NumPy란?
파이썬의 과학 컴퓨팅을 위한 기본 패키지로서, 다차원 배열 객체, 다양한 파생 객체를 제공하는 라이브러리
복잡한 수학, 음파 및 이미지 처리, 선별 선택, I/O, 기본 통계 작업, 무작위 시뮬레이션 등을 포함하여 배열에 대한 빠른 작업을 위한 다양한 루틴을 제공해준다.
핵심은 ndarray 객체로, 동질데이터 형식의 n 차원 배열이 캡슐화되어, 성능을 위한 컴파일된 코드로 많은 작업을 수행한다.
설치
pop install numpyNumPy 퀵스타트
구성요소
앞으로의 예제를 작업하려면 NumPy 외에 matplotlib 로 설치해야 한다.
matplotlib 는 그래프 영역을 만들고, 몇 개의 선을 표현하고, 레이블로 꾸미는 등의 일을 할 수 있다.
pip install matplotlib기본
NumPy 의 주요 객체는 다차원 배열로, 음이 아닌 정수의 튜블에 의한 인덱싱된 모두 같은 유형의 요소 테이블이다. NumPy 에서 차원을 축(axes)이라 한다.
3D 공간에 한 점의 좌표 [1, 2 ,1] 에 한 축이 있다.
이 축엔 3개의 요소가 있으니 길이가 3이라 하자.
아래와 같이 예로 배열에 2개의 축이 있다. 첫 번째 축의 길이는 2고 두 번째는 3이다.
[[1., 0., 0.],
[0., 1., 2.]]NumPy 의 배열 클래스인 ndarray 는 array 라는 별칭으로도 알려져 있지만 표준 파이썬 라이브러리 클래스인 array.array 와는 동일하지 않다.
| 주요 속성 | 기능 |
|---|---|
| ndarray.ndim | 배열의 축 수 |
| ndarray.shaep | 배월의 차원. 각 차원에서 배열 크기를 나타내는 정수의 튜플 n 로우와 m 컬럼에 대한 shape 는 (n, m) 이다.shape 튜플의 길이는 축의 수, ndim이다. |
| ndarray.size | 배열 요소의 총 수. |
| ndarray.dtype | 배열의 요소 유형을 설명하는 개체 파이썬 유형으로 dtype을 만들거나 지정할 수 있다. |
| ndarray.itemsize | 배열의 각 요소의 크기(바이트) |
| ndarray.data | 배열의 실제 요소를 포함하는 버퍼 인덱싱 기능을 사용하여 배열 요소에 액세스하여 이 속성을 사용할 필요가 없다. |
>>> import numpy as np
>>> a = np.arange(15).reshape(3, 5)
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> a.shape
(3, 5)
>>> a.ndim
2
>>> a.dtype.name
'int32'
>>> a.itemsize
4
>>> a.size
15
>>> type(a)
<class 'numpy.ndarray'>
>>> b = np.array([6, 7, 8])
>>> b
array([6, 7, 8])
>>> type(b)
<class 'numpy.ndarray'>배열 생성
배열 만드는 데는 여러 방법이 있다.
예로 array 함수로 일반 파이썬 리스트 또는 튜플로 배열을 만들 수 있다.
>>> import numpy as np
>>> a = np.array([2, 3, 4])
>>> a
array([2, 3, 4])
>>> a.dtype
dtype('int32')
>>> b = np.array([1.2, 3.5, 5.1])
>>> b.dtype
dtype('float64')
빈번히 일어나는 오류는 array 단일 시퀀스를 인수로 제공하는 대신 여러 인수를 사용하는 것이다.
>>> a = np.array(1, 2, 3, 4)
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: array() takes from 1 to 2 positional arguments but 4 were givenarray 시퀀스의 시퀀스를 2차원 배열로, 시퀀스의 시퀀스의 시퀀스를 3차원 배열 등으로 변환한다.
>>> b = np.array([(1.5, 2, 3), (4, 5, 6)])
>>> b
array([[1.5, 2. , 3. ],
[4. , 5. , 6. ]])배열 유형을 명시적으로 지정할 수도 있다.
>>> c = np.array([[1, 2], [3, 4]], dtype=complex)
>>> c
array([[1.+0.j, 2.+0.j],
[3.+0.j, 4.+0.j]])함수 zeros 는 0으로 가득, ones 는 1로 가득, empty 는 메모리 상태에 따라 무작위의 배열을 만들 수 있다. 기본적으로 dtype은 float64지만, 키워드 인수로 지정할 수도 있다.
