논문 및 이미지 출처 : https://arxiv.org/pdf/2303.02506.pdf
Shikun Liu, Linxi Fan, Edward Johns,
Zhiding Yu, Chaowei Xiao, Anima Anandkumar
Imperial College London, NVIDIA, ASU, Caltech
Abstract
최근 vision-language 모델이 multi-modal 능력을 보이기 위해 거대한 학습이 필요하다.
이에 Prismer 로 데이터 및 파라미터에 효율적인 vision-language 를 소개
Prismer 는 적은 수의 구성요소만 학습하며, 대부분의 가중치는 미리 학습된 domain experts 로부터 상속받아 학습 중 동결 상태를 유지한다.
넓은 범위의 domain experts 를 모아, Prismer 는 효율적으로 expert knowledge 를 수집하고, 다양한 vision-language 추론 작업에 적용할 수 있음을 보여준다.
최대 2배 적은 데이터로도 Prismer 는 SOTA 를 달성한 모델들과 경쟁력 있는 fine-tuning 과 few-shot learning 성능에 도달 했다.
1. Introduction
pretraining 한 대규모 모델은 다양한 작업에 좋은 일반화 능력을 가졌지만 대량의 훈련 데이터 및 계산 비용이 든다.
특히, vision-language 은 image captioning, visual question answering 등과 같은 multi-modal 추론이 필요하므로 recognition, detection, counting, 3D perception 등의 많은 기술이 요구된다.
일반적으로 이들은 대규모 데이터를 학습한 모델로 해결한다.
대신에, 저자들의 접근법으로 experts 라고 하는 서로 분리된 sub-network 로 이러한 스킬들과 domain knowledge 을 학습시키는 것이다.
