논문 및 이미지 출처 : https://arxiv.org/pdf/2204.03649.pdf

Abstract
CLIP 같은 모델이 visual 과 langauge 간의 Contrastive learning 을 통해 훌륭한 tranasfer learning 을 보이고, 추론 과정에 proper prompt (text description) 형태가 필요해졌다.
후속으로, 힘든 prompt engineering 을 피하기 위해 CoOp, CLIP-Adapter 및 Tip-Adapter 같은 연구들은 downstream image recognition task 에 few-shot, zer-shot learning 으로 잘 일반화시키기 위해서 vision-language model (VLM)을 채택하였다.
본 논문은 다른 시나리오에 대해 탐구한다. target 데이터를 제공하지 않는, CLIP-like VLM 의 transfer 성능을 향상하는 동시에 prompt engineering 을 피하는 approach 인 Unsupervised Prompt Learning (UPL) 을 제안한다.
unsupervised learning 을 prompt learning 에 도입한 것은 이 논문이 처음이며, 실험적으로도 UPL 은 CLIP 과 prompt engineering 측면에서 ImageNet 이나 다른 데이터셋에서 좋은 성능을 보였다.
향상된 버전의 UPL 은 8-shot CoOp 이나 8-shot TIP-Adapter 와 경쟁력 있었다.
코드는 https://github.com/tonyhuang2022/UPL 에서 확인하자.
Introduction
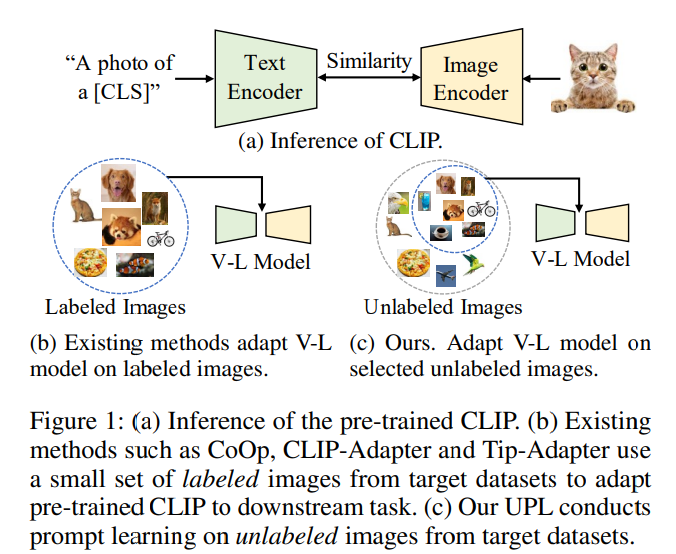
최근, CLIP 및 FLIP 은 기존 visual framework 와 달리, 대규모의 image-text pair 데이터를 두 개의 아키텍처 image encoder 와 text encoder 를 공유된 임베딩 공간에서 align 하도록 훈련한다.
downstream task 에 최적화하도록 transfer 하기 위해, 알맞은 텍스트 설명인 prompt 가 필요한데, Figure 1a 처럼 CLIP 에서는 "a photo of a [CLS]" 형태의 prompt 템플릿을 사용했다. 하지만 proper prompt 를 식별하는 것은 쉽지 않아, domain knowledge 와 힘든 prompt engineering 이 필요하다.
hand-crafted prompt 를 피하고 transfer 성능을 올리기 위해, supervised 방법으로는 CoOp, CLIP-Adapter 및 Tip-Adapter 가 있으며 downstream image recognition task 를 위해 LLM 을 사용하여 target dataset 의 적은 셋을 사용한다 (Figure 1b).
- CoOp 은 hand-crafted prompt 를 continuous prompt representation 으로 교체
- CLIP-Adapter 는 정제된 feature 를 학습하기 위해 추가적인 네트워크 사용
- TIP-Adatper 는 few-shot supervision 으로 query-key cache 모델을 구성하여 CLIP-Adapter 확장
위 방법들은 annotated sample 이 필요하므로 모델 확장에 한계가 있다.
저자는 다른 설정을 탐구하며, 이는 target dataset 을 제공하지 않고 UPL 로, downstream image recognition task 에 대한 VLM 을 효과적으로 사용하면서도 prompt engineering 을 피하는 것이다 (Figure 1c).
UPL 은 CLIP 을 활용하여 target image 에 대한 pseudo label 을 생성하고, 샘플된 pseudo label 에서 learnable prompt representation 을 최적화하는 것으로 self-training 과정을 수행한다.
