논문 및 이미지 출처 : https://dl.acm.org/doi/pdf/10.1145/3560815

Abstract
NLP 의 새로운 패러다임으로 prompt-based learning 이 등장
- 기존 방식 supervised learning
- input 를 사용하여 output 을 예측하도록 를 훈련
- prompt-based learning
- 텍스트의 확률 직접적으로 모델링
- 기존의 input 를 채워지지 않은 공백(unfilled slot)을 가진 텍스트 문자 prompt 로 수정하여 사용
- 그 후, 미입력된 정보를 확률적으로 채워 최종 문자열 를 얻음. 이를 최종 output 으로 유도함
이 방식은 다음과 같은 이유로 강력함
- LM 이 대량의 raw text 를 pre-trained 할 수 있게 함
- 새로운 prompting 함수를 정의하여, few/no labeled data 로 few/zero-shot learning 가능
본 논문은 prompting 패러다임을 소개하며 pretrained LM, prompt 및 튜닝 전략의 선택과 같은 다양한 측면의 리뷰를 소개함.
이 외에도 NLPedia-Pretrain 사이트를 제공하며, 지속적으로 업데이트되는 조사 및 논문 목록을 포함한다.
1. Two Sea Changes in Natural Language Processing
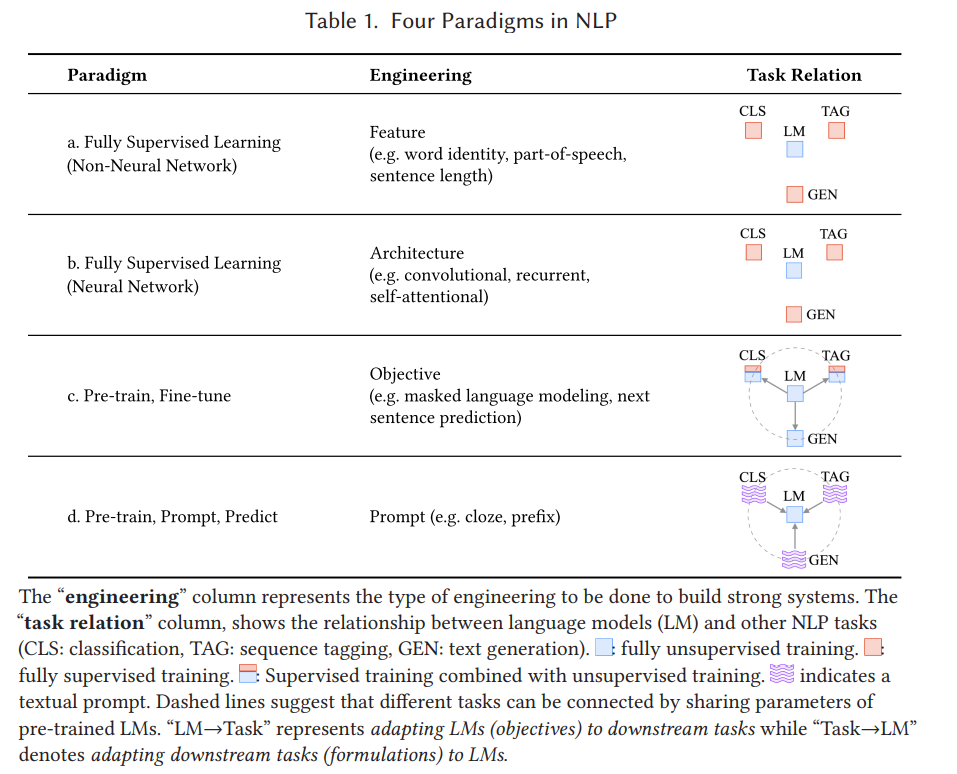
- Fully Supervised Learning : task-specific model 이며, target task 에 대한 데이터셋에 의존
- feature engineering : 연구자 또는 엔지니어가 raw data 에서 feature 를 추출하고 모델에 제공하는 방식
- 제한된 데이터를 학습하여 bias 가 내재
- architecture engineering : NLP 의 neural network model 이 진보하며, 주요 feature 를 잘 학습하는 network architecture 구축에 초점을 둠
- 적절한 아키텍처 설계로 inductive bias 를 제공
- feature engineering : 연구자 또는 엔지니어가 raw data 에서 feature 를 추출하고 모델에 제공하는 방식
2017~2019 에 NLP 의 큰 변화로 fully superviesd 패러다임은 축소됨
- pre-train and fine-tune paradigm : language model (LM) 을 대규모 데이터셋에서 pre-train을 진행한 task-specific objective function 으로 fine-tune 을 진행한다.
- objective engineering : pre-training 및 fine-tuning 과정에 objective 맞게 훈련을 설계
- 대규모 문장 예측에 loss function 을 도입하여 pre-trained LM 이 text summarization 에 좋은 성능을 보여주며, pre-trained LM 의 몸체가 일반적으로 downstream task 에 대한 해결책으로 적절하게 fine-tuning 된다.
- objective engineering : pre-training 및 fine-tuning 과정에 objective 맞게 훈련을 설계
2021 에 다시 큰 변화가 일어나 "pre-train and fine-tune" 에서 "pre-train, prompt, and predict" 로 대체됨
- pre-train, prompt, and predict : LM 을 downstream 에 object engineering 으로 적응시키는 대신 downstream task 와 유사하게 textual prompt 를 재구성
- 예시로 다음과 같다.
- "나 오늘 버스 놓쳤어," 그리고 prompt "내 기분은 _" 으로 계속하여 LM 에게 공백을 채우도록 요청
- "English:I missed the bus today. French: _" 으로 번역을 예측하도록 공백을 채우게 한다
- 이처럼 적절한 prompt 를 선택하여 task-specific training 없이 원하는 출력을 예측할 수 있음
- 장점으로 다양한 prompt 를 unsupervised 으로 LM 을 통해 많은 task 해결 가능
- 적절한 prompt 를 찾는 prompt engineering 이 필수
- 예시로 다음과 같다.
2 A Formal Description of Prompting
2.1 Supervised Learning in NLP
NLP 의 기존 supervised learning 은 input (보통 text) 으로 output 를 예측하는, 모델에 기반한다.
는 label, text 또는 다른 형태의 output 일 수 있다.
parameter 를 학습시키기 위해, input 과 output 쌍의 데이터셋을 사용하며, 이의 확률 값을 예측하는 모델로 훈련시킨다.
먼저 text classification 에선 text 로 label set 로부터 label 를 예측하게 한다.
-
sentiment analysis 에서 input = "I love this movie" 로 label set = {++, +, ~, -, --} (positive, negative 정도) 중 label = ++ 을 예측하도록 한다.
-
conditional text generation 에서 필란드어 input = "Hyvää huomenta" 로 영어 output = "Good morning" 을 생성한다.
2.2 Prompting Basics
supervised learning 은 대규모의 annotated data 가 필수이다.
prompt-based learning 은 이 문제를 해결하기 위해 3 단계의 prompting 으로 가장 높은 점수의 를 예측한다.
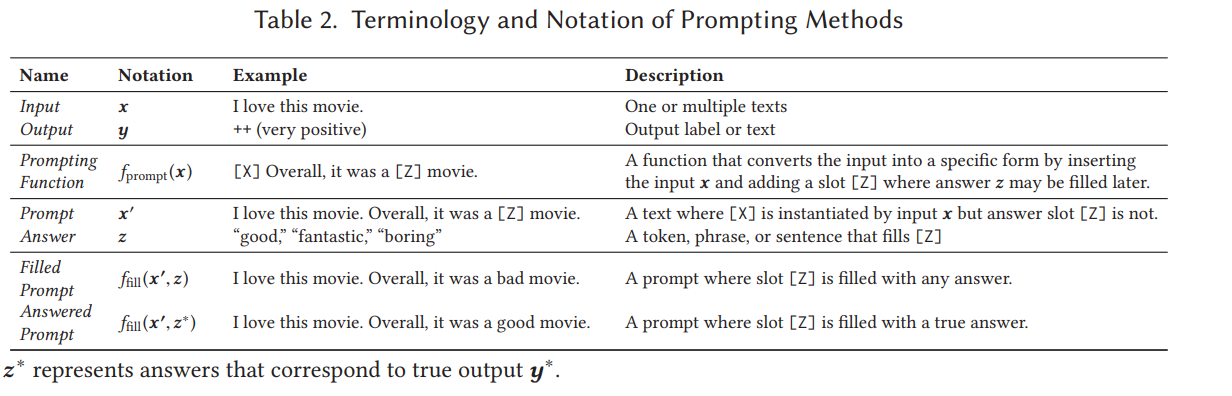
2.2.1 Prompt Addition
- input → → prompt
- prompting function 은 template 를 적용하는 것으로, 두 가지 slot 이 있는 textual string
- input 를 위한 input slot [X]
- 로 매핑될 text 가 있는 answer slot [Z]
- input text 으로 slot [X] 를 채움
- prompting function 은 template 를 적용하는 것으로, 두 가지 slot 이 있는 textual string
이전의 sentiment analysis 의 예시로 들면 다음과 같다.