>>> np.zeros((3, 4))
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
>>> np.ones((2, 3, 4), dtype=np.int16)
array([[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]]], dtype=int16)
>>> np.empty((2, 3))
array([[3.73603959e-262, 6.02658058e-154, 6.55490914e-260],
[5.30498948e-313, 3.14673309e-307, 1.00000000e+000]])숫자 시퀀스를 생성하기 위해 arange 함수도 제공한다.
배열을 반환한다.
>>> np.arange(10, 30, 5)
array([10, 15, 20, 25])
>>> np.arange(0, 2, 0.3)
array([0. , 0.3, 0.6, 0.9, 1.2, 1.5, 1.8])arange 는 부동 소수점의 정밀도를 정확히 예측하는 것이 가능하지 않아 이 때는 linspace 를 사용하는 것이 좋다.
>>> x = np.linspace(0, 2 * pi, 100)
>>> f = np.sin(x)배열 출력
배열 출력에 중첩 리스트와 유사한 방식으로 배열을 표시하지만 레이아웃은 다음과같다.
- 마지막 축은 왼쪽에서 오른쪽로 출력
- 마지막에서 두 번째는 위에서 아래로 출력
- 나머지 부분도 위에러 아래로 출력되며 각 슬라이스는 빈 줄로 다음 슬라이스와 구분
>>> a = np.arange(6) # 1d array
>>> print(a)
[0 1 2 3 4 5]
>>>
>>> b = np.arange(12).reshape(4, 3) # 2d array
>>> print(b)
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
>>>
>>> c = np.arange(24).reshape(2, 3, 4) # 3d array
>>> print(c)
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]배열이 매우 큰 상태라면 중앙 부분을 건너뛴다.
>>> print(np.arange(10000))
[ 0 1 2 ... 9997 9998 9999]
>>>
>>> print(np.arange(10000).reshape(100, 100))
[[ 0 1 2 ... 97 98 99]
[ 100 101 102 ... 197 198 199]
[ 200 201 202 ... 297 298 299]
...
[9700 9701 9702 ... 9797 9798 9799]
[9800 9801 9802 ... 9897 9898 9899]
[9900 9901 9902 ... 9997 9998 9999]]해당 동작을 비활성화하고 싶다면 다음과 같이 옵션을 변경한다.
>>> np.set_printoptions(threshold=sys.maxsize)기본 조작
배열의 산술 연산는 요소별로 적용된다.
>>> a = np.array([20, 30, 40, 50])
>>> b = np.arange(4)
>>> b
array([0, 1, 2, 3])
>>> c = a - b
>>> c
array([20, 29, 38, 47])
>>> b**2
array([0, 1, 4, 9])
>>> 10 * np.sin(a)
array([ 9.12945251, -9.88031624, 7.4511316 , -2.62374854])
>>> a < 35
array([ True, True, False, False])곱 연산자 * 는 NumPy 배열에서 요소별로 작동하며 행렬 곱은 @ 연산자 또는 dot 함수 또는 메소드를 사용하여 수행할 수 있다.
>>> A = np.array([[1, 1],
... [0, 1]])
>>> B = np.array([[2, 0],
... [3, 4]])
>>> A * B # elementwise product
array([[2, 0],
[0, 4]])
>>> A @ B # matrix product
array([[5, 4],
[3, 4]])
>>> A.dot(B) # another matrix product
array([[5, 4],
[3, 4]])+= 및 *= 등은 새 배열을 생성하는 대신 기존 배열을 수정하는 역할이다.
>>> rg = np.random.default_rng(1) # 랜덤값 생성
>>> a = np.ones((2, 3), dtype=int)
>>> b = rg.random((2, 3))
>>> a *= 3
>>> a
array([[3, 3, 3],
[3, 3, 3]])
>>> b += a
>>> b
array([[3.51182162, 3.9504637 , 3.14415961],
[3.94864945, 3.31183145, 3.42332645]])
>>> a += b # b 는 자동적으로 정수로 변환 안됨
Traceback (most recent call last):
...
numpy.core._exceptions._UFuncOutputCastingError: Cannot cast ufunc 'add' output from dtype('float64') to dtype('int64') with casting rule 'same_kind'다른 유형의 배열로 작업 시 더 일반적이거나 정확한 배열이어야 한다.
>>> a = np.ones(3, dtype=np.int32)
>>> b = np.linspace(0, pi, 3)
>>> b.dtype.name
'float64'
>>> c = a + b
>>> c
array([1. , 2.57079633, 4.14159265])
>>> c.dtype.name
'float64'
>>> d = np.exp(c * 1j)
>>> d
array([ 0.54030231+0.84147098j, -0.84147098+0.54030231j,
-0.54030231-0.84147098j])
>>> d.dtype.name
'complex128'배열에 있는 모든 요소의 합을 계산하는 등의 많은 단항 연산은 ndarray 클래스의 메소드로 구현된다.
