논문 및 이미지 출처 : https://arxiv.org/pdf/2303.06674v1.pdf
Bin Yan1*, Yi Jiang2,†, Jiannan Wu3, Dong Wang1,†, Ping Luo3, Zehuan Yuan2, Huchuan Lu1,4
School of Information and Communication Engineering, Dalian University of Technology, China, ByteDance, The University of Hong Kong 4 Peng Cheng Laboratory
Abstract
본 논문에서 universal instance perception model 에 대한 next generation 인 UNINEXT 를 제안한다.
기존의 모든 instance perception task 는 category names, language expressionbs, target annotations 와 같은 query 들로 객체를 찾는 것이 목표지만 이들은 모두 독립적인 하위 task 로 분할되어 있는데, 이를 범용적으로 인식할 수 있는 새로운 기술을 제안하는 바이다.
다양한 instance perception task 를 통합된 객체 탐지 및 retrieval paradigm 으로 재구성하고, input prompt 를 단순화하여 객체를 유연하게 인식한다.
이렇게 통합하여 다음 이점을 얻을 수 있다.
- 서로 다른 tasks 및 label vocabularies 에서 대량의 데이터를 공동으로 훈련하여 일반적인 instance-level 의 표현을 교육하는 데 매우 유용. 특히 훈련 데이터가 부족한 작업에 이점을 제공
- 통합 모델은 매개 변수 효율적이며, 여러 작업을 동시에 처리할 때 중복 계산을 줄일 수 있음
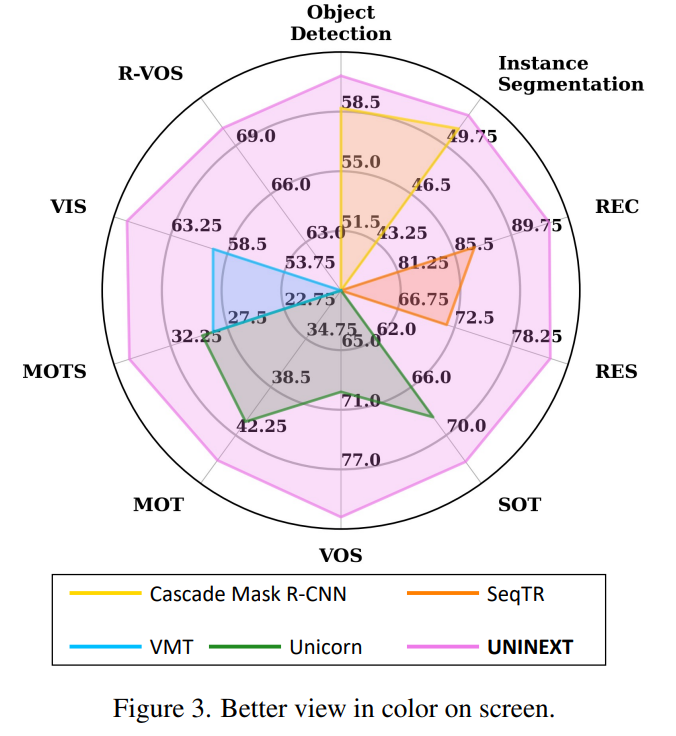
UNITEXT 는 고전적인 image-level task (object detection, instance segmentation), vision-language task (referring expression comprehension, segmentation) 및 6 개의 video-level object tracking task 를 포함하는 10 개의 instance-level task 로부터 총 20 개의 어려운 벤치마크에 대해 우수한 성능을 보여준다.



1. Introduction
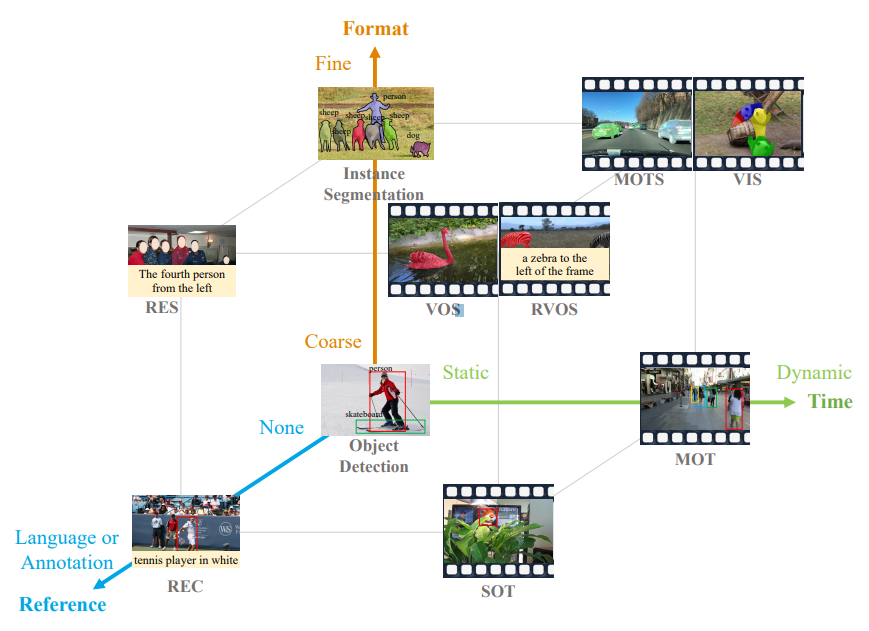
본 논문에서는 위의 정육면체 꼭짓점에 나타낸 10개의 sub-tasks 에 대해 논의한다.
- 가장 기본적인 task 인 object detection, instance segmentation 은 box 와 mask 로 특정 categories 의 모든 객체를 찾아야 한다.