그리고 hand-crafted prompt 를 최적화된 prompt representation 으로 바꾸는 것으로 CLIP 의 성능을 향상시킬 수 있다.
threshold 기반 self-training 과 대조적으로, 저자는 다음의 관찰된 사항들에 따른 self-training 을 위해 각 class 에서 샘플링된 것을 top- 로 택한다.
- VLM 은 서로 다른 클래스에 편향된 성능을 가지며, 불확실한 샘플링을 걸러내기 위해 threshold 를 사용하는 것은 불균형한 pseudo label 데이터 분포를 초래함
- confidence score 와 pseudo label 정확도 간의 상관관계가 없어, noisy pseudo label 을 동시에 도입할 수 있지만, 실험적으로 모든 클래스에 동일한 prompt representation 을 사용하기 때문에 nosity 가 robust 하다는 것을 발견함.
CLIP 에서 제안한 prompt 앙상블 전력에 영감을 받아, pseudo label 앙상블과 prompt representation 앙상블을 도입하여 저자의 방법론을 더 강화하였다.
다음 세 가지 contribution 으로 요약할 수 있다.
- prompt engineering 을 피하고 VLM 활용을 위해 UPL 을 제안하며, VLM 에 unsupervised learning 을 prompt learning 에 도입한 첫 연구
- pseudo-labeling 에 대한 CLIP 의 특성을 분석하여, top- 전략을 사용하며, transfer 성능 향상을 위해 prompt representation 앙상블을 시도
- 10 가지 image classification task 데이터셋에서 CLIP 의 promnpt engineering 보다 성능이 좋으며, 8-shot CoOp 및 8-shot TIP-Adapter 보다 대부분의 데이터셋에서 성능이 우수했음
Related Work
Vision-language Models
VLM 은 대규모의 iamge-text 쌍을 학습하여 visual representation learning 에 대한 큰 잠재력을 입증했다.
- CLIP : 4 억개 데이터셋 수집
- ALIGN : 18억개 noisy image-text 쌍 이용
- FLIP : vision-language pretraining 의 fine-grained 를 위해 3 억개의 수집
- Wukong : 서로 다른 multi-modal pre-training 의 벤치마킹에 대한 1 억개 데이터 포함
- Florence : FLD-900M 라는 9 억개의 image-text 쌍 데이터셋 포함
위 VLM 은 vision encoder, text encoder 두 아키텍처로 다음을 활용
- vision encoder : ResNet, ViT 또는 Swin Transformer
- text encoder : Standard Transformers
image 와 text 를 embedding space 에서 align 하기 위해 contrastive learning 을 채택함.
representation framework CLIP 은 object detection, semantic segmentation, action recognition, video caption 및 3D recogmnition 등에 채택되어 왔다.
Prompt Learning
Pretrained VLM class embedding 생성을 위해 prompt (예; "a photo of a [CLS]") 를 사용한다.
proper prompt 식별 및 prompt engineering 이 힘드므로 NLP 의 prompt learning 에 영감을 받아,
- CoOp : continuous prompt optimization 전략을 제안하여 prompt design 을 피한다.
- CLIP-Adapter : 추가적인 adapter network 를 사용하여 text feature 와 image feature 를 새로운 embedding 공간에서 매핑하여, 더 좋은 target dataset 을 채택하게 된다.
- Tip-Adapter : key-query cache 모델의 weight 를 만들어 CLIP-Adapter 를 확장한다.
하지만 위 방법들은 few-shot labeled data 에 의존하며, 모델 용량을 스케일링하는데 한계가 있는 반면, UPL 은 VLM 의 trnasfer 성능을 향상시키면서도 annotation target dataset 을 필요로 하지 않는다.
Self-training
Self-training 은 간단한 semi-supervised learning 접근법이다.
잘 학습된 모델로 unlabaled dataset 에서 pseudo label 을 생성한 후 labeled data 와 pseudo-labeld data 를 사용하여 finetuning 한다.
최근, self-training 은 image classification, object detection, semantic segmentation, speech recognition, action recognition 및 machine traslation 분야의 딥러닝에 큰 진보를 보여주고 있다.
VLM 은보통 대규모 image-text 쌍에 pretraining 하며 prompting 으로 좋은 성능을 보여준다.
저자는 UPL 을 제안하여 target dataset 에 대한 pseudo label 을 생성하며 self-training 으로 continuous prompt representation 를 최적화한다.