이 모델은 모든 것을 한번 학습하는 것보다, 여러 스킬과 domain knowledge 를 통합하는데 초점을 둔다. 이 방법은 multi-modal 학습을 축소하는데 효과적인 방법이다.
Prismer 의 핵심 설계는 다음 요소를 포함한다.
- web-scale knowledge 에 대한 강력한 vision, language 백본 모델
- auxiliary knowledge 형태의 low-level vision signals (e.g. depth) 과 high-level vision signals (e.g. instance, segmentic label) 로 다양한 형태의 vision 정보를 인코딩한 vision experts
모든 expert model 은 따로 따로 pre-trained 하여 동결하여 전체 network parameter 에 약 20% 에 해당하는 학습가능한 components 로 연결된다.
Prismer 는 13M 에도 불구하고 image captioning, image classification, visual question answering 등의 multi-modal 에 좋은 추론 성능을 보인다.
마지막으로, Prismer 의 다음 학습 방식을 분석한다.
- noisy experts 에 대해 강한 견고함을 보임
- 학습 성능 또한 experts 양이 증가함에 따라 호의적으로 확장
2. Related Work
3. Prismer: Open-ended Reasoning with Multi-modal Knowledge
3.1 Model Overview
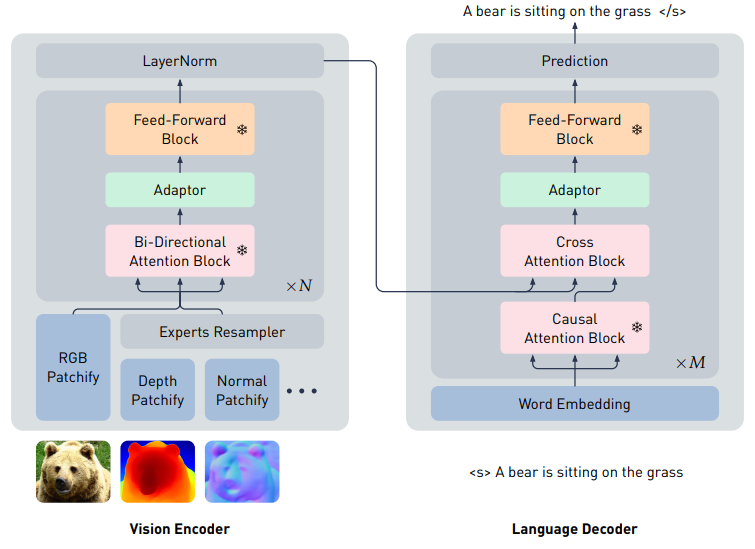
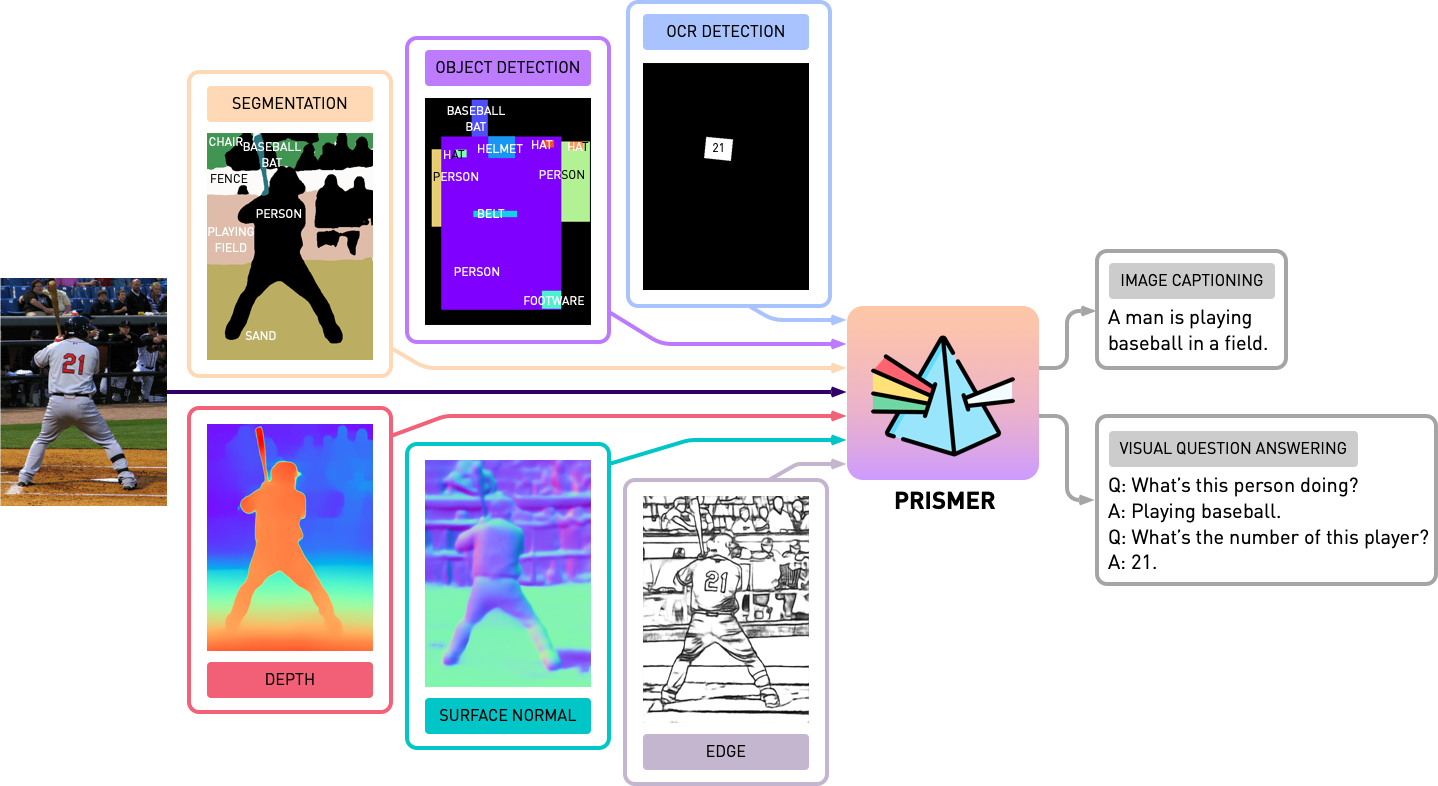