- 정적 이미지를 동적 비디오로 입력을 확장할 경우, Multiple Object Tracking (MOT), Multi-Object Tracking and Segmentation (MOTS), Video Instance Segmentation (VIS) 는 비디오에서 특정 category 의 모든 객체 궤적을 찾아야 한다.
위와 같은 category names task 외의 몇몇 task 는 다른 참조 정보를 제공한다.
- Referring Expression Comprehension (REC), Referring Expression Segmentation (RES), Referring Video Object Segmentation (R-VOS) 는 "왼쪽에서 네 번째 사람" 과 같은 language expressions 과 일치하는 객체를 찾아야 한다.
- Single Object Tracking (SOT), Video Object Segmentation (VOS) 는 첫 번째 프레임에서 제공된 target annotations (box or mask) 을 참조하여 후속 프레임에서 객체의 궤적을 예측해야 한다.
위에서 언급한 모든 tasks 는 특정 속성의 instance 를 인지하려는 것이기 때문에, 이를 instance perception 이라 칭한다.
최근, 대부분의 instance perception 으로 sub-tasks 의 일부분 또는 하나에 대해서만 개발되며, 특정 domain 으로 분리하여 훈련되는데, 이는 다음과 같은 단점을 지닌다.
- 각 독립적인 설계는 서로 다른 task 및 domain 간의 knowledge 학습을 공유하는 것을 방해하며 중복 매개변수를 초래
- 서로 다른 task 간의 상호 기여의 가능성이 간과된다.
- 고정 크기의 classifier 로 제한된 전통적인 object detector 는 다양한 label vocabularies 가 있는 여러 데이터셋을 공동으로 훈련하는 것과 추론 중에 감지할 object categories 를 동적으로 변경하는 것은 어려움
따라서, 본질적으로는 모든 instance perception tasks 는 모든 queries 에 따라 특정 물체를 찾는 것을 목표로 한다.
이에 모든 주요 instance perception tasks 를 한 번에 해결할 수 있는 통합 모델을 설계할 수 있을까?
이 질문에 대한 대답으로 UNINEXT 를 제안
먼저 10 가지의 instance perception 인식 tasks 를 input prompt 에 따라 3 가지 유형으로 재구성
- category names 의 prompt (Object Detection, Instance Segmentation, VIS, MOT, MOTS)
- language expressions 의 prompt (REC, RES, R-VOS)
- reference annotations 의 prompt (SOT, VOS)
그런 다음, 위 tasks 를 해결하기 위해 통합된 prompt-guieded 객체 발견과 retrieval formulation 를 제안
- 먼저, prompt 의 가이드 하에 N 개의 object proposals 를 발견
- 이후, instance-prompt 매칭 점수에 따른 proposals 로부터 최종 instance 를 찾음
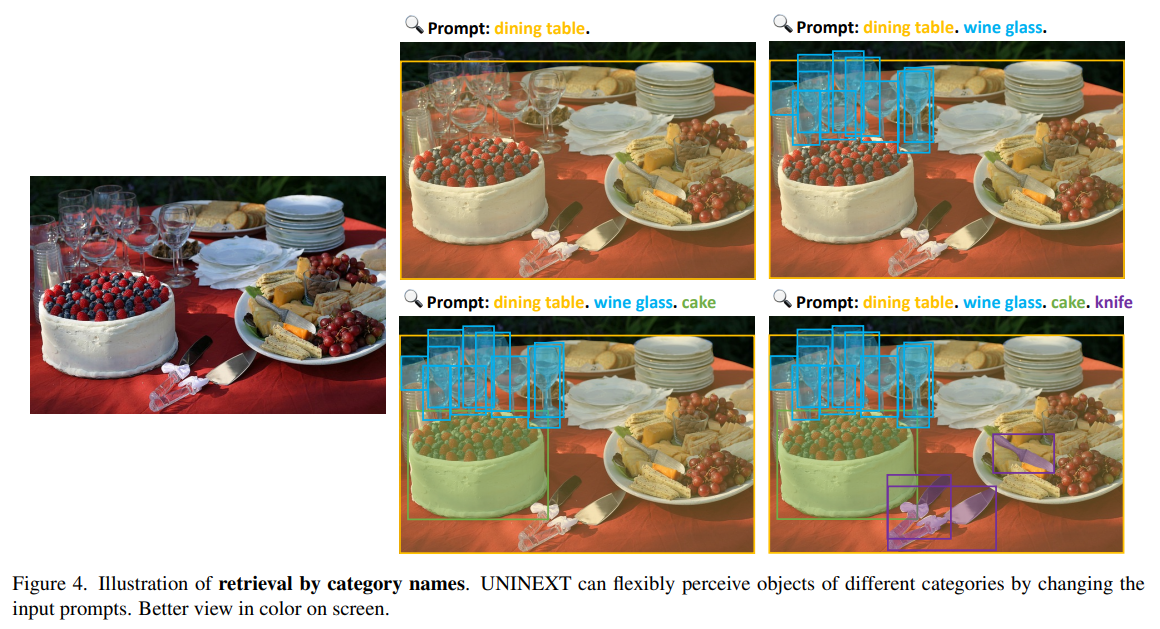
위 새로운 formulation 을 기반으로, prompt 를 간단하게 바꿔서 다양한 instance 를 유연하게 찾을 수 있게 된다.
또한 다양한 prompt modalities 를 다루기 위해 다음을 제안
- reference text encoder 와 reference visual encoder 로 구성된 prompt generation module 을 채택
- early fusion module 을 현재 이미지의 원시 비주얼 특성과 prompt embedding 을 향상 시키기 위해 사용
위 작업으로 깊은 정보 교환이 가능하고 후속 instance 예측 단계에 대해 높은 구별력을 제공한다.