>>> a = rg.random((2, 3))
>>> a
array([[0.82770259, 0.40919914, 0.54959369],
[0.02755911, 0.75351311, 0.53814331]])
>>> a.sum()
3.1057109529998157
>>> a.min()
0.027559113243068367
>>> a.max()
0.8277025938204418이런 작업들은 배열 전체에 적용된다. axis 매개변수를 지정하면 배열의 지정된 측정으로 작업을 적용할 수 있다.
>>> b = np.arange(12).reshape(3, 4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> b.sum(axis=0) # 각 컬럼의 합
array([12, 15, 18, 21])
>>>
>>> b.min(axis=1) # 각 로우의 최소값
array([0, 4, 8])
>>>
>>> b.cumsum(axis=1) # 각 행에 따른 누적 값
array([[ 0, 1, 3, 6],
[ 4, 9, 15, 22],
[ 8, 17, 27, 38]])범용 함수
NumPy 는 sin, cos, exp 같은 수학 함수도 제공한다. 이를 범용 함수(ufunc)이라 한다.
>>> B = np.arange(3)
>>> B
array([0, 1, 2])
>>> np.exp(B)
array([1. , 2.71828183, 7.3890561 ])
>>> np.sqrt(B)
array([0. , 1. , 1.41421356])
>>> C = np.array([2., -1., 4.])
>>> np.add(B, C)
array([2., 0., 6.])인덱싱, 슬라이싱 및 반복
1차원 배열은 목록 및 기타 Python 시퀀스와 마찬가지로 인덱싱, 슬라이스 및 반복될 수 있다.
>>> a = np.arange(10)**3
>>> a
array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729])
>>> a[2]
8
>>> a[2:5]
array([ 8, 27, 64])
>>> # a[0:6:2] = 1000 와 동일
>>> # 처음부터 위치 6까지의 두 번재 요소 모두 1,000으로 세팅
>>> a[:6:2] = 1000
>>> a
array([1000, 1, 1000, 27, 1000, 125, 216, 343, 512, 729])
>>> a[::-1] # a 의 반전
array([ 729, 512, 343, 216, 125, 1000, 27, 1000, 1, 1000])
>>> for i in a:
... print(i**(1 / 3.))
...
9.999999999999998
1.0
9.999999999999998
3.0
9.999999999999998
4.999999999999999
5.999999999999999
6.999999999999999
7.999999999999999
8.999999999999998다차원 배열은 축당 하나의 인덱스를 가지며, 이런 인덱스는 쉼표로 구분된 튜플에 제공된다.
>>> def f(x, y):
... return 10 * x + y
...
>>> b = np.fromfunction(f, (5, 4), dtype=int)
>>> b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
>>> b[2, 3]
23
>>> b[0:5, 1] # b의 두번째 컬럼의 각 로우
array([ 1, 11, 21, 31, 41])
>>> b[:, 1] # 이전 예와 동일
array([ 1, 11, 21, 31, 41])
>>> b[1:3, :] # b의 두, 세 번째 각 컬럼
array([[10, 11, 12, 13],
[20, 21, 22, 23]])축 수보다 적은 인덱스가 제공되면 누락된 인덱스는 완전한 슬라이스로 간주
>>> b[-1] # 마지막 로우. b[-1, :] 와 동일
array([40, 41, 42, 43])대괄호 안의 표현식은 나머지 축을 나타내는 데 필요한 만큼 인스턴스가 뒤에 오는 것으로 b[i] 로 처리된다.
NumPy 는 또한 dots 연산자 처럼 b[i, ...] 으로 사용하는 것을 허락한다.
dots(...) 연산자는 색인 튜플을 생산하기 위헤 필요한 만큼 콜론을 나타낸다.
예로 5개의 축이 있는 배열 x 의 경우
x[1, 2, ...]는x[1, 2, :, :, :]x[..., 3]는x[:, :, :, :, 3]x[4, ..., 5, :]는[4, :, :, 5, :]
>>> c = np.array([[[ 0, 1, 2], # 3d 배열
... [ 10, 12, 13]],
... [[100, 101, 102],
... [110, 112, 113]]])
>>> c.shape
(2, 2, 3)
>>> c[1, ...] # c[1, :, :] 또는 c[1] 와 같음
array([[100, 101, 102],
[110, 112, 113]])
>>> c[..., 2] # c[:, :, 2] 와 같음
array([[ 2, 13],
[102, 113]])다차원 배열에 대한 반복은 첫 번재 축을 기준으로 실행된다.
>>> for row in b:
... print(row)
...
[0 1 2 3]
[10 11 12 13]
[20 21 22 23]
[30 31 32 33]
[40 41 42 43]하지만, 배열의 각 요소에 대한 작업을 하나씩만 원한다면, 배열의 모든 요소에 대한 반복자인 flat 요소를 사용하면 된다.