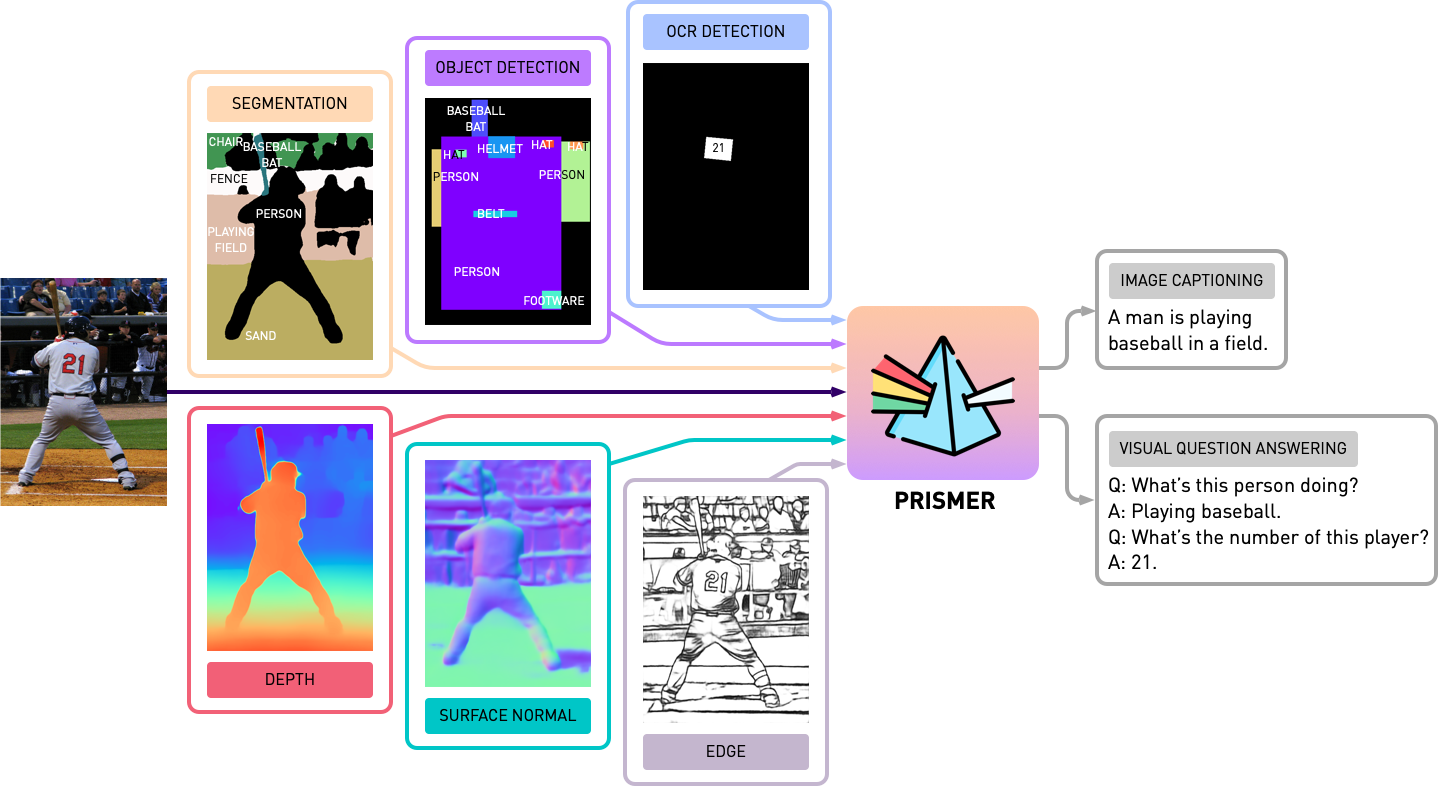
Prismer 는 encoder-decoder 인 transformer model 이다.
-
endoer : vision
- input : RGB image 와 multi-label labels (e.g. depth, surface normal, segmentation ..)
- output : RGB 와 multi-modal features 의 sequence
-
decoder : auto-regressive language
- cross attention 을 통해 multi-modal features 를 조절
- output : 텍스트 token 의 sequence
위 Prismer 는 다른 SOTA 만큼의 성능에 도달하는데 필요한 GPU 시간을 줄였다.
web-sacle 을 학습한 pretrained vision 과 language 인 top backbone 모델로 만들어 졌다.
또한 multi-modal signals 를 받아들이기 위해 vision encoder 를 확장하였으며, 이는 generated multi-modal auxiliary knowledge 와 capture semantic 을 가능케 했다.
예를 들어,
- "text-reading" 은 OCR detection expert 로 해결
- "object-recognition" 은 object detection 으로 해결
모든 visual expert labels 은 Prismer 에 포함한다.
Prismer 는 생성 모델로, language modeling 이나 prefix language modeling 같은 vision-language 추론 작업을 새로 만들었다.
3.2 Pre-trained Experts
Prismer 는 두 가지의 pre-trained experts 를 포함한다.