유연한 query-to-instance 방식을 고려하기 위해 다음을 제안
- Transformer 기반의 object detector 를 instance decoder 로 선택
- 특히, 이 decoder 는 먼저 N 개의 instance proposals 를 생성
- 그후, prompt 를 사용하여 위의 instance proposals 로부터 매칭되는 object 를 찾는다.
이 검색 메커니즘은 전통적으로 사용하는, 고정된 크기의 classifier 를 극복하고 서로 다른 task 와 domain 의 데이터를 공동으로 훈련할 수 있다.
이러한 통합된 모델 아키텍처인 UNINEXT 는 다양한 task 의 대규모 데이터를 강력한 generic representations 를 학습하고 동일한 모델 파라미터로 10 가지의 instance-level perception tasks 를 해결할 수 있다.
실험 결과 20 가지의 벤치마크에서 우수한 결과에 달성했으며 이라한 기여를 다음과 같이 요약한다.
- universal instance perception 에 대해 통합된 prompt-guided formulation 을 제안하며, 분산된 instance-level 의 sub-tasks 를 하나로 통합
- 유연한 객체 발견과 검색 파라다임의 이점을 살린 UNINEXT 는 특정 task 헤드가 필요하지 않으므로 서로 다른 tasks 와 domains 를 훈련할 수 있다.
- 동일한 model parameter 로 10 가지의 instance perception tasks 의 20 가지 벤치마크에 대해 우수한 결과 달성
2. Related Work
3. Approch
introduction 에서 언급한 것과 같이, instance perception tasks 를 3 가지의 class 로 분류한다.
- Object detection, instance segmentation, MOT, MOTS 및 VIS 는 category names 를 prompt 로 사용하여 특정 class 의 모든 instance 를 찾는다.
- REC, RES 및 R-VOS 는 expression 을 prompt 로 이용하여 특정 타깃을 localizing 한다.
- SOT 와 VOS 는 첫 프레임에 주어진 annotation 을 prompt 로 사용하여 추적하는 타깃의 궤적을 예측한다.
위 tasks 는 prompt 로 특정 객체를 찾는 것을 목표로 한다.
그리고 이 방법은 모든 instance perception tasks 를 prompt-guided 객체 발견과 retrieval problem 으로 재구성하는 동기를 주며 통합 모델 아키텍처와 학습 파라다임으로 해결한다.
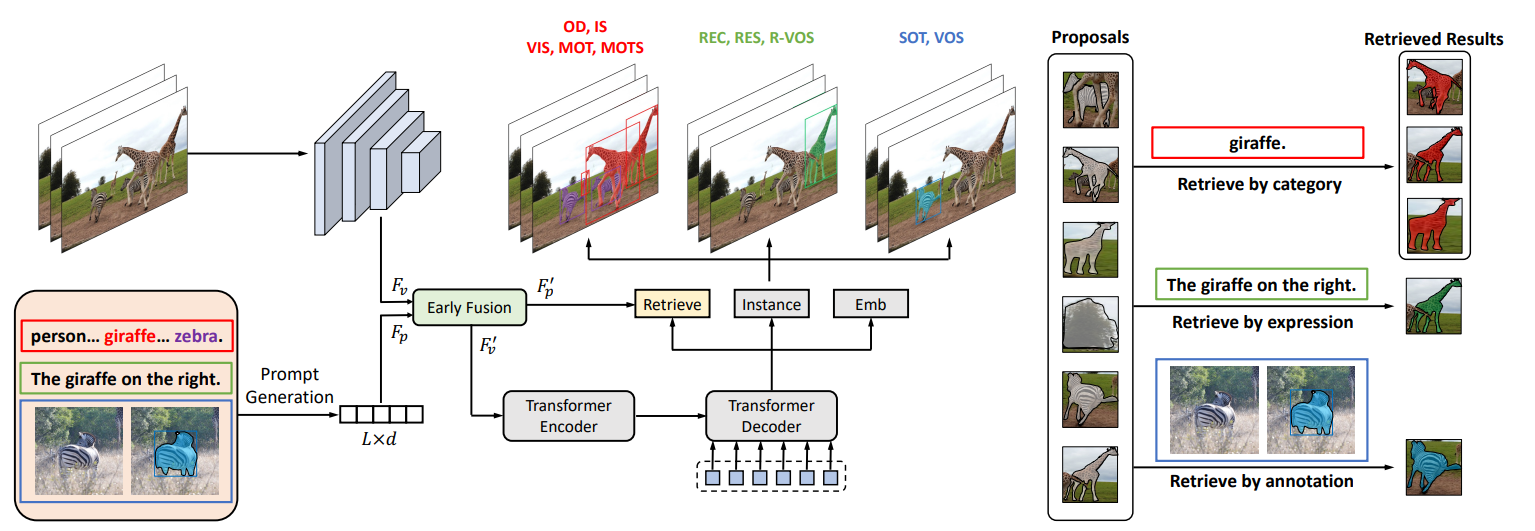
다음 그림으로 입증할 수 있다.