- = "I love this movie,"
- template = "[X] Overall, it was a [Z] movie"
- = "I love this movie. Overall, it was a [Z] movie,"
위와 같은 과정으로 [Z] 를 예측하도록 한다. translation 의 예시로 한다면 "Finnish: [X] English: [Z]" 가 될 수 있겠다.
더 많은 예시는 Table 3 에서 볼 수 있다.

세 가지의 주목할 점이 있다.
- 위와 같은 prompt 는 z 를 채우기 위한 빈 슬롯을 middle, end 에 가진다.
- close prompt : middle
- prefix prompt : end
- 이러한 template 은 natural language token 가 아닌 다음과 같을 수 있다.
- continuous space 상의 embedding 될 수 있는 가상 단어
- continuous vectors
- [X] 및 [Z] 슬롯은 task 에 따라 유연하게 변경할 수 있음
2.2.2 Answer Search
LM 의 score 를 최대화하는, 가장 높은 score 의 text 를 찾아야 한다.
는 언어 전체 범위나 작은 부분 집합일 수 있다.
예로, = {"excellent", "good", "OK", "bad", "horrible"} 괴 = {++, +, ~, -, --} 처럼 나타낼 수 있다.
- prompt 의 [Z] 의 answer 를 채울 함수 정의
- filled prompt : 위 함수로 채워진 prompt
- answered prompt : true answer 로 채워진 prompt (예; Table 2)
- pretrained LM 으로 filled prompt 의 확률을 계산하여 answer 를 탐색
위 search 함수는 다음이 가능
- argmax search : 가장 높은 score 의 output 을 찾는 함수
- sampling : LM 확률 분포에 따른 무작위 output 생성
2.2.3 Answer Mapping
마지막 단계로, 가장 score 가 높은 answer 으로 output 을 낸다.
번역 같은 생성 작업에선 answer 에 대한 output 생성은 쉽지만, multiple answer 에 대해 동일한 output 을 내는 경우가 있다.
예로, single class (예; ++)를 나타내는 여러 감정 단어 (예; "excellent", "fabulous", "wonderful")를 사용할 수 있다.
이 경우, searched answer 와 output 간의 매핑이 필요하다.
2.3 Design Considerations for Prompting
수학적 공식을 알았으니, prompting 방법에 대한 기본적인 설계 고려사항을 보자.
- Pre-trained LM Choice
- 를 계산할 다양한 pretrained LM
- Prompt Template Engineering
- task 에 따른 proper prompt 선택
- 정확도뿐만 아니라 model 수행에도 영향 끼침
- Section 3 에서 로 template 선택법 설명
- Prompt Answer Engineering
- task 에 따른 설계 가능
- 경우에 따라선 매핑 함수와 함께 설계도 할 수 있음
- Section 4 다양한 방법을 다룸
- Expanding the Paradigm
- Section 5 에서 기본 패러다임을 확장하여 더욱 개선하고 적용 가능성을 높이는 방법을 다룸
- Prompt-based Training Strategies
- prompt, LM 둘의 parameter 를 훈련시키는 방법도 있음
- Section 6 에서 다양한 전략을 요약하고 이점을 설명
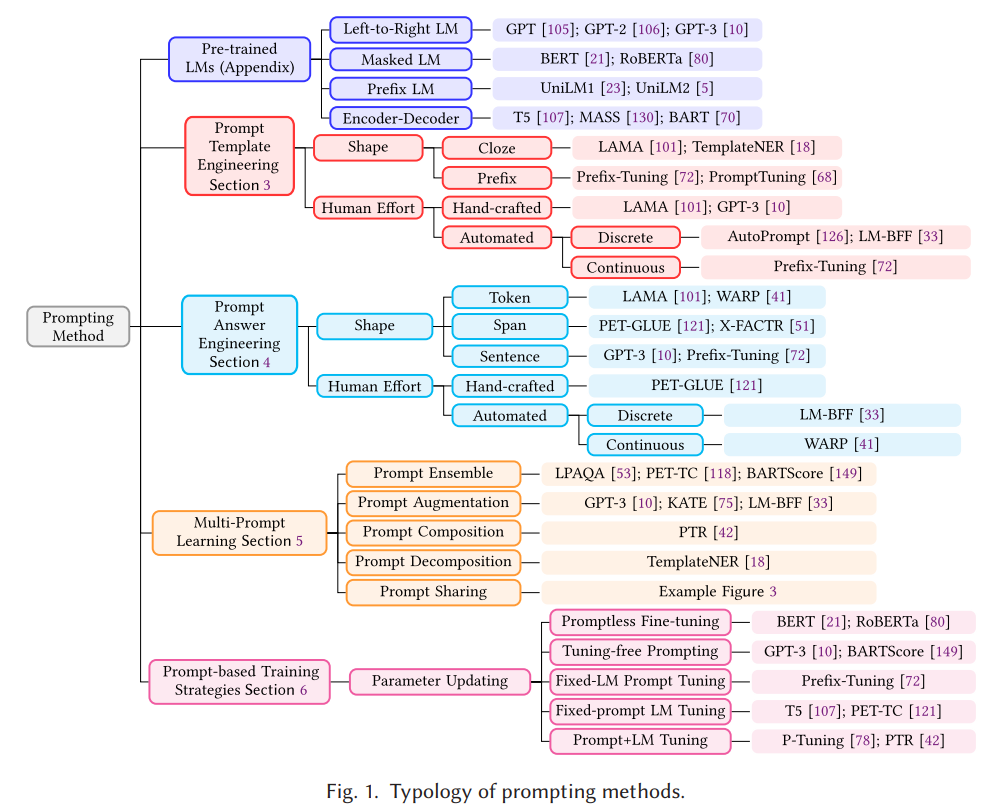
3 Prompt Template Engineering
Prompt template engineering : downstream task 에 효과적인 성능을 만다는 prompting function 를 생성하는 과정
task 에 따른 최상의 template 을 위해서, Figure 1 과 같이 두 가지 접근법으로 원하는 shape 의 prompt 를 만들 수 있다.
3.1 Prompt Shape
앞서 close prompt 와 prefix prompt 를 언급했다. 이는 task 및 model 에 따라 선택이 갈린다.
- 생성 관련 task / 표준 auto-regressive LM 의 경우 : prefix prompt 가 더 유리
- left-to-right 특성의 모델과 어울림
- masked LM 의 경우 : close prompt 가 적합
- pre-training task 형식과 유사
- 텍스트 재구성 모델의 경우 : close prompt 및 prefix prompt 함께 사용 가능
- text pair classification 같은 multiple input 의 경우 : prompt template 은 [X1], [X2] 두 개의 input 또는 그 이상을 포함해야함
3.2 Manual Template Engineering
가장 자연스러운 prompt 는 사람의 심리를 기반한 직관적인 template 을 수동으로 생성하는 것이다.
예로, LAMA 데이터셋은 LM 의 knowledge 를 조사하기 위해 수동으로 생성된 close template 을 제공한다.
- Language Models are Few-Shot Learners 논문에선 question answering, translation 및 probing task 와 같은 일반적인 추론 task 를 포함한 다양한 영역을 처리하기 위해 prefix prompt 를 수동으로 만든다
- Exploiting Cloze Questions for Few Shot Text Classification and Natural
Language Inference, Few-Shot Text Generation with Natural Language Instructions, It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners 논문들은 text classification 및 text generation task 에서 few-shot learning setting 에서 미리 정의한 template 을 사용
3.3 Automated Template Learning
수동 제작된 template 은 직관적이고 다양한 task 를 어느 정도 해결할 수 있지만 몇 가지 이슈가 있다.