기존의 self-training 은 네트워크의 모든 layer 를 finetuning 하는 반면, UPL 은 네트워크를 고정하여 유지하면서도 (image, text encoder) continuous prompt representation 을 최적화 한다.
Method
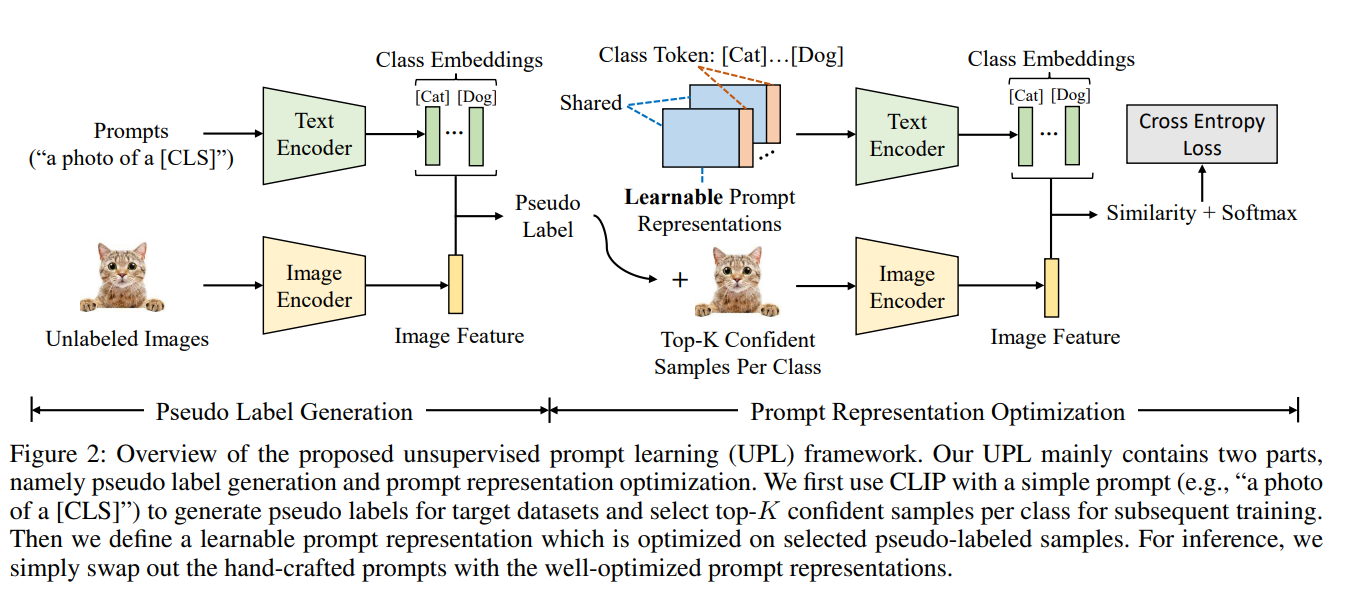
UPL 을 도입하며 transfer 성능을 향상시키며 prompt engineering 을 피한다.
기존 supervised 방법과 달리, target dataset 의 annotation 을 필요하지 않는다.
- UPL 의 overview
- target image 에 대한 pseudo label 생성
- self-training 을 통해 prompt representation 최적화
Overview of UPL
Figure 2 에서 전체 개요를 보여 준다.
UPL 은 pseudo label generation 과 prompt representation optimization 두 모듈을 포함한다.
- pretrained VLM (예; CLIP) 을 활용하여 target dataset 에서 unlabeled image 의 pseudo label 을 생성한다.
이는 다음의 두 가지 관찰을 기반으로 한다.
- pseudo label 정확도와 confidence score 간의 상관관계가 낮음
- VLM 은 각각의 클래스에 편향된 정확도를 가지므로, 각 클래스에 확실한 샘플링을 위해 top- 를 택한다. 이는 threshold 보다 confidence score 가 더 높다.
- CoOp 에서 영감을 얻어 learnable prompt representation 를 정의
prompt representation 은 모든 카테고리에 교차로 공유되며 생성된 pseudo-label 와 선택된 unlabeled sample 을 최적화한다.
- 추론 단계에서, hand-crafted prompt 를 최적화된 prompt representation 으로 교체하여 CLIP 의 inference pipeline 을 따름
Pseudo Label Generation
Inference of CLIP
저자는 CLIP 의 inference 에 대해 다시 다루었으며, class 를 포함한 target dataset 이 주어지면, CLIP 은 "a photo of a [CLS]" 와 같은 prompt 를 소문자의 byte pair encoding (BPE) representation 으로 변환한다. 여기서 각 카테고리에 대한 class embedding 을 생성시키기 위해 CLIP 의 text encoder 를 지난다.