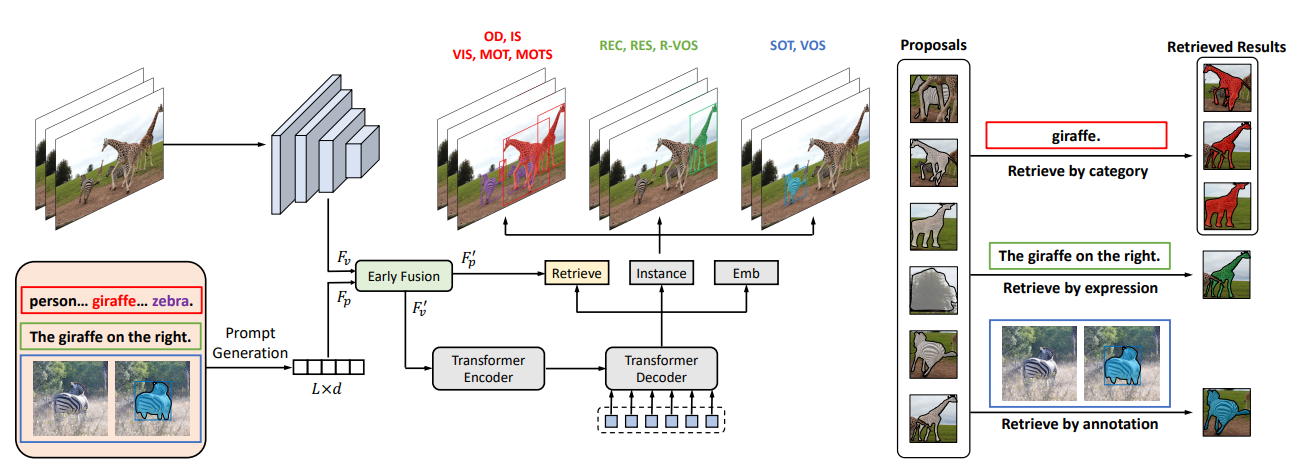
UNINEXT 는 다음 세 가지의 주요 컴포넌트를 포함한다.
- prompt generation
- image-prompt feature fusion
- object discovery and retrieval
3.1 Prompt Generation
먼저, prompt generation modile 은 원본의 다양한 prompt 입력을 통합된 형태로 변환하기 위해 채택됐다.
다음 두 단락에서 각각의 modalities 에 대한 대응 전략을 소개한다.
언어관련 prompt 를 처리하기 위해 language encoder 인 를 채택한다.
구체적으로 category-guided tasks 에 대해, 현재 데이터셋에서 나타난 class names 를 언어 표현으로 연결한다.
COCO 를 예로, 표현식을 "person. bicyle, .. , toothbrush" 와 같이 작성될 수 있다.
이후 category-guided 및 expression-guided tasks 등의 언어 표현식은 에 전달되어, 시퀀스 일이 인 prompt embedding 가 생성된다.
annotation-guided tasks 에 대해선, fine-grained visual 특징을 추출하고 target annotations 를 완전히 활용하기 위해, 추가적인 reference visual encoder 인 를 도입한다.
구체적으로, 참조하는 프레임에서의 타깃 위치 중심으로 맞춰진 배의 타깃 박스 영역 템플릿을 자른다.
이후, 이 템플릿을 의 고정된 사이즈로 조정한다.
더 정확한 정보를 도입하기 위해, target prior 이라는 추가된 channel 은 템플릿 이미지에 연결되어 4-channel 입력을 형성한다.
자세히 말해, target prior 의 값 target region 에서는 1 이고, 그 외에는 0 이다.
이후, target prior 과 함께한 이 템플릿 이미지는 reference visual encoder 에 전달되어, hierarchical feature pyramid 를 얻는다.
각 구역의 사이즈는 , , , 이다.
타깃 정보를 유지하고 다른 작업과 동일한 형식의 prompt embedding 을 얻기 위해 병합된 모듈이 적용된다. 다시말해, 피처의 모든 level 는 먼저 으로 다운샘플링을 한 후에 추가되며, 최종적으로는 의 prompt embedding 으로 flatten 된다.
Fine-Grained & Coarse-GrainedFine-Grained
- 하나의 작업을 작은 단위의 프로세스로 나눈 뒤, 다수의 호출을 통해, 작업 결과를 생성해내는 방식
- 예를 들어, Do() 라는 함수가 있다면 해당 함수를 First_Do(), Second_Do() 로 나누어 작업 결과를 생성해내는 방식
- 따라서, 다양한 "Flexible System" 상에서 유용하게 쓰일 수 있음
Coarse-Grained
- 하나의 작업을 큰 단위의 프로세스로 나눈 뒤, "Single Call" 을 통해, 작업 결과를 생성해내는 방식
- 예를 들어, Do() 라는 함수가 있다면 단순히, Do() 를 호출해 작업 결과를 생성해내는 방식
- 따라서, "Distributed System" 상에서 유용하게 쓰일 수 있음
위의 prompt 생성 과정은 다음과 같은 공식으로 나타낼 수 있다.
3.2 Image-Prompt Feature Fusion
prompt 생성과 병렬로, 현재의 이미지 전체는 다른 visual encoder 로 전달되어, hierarchical visual features 를 얻는다.
image contexts 로 원본 prompt embedding 을 강화시키고 원본 visual features 를 prompt-aware 하게 만들기 위해서, early fusion module 를 채택한다.
구체적으로, 다양한 입력의 정보를 찾기위해 bi-directional cross-attention module (Bi-XAtt) 를 사용한다.
이후, retrieved representations 를 원본 features 에 추가한다.
위의 prompt 생성 과정은 다음과 같은 공식으로 나타낼 수 있다.
feature 향상을 위해 6 개의 vision-language fusion layer 와 6 개의 추가 BERT layer 를 채택하는 GLIP 과 달리, early fusion module 은 훨씬 더 효율적이다.
3.3 Object Discovery and Retrieval
판별적인 visual 과 prompt representations 과 함께, 다음 중요한 단계는 다양한 인식 tasks 에 대해 input features 를 instance 로 변환하는 것이다.
UNINEXT 는 Deformable DETR 에서 제안된 encoder-decoder 아키텍처를 채택하여 유연한 query-instance 형식을 사용한다.
Transformer encoder 는 hierarchical prompt-aware viusal feature 를 input 으로 사용한다.
효율적인 Multi-scale Deformable Self-Attention 의 도움으로, 서로 다른 스케일의 타깃 정보를 교환할 수 있으며, 후속 instance decoding 에 대한 강력한 instance feature 를 제공해준다.