- prompt 를 생성하고 실험하는 시간 및 비용이 든다; 특히 의미 이해같은 복잡한 task 는 더 힒듬
- 경험이 많은 prompt 디자이너도 최적의 prompt 를 발견하는데 실패할 수 있음
이 문제를 해결하기 위해 template 을 자동으로 설계하는 프로세스가 제안됨
- discrete prompt : 실제 텍스트 문자열
- continuous prompt : LM 의 임베딩 공간에 직접 설명되는 prompt
3.3.1 Discrete Prompt
discrete prompt 방법은 다음과 같다.
- D1: Prompt Mining
- training input 및 output 에서 자동으로 template 를 찾는 마이닝 기법
- large text corpus (예; 위키피디아) 에서, "[X] middle words [Z]" 와 같은 template 으로 와 간의 middle words 또는 dependency path 를 찾음
- D2: Prompt Paraphrasing
- seed prompt 로 다른 후보 prompt 간에 paraphrase 하여 가장 높은 정확도를 선택하는 기법
- prompt 를 다른 언어로 번역한 후 재번역하는 방법
- 시사어에 구절을 바꾸는 방법
- 정확도 향상에 특화된 neural prompt rewriter 사용하는 방법
- 특히 이 방법은 가 template 에 입력된 후 paraphrase 수행 후 각각의 input 에 다른 paraphrase 생성 가능
- seed prompt 로 다른 후보 prompt 간에 paraphrase 하여 가장 높은 정확도를 선택하는 기법
- D3: Gradient-based Search
- 실제 토큰에 대한 gradient-based search 로 생성가능한 짧은 시퀀스를 찾는 기법
- 반복 수행 및 prompt 토큰에 순차 탐색
- downstream 에 대한 training sample 로 탐색하여 강력한 성능을 보여줌
- D4: Prompt Generation
- 텍스트 생성 모델로 prompt 를 생성
- 누락된 범위를 채우는데 특화된 T5 를 사용한 32 이 있음
- template 내에 template token 을 삽입할 위치 지정
- T5 가 template token 을 디코딩 하도록 training sample 제공
- 36 : prompt 생성 제어를 위해 강화 학습을 사용하기도 함
- 5 : T5 를 각 input 에 domain relevant feature (DRFs) 을 생성하도록 훈련하는 도메인 적응 알고리즘 제안
- DRF (도메인 정보를 특징화하는 키워드 집합) 는 input 과 연결하여 template 을 형성하고 downstream task 에 의해 추가 사용
- D5: Prompt Scoring
- 19 : knowledge base 의 task 를 조사 후 LM 을 이용하여 input(head-relation-tail)에 대한 template 설계
- 후보군 template 셋을 수동으로 작성하고 input 과 output slot 을 채워 prompt 를 형성
- 그 후, 단방향 LM 으로 filled prompt 를 평가하여 가장 높은 확률을 선택
- 19 : knowledge base 의 task 를 조사 후 LM 을 이용하여 input(head-relation-tail)에 대한 template 설계
3.3.2 Continuous Prompt
continuous prompt : LM 가 효과적으로 task 를 수행하도록 인간이 이해 가능한 자연어가 아닌, LM 의 임베딩 공간에 직접 prompting 을 수행하도록 하는 방법이다.
이 방법은 두 가지 제약을 없앤다.
- template 단어의 임베딩과 자연어 단어의 임베딩이 일치해야 한다는 제약 완화
- template 가 pretrained LM 의 파라미터화 되야 한다는 제약 제거
- 대신, downstream task 의 데이터에 따라 조정할 수 있는 자체 파라미터가 있음
아래 대표적인 방법들이 있다.
- C1: Prefix Tuning
- Prefix Tuning 17 : input 에 continuous task-specific vector 의 시퀀스를 접두어로 추가하는 기법. 동시에 frozen LM 파라미터를 유지수학적으로, matrix 와 pre-trained LM 의 파라미터 가 주어였을 때 log-likelihood 목표에 따라 최적화한다.
는 timestep 에 따른 모든 neural network 층의 연결이다.
해당 timestep 이 prefix ( 가 내에 있는 경우, 직접 에서 복하된다. 그렇지 않으면 pre-trained LM 으로 계산한다. - 71 : continuous prefix-based learning 이 실제 단어로된 discrete prompt 보다 저데이터 설정에서 초기화에 더 민감하단 것을 관찰
- 67 : input 시퀀스에 특수 토큰을 추가하여 template 를 형성 하고 토큰의 임베딩을 직접 tuning
- 71 와 비교하여, 이 방법이 추가 매개변수를 도입하지 않아, 더 적은 매개변수를 사용
- 135 : 캡션 생성을 위해, frozen LM 을 사용하여 이미지를 임베딩 시퀀스로 인코딩하는 visual encoder 를 학습
- visual-language task 에 대한 few-shot learning 이 가능한 것을 보여줌
- 위 두 논문과 달리, prefix 는 샘플에 따라 다르며, task embedding 이 아닌 input image 의 representation 이다.
- Prefix Tuning 17 : input 에 continuous task-specific vector 의 시퀀스를 접두어로 추가하는 기법. 동시에 frozen LM 파라미터를 유지
- C2: Tuning Initialized with Discrete Prompt
- discrete prompt 탐색 기법으로 생성된 prompt 로 continuous prompt 를 초기화하는 기법
- 152 는 AutoPrompt 와 같은 discrete 탐색 기법으로 template 를 정의
이 prompt 를 기반으로 가상 토큰을 초기화 후 정확도 상승을 위해 임베딩을 finetuning- 수동 template 로 초기화하면 탐색 기법보다 더 나은 starting point 를 제공한 다는 점 발견
- 103 : 각 input 에 대한 soft template 의 혼합을 학습한다.
- 각 template 의 가중치와 파라미터를 training sample 로 공동 학습한다.
- 초기 template 셋은 수동으로 만들거나 prompt mining 기법으로 얻는다.
- 40 : 수동 prompt template 의 shape 를 따르는 continuous template 을 사용한다.
- C3: Hard-Soft Prompt Hybrid Tuning
- 단순히 learnable prompt template 사용 대신, hard prompt template 를 tunable 임베딩에 삽입하는 기법
- 77 : P-tuning 을 제안
- continuous prompt 를 학습 가능한 변수를 embedded input 에 삽입하여 학습됨
- prompt token 간의 상호작용을 위해, prompt embedding 을 BiLSTM 의 출력으로 나타냄
- 성능 향상을 위해 template 에 고정된 anchor token 을 사용
- 41 : prompt tuning with rules (PTR) 제안
- 규칙 기반으로 완전한 template 을 만들기 위해 수동 제작된 sub-templates 를 사용
- template ability 향상을 위해 training sample 을 통해, pretrained LM parameter 와 함께 tunable 가상 토큰을 삽입
- PTR 의 template token 은 actual token 및 virtual token 포함
- relation classification task 에 효과적
4 Prompt Answer Engineering
promt answer engineering : 예측 모델에서 answer space 를 탐색하고 output 와 매핑하는 것이 목표
answer shape 및 answer design 기법에 대해 고려해야함
4.1 Answer Shape
answer 의 모양은 세부도를 특징 짓는다. 일반적인 선택은 다음과 같다.
- Token : pre-trained LM 의 vocabulary 에 있는 token 중 하나 또는 vocabulary 의 하위집합
- Span : 짧은 multi-token span. 보통 close prompt 와 사용됨
- Sentence : 문장 또는 문서. 보통 prefix prompt 와 사용
answer shape 는 task 에 따라 다르다.
- token/text-span 의 answer space 는 classification (감정 분류; 144), relation extraction 100 또는 entity recognition 17 등 널리 사용된다.
- longer phrasal/sentential 의 answer space 는 언어 생성 105 이나 mutliple-choice question answering 55 task 등에 자주 사용된다.
4.2 Answer Space Design Method
적절한 answer space 을 설계하는 방법과 answer 이 최종 output 으로 사용되지 않을 경우 output space 를 매핑하는 방법이다.
4.2.1 Manual Design
manutal design : answer space 와 매핑할 에 대해 관심사로 수동으로 만드는 기법
- Unconstrained Spaces : answer space 는 모든 토큰 공간 100 , fixed-length spans 50 , 또는 token sequence 105 이다.
