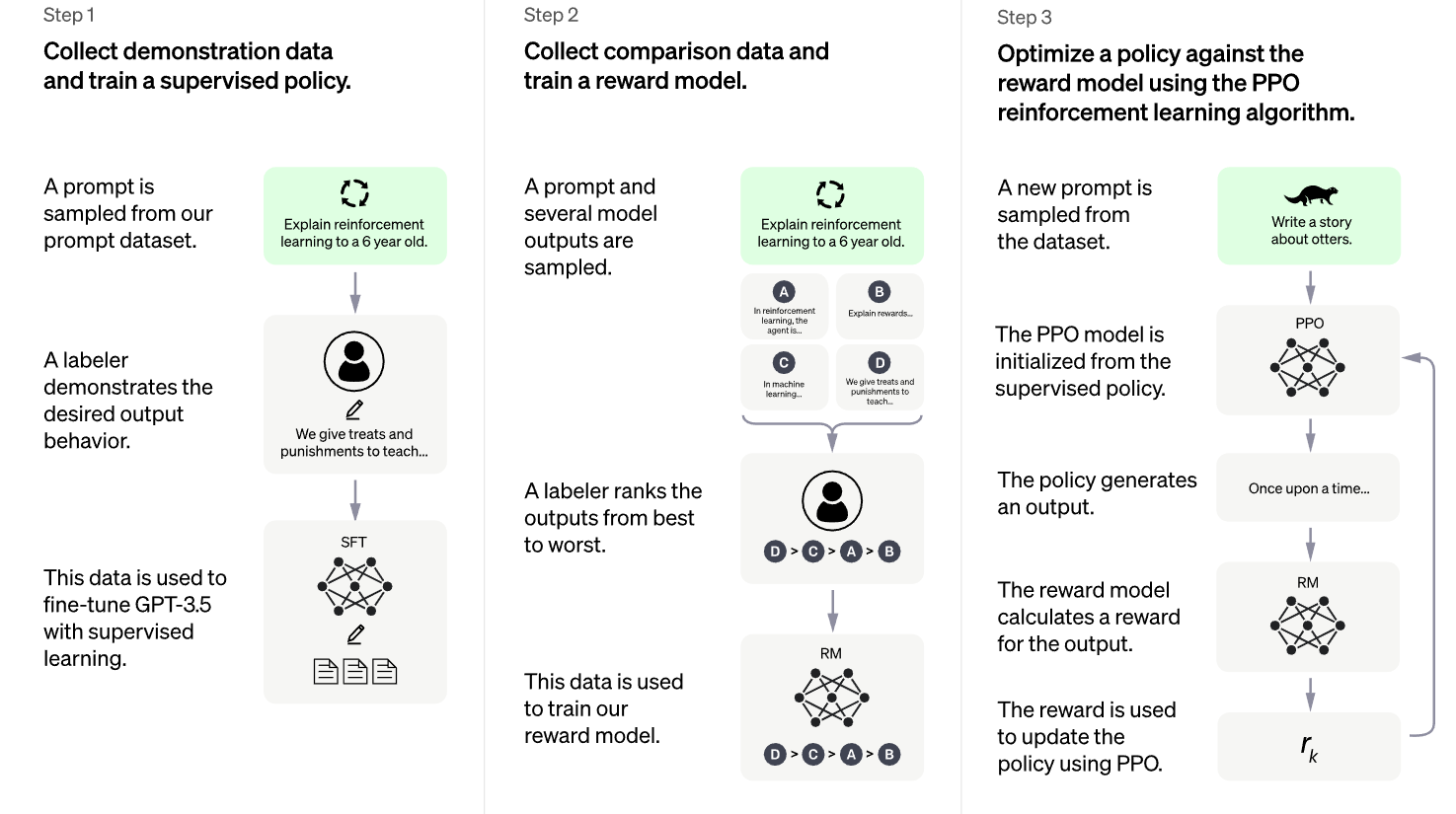
InstructGPT 와 동일한 방법(SFT+RLHF)을 사용하면서도 데이터 수집에서 약간 다르다: InstructGPT dataset + new dialogue dataset (AI Trainer 가 AI 와 대화하며 출력을 수정)
Limitations
- ChatGPT 는 그럴듯 하지만 부정확하거나 무의미한 답변 작성
- RL 훈련 중 진실의 출처가 없음
- 더 신중하도록 훈련하면 올바르게 대답할 수 있는 질문도 거부
- 이상적인 답변은 모델이 아는 것에 따라 다르기 때문에 오도를 하기도 함
- 입력 문구를 수정 하거나 동일한 prompt 의 다중 시도에 민감
- 한 문구에 대해 모른다고 하거나 문구를 약간의 수정으로 올바르게 대답 가능
- 이상적인 모델은 모호한 쿼리에 대해 명확한 질문을 해야한다.
- 현재 모델은 의도를 추측
- 모델이 부적절한 요청에는 거부하도록 노력했지만 유해하거나 편향된 행동을 보임
- 지속적인 작업으로 Human Feedback 을 수집해야함