또한, Deformable DETR 의 두 단계에서 수행처럼, auxiliary prediction head 는 encoder 의 끝에 추가되어, 가장 높은 점수를 가진 개의 초기화된 reference points 를 생성하여 decoder 의 input 으로 사용한다.
Transformer decoder 는 향상된 multi-scale features 인, encoder 의 N 개의 reference points 와 N 개의 object queries 를 input 으로 사용한다.
이전 연구처럼, object queries 는 instance perception tasks 에서 중요한 역할을 한다. 본 연구는 두 가지의 query 생성 전략을 시도한다.
- 이미지 또는 프롬프트에 상관없이 변하지 않는 static queries
nn.Embedding(N, d)로 쉽게 구현 가능
- 프롬프트에 의존적인 dynamic queries
- 먼저 향상된 prompt features 를 pooling 하여 global representation 을 얻은 다음, 번 반복하여 수행할 수 있음
위 두 방법으로 정적 쿼리가 동적 쿼리보다더 나은 성능을 발휘 한다는 것을 발견했다. 이유는 정적 쿼리가 동적 쿼리보다 더 많은 정보를 포함하고 더 나은 훈련 안정성을 진행하기 때문이다.
deformable attention 의 도움으로, object queries 는 효율적으로 prompt visual features 를 찾으며, 강력한 instance embedding 를 학습할 수 있다.
decoder 의 끝 부분에서는 최종적인 instance predictions 을 얻기 위해 prediction heads 그룹을 활용한다.
구체적으로, instance head 는 타깃의 boxes 와 masks 를 생성한다. 또한, embedding head 는 현재 감지된 결과와 MOT, MOTS 및 VIS 의 이전 궤적과 연관시키기 위해 도입된다.
지금까지, 위 그림에서 회색 마스크로 나타낸 개의 잠재적인 instance proposals 를 채굴했지만, 모든 proposals 는 prompt 가 실제로 참조하는 타깃을 나타내는 것은 아니었다.
따라서, 그림의 오른쪽처럼 prompt embedding 에 따라 이러한 proposals 로부터 실제로 일치되는 타깃을 더 검색해야 한다.
구체적으로, early fusion 후의 prompt embedding 가 주어지면, category-guided tasks 를 위해 각 category name 의 embedding 을 weight matrix 로 사용한다.
또한, expression-guided 와 annotation-guided tasks 를 위해 weight matrix 는 sequence 차원을 따라 global average pooling (GAP) 를 사용하여 prompt embedding 를 집계하여 얻는다.
마지막으로, instance-prompt 매칭 점수 는 타깃 features 과 전치된 가중치 행렬의 행렬 곱으로 계산할 수 있으며 식으로 로 나타낸다.
이전 연구에 따르면, 매칭 스코어는 Focal Loss 로 supervise 될 수 있다.
이전의 고정된 크기의 classifiers 와 달리, proposed retrieval head 는 prompt-instance 매칭 메커니즘으로 객체를 선택한다.
이 유연한 설계는 서로 다른 tasks 의 다양한 label vocabularies 을 가진 거대한 데이터셋을 공동으로 학습하여, UNEXT 를 가능케 한다.
3.4 Training and Inference
Training
전체 훈련 프로세스는 세 단계를 포함한다.
- general perception pretraining
- UNINEXT 를 객체에 대한 범용적인 지식을 학습시키기 위해 object detection 데이터셋인 Object365 로 pretrain
- Object365 는 mask annotations 가 없기 때문에, mask brach 를 훈련하기 위해, BoxInst 에서 제안한 auxiliary losses 를 도입한다. 이 loss function 은 다음과 같다.
- image-level joint training
- 1 단계의 pretrained weight 를 토대로, image datasets 를 공동적으로 UNINEXT 에 finetuning 한다.
- 주로 COCO 와 RefCOCO, RefCOCO+ 및 RefCOCOg 를 섞은 데이터셋이다.
- 수동으로 라벨링된 mask annotations 을 사용하면, Dice Loss 및 Focus Loss 와 같은 전통적인 loss function 을 mask 학습에 사용될 수 있다.
- 이 스텝을 지나면, UNINEXT 는 object detection, instance segmentation, REC 및 RES 에 우수한 성능을 낼 수 있다.
- video-level joint training
- 다양한 downstream object tracking tasks 와 벤치마크를 위해 video-level 데이터셋에 UNINEXT 를 finetuning 한다.
- 원본 비디오에서 무작위로 선택된 두 프레임을 학습한다.
- image-level tasks 에서 학습된 지식을 잊는 것을 방지하기 위해, image-level 데이터셋을 가짜 비디오로 변환하여 공동으로 학습
- 가짜 영상은 COCO, RefCOCO/g/+, SOT&VOS (GOT-10K, LaSOT, TrackingNet 및 Youtube-VOS), MOS&VIS (BDD10K, VIS19, OVIS) 및 R-VOS (Ref-Youtuve-VOS) 를 포함한다
- SOT&VOS 에 대한 reference visual encoder 와 연관성에 대한 추가적인 embedding head 도 도입되어 최적화한다.
Inference
category-guided tasks 에 대해, UNINEXT 는 서로다른 categories 의 instance 를 예측하고 이전 궤적과 연관시킨다.
이 연관성 짓는 과정은 온라인 방식으로 이루어지며, 이전 연구처럼 학습된 instance embedding 만을 기반으로 한다.
expression-guided 와 annotation-guided 에 대해, 주어진 prompt 와 가장 높은 매칭 점수를 가진 객체를 최종 결과물로 선택한다.
오프라인 방식과 복잡한 후처리 과정에 의해 제한되는 이전 연구와 달리, 이 방법은 간단하고, 온라인 방식이며, 후처리가 필요하지 않다.