- identity mapping 으로 answer 을 output 와 직접 매핑하는 것이 일반적
- Constrained Spaces : text classification / entitiy recognition / multiple-choice question answering 와 같은 제한된 라벨 공간에 대한 task 를 수행할 때 사용하는 기법
- 144 : input text 와 관련한 단어의 목록 (예; 감정 ["anger", "joy", "sadness", "fear"], topics ["health", "finance", "politics"]) 를 수동으로 설계
- 17 : named entity recognition (NER) task 에 대해 "person", "location" 같은 목록을 수동으로 설계
- 위 두 논문 같은 경우, answer 와 class 간의 매핑이 필수
- 155 : multiple-choice question answering task 에 대해선 LM 을 사용하여 여러 선택 중 하나의 출력 확률 계산이 일반적
4.2.2 Discrete Answer Search
수동 생성된 answer 으로 이상적인 예측 성능을 얻는 다는 것은 sub-optimal 이다.
discrete answer search : 자동으로 answer search
- Answer Paraphrasing
- 초기 answer space 을 시작으로, paraphrasing 을 사용하여 answer space 를 확장
- answer 및 output 주어지면, answer para 인 paraphased set 을 생성하는 함수 정의
- 최종 output 을 모든 answer 에 대한 마진 확률을 정의.
- 51 : back-translation 방법을 사용
- 다른 언어로 번역한 다음, 다시 되돌려 여러 paraphrased answer 을 생성한다
- 초기 answer space 을 시작으로, paraphrasing 을 사용하여 answer space 를 확장
- Prune-then-Search : 그럴듯한 answers 를 초기 pruned answer space 에 생성한 후, 알고리즘으로 최종 answer 셋을 선택하는 기법
- 117, 115 : label 에서 single answer toek 로 매핑하는 함수를 정의. verbalizer 라고 함
- 최소 두 개의 알파벳 문자를 포함한 토큰 탐색
- 탐색 단계에서, 데이터의 likelihood 를 극대화하여 label 에 대한 answer 로의 적합도 계산
- AutoPrompt : [Z] token 의 contextualized representation 을 입력으로 사용해 logistic classifier 를 학습
- 탐색 단계에서, 학습된 logistic classifier 로 top- token 을 선택
- 선택된 토큰들로 answer 형성
- 32 : 훈련 샘플로 결정된 [Z] 위치의 확률값을 기반으로 top- vocabulary 단어를 선택하여, pruned search space 를 구성
- 훈련 샘플에 zero-shot 정확도를 기반으로 의 하위 집합을 선택하여 search space 를 더욱 pruning 함
- 탐색 단계에서, 고정된 template 와 모든 answer 매핑을 사용하여 LM 을 finetuning 한 후, 이의 정확도를 기반으로 가장 좋은 label word 를 선택
- 117, 115 : label 에서 single answer toek 로 매핑하는 함수를 정의. verbalizer 라고 함
- Label Decomposition
- 13 : 관계 추출 시, 관계 라벨을 구성 요소 단어로 자동으로 분해하고 answer 로 사용
- 예;
per:city_of_death의 경우,{person,city,death}로 분해한다. - answer span 의 확률은 각 토큰의 확률의 합으로 계산
- 예;
- 13 : 관계 추출 시, 관계 라벨을 구성 요소 단어로 자동으로 분해하고 answer 로 사용
4.2.3 Continuous Answer Search
몇몇 연구는 경사하강법으로 최적화할 수 있는 soft answer token 을 사용하는 가능성을 연구한다.
40 에서는 각 class label 에 대한 가상 토큰을 할당하고 prompt token embedding 과 함께 각 클래스에 대한 token embedding 을 최적화한다.
answer token 은 임베딩 공간에 직접 최적화할 수 있어, LM 으로 학습된 임베딩을 사용하는 대신 각 라벨을 처음부터 학습한다.
5 Multi-Prompt Learning
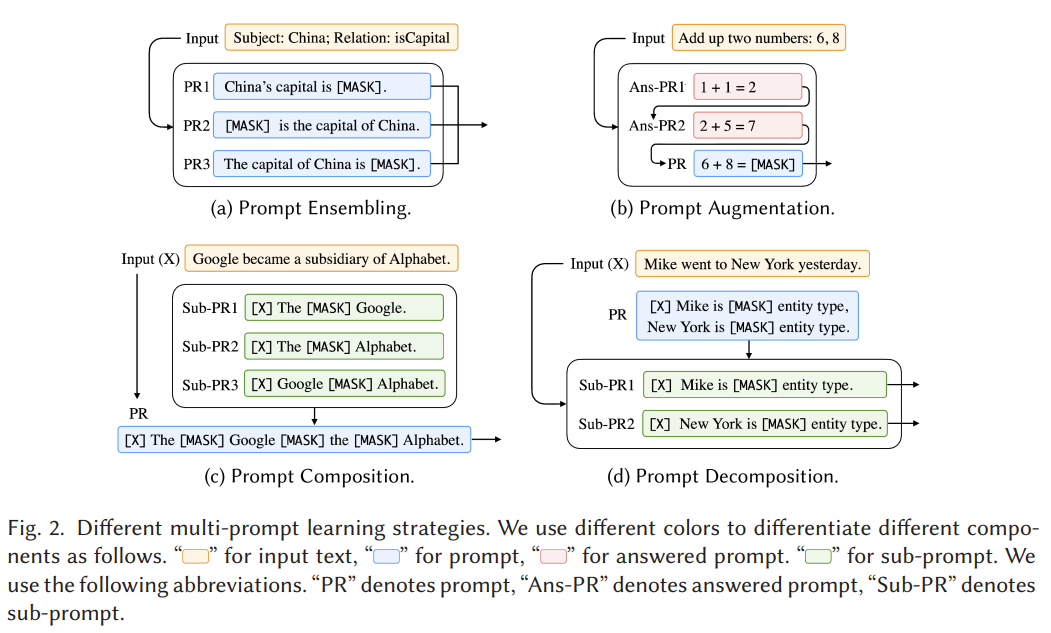
multi-prompt learning : single prompt learning 을 확장하여 효율성을 향상한 방법
5.1 Prompt Ensembling
prompt ensembling : 추론 시, 여러 unanswered prompt 를 이용한 프로세스
multiple prompt 는 discrete prompt 또는 continuous prompt 일 수 있다.
- 서로 보완적인 prompt 의 이점을 활용
- prompt engineering 비용 완화
- downstream task 의 성능을 안정화
Prompt ensembling 은 머신 러닝의 긴 역사 중 멀티 시스템을 결합한 앙상블 방법을 이용한 것으로, 현재 효과적인 방법을 도출
- Uniform averaging : 여러 prompt 의 확률값을 평균
- Weighted averaging : weight 가 있는 각 prompt 로 weight average 를 사용하여 앙상블
- Majority voting : classification task 에서, 다양한 prompt 의 결과를 결합하기 위해 다수결 투표를 사용 (40, 67)
- Knowledge distillation : 성능 향상을 위해 우수한 모델을 단일 모델로의 knowledge distillation
- Prompt ensembling for text generation
- generation task 에 대한 prompt ensembling 연구는 상대적으로 적음
- answer sequence 의 다음 단어의 앙상블될 확률 을 기반으로 output 생성
- 118 : 각 prompt 에 대한 별도의 모델을 훈련
- 각각의 finetuned LM 을 메모리에 저장하기 힘듬
대신 각 모델의 생성을 디코드한 다음, 생성 확률의 평균을 사용하여 평가
- 각각의 finetuned LM 을 메모리에 저장하기 힘듬
5.2 Prompt Augmentation
Prompt Augmentation ( Demonstration Learning ) : LM 에게 input 로 인스턴스화된 실제 프롬프트에 대한 answer 를 제공하는데 사용될 수 있는 answered prompt 를 추가로 제공하는 것
"중국의 수도는 [Z]" 대신, "영국의 수도는 런던. 일본의 수도는 도쿄. 중국의 수도는 [Z]" 와 같이 prompt 를 제공할 수 있음
few-shot demonstration 으로 강력한 언어 모델이 반복 패턴을 학습하는 데 활용한다.
아이디어는 간단하지만 다음 어려움이 있음
- Sample Selection : 가장 효과적인 예는 어떻게 선택?
- Sample Ordering : 선택한 샘플을 올바르게 정렬하는 방법은 무엇?
- 80 : answered prompt 의 정렬은 모델 성능에 중요한 역할하는 점 발견 및 다양한 후보 순열을 평가하기 위해 entropy 기반 방법 제안
- 62 : prompt augmentation 으로 훈련 예제의 좋은 순열을 찾고, prompt 사이의 separator token 을 학습하여 성능 증가
- 145 : prompting 을 통한 answered prompt 를 기반으로 meta-prompt 를 생성하는 것을 제안
- 37 : Prompt Augmentation 은 많은 textual context 를 제공하여 성능을 증가시키는 검색 기법과 관련 있음을 발견
- 99 : 37 방법은 prompt 기반 학습에도 효과적임을 발견
- 37 와의 차이는, prompt augmentation 은 template 과 answer 에 좌우되는 반면, larger context learning 은 그렇지 않다는 것
5.3 Prompt Composition
Prompt Composition : 여러 하위 프롬프트를 사용하여 각 하위 작업에 수행하고, 해당 하위 프롬프트를 기반으로 composite prompt 를 정의하는 기법
relation extraction task 의 경우, 두 개체 간의 관계를 추출하는 것으로, 개체 식별 및 개체 분류를 포함한 하위 작업으로 분해할 수 있다.
