논문 및 이미지 출처 : http://cs231n.stanford.edu/reports/2017/pdfs/815.pdf

Abstract
- 수학 공식을 LATEX 로 변환하는 문제는 computer vision (CV) 와 natural language processing (NLP)를 모두 포함하는 문제
- 저자는 이 task 를 attention machanism 으로 encoder-decoder 세팅으로 해결
- ArXiv 에서 약 100,000 개의 LATEX 공식으로 훈련
- 평가 지표를 code level (BLEU score) 와 image level (exact match) 사용
1. Introduction
저자는 CV 분야에서 손글씨를 이해하는 것은 현재 거의 완벽에 가까우므로, NLP 분야를 더하여, 손글씨 수학 공식을 LATEX 로 변환을 하기 위해, 주어진 방정식을 생성하는 LATEX 코드로 재구성하는 작업이니,
OCR 보다는 이미지 캡셔닝에 가깝다고 주장한다.
이미지 캡셔닝의 Seq2Seq 모델과 유사한 접근 방식을 사용한다.
먼저 입력 이미지를 고정 크기의 벡터로 인코딩 한 다음, 캡션에서 토큰을 하나씩 생성하여 이 벡터를 디코딩한다.

Harvard University [Deng et al.,2016] 에서 제안한 것과, [Xu et al., 2015] 의 이미지 캡셔닝 시스템을 결합하여 사용한다.
주요 결과는 다음과 같다
- end-to-end LaTeX 렌더링 개발, 이미지 캡셔닝에도 적용 가능
- 인코더와 디코더를 비교하며 이미지 캡셔닝의 특정 문제에 대한 작동 분석
2. Related Work
3. Method
3.1 Encoder-Decoder
Encoder
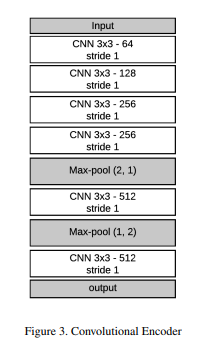
이미지를 filter size 3x3, stride 1, padding 1 인 convnet 을 6개의 층으로 구성한다.
이후 convnet 은 max pooling 층을 추가하며, max-pooling 으로 문자 구조를 추출한다.
이 CNN 구조는 원본 이미지 를 피처맵 로 인코딩 한다.
여기서 는 convnet 마지막 층의 필터 수이다.
이 인코더를 영역의 각 벡터로 정의한다.
각 는 이미지의 한 영역의 정보를 담게 된다.
Decoder
위 과정으로 얻은 피처맵 으로 LaTeX 토큰 생성을 위해 디코딩을 한다.
LSTM 이 이러한 작업과 관련하여, 효율적인 long term dependencies 와 역전파에 용이한 것을 보인다.
따라서 디코더는 hidden vector (hidden state 와 memory 는 포함하는 LSTM 의 hidden state) 와 이전 토큰 를 인풋으로 사용한다.
각 단계마다, 디코더는 이미지와 다음 hidden vector 에 의존하는 attention vector 를 계산
vocabulary 의 확률 분포를 계산하는데 사용될 output state 을 계산한다.
이 구현은 [Deng et al.,2016], [Xu et al., 2015] 와 유사하며 자세한 것은 다음을 따른다.
- 여기서 는 임베딩이며, 는 행렬
- 는 attention vector 를 의미하며, LSTM 의 cell state 를 의미하는 것이 아님
- 는 인코딩된 이미지.
두 특별 토큰 START 와 END 를 사용한다.
기토거응 END 을 예측하며, 새로운 토큰 생성은 하지 않는다.
START 토큰은 디코더 초기화에 사용되며, hidden vecotr 를 zero 로 초기화하는 대신 표현적인 초기화와 결합하여 각 hidden state 를 다음 규칙으로 초기화한다.
여기서 각 hidden state (LSTM 의 memory 와 output vector 를 포함) 에 독립적인 행렬 와 bias 를 학습한다.
3.2 Attention mechanism
디코더 성능 향상을 위해, soft attention mechanism 으로 이미지 캡셔닝 수렴을 도운다.
디코딩 과정 각 단계마다, 피처맵 에 RNN 을 시도하며 이 벡터들의 weighted average 를 계산한다.
3.3 Beam search
각 단계에서, LSTM 은 vocabulary 사이즈이며 다음 단어에 대한 vocabulary 의 확률 분포를 나타내는 차원의 벡터 를 생산한다.
벡터 로부터, output 토큰을 결정하고 다음 input 에 줄 필요가 있다. 이에 두 가지 방법을 시도 한다.
- Greedy approach : 간단한 방법으로, 각 단계에서 가장 높은 확률을 가진 토큰을 출력. 최적이지 않을 수 있으며, 더 낮은 값을 가질 수도 있다.
- Beam search : beam search 를 구현하여 최적의 출력을 찾으며, 가장 높은 확률인 B 개의 가설을 메모리에 유지하며, B 개의 토큰을 디코더에 입력하고, B 개의 벡터 를 계산한 다음, 가장 높은 확률을 가진 B 개 토큰의 목록을 업데이트하며 부모 노드를 추적한다.
각 단계의 디코딩에서 최대화하려는 것은 각 토큰의 확률의 곱이다.