- Backbone Experts
- vision 과 language 모델 모두 transformer 아키텍처를 기반으로 한다
- 학습가능한 components 로 쉽게 연결
- 모델 parameter 에 encoding 된 domain knowledge 를 보존하기 위해 pretraining 면서 대부분의 weight 를 동결
- Modality Experts
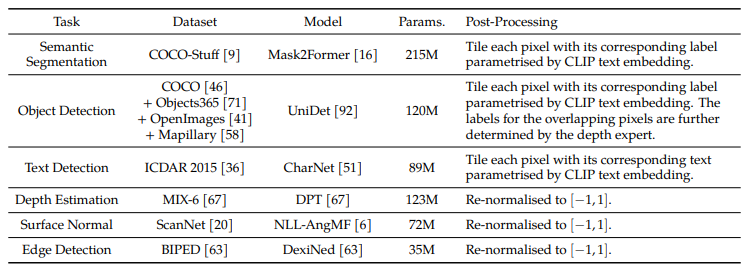
- low-level vision signals: depth, surface, edge; high-level vision signals: object labels, segmentation labels, text labels; 를 인코딩한 6 modality expert 포함
- 위 mdality experts 는 black-box 예측기
- modality experts 의 weight 를 동결하여 어떤 설계도 가능하도록 함
위 predicted labels 에 modality 별로 후 처리 후 tensor 로 transforming 한다 (H, W, C 는 height, width, channel 임. e.g. depth 는 , surface 는 ).
high-level semantic signal 를 인코딩한 모든 experts 에 대해, 각 픽셀을 이에 대응하는 pretrained CLIP model 로 text embedding 과 함께 tiling 한다.
이후 효과적인 훈련을 위해서 PCA 를 적용하여 차원수를 으로 down-sampling 한다.
모든 modality experts 에 대한 자세한 사항은 아래 테이블과 같다.
3.3 Key Architectural Components
Modality-Specific Convolutional Stem
모든 experts labels 는 처음에 무작위로 초기화된 convolution layer 를 지난다.
- 같은 차원수로 매핑하기 위함
- 5 convolution layers 를 적용
- 각각에
[3 x 3]의 작은 커널을 구성 - 기존 ViT 의 큰 커널로 된 single convolutional layer 보다 성능이 좋음
For high-level semantic labels
- 실행중인 메모리를 보존하기 위해 해상도를 4배로 다운 샘플링
- object instance 간의 차이를 식별하기 위해 학습 가능한 무작위로 샘플링된 embedding 을 추가 → instance embedding, 128 로 설정
For RGB images
- 간단하게 pretrained vision 백본으로 convolutional stem 정의
- 모든 modality expert embedding 은 RGB 를 포함하며, transformer layer 를 지나기 전에, pretrained positional embedding 을 추가한다.
Experts Resampler
self-attention 의 계산 복잡도는 patch 수에 비례하므로, modality experts 의 수가 크면 쉽게 많은 메모리를 요구할 수도 있다.
이 이슈를 해결하기 위해 Experts Resampler 를 제안한다.
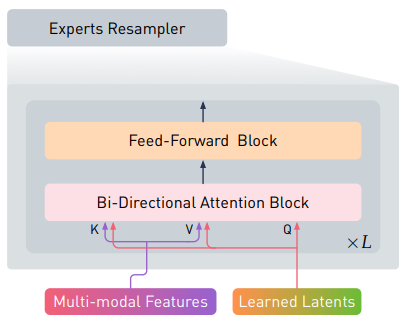
For Experts Resampler
- 다양한 experts 를 input 으로 받음
- 고정된 수의 embedding 을 출력
- language decoder 와 vision encoder 와 무관하게 self-attention 계산에 대해 일정한 메모리를 소모
- 모든 multi-modal features 에서 연결된 flattened embedding 을 cross-attend 하기 위해 pretrained latent query 를 학습
- 이후 multi-modal features 를 auxiliary knowledge distillation 형태처럼 latent query 의 수와 동일한 작은 수의 토큰으로 압축한다.
- 결국, 더 좋은 효과를 위해 multi-modal features 와 learned latent queries 를 연결하기 위해 key 와 value 로 설계
Lightweight Adaptor
multi-modal features 의 표현력과 훈련성을 향상 시키기 위해 vision 과 language 백본 모델의 각 transformer layer 에 lightweight adaptor 를 삽입
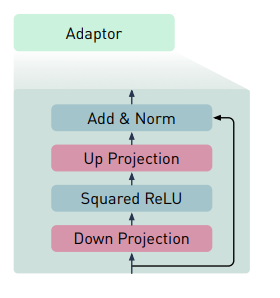
For Lightweight Adaptor
- 먼저, input feature 를 non-linearity 적용으로 작은 차원으로 down-projection 한다.
- 훈련 안정성을 위해 Squared ReLU 를 사용한다.
- 이후, input 의 원래 차원으로 되돌리기 위해 up-projection 한다.