41 : 개체 관계 및 관계 분류에 대한 수동 생성한 여러 sub-prompt 를 생성하고, 관계 추출 로직을 기반으로 완전한 prompt 로 조합
5.4 Prompt Decomposition
한 샘플로 여러 예측을 수행하는 작업은 전체 input 에 대한 holistic prompt 를 직정 정의하는 것으로 어려움
Prompt Decomposition : holistic prompt 를 여러 sub-prompts 로 분해하여 각 sub-prompts 를 개별적으로 answer 하는 기법
개체 식별 작업에서, input 을 text span 셋으로 변환하고, 모델은 각 span 에 대한 개체 타입 ("Not an Entity" 포함)을 예측하도록 prompt 될 수 있음. 이는 span 수가 많아서, 각 span 에 대한 여러 prompt 를 생성하고 개별적으로 예측한다.
17 : 개체 인식에 대한 prompt decomposition 의 접근법을 조사
6 Training Strategies for Prompting Methods
prompt 를 통해 모델을 훈련하는 방법을 보자.
6.1 Training Settings
- zero-shot learning : text 확률을 예측하는 간단한 모델로 훈련하지 않고 close / prefix prompt 를 채우는 것을 적용할 수 있다.
이는 특정 task 에 대한 훈련 데이터가 없는 zero-shot learning setting 이라 한다. - full-data learning : 많은 수의 예제를 모델이 훈련
- few-shot learning : 적은 수의 예제로 모델 훈련
- 훈련 예제가 충분하지 않고 모델이 올바르게 작동하는데 효과적
annotated 훈련 샘플을 downstream task 훈련 에 사용되지 않지만, downstream task 에 사용할 prompt 생성이나 검증에 사용된다. 이점은 96 에 따르면, downstream task 에 관련한 zero-shot learning 이 아니라고 한다.
6.2 Parameter Update Methods
prompt 기반 downstream task learning 엔 두 타입의 파라미터다 있다.
- pre-trained LMs
- prompts
다양한 시나리오에 적용 가능한 수준이 다르기 때문에, 파라미터 결정은 중요하다.
다음 여부에 따라 5 가지 tuning 전략을 소개
- LM parameter 의 tuning 여부
- prompt 관련 parameter 의 추가 여부
- 추가 prompt 가 있는 경우, 해당 parameter 의 tuning 여부
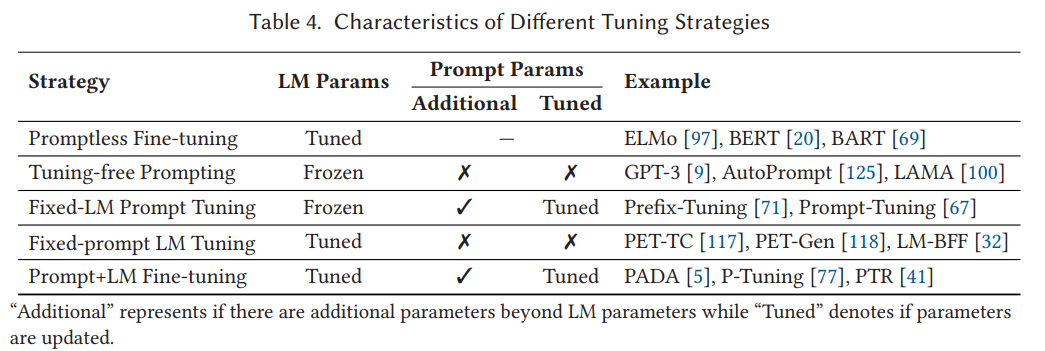
6.2.1 Promptless Fine-tuning
Promptless Fine-tuning : pretrained LM 의 모든 parameter (또는 일부 46, 98) 가 downstream task 훈련 샘플에서 prompt 없이 gradient 를 통해 업데이트하는 기법
- BERT 및 RoBERTa : 위 방법으로 pretrained LM 을 finetuning
이 방법은 간단하며 강력하여 널리 사용되지만, 적은 데이터셋에선 과적합 및 안정적인 학습이 안될 수 있음 - 84 : 이러한 모델은 catastrophic forgetting 에 취약. 즉, LM 이 finetuning 전에 한 일을 할 수 없게 되는 것
- Advantages : 간단, prompt 설계 불필요, LM 의 parameter 를 tuning 하여 큰 데이터셋에 fit 가능
- Disadvantages : 적은 데이터셋에선 과적합 및 불안정
6.2.2 Tuning-free Prompting
Tuning-free Prompting : prompt 기반의 pre-trained LM 의 파라미터를 변경하지 않고 직접 answer 를 생성하는 기법
- answered prompt 를 선택적으로 augmentation 하거나, in-context learning 으로 tuning-free prompting 과 prompt augmentation 을 조합 가능
- 일반적으로 tuning-free prompting 의 예로 LAMA 및 GPT-3 이 있음
- Advantages : 효율적, 파라미터 업데이트 과정 없음, catastrophic forgetting 없음, zero-shot 설정 적용 가능
- Disadvantages : 높은 정확도를 위해선 heavy engineering 필요. in-context learning 에서, 많은 answered prompt 가 제공되면 테스트 시간이 느리고 대규모 훈련셋에 쉽게 사용 불가
6.2.3 Fixed-LM Prompt Tuning
Fixed-LM Prompt Tuning : prompt 관련 파라미터가 추가되는 상황에, downstream task 훈련 샘플로 얻은 supervision 을 사용하여 prompt 의 파라미터 만을 업데이트하면서도 pretrained LM 은 변하지 않는 기법
- 일반적으로 Prefix-Tuning 및 Prompt-Tuning 이 있음
- Advantages : tuning-free prompting 과 유사하게, LM 의 knowledge 유지 및 few-shot 에 적합. 종종 tuning-free prompting 보다 정확도 높음
- Disadvantages : zero-shot 불가능, 대규모 데이터셋에선 representation 이 제한됨, hyperparameter / seed prompts 선택을 통한 prompt engineering 필수. 사람이 이해 및 조작할 수 없음
6.2.4 Fixed-Prompt LM Tuning
Fixed-prompt LM Tuning : pretraining 및 finetuning 으로 LM 을 tuning 하지만, 고정된 파라미터의 prompt 를 사용하여 모델의 동작을 지정하는 기법
- few-shot 상황에 잠재적인 성능 향상을 가져옴
- 자연스러운 방법은 모든 훈련 및 테스트 예제에 적용되는 discrete textual template 을 제공하는 것
- 일반적으로 117, 118 및 32 이 있음
- 48 : LM finetuning 일부와 prompt answer engineering 의 조합으로 prompt engineering 을 줄일 수 있음을 관찰
- input 과 mask 를 template word 없는 "[X][Z]" 로 직접 연결한 간단한 템플릿 null prompt 를 정의
- 경쟁력 있는 정확도를 달성
- Advantages : Template 및 answer engineering 은 특정 task 에 더 경쟁력 있고 더 효과적인 학습을 함. 특히 few-shot 상황에 좋음.