저자는 클래스 임베딩의 집합을 로 표기하며, 여기서 는 -th 카테고리의 클래스 임베딩을 나타낸다.
이미지 의 경우, CLIP 의 image encoder 로 추출한 visual feature 를 로 표기한다.
클래스 가 될 확률은 다음과 같이 계산한다.
여기서 는 CLIP 에서 학습된 temperature parameter 이며, 은 cosine similarity 이다.
이제 prediction 를 쉽게 구할 수 있다.
Pseudo Label Generation
pretrained CLIP 으로 식 1, 식 2 를 사용하여 target dataset 으로부터 unlabeled sample 에 대한 pseudo 를 생성할 수 있다.
Self-training 과 semi-supervised learning 은 threshold 보다 score 가 높은 confident sample 을 유지하지만, 이를 CLIP 에 바로 적용시키기 힘들다.
이는 두 가지 이유가 있다.
-
CLIP 은 downstream image recognition task 에 transfer 할 때 서로 다른 클래스에 대한 편향된 성능을 보인다. 이는 pretraining dataset 과 target dataset 간의 domain 차이 때문이다. 이 현상은 Figure 3 에서 확인할 수 있다.
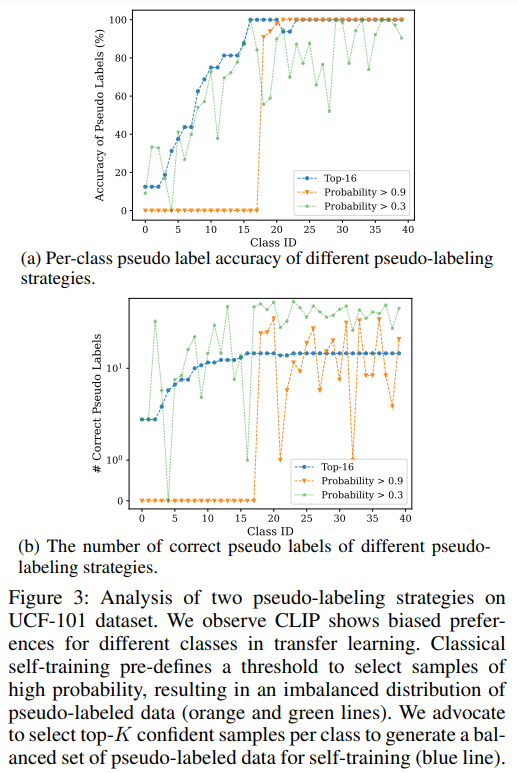
pseudo-labaled data 의 임밸런스 분포에서 unconfident sample 을 필터링하기 위해 고정된 threshold 를 사용하면 최적화가 저해된다. -
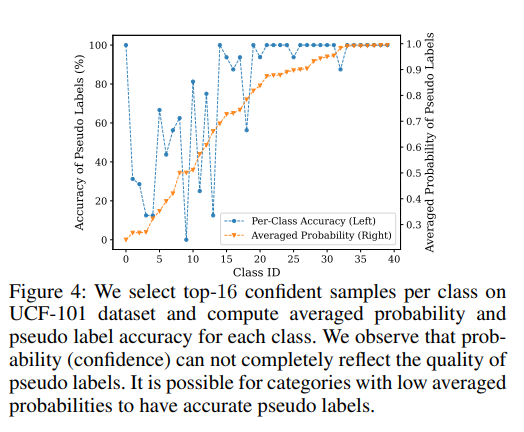
Self-training 은 condidence (probability) 가 pseudo label 의 퀄리티를 잘 반영할 것으로 예상한다. 따라서 threshold (예; 0.9) 는 하이 퀄리티 샘플을 선택하기 위해 사용될 수 있지만, CLIP 에서 confidence score 와 pseudo label 정확도 간의 상관관계가 비교적 약하다는 것을 관찰하였으며 이는 Figure 4 에서 확인할 수 있다.
그러므로 저자는 최적화를 위해 식 1, 2 를 사용하여 confident sample 을 top- 선택을 지지한다.
이는 대규모의 샘플들이 훈련 중 overwhelm 되는 것을 예방한다. 이는 대규모의 샘플들이 훈련 중에 overwhelm 되는 것을 예방하며, 저자는 으로 설정한다.