- residual connection 을 이용하여, identity function 을 일치시키기 위해 near-zero weights 로 모든 adaptor 를 초기화 한다.
위 adaptor 를 통해서, language decoder 에서 cross attention block 과 연결하여 domain 별 vision 및 language 백본을 vision-language 로 자연스럽게 변환시킨다.
3.4 Training Objective
저자는 Prismer 를 next token 을 autoregressive 하게 예측하기 위한 한 가지 목표로 훈련 시켰다.
표준 encoder-decoder 아키텍처에 따라 다음의 forward autoregressive factorisation 진행
- vision encoder 의 multi-modal feature 예측값
- language decoder 는 길이만큼 text caption 의 조건부 우도 (conditional likelihood)를 최대화하도록 학습
위 목표는 gradient 계산을 위해 한 번의 forward pass 만 요구되며, 다른 VLMs 보다 효과적이고 능률적이다.
하지만 모델은 multi-modal language generation 에 초점을 두기 때문에, image-text retrieval 이나 visual entailment 와 같은 mutli-modal discriminative task 에는 적합하지 못하다.
4. Experiments
4.1 Prismer Model Variants
Prismer 말고도, Experts Resampler 없이 RGB 이미지 만으로 학습을 진행한 PrismerZ 도 있다.
두 모델은 vision encoder 에 pretrained CLIP, language decoder 에 RoBERTa 를 활용했다.
실험 초기엔 다른 언어 모델인 OPT 나 BLOOM 을 사용했지만 좋은 성능은 내지 못했다.
모델 사이즈는 LARGE, BASE 두 가지로 진행을 한다.
- BASE : ViT-B/16 and RoBERTa
- LARGE : ViT-L/14 and RoBERTa
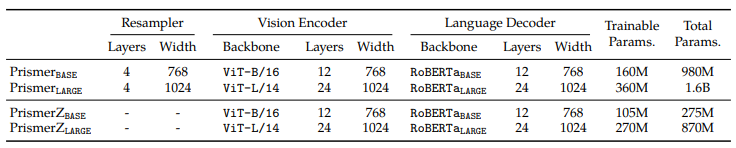
4.2 Training and Evaluation Details
Pre-training Datasets
in-domain 데이터셋
- COCO
- Visual Genome
web 데이터셋
- Conceptual Captions
- SBU captions
- Conceptual 12M
web 데이터셋은 image captioner 로 pre-filter 와 re-caption 을 거쳤다.
데이터셋은 11M image 또는 12.7M 의 image/text 쌍을 포함하고 있다.
Optimisation and Implementation
Optimizer
- AdamW
- weight decay, 0.05
Model Sharding
- model parameters 의 일부만 훈련이 가능하여 고해상도 fine-tuning 할 때만 적용
- 모든 GPU 에 교차하여 optimiser states 와 parameter gradient 가 가능한 ZeRO Stage 2 기술을 채용
Mixed Precision
- 훈련 시간 감소를 위해 Automatic Mixed Precision (AMP) 사용
- fp16 precision 적용
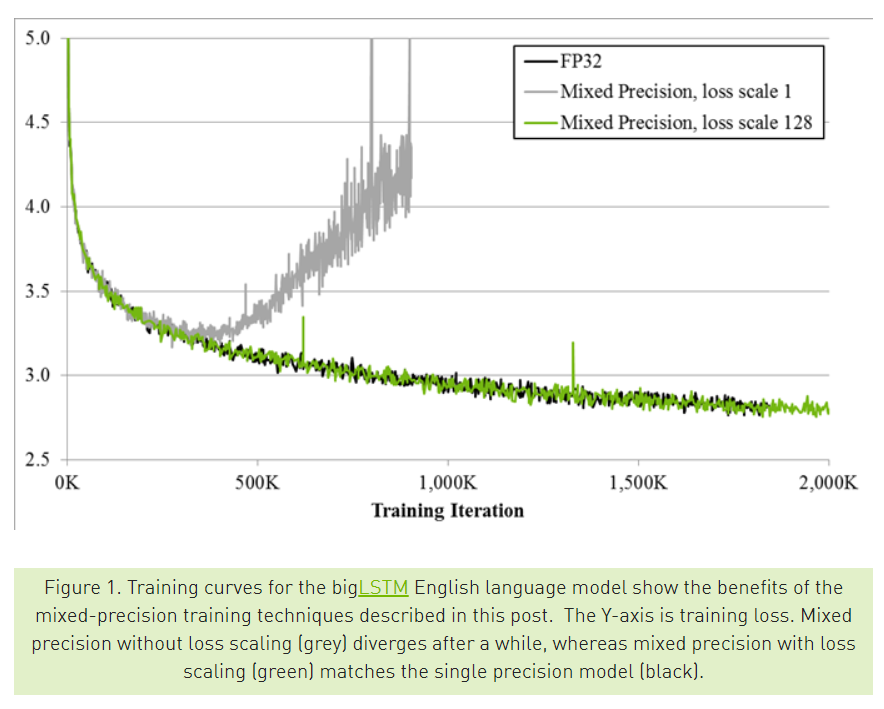 비트 수가 줄어든 만큼 backpropagation 을 진행하면서 정확한 수를 표현 못하기 때문이다.