- Disadvantages : prompt 가 없으면 Template 및 answer engineering 이 여전히 필요. 한 downstream task 에 finetuning 된 LM 은 다른 downstream task 에 비효율적
6.2.5 Prompt+LM Tuning
Prompt+LM Tuning : pretrained LM 의 파라미터의 일부나 모두를 prompt 관련 파라미터와 함께 finetuning 하는 기법
- 일반적으로 PADA 및 P-Tuning 이 있음
- 표준 pretraining 과 finetuning 패러다임과 유사하지만, prompt 추가로 모델 훈련 시작 시 추가 부스팅을 제공
- Advantages : 표현력이 가장 뛰어난 방법, 높은 수준의 데이터에 적합
- Disadvantages : 모든 모델의 파라미터를 훈련하고 저장이 필요. 적은 데이터셋에는 과적합
7 Applications
어떠 분야에 사용되었는지 관점으로 섹션 시작
7.1 Knowledge Probing
- Factual Probing : prompting method 를 적용하여 사실을 탐색하는 가장 초기의 시나리오로, LM 의 representation 이 얼마나 사실적 지식을 많이 담는지 정량화하는 것
- LM parameter 를 고정되고, 수동 / 자동으로 발견될 수 있는 close prompt 로 original input 을 변환하여 지식을 탐색
- answer 가 미리 정의되어, 효과적인 template 및 다양한 모델의 결과 분석에 중점적
- Linguistic Probing : 대규모 pretrained LM 은 analogies 9, negations 25, semantic role sensitivity 25, semantic similarity 131, understanding 131 및 rare word understanding 116 가능
- 위 지식은 LM 이 완성해야할 자연어 문장의 형태로 lignuistic probing 작업을 제시하여 도출
7.2 Structure Prediction
- Semantic Parsing : 자연어가 주어지면 구조화된 의미있는 representation 을 생성하는 작업
- 124 : LM 으로 few-shot semantic parsing 에 대한 task 를 탐구
- 의미있는 파싱 작업을 paraphrasing 작업으로 재구성
- 문법에 따라 유효한 출력만 허용하여 디코딩
- in-context learning 으로 테스트 예제와 의미있게 가까운 answered prompt 선택
- pretrained LM 으로 의미있는 파싱에 대한 paraphrasing 재구성의 효과를 입증
- 124 : LM 으로 few-shot semantic parsing 에 대한 task 를 탐구
7.3 Classification-based Tasks
classification-based tasks 는 텍스트 분류와 자연어 추론과 같이 템플릿을 쉽게 구성할 수 있다.
핵심 prompting 은 적절한 prompt 를 구성하는 것이다. 예로, 144 에서는 "이 문서의 주제는 [Z]." 같은 prompt 를 사용하며, 이 prompt 는 슬롯을 채우기 위해 masked pretrained LM 에 입력된다.
- Text Classification
- Text Pair Classification : 두 문장 간의 관계 (유사성, 함축 등)를 예측하는 작업
7.4 Information Extraction
prompt 를 구성하는 데, 섬세함이 classification task 보다 더 필요
- Relation Extraction : 문장 내의 두 개체 간의 관계 예측
- 13 : relation extraction 에서 처음으로 fixed-prompt LM Tuning 기법 적용 및 classification task 로 부터의 prompting 상속을 방해하는 두 가지를 논의
- 더 큰 label space (예; 80개 관계 추출 vs 이진 감정 분류) 는 prompt answer engineering 에 큰 어려움 초래
- 관계 추출에서 input sequence 의 여러 token 들은 중요도가 다름.
- 위 문제 해결을 위해, adaptive answer selection method 제안
- task-oriented prompt template 구축
- template 에서 entity mention 을 강조하기 위해 특수 마커 (예; [E]) 사용
- 41 : 위와 유사하게, multiple prompt 를 통해 개체 유형 정보를 통합
- 13 : relation extraction 에서 처음으로 fixed-prompt LM Tuning 기법 적용 및 classification task 로 부터의 prompting 상속을 방해하는 두 가지를 논의
- Named Entity Recognition : 문장 내의 named entity 식별 (예; 사람 이름, 지역)
- tagging task 에 prompt-based learning 적용이 어려움
- 예측 단위가 text 가 아닌 token 이나 span 임
- token label 간의 잠재적인 관계가 존재
- 17 : BART 로 template-based NER 모델 제안
- text span 열거 및 수동 생성된 template 내에서 각 타입의 생성 확률 고려
- "마이크는 어제 뉴욕에 갔다" 가 주어지면 "마이크는 [Z] 개체다." 라는 template 으로 결정
answer space 는 "사람", "조직" 과 같은 값으로 구성
- tagging task 에 prompt-based learning 적용이 어려움
7.5 "Reasoning" in NLP
신경망이 "추론" 을 하는지 "페턴" 을 인식하는지는 아직도 논쟁이다. 추론 능력 조사를 위해 다양한 시나리오를 포괄하는 벤치마크 작업을 정의하는 시도가 많다.
- Commonsense Reasoning : NLP 의 상식 추론을 테스트 하는 것. 많은 벤치마크 데이터셋 존재 [47, 72, 101, 107]
- 68 : 모호한 대명사를 선행 식별하거나 여러 선택 중 문장을 완성하도록 모델에게 요구하여 해결
- 전자의 경우, "트로피가 갈색 가방에 못 들어가. 이것은 너무 커." 에서 "이것" 이 트로피인지 가방인지 추론
- 후자의 경우, "Eleanor 은 손님에게 커피를 제안했다. 그녀는 깨끗한 [Z] 가 없단걸 깨달았다" 에서 후보군은 "컵", "그릇", "숟가락" 이다.
- 134 : 잠재적 후보의 다양한 선택 확률을 계산하여 pretrained LM 으로 가장 높은 확률을 택하여 전자 해결
- 25 : 각 후보의 생성 확률을 평가하여 가장 높은 확률을 선택하여 후자 해결
- 68 : 모호한 대명사를 선행 식별하거나 여러 선택 중 문장을 완성하도록 모델에게 요구하여 해결
- Mathematical Reasoning : 산술, 함수 등과 같은 수학 문제를 해결하는 것
7.6 Question Answering
Question answering (QA) : context document 를 기반으로 input question 에 대한 answer 제공을 목표
QA 는 다양한 형태 존재
- extractive QA [SQuAD] : context document 에서 answer 을 포함하는 내용 식별
- multiple-choice QA [RACE] : 모델이 여러 선택지 중에 선택
- free-form QA [NarrativeQA] : 모델이 임의의 텍스트 문자열을 answer 로 반환
이런 다양한 형태는 서로 다른 모델링 프레임워크로 처리하지만, prompting 을 통하면 한 프레임워크로 처리할 수 있다는 장점이 있다.
- 55 : context 와 question 으로 적절한 프롬프트 및 seq2seq pretrained T5 를 finetuning 하여 QA task 를 text generation 문제로 재구성
- 51 : seq2seq pretrained LMs (T5, BART, GPT2) 으로 QA task 를 관찰하여, 이러한 모델들의 확률이 QA 작업에 유용하지 않다는 점 발견
7.7 Text Generation
Text Generation : 다른 정보에 따라 텍스트를 생성하는 작업들의 집합. prompting 방법은 prefix prompt 와 함께 autoregressive pretrained LM 으로 쉽게 적용 가능
- 105 : "프랑스어 번역, [X], [Z]." 같은 prompt 를 사용하여 텍스트 요약 및 번역의 생성 작업의 놀라운 성능 입증
- 9 : 텍스트 생성에 in-context learning 수행, multiple answered prompt 로 수동 템플릿 및 augmenting 와 함께 prompt 생성
- 118 : 수동 생성된 template 로 few-shot 텍스트 요약에 대한 fixed-prompt LM tuning 탐구
- 71 : few-shot 에서 텍스트 요약 및 data-to-text 생성에 대한 fixed-LM prompt tuning 을 탐구
- learnable prefix token 을 input 앞에 붙임
- pretrained LM 의 파라미터를 유지
- 23 : 텍스트 요약 task 에서 prompt+LM tuning 전략 탐구
- learnable prefix prompt 사용 및 pretrained LM 의 파라미터와 함께 업데이트
7.8 Automatic Evaluation of Text Generation
147 : 생성된 텍스트에 자동 평가를 prompt learning 으로 사용될 수 있음을 입증
pretrained seq2seq 을 사용하여 생성된 텍스트의 평가를 텍스트 생성 문제로 개념화하고 pretraining task 와 가깝게 평가하도록 하는 prefix prompt 사용
실험적으로 변역된 텍스트에 "such as" 문구를 추가하여, 독일어-영어 번역 평가에서 상당한 관계 개선을 가져올 수 있음을 발견
7.9 Meta-Applications
prompting 기술은 NLP task 뿐 아니라 다른 task 에도 모델을 훈련하는 데 유용한 요소로 작용
- Domain Adaptation : 한 도메일에서 다른 도메인으로 적응 시키는 것 (예; 뉴스 → 소셜 미디아)
- 5 : 원본 텍스트 input 을 augmentation 하기 위해 self-generated DRFs 사용 및 seq2seq 모델로 시퀀스 태깅 수행
- Debiasing
- 121 : LMs 가 biased / debiased instruction 에 따라 self-diagnosis / self-bebiasing 을 수행할 수 있음을 발견
- self-diagnosis 의 경우
- 폭력적인 정보가 포함되었는지 self-diagnosis 하기 위해, "The following text contains violence. [X][Z]" 사용 가능
- ㅤ[X] 를 채우고 [Z] 의 생성 확률을 본다.