4. Experiments
4.1 Implementation Details
본 저자는 세 가지의 백본 모델 ResNet-50, ConvNeXt-Large 및 ViT-Huge 를 visual encoder 로 시도한다.
또한 BERT 를 text encoder 로 채택하고 파라미터는 1, 2 번째 훈련 단계에서 훈련되며, 마지막 훈련 단계에서 동결 시킨다.
Transformer encoder-decoder 아키텍처는 DETR 연구에 따라 6 encoder layer 와 6 decoder layer 를 사용한다.
- object queries 수 은 900
- optimizer, AdamW, 0.05 weight decay
- Object365 pretraining 에 대해 32, 16 A 100 GPUs 사용
4.2 Evaluations on 10 Tasks
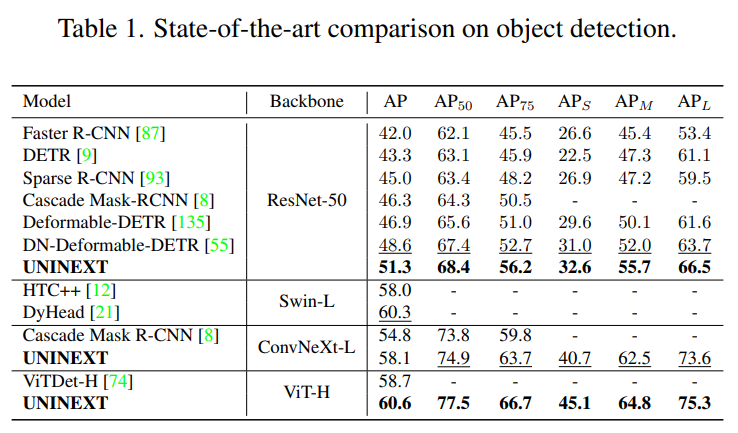
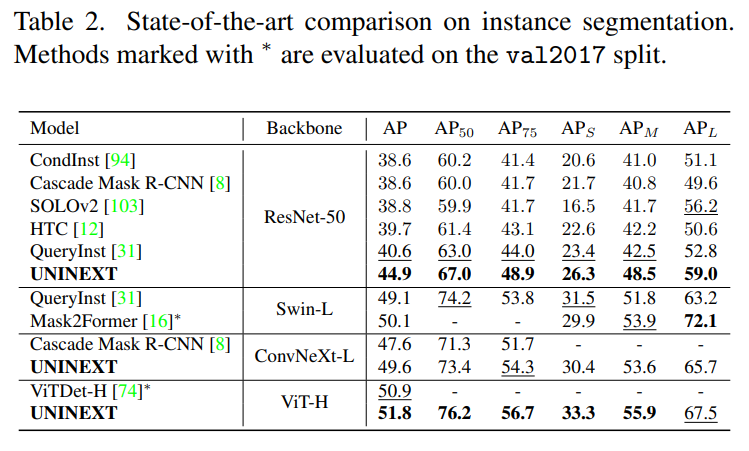
Object Detection and Instance Segmentation
UNINEXT 를 COCO val2017 (5k images) 및 test-dev split (20k images) 에서 SOTA object detection 과 instance segmentation AP 점수 비교
REC and RES
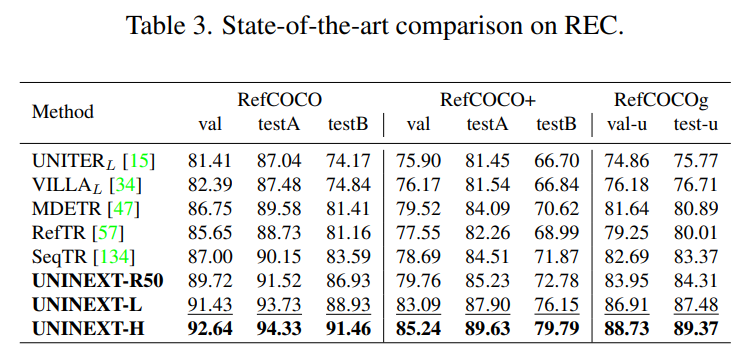
REC 및 RES 를 RefCOCO, RefCOCO+ 및 RefCOCOg 로 평가한다.
REC 및 RES 평가지표는 Precision@0.5 와 Overall IoU (oIoU) 를 채택했다.
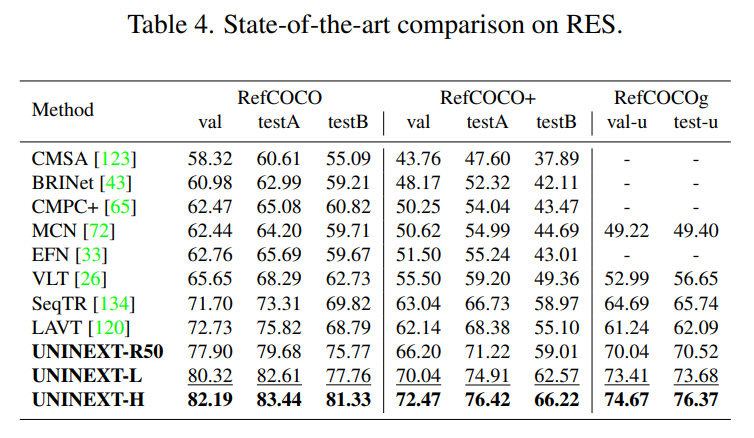
SOT
네 개의 large-scale 벤치마크: LaSOT, LaSOT-ext, TrackingNet 및 TNL-2K 로 SOTA 와 SOT 를 비교했다.
이 벤치마크들은 success curve (AUC), normalized precision () 및 precision (P) 로 평가했으며, 각각 280, 150, 511 및 700 개의 테스트 셋 비디오를 포함한다.