비트 수가 줄어든 만큼 backpropagation 을 진행하면서 정확한 수를 표현 못하기 때문이다. 이에 NVIDIA 측에서 이를 해결하고자 다음과 같은 automatic 방법을 제안한 것
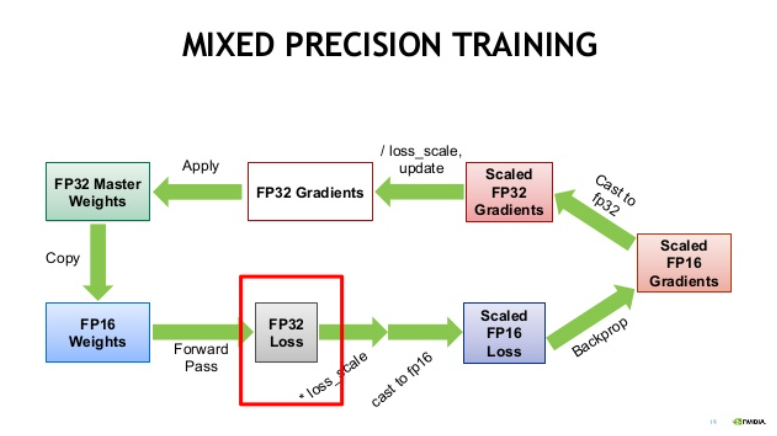 모델 최적화 및 훈련 속도 감소를 가능케 한다.
모델 최적화 및 훈련 속도 감소를 가능케 한다.
Evalution Setting
image captioning 평가를 위해 텍스트 생성을 beam size 3 으로 beam search 를 사용한다.
fine-tining 된 image captioning 에 "A picture of" 라는 접두사 prompt 를 input text 에 추가하니 품질 개선에 도움이 되는 것을 발견했다.
VQA 및 image classification 평가에 대해서는 미리 정의된 답변 목록에서 token 단위로 log-likelihood 를 순위로 매겨서 closed ended 방식으로 평가한다.
beam search NLP 분야의 Decoder 알고리즘모든 단어 조합을 생성하고 그 중 가장 가능성이 높은 조합을 선택하는데, 이때 단어 조합 수를 파라미터인 "beam size" 를 설정한다. 즉, beam size 는 후보군 개수이다. Open-ended & Close-ended Open-ende 는 문제에 대한 미리 정의된 대답에 제한되지 않고, 개념적 이해나 문맥적 이해가 필요한 것. 예로 이미지 캡셔닝 작업에서 이미지에 대한 설명이나 이야기를 생성
Close-ended 는 미리 정의된 목록에서 선택할 수 있는 한정된 대답만 가지고 문제를 해결 하는 것. 예로 이미지가 주어졌을 때 미리 정의된 카테고리 목록에 해당하여 분류 되는지 봄
4.3 Results on Vision-Language Benchmarks
Fine-tuned Performance COCO Caption, NoCaps and VQAv2
표준 cross-entropy loss 로 COCO Caption 을 fine-tuning 진행
이후, COCO Caption test 와 NoCaps validation, VQAv2 dataset 와 Visual Genome training samples 로 평가
다른 VLMs 모델들과 다음과 같이 비교를 하였다.

Zero-shot Performance on Image Captioning
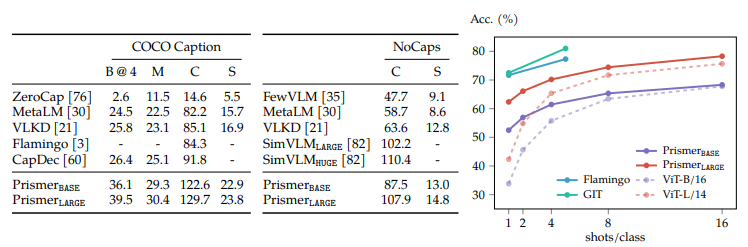
Fig 4
Prismer approach 는 zero-shot 생성도 가능하며, 추가적인 fine-tuning 없이 image captioning 에 직접적으로 적용이 가능하다.