Pseudo Label Ensemble
CLIP 은 다음의 visual model 을 포함한다.
- ResNet-50, ResNet-101, ResNet50x4, ResNet-50x16, ResNet-50x64
- ViT-B/32, ViT-B/16, ViT-L/14
저자는 CLIP 의 여러 아키텍처가 Figure 5 처럼 클래스에 편향된 정확도를 가지는 것을 관찰했다.
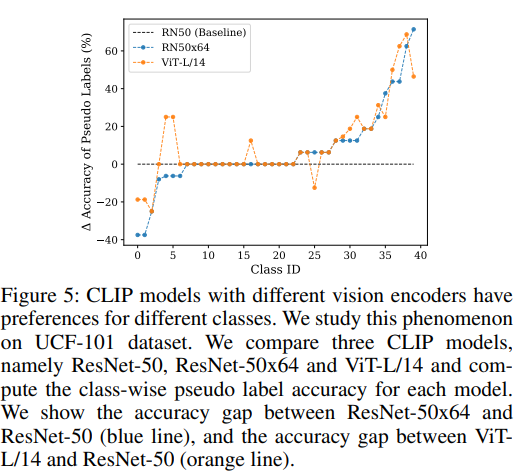
이 결과를 바탕으로, pseudo label 의 퀄리티를 향상시키기 위해 간단한 pseudo label ensemble 전략을 제안한다.
특히, 다양한 아키텍처의 CLIP model 이 주어지면, 식 1 을 활용하여 -th CLIP model 로 예측된 확률을 얻는다.
그리고 간단하게 으로 평균화하여 확률을 얻을 수 있다.
그 후, 향상된 pseudo label 을 생성하기 위해 에 식 2 를 적용한다.
위 과정이 끝나면, unsupervised prompt representation 최적화를 위해 pseudo-labeled data 를 사용한다.
Prompt Representation Optimization
기존의 CLIP 에선 transfer learning 을 위해 "a photo of a [CLS]" 처럼 다양한 prompt 템플릿을 정의했는데, proper prompt 를 식별하는 것은 domain knowledge 와 prompt engineering 이 요구되어 힘든 작업이다.
그리고 prompt 에 약간의 변화만 있어도 성능이 크게 변한다.
CoOp 은 hand-crafted prompt 를 피하기 위해 적은 labeled data 에서 continuous prompt representation 를 최적화하였다.
UPL 은 CoOp 과 비슷하지만, target dataset 에서 어떠한 annotation 도 요구하지 않는다.
Learnable Prompt Representation
목표는 CLIP 의 transfer 성능 향상을 위해 pseudo-labeled data 에 prompt representation 을 학습하는 것이다.
learnable prompt representation 을 로 표기하며, 는 word embedding 의 차원 (CLIP 의 경우 512), 은 hypter-parameter 를 표기하는 것으로 default 는 16 이다.
classes 를 포함하는 target dataset 이 주어지면, class () 에 대한 continuous prompt 를 정의한다.
는 class 의 fixed word embedding 이다.
identical prompt representation 는 모든 클래스에 공유된다.
훈련 과정은 Figure 2 (right part) 에서 보여준다.
각각의 pseudo labeled image 의 경우, 저자는 image 을 CLIP 의 vision encoder 를 지나 visual feature 를 추출한다.
는 CLIP 의 text encoder 을 지나 class embedding 을 얻는다.
-th class 의 확률은 다음과 같이 계산할 수 있다.
여기서 는 temperature parameter 이다.
training image 의 경우, 식 4 를 이용하여 모든 클래스의 확률을 계산하고 pseudo label 로 cross-entropy loss 를 최소화한다.
gradient 는 text encoder 을 통해 back-propagate 하여 text encoder 의 풍부한 knowledge 를 이용한다.
마지막으로, learnable prompt representation 를 업데이트 한다.
여기서 image encoder 와 text encoder 는 훈련 중에는 weight 가 변하지 않는다는 것을 알야야 한다.
Inference
prompt representation 의 최적화가 끝나고, target dataset 이 주어지면, 를 CLIP 의 text encoder 를 지나 모든 클래스에 대한 class embedding 을 얻는다.
test image 의 경우, 이미지를 CLIP 의 image encoder 를 지나 visual feature 를 추출하고 식 4를 적용하여 image recongnition 을 위한 확률값을 계산한다.