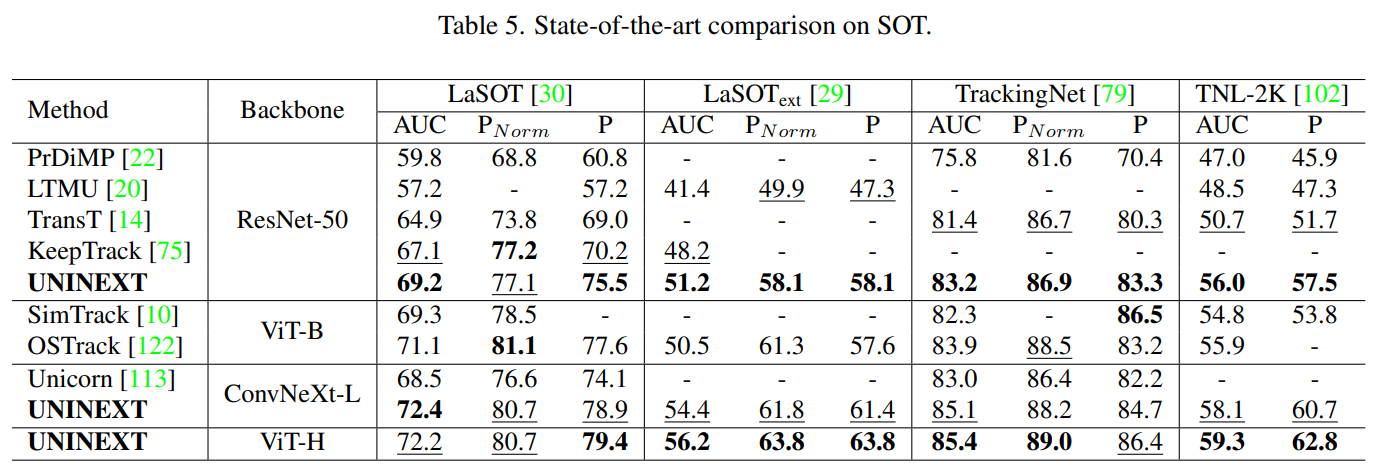
VOS
VOS 는 DAVIS-2017 및 Youtube-VOS 2018 데이터셋으로 평가한다.
DAVIS-2017 은 region similarity , contour accuracy , averaged score 로 나타낸다.
Youtube-VOS 2018 은 와 를 seen 및 unseen categories 로, averaged overall score 는 로 나타낸다.
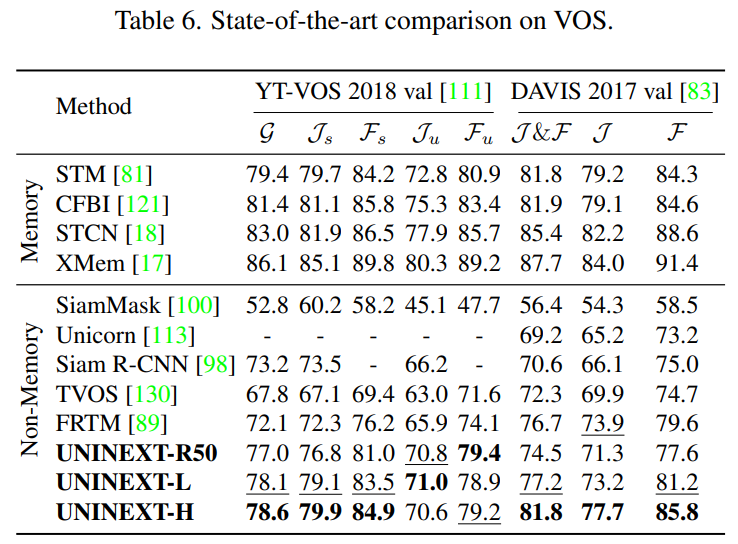
MOT
MOT 에서 자율운전 중 8 개의 class instance 를 추척을 요구하는 BBD100K 에서 SOTA 와 UNINEXT 를 비교한다.
전통적인 평가지표 Multiple-Object Tracking Accuracy (MOTA), Identity F1 Score (IDF1) 및 Identity Switches (IDS) 를 제외하고도, 추가로 도입된 mMOTA 및 mIDF1 로도 성능 평가를 했다.
MOTS
MOT 와 비슷하게, BDD100K MOTS 첼린지에서 mMOTSA, mMOTSP, mIDF1 및 ID Sw 로 multi-class 추적을 평가한다.
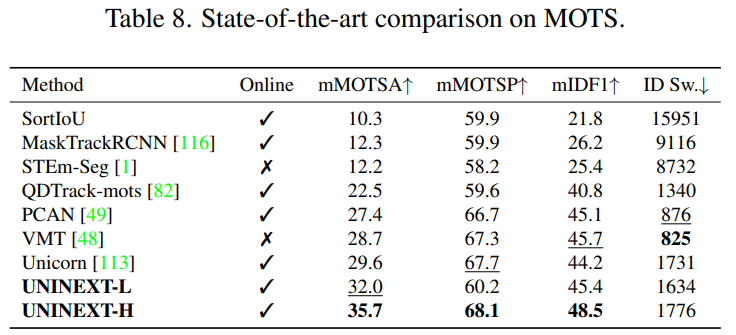
VIS
Youtube-VIS 와 OVIS 검증셋에서 SOTA 와 UNINEXT 를 비교한다.
특히 위 검증셋은 각각 40 및 25 object categories 와 302 및 140 개 비디오 검증셋을 포함한다. 각 벤치마크에 대해 AP 로 평가한다.