위 중앙 테이블을 살펴보자.
- NoCaps 데이터셋에서, 140회 정도의 훈련만으로 SimVLM 과 경쟁력이 있다.
다음과 같은 Prismer 로 생성한 caption 목록 예제를 보여준다.

Few-shot Performance on ImageNet Classification
few-shot 으로 ImageNet 데이터셋을 통해 평가를 진행
"A photo of a [CLASS NAME]" 과 같은 임시 caption 으로 각 카테고리를 매핑하여 classification task 로 변환하였으며, log-likelihood 를 사용하여 모든 caption 에 점수를 매긴다.
Flamingo 는 gradient 업데이트 없이 in-context (문맥에 포함되는지) 를 통해 few-shot 한것과 달리, Prismer 는 가벼운 fine-tuning 으로 few-shot 하였다.
Fig 4 의 오른쪽을 살펴보자.
- GIT 이나 Flamingo 보다는 좋은 실적을 내지 못함.
- few-shot 에서 백본 모델인 ViT-B 와 ViT-L 과 큰 차이로 성능이 좋음
- 위 사실로, 더 좋은 experts label 이나 vision backbone 으로 성능을 더 끌어올릴 수 있다는 것을 시사
5. Additional Analysis
저자는 Prismer 에 대한 추가적인 조사와 발견을 위해 추가 실험을 수행, 여러 component 아키텍처 를 제거
모든 실험은 BASE 모델로 진행하였으며, 총 3M data 인 Conceptual Captions 와 SBU 를 결합하여 훈련 하였으며, 평가는 [224 x 224] 해상도의 VQAv2 로 평가했다.
5.1 Intriguing Properties of Prismer
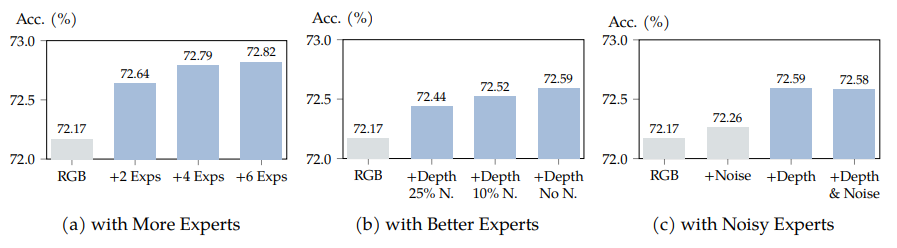
More Experts, Better Performance
- 위 그림의 (a) 와 같이 더 많은 modality experts 를 추가하니 성능 개선이 나타남
- 이유는 모델에 더 많은 domain knowledge 를 제공할 수 있기 때문
- 하지만 끝내 성능이 정체되며, 이후 추가되는 modality experts 는 확실한 이득을 제공하진 않음
Better Experts, Better Performance
- 위 그림 (b) 와 같이 expert 의 퀄리티에 대한 영향을 평가
- 일정 수의 예측된 depth labels 를 손상된 depth 로 교체 (균일하게 분포된 무작위 noise 를 샘플링)
- 위 사항으로 좋은 quality experts 는 더 정확한 domain knowledge 를 제공한다는 사실을 관찰
Robustness to Noisy Experts
- 위 그림 (c) 와 같이Prismer 가 noise 를 예측하는 expert 를 포함해도 성능이 유지되는 것을 관찰
- RGB 이미지만 학습한 것 보다 noise 를 추가한 것이 정확도가 좋다.