Prompt Representation Ensemble
기존 CLIP 은 transfer 성능 향상을 위해 다양한 prompt 를 정의하였으며, 이는 저자의 approach 에서 다양한 초기화로 multi prompt representation 학습에 영감을 주었다.
정확히는, 개의 random 하게 초기화된 prompt representation 을 각각 독립적으로 최적화한다.
inference 단계에서, 모든 prompt representation 의 예측 확률 값을 계산하고 평균화하여 최종 예측 확률값을 만든다.
Experiment
Implementation Details
Vision-language Models
ResNet-50 이 있는 CLIP 을 베이스라인으로 UPL 에 적용한다. 결과는 Figure 5 에서 볼 수 있다.
CLIP 의 여러 vision encoder 는 다양한 카테고리에 대한 성능을 가지고 있어, pseudo label 의 퀄리티를 향상시키기 위해 저자는 ResNet-101, ResNet50x4, ResNet50x16, ResNet50x64, ViT-B/32, ViT-B/16 및 ViT-L/14 를 포함하는 다양한 vision 아키텍처의 추가적인 CLIP 모델을 사용한 UPL* 이라는 향상된 버전을 정의했다.
Pseudo label 에만 다양한 비전 아키텍처를 사용했기 때문에 UPL* 은 여전히 UPL 과 같은 아키텍처 (CLIP with ResNet-50)을 사용한다.
Pseudo Label Generation
CLIP 에선 ImageNet 에 대해 80 개의 hand-crafted prompt 로 inference 를 설계한다.
CLIP 으로 pseudo label 생성된 모든 prompt 를 수반하면 prompt engineering 을 피하는 것이 불리해진다. 따라서, 가장 간단한 prompt 를 사용하여 pseudo label 을 생성한다.
예로, ImageNet 에선 "a photo of a [CLS]" prompt 를 사용한다. 그리고 클래스 당 top-16 confident sample 을 하여 prompt representation 을 최적화한다.
Learnable Prompt Representation
prompt representation 은 zero-mean 가우시안분포와 0.02 표준 편차로 무작위 초기화한다.
식 3 에서 length 을 설정한다. 그리고 16 개 prompt representation 을 앙상블한다.
Training Details
- SGD
- lr 0.002
- cosine decay learning rate schedular
- 50 epoch
- 32 batch size
- warm up in the first epoch with lr 1e-5
Dataset
11 개의 image classification dataset
- ImageNet
- Caltech101
- DTD
- EuroSAT
- FGVCAircraft
- Food101
- Flowers102
- OxfordPets
- SUN397
- StandfordCars
- UCF101
Main Results
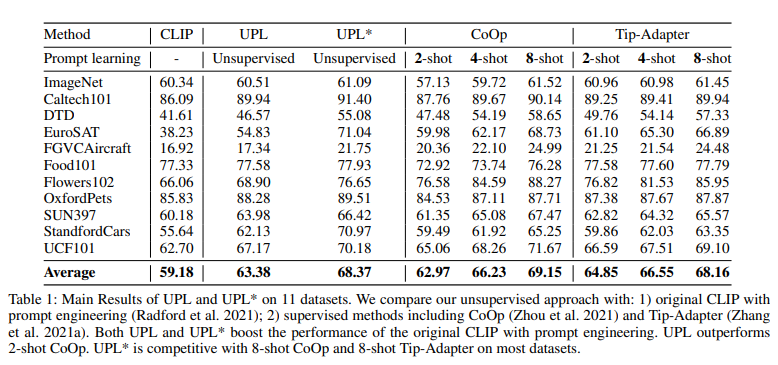
11 데이터셋에 대한 결과는 위 테이블 1 에서 확인할 수 있다.
저자의 approach 와 다른 모델들을 비교한다.
- 기존 CLIP 의 prompt engineering
- supervised method (CoOp, Tip-Adapter)
UPL 은 prompt engineering 을 피할 뿐만 아니라 CLIP 보다 4.2 point 성능이 더 좋았다.
ResNet-50 의 single CLIP 을 사용하면서 pseudo-labeling 에서 여러 CLIP 모델을 사용하여 정확도를 68.37 로 boost 하였다.
또한 8-shot 의 CoOp 이나 Tip-Adapter 와 경쟁력있는 성능을 보인다.
Conclusion
- 처음으로 unsupervised prompt learning UPL 을 도입하여 prompt engineering 을 피하며 CLIP 의 transfer 성능을 끌어올린다.
- CoOp, CLIP-adapter 및 TIP-Adapter 같은 supervised approach 보다 좋은 성능을 가진다.