- "Yes" 와 "No" 의 확률을 통해 폭력이 포함되었는지 아닌지 추정
- debiasing 의 경우
- input 이 주어지면 다음 단어의 확률 계산
- self-diagnosis input 을 원본 input 에 추가하여 다음 단어의 확률 계산
- 다음 토큰에 대한 위의 두 확률 분포를 결합하여 원하지 않는 속성을 막음
- 121 : LMs 가 biased / debiased instruction 에 따라 self-diagnosis / self-bebiasing 을 수행할 수 있음을 발견
- Dataset Construction
- 117 : 특정 instruction 이 주어지면 데이터셋을 생성하기 위해 pretrained LM 사용을 제안
- 의미적으로 유사한 문장으로 데이터셋 구성할 경우, 각 input 문장은 다음과 같은 template 을 사용할 수 있다.
"Write two sentences that mean the same thing. [X][Z]"
그리고 같은 의미를 공유하는 문장을 생성할 수 있다.
- 의미적으로 유사한 문장으로 데이터셋 구성할 경우, 각 input 문장은 다음과 같은 template 을 사용할 수 있다.
- 117 : 특정 instruction 이 주어지면 데이터셋을 생성하기 위해 pretrained LM 사용을 제안
7.10 Multi-modal Learning
135 : NLP 의 prompt learning 을 multi-modal 에서 적용
fixed-LM prompting tuning 과 prompt augmentation 사용
각 이미지를 continuous embedding 의 시퀀스로 표현하고 파라미터가 고정된 pretrained LM 으로 프롬프트화하여 image caption 을 생성
위 결과는 few-shot learning 능력을 보여줌
→ few demonstration (answered prompt) 을 통해 시스템이 새로운 객체와 시각점 카테고리에 대한 단어를 빠르게 학습
8 Prompt-Relevant Topics
prompt-based learning 의 본질 및 다른 learning method 와의 관계를 알아보자.

- Ensemble Learning : 여러 시스템의 상보성(complementarity) 의 이점을 사용하여 task 의 성능 향상을 목적
- 앙상블은 여러 시스템의 아키텍처, 학습 전략, 데이터 순서 또는 무작위 초기화로 생성
- prompt template 의 선택 또한 여러 결과를 생성하는 하나의 방법
- 여러 번 학습할 필요가 없는 이점
- 예로, discrete prompt 사용 시 추론 단계에서 간단히 변경 가능 [52]
- Few-shot Learning : 적은 훈련 샘플로 데이터가 적은 상황에 훈련하는 것을 목표. 다양한 방법 존재
- model agnostic meta-learning [29] : 새로운 task 에 빨리 적응하는 feature 학습
- embedding learning [8] : 유사한 샘플이 서로 가깝도록 각 샘플을 저차원 공간에 임베딩
- memory-based learning [53] : 각 샘플이 메모리에서 내용을 weighted average
- prompt augmentation [62] : few-shot 을 위한 방법으로 볼 수 있음. 파라미터 tuning 없이 pretrained LM 에서 knowledge 를 유도하여 여러 샘플을 더 추가 가능
- Larger-context Learning : input 에 학습 데이터셋 [11] 또는 외부 데이터 소스 [38] 에서 검색된 추가적인 문맥 정보로 augmentation 하여 성능을 향상하는 것이 목표
- Prompt Augmentation 은 input 에 관련 라벨 샘플을 추가하지만, larger-context learning 과의 차이점은 라벨 데이터가 반드시 필요하지 않다는 점
- Query Reformulation : input query 를 관련된 용어로 확장하거나 paraphrasing 을 생성하여 관련성 높은 텍스트를 유도하는 것이 목표
- QA-based Task Reformulation : 다양한 NLP task 를 question-answer 문제로 개념화 하는 것을 목표
- Controlled Generation : input text 외의 다양한 유형의 가이드를 생성 모델에 통합하는 것을 목표
- guidance signal 은 style token [27, 123], length spacifications [56], domain tags [14] 또는 생성된 텍스트를 제어하기 위해 사용되는 다양한 다른 정보일 수 있다.
생성된 텍스트의 내용을 계획하기 위해 keywords [112], relation triples [154] 또는 highlighted phrases or sentences [34, 78] 일 수도 있다. - 이 작업에서 prompt 는 task 지정에 사용되며, 다음 두 유형 사이에 공통점을 발견할 수 있음
- 나은 생성을 위해 input text 에 정보를 추가하며, 이러한 additional signals 는 learnable parameter 이다
- "controlled generation" 을 seq2seq pretrained LM (예;BART) 로 얻었다면, input 종송적인 prompt 및 prompt+LM fine-tuning 전략을 가진 prompt learning 으로 간주 가능.
예; prompt 및 LM 파라미터로 tuning 가능한 GSum
- controlled generation 과 prompt-based text generation 의 차이
- control 은 생성 스타일이나 내용 제어하는데 사용 [23, 27] 하면서도 동일한 task 상태로 유지. pretrained LM 이 필수적이지 않음
- text generation 의 prompt 사용 동기는 task 명시 및 pretrained LM 활용
- text generation 의 prompt learning 은 최근 연구에서 데이터셋 또는 task-level prompt 를 공유 [71]
- 몇몇 연구에서만 input 종속성에 대해 탐구하지만, contolled text generation 에서 일반적인 세팅이며 효과적이다. prompt learning 에 대한 미래 연구의 방향을 제공할 수도 있다.
- guidance signal 은 style token [27, 123], length spacifications [56], domain tags [14] 또는 생성된 텍스트를 제어하기 위해 사용되는 다양한 다른 정보일 수 있다.
- Supervised Attention : 데이터 기반 attention 은 과적합될 수 있어, 모델의 attention 을 supervised 로 제공하는 것을 목표 [76]
- Data Augmentation : 기존 데이터를 수정하여 훈련에 사용될 데이터 양을 늘리는 기술 [26, 109]
- 114 : prompt 추가가 분류 작업 전반에 걸쳐 100개 이상의 데이터 포인트 추가와 유사한 정확도 향상을 평균적으로 얻을 수 있음을 발견
- downstream task 에 대한 prompt 사용이 data augmentation 을 암묵적으로 수행하는 것과 유사하다는 것을 시사
- 114 : prompt 추가가 분류 작업 전반에 걸쳐 100개 이상의 데이터 포인트 추가와 유사한 정확도 향상을 평균적으로 얻을 수 있음을 발견
9 Challenges
prompt-based learning 은 다양한 task 와 상황에 대해 상당한 잠재력을 보여주지만, 아직 몇몇 과제들이 있다.
9.1 Selection of Pre-trained LMs
다양한 LMs 가 있어, prompt-based learning 을 더 잘 활용하기 위해 선택하는 법도 과제이다.
현재까지 다양한 pretrained LM 에 대한 prompt-based learning 이점의 체계적인 비교가 거의 없거나 전무하다.
9.2 Prompt Design
- Tasks beyond Classification and Generation : prompt-based learning 은 text classification / generation-based task 에 비해 information extraction / text analysis task 는 덜 다루어졌다. 이유는 prompt 설계가 덜 직관적이기 때문이다.
- 추후, 적절한 텍스트 형태로의 구조화된 출력을 표현하는 효과적인 prompt answer engineering 이나, 텍스트 분류 및 생성 작업처럼 재구성이 필요할 것으로 보임
- Prompting with Structured Information : NLP task 에서 input 은 tree, graph, table, relational structure 등 다양하게 표현할 수 있는데, template / answer engineering 에서 어떻게 잘 표현할지가 과제
- Entanglement of Template and Answer : 모델 성능은 사용 중인 template 과 고려 중인 answer 에 따라 달라진다.
9.3 Prompt Answer Engineering
- Many-class Classification Tasks : class 가 너무 많은 경우, 적절한 answer space 를 선택하는 방법은 어려운 최적화 문제
- Long-answer Classification Tasks : multi-token answer 을 사용하는 경우, LMs 를 사용하여 다중 토큰을 잘 디코딩하는 방법은 아직 알려지지 않았으며, 몇 가지 다중 토큰 디코딩 방법이 제안되었지만 [50], 여전히 최적이지 않음
- Multiple Answers for Generation Tasks : text generation 의 경우, 적절한 answer 는 의미는 동등하지만 문법적으로는 다양
- 거의 모든 연구가 single answer 에 의존하여 text generation 을 prompt learning 을 사용하며, 예외적인 경우는 거의 없음 [52]
- 멀티 레퍼런스로 학습 과정을 잘 가이드하는 방법은 여전히 크게 연구되지 않은 문제
9.4 Selection of Tuning Strategy
prompt, LMs, 또는 둘 모두의 파라미터 튜닝에는 다양한 방법이 있다.