- 위 사항은 암묵적으로 정규화로 간주될 수 있으며, Prismer 가 유익하지않은 expert 에 대해서도 안전하게 학습하고 성능 저하를 일으키지 않는 다는 것이다
- 표준적인 multi-task 나 auxiliary learning 보다 더 효과적인 학습 전략이라는 것을 암시
5.2 Architecture Design and Training Details
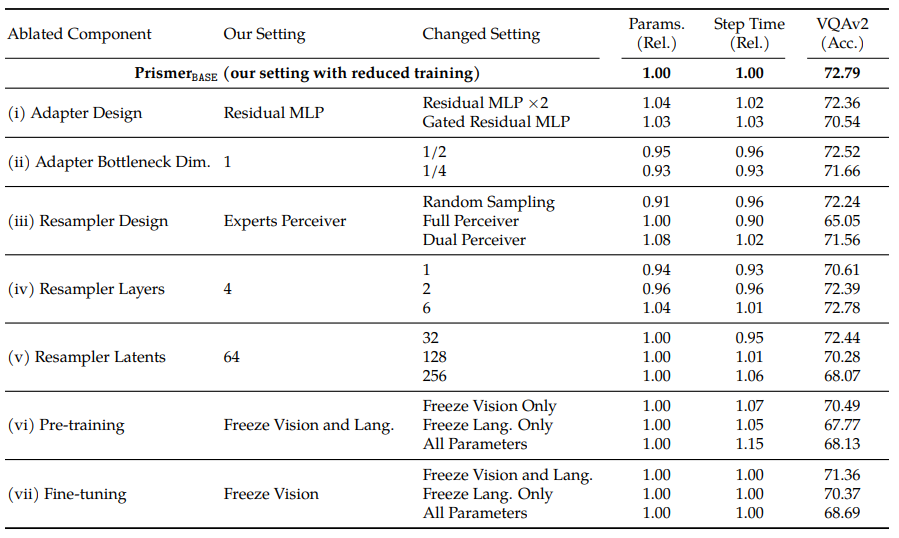
Adaptor Design and Size
adaptor 설계에 대한 ablation study 는 위 표에서 확인할 수 있다.
표준 residual connection 과 encoder-decoder 구조가 포함된, 간단한 adaptor design 이 가장 성능이 좋았다.
각 transformer layer 끝마다 adaptor 를 추가하거나 learnable gating 메커니즘을 구성한 복잡한 설계에 대해서는 성능이 좋지 않았다.
나아가, 단일 adaptor 에 큰 bottleneck hidden size 를 주니 개선된 성능을 보였다.
Resampler Design and Multi-modal Sampling Strategy
resampler 설계에 대한 ablation study 는 위 표에서 확인할 수 있다.
간단한 설계가 학습에 가장 적합했다.
무작위로 non-learnable 샘플링한 접근법은 learnable resampler 보다 성능이 낮았고, resampler 를 RGB 를 포함하여 모든 input signal 을 받아 들이니 (Prismer design 은 RGB 에 대해선 받지 않음) 성능 감소가 일어났다.
마지막으로 resampler 크기를 키우니 이득을 얻지 못하였다.
The Effect of Frozen Backbones
모델을 freezing 한 것과, pre-training 및 fine-tuning 을 비교한 실험을 진행
freezing pre-trained 파라미터가 좋은 성능이 나타났으며, 과적합 및 학습하며 배운 knowledge 을 잊는 것을 피하였다.
또한 이 파라미터들을 freezing 을 하니 GPU 메모리의 상당 수의 양을 save 하였다.
심지어 다른 downstream task 에 fine-tuning 할 때도 이득을 얻었다.
6. Conclusions, Limitations and Discussion
이 논문의 결론으로 Prismer 가 적은 수의 trainable components 를 활용하여, Image captioning, VQA, image classification 등에 좋은 성능을 보인다는 것을 말한다.
Multi-modal In-context Learning
- zero-shot in-context generalisation 은 큰 언어 모델에만 존재하는 신생적인 특성
- Prismer 는 효율적인 학습을 중점으로 두어, 작은 규모라서 few-shot in-context prompting 수행 능력이 없음
Zero-shot Adaptation on New Experts
- 다른 데이터셋으로 pre-train 한 segmentation expert 로 pre-train 된 Prismer 의 추론을 실험
- 동일한 언어 모델로 semantic label 을 인코딩하지만, 서로 다른 semantic 정보에 대한 experts 에 대해 제한된 적응성을 보여, 성능 저하를 일으킴
Free-form Inference on Partial Experts
- 위 내용과 비슷하게, Prismer 가 pretraining 할 때 포함되는 모든 experts 의 multi-modal features 에 얽매이는 것을 발견
- 따라서 추론 중 일부 experts 만 있으면 성능 저하를 일으킴
- 마스킹된 auto-encoding 같은 다른 훈련 목표로, Prismer 를 임의의 수로 experts 를 기반으로 추론하니 성능 저하가 일어남
Representation of Expert Knowledge
Prismer 는 모든 experts 에 대해 후 처리 후 이미지와 동일한 3차원 텐서로 변환하는데, object detection labels 을 텍스트 토큰 시퀀스로 변환과 같은 domain knowladge 을 나타내는 효과적인 방법도 있으며, 이는 앞으로의 연구에서 더 강한 추론과 안정적인 훈련이 가능할 것으로 보임.