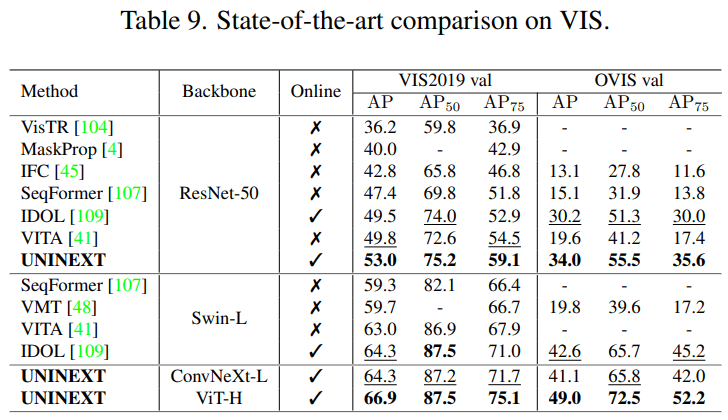
R-VOS
Ref-Youtube-VOS 와 Ref-DAVIS17 은 R-VOS 분야에서 인기 있는 데이터셋으로, object 에 대해 언어표현을 도입한다.
VOS 와 비슷하게 region similarity , contour accuracy , averaged score 를 평가지표로 채택한다.
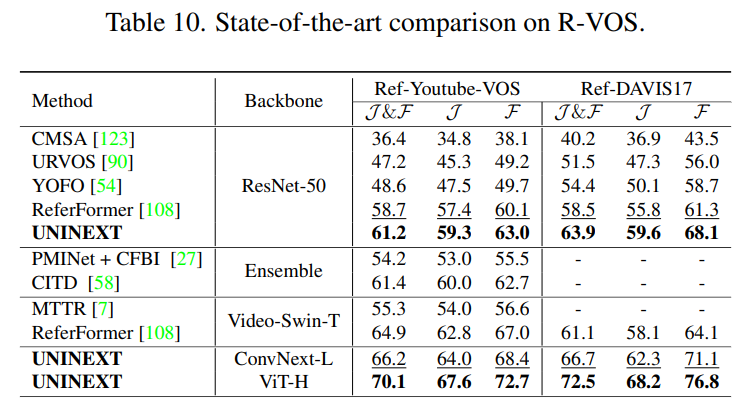
4.3 Ablations and Other Analysis
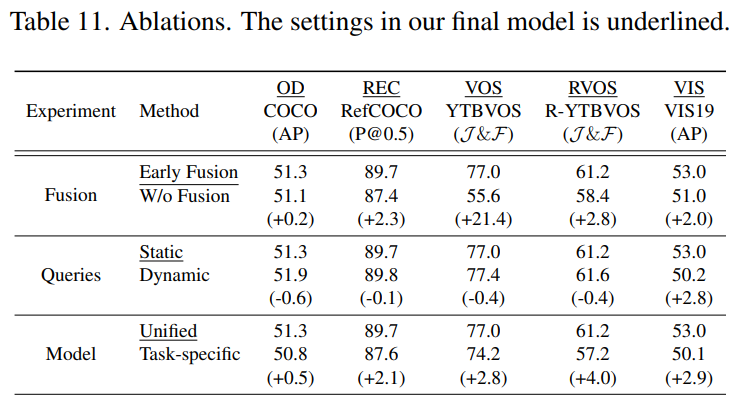
모든 모델에 ResNet-50 백본을 사용하여 다섯 가지 벤치마크 (COCO, RefCOCO, Youtube-VOS, Ref-Youtube-VOS 및 Youtube-VIS 2019) 에 대해 평가를 진행한다.
Fusion
visual features 와 prompt embedding 사이의 fusion 에 대한 영향력을 연구하기 위해, early fusion 없이 구현을 해보았다.
실험 결과 Early fusion 없으면 성능 저하가 일어났는데 다음 주요 세 가지 이유가 있다.
- prompt embedding 의 지도가 없는 네트워크는 나무나 싱크대 같은 희귀한 타깃을 찾기가 힘들다.
- early fusion 없는 네트워크는 첫 번째 프레임에서 fine mask annotation 을 완전히 활용할 수 없어 mask 품질이 저하된다. 또한 feature fusion 을 제거하니 성능 저하가 일어났다.
- feature fusion 은 object detection 및 VIS 에 최소한의 영향을 미치는데, prompt 에서 참조하는 특정 타깃 하나를 찾는 것이 아니라 가능한 모든 object 를 찾는 것을 목표로 하기 때문으로 이해할 수 있다.
Queries
본 저자는 두 가지의 query generation 전략을 비교한다.
static queries
nn.Embedding(N, d)로 간단히 구현 가능- VIS task 에서 2.8 AP 로 dynamic queries 전략보다 더 좋은 성능을 냄
- 잠재적인 이유는 N 개의 다른 object queries 가 단순히 N 번의 query 로 pool 된 prompt 를 복사하는 것보다 서로 다른 타깃간의 풍부한 관계로 인코딩할 수 있기 때문
dynamic queries
- prompt embedding 에 의존
- 처음의 4 가지 tasks 에 대해선 static queries 보다 성능이 약간 좋았다.
Unification
모든 tasks (10 tasks) 를 통합한 모델과 5 가지 tasks 를 통합한 mutliple tasks 모델을 비교하였다.
통합 모델은 5 tasks-specific 모델보다 성능이 약간 더 좋았다.
최종적으로는 통합 모델이 많은 파라미터를 아끼고, 파라미터에 더 효율적이었다.
5. Conclusions
- UNINEXT 는 prompt-guided 객체 발견과 검색 파라다임으로 10 가지 instance perception tasks 를 통합했다.
- UNINEXT 는 동일한 모델 파라미터로 단일 모델 만으로 20 가지의 벤치마크에서 우수한 성능에 도달했다.