이 연구 분야의 초기 단계에서, 이러한 방법들 사이의 균형에 대한 체계적인 이해가 부족하다.
다양한 전략들 간의 균형에 대한 체계적인 탐구로 pretrain 및 finetune 패러다임에 수행되는 것과 유사학 이득을 취할 수 있을 것이다 [98].
9.5 Multiple Prompt Learning
-
Prompt Ensembling : prompt ensembling 에서, prompt 를 많이 고려할수록 공간 및 시간 복잡도는 증가
- 다양한 프롬프트의 knowledge 를 추출하는 방법은 아직 충분히 탐구되지 않음
- 앙상블 할만한 프롬프트를 선택하는 방법도 아직 충분히 탐구되지 않음
- 텍스트 생성 작업의 경우, prompt ensemble learning 의 연구가 수행되오지 않았으며, 이는 텍스트 생성에서의 앙상블 학습이 비교적 복잡하기 때문
- Refactor : 위 해결방안으로, neural ensembling method 제안
-
Prompt Composition and Decomposition : 다중 sub-prompt 를 도입하여 복잡한 task input 의 어려움을 제거하는 것이 목표. 좋은 선택을 해야 하는 것이 중요
-
Prompt Augmentation : 기존의 prompt augmentation 은 입력 길이에 제한이 있다.
- 예로, 너무 많은 demonstration 을 input 으로 넣으면 실행 불가능하다.
- 정보를 가진 demonstration 을 선택하고 적절하게 정렬하는 방법은 흥미롭고 도전적인 문제다 [62]
-
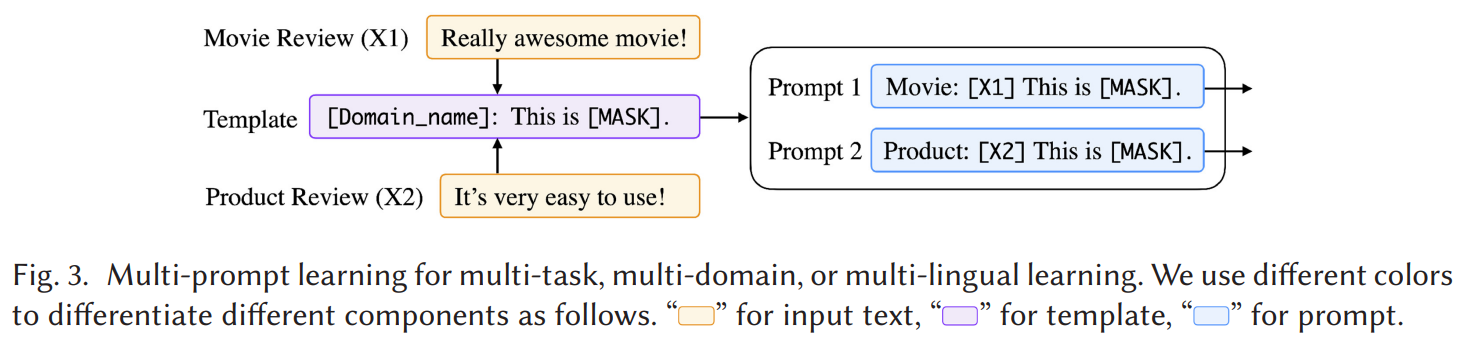
Prompt Sharing : 이전엔 주로 single task, domain, language 에 대한 prompt 적용이었지만 multiple 에 대해서도 prompt learning 을 적용하는 prompt sharing 을 고려할 수 있다.
- 다양한 task 에서 개별 prompt 를 설계 및 각각의 상호작용을 맞추는 법이 핵심
- 지금까지 많이 탐구되지 않은 분야
- Fig. 3 에서 mutiple task 에 대한 multiple prompt learning 전략으로 prompt template 을 공유하는 것을 보여준다
9.6 Theoretical and Empirical Analysis of Prompting
많은 상황에선 성공하지만, prompt-based learning 의 이론적 분석과 보장은 희박하다.
- 141 : soft-prompt tuning 은 downstream recovery (예; downstream task 의 ground-truth labels 을 복원하는 것)를 위해 필요한 non-degeneracy assumptions (각 토큰의 생성 확률은 선형적으로 독립) 을 완화시킬 수 있음을 입증
- 이는 task-specific 정보를 추출하기 쉽게 만들어줌
- 113 : 텍스트 분류 작업은 문장 완성 작업으로 재구성할 수 있음을 검증하여, 언어 모델링이 의미 있는 pretrained 작업이 될 수 있음을 보여줌
- 114 : 분류 작업 전반에 걸쳐 prompt 가 평균 데이터 포인트 수백 개에 해당하는 가치가 있다는 것을 경험적으로 보여줌
9.7 Transferability of Prompts
prompt 가 모델에 특화된 정도를 이해하고 prompt 의 전이성을 향상시키는 것 또한 중요한 주제
96 에선 tuned few-shot learning 상황 (prompt 를 선택하기 위해 더 큰 검증셋이 있는 경우)에서 선택된 prompt 가 유사한 크기의 모델에 잘 일반화되는 반면, true few-shot 상황 (학습 샘플이 몇 개 뿐일 경우)에서 선택된 prompt 는 전자보다 일반화되지 않는 다는 것을 보여줌.
모델 크기가 두 상황 모두에서 상당히 다른 전 경우, 전이성이 낮다.
9.8 Combination of Different Paradigms
prompting 패러다임의 성공은 BERT 같은 pretrain 및 finetune 으로 개발된 pretrained LMs 의 top 에서 구축되었다.
하지만, 후자에 대한 효과적인 pretraining 방법이 전자에 그대로 적용할 수 있는지, 또는 다시 생각하여 정확성이나 prompt-based learning 의 적용 용이성을 더 개선할 수 있는지 중요한 연구 질문으로, 이에 대한 문헌은 충분히 다뤄지지 않았다.
9.9 Calibration of Prompting Methods
Calibration (보정)는 모델이 좋은 확률적 예측을 할 수 있는 능력을 말한다 33.
answer 예측을 위해 pretrained LMs (예; BART) 의 생성 확률 사용 시, 확률 분포가 일반적으로 잘 보정되어 있지 않아 조심할 필요가 있다.
- 51 : QA task 에서의 pretrained LMs (예; BART, T5, GPT2) 의 확률이 잘 보정된다는 점 발견
- 151 : answered prompt 가 제공됐을 때, pretrained LMs 가 특정 answer 로 향하도록 편향되는 세 가지 문제점 (대부분 label bias, receny bias, common token bias)을 식별함
- 예로, 최종 answered prompt 가 positive label 이면, 모델은 positive words 를 예측하도록 편향됨
- 이를 해결하기 위해
- context-free input (예; prompt 가 "Input: Subpar acting. Sentiment: Negative\n Input: Beautiful film. Sentiment: Positive\n Input: N/A. Sentiment:")을 사용하여 초기 확률 분포 을 얻는다
- real input (예; prompt 가 "Input: Subpar acting. Sentiment: Negative\n Input: Beautiful film. Sentiment: Positive\n Input: Amazing. Sentiment:") 를 사용하여 확률 분포 를 얻는다.
- 이 두 분포를 사용하여 보정된 생성 확률 분포를 얻는다.
- 이 모델은 두 가지 단점이 있다.
- 적절한 context-free input (예; "N/A" 나 "None" 을 사용할지 여부)을 찾는 추가 비용 발생
- pretrained LMs 의 확률 분포는 여전히 보정되지 않음
보정된 확률 분포가 있어도, input 에 대한 single gold answer 추정할 때 조심할 필요가 있다.
동일한 객체의 표면 형태가 유한한 확률 질량을 경쟁한다는 것을 의미 45
예로, "Whirlpool bath" 가 gold answer 이라면, 해당 생성 확률은 일반적으로 낮을 것이다.
이유는 "Bathtub" 단어는 동일한 의미를 공유하며 더 큰 확률 질량을 차지하기 때문이다.
이를 해결하기 위해
- paraphrasing 을 사용하여 gold answer set 을 포괄적으로 구성하는 prompt answer angineering 을 수행
- 단어 확률을 context 내의 이전 확률에 기반하여 보정