>>> for element in b.flat:
... print(element)
...
0
1
2
3
10
11
12
13
20
21
22
23
30
31
32
33
40
41
42
43모양 조작
배열의 모양 변경
배열은 각 축에 따른 요소의 수로 지정된 모양을 갖는다.
>>> a = np.floor(10 * rg.random((3, 4)))
>>> a
array([[3., 7., 3., 4.],
[1., 4., 2., 2.],
[7., 2., 4., 9.]])
>>> a.shape
(3, 4)배열의 모양은 다양한 명령으로 변경할 수 있는데, 다음 세 가지 명령은 수정된 모든 배열을 반환하지만 원래 배열은 변경하지 않는다.
>>> a.ravel() # 단차원의 배열을 반환
array([3., 7., 3., 4., 1., 4., 2., 2., 7., 2., 4., 9.])
>>> a.reshape(6, 2) # 수정된 모양의 배열을 반환
array([[3., 7.],
[3., 4.],
[1., 4.],
[2., 2.],
[7., 2.],
[4., 9.]])
>>> a.T # 뒤바뀐 배열을 반환
array([[3., 1., 7.],
[7., 4., 2.],
[3., 2., 4.],
[4., 2., 9.]])
>>> a.T.shape
(4, 3)
>>> a.shape
(3, 4)reshape 함수는 수정된 모양의 요소를 반환하는 반면, ndarray.resize 는 배열 자체를 수정한다.
>>> a
array([[3., 7., 3., 4.],
[1., 4., 2., 2.],
[7., 2., 4., 9.]])
>>> a.resize((2, 6))
>>> a
array([[3., 7., 3., 4., 1., 4.],
[2., 2., 7., 2., 4., 9.]])재형성 작업에서 치수가 -1 로 지정되면 다른 치수로 자동 계산된다.
>>> a.reshape(3, -1)
array([[3., 7., 3., 4.],
[1., 4., 2., 2.],
[7., 2., 4., 9.]])서로 다른 배열 함께 쌓기
여러 배열을 서로 다른 축을 따라 함께 쌓을 수 있다.
>>> a = np.floor(10 * rg.random((2, 2)))
>>> a
array([[9., 7.],
[5., 2.]])
>>> b = np.floor(10 * rg.random((2, 2)))
>>> b
array([[1., 9.],
[5., 1.]])
>>> np.vstack((a, b))
array([[9., 7.],
[5., 2.],
[1., 9.],
[5., 1.]])
>>> np.hstack((a, b))
array([[9., 7., 1., 9.],
[5., 2., 5., 1.]])column_stack 은 1D 배열을 2D 배열에 컬럼으로 쌓는다.
2D 배열의 경우에만 hstack 과 동일하다.
>>> from numpy import newaxis
>>> np.column_stack((a, b)) # 2D 배열
array([[9., 7., 1., 9.],
[5., 2., 5., 1.]])
>>> a = np.array([4., 2.])
>>> b = np.array([3., 8.])
>>> np.column_stack((a, b)) # 2D 배열 반환
array([[4., 3.],
[2., 8.]])
>>> np.hstack((a, b)) # 다른 결과
array([4., 2., 3., 8.])
>>> a[:, newaxis]
array([[4.],
[2.]])
>>> np.column_stack((a[:, newaxis], b[:, newaxis]))
array([[4., 3.],
[2., 8.]])
>>> np.hstack((a[:, newaxis], b[:, newaxis])) # the result is the same
array([[4., 3.],
[2., 8.]])반면, row_stack 함수는 vstack 의 모든 입력 배열에 동일하다.
실제로 row_stack 의 별칭이 vstack 이다.
>>> np.column_stack is np.hstack
False
>>> np.row_stack is np.vstack
True2차원 이상의 배열의 경우에 두 hstack 번째 축을 vstack 에 따라 누적되고 첫 번째 축을 따라 누적되어 concatenate 연결이 발생해야 하는 축의 번호를 제공하는 선택적 인수를 허용한다.
복잡할 경우엔 r_ 및 c_ 으로 숫자를 쌓아 배열을 만드는데 유용하다.
>>> np.r_[1:4, 0, 4]
array([1, 2, 3, 0, 4])한 배열을 여러 작은 배열로 나누기
hsplit 을 사용하면 동일한 모양의 배열을 지정하거나, 분할이 발생해야 하는 열을 지정하여 수평 축을 따라 배열을 분할할 수 있다.
>>> a = np.floor(10 * rg.random((2, 12)))
>>> a
array([[6., 7., 6., 9., 0., 5., 4., 0., 6., 8., 5., 2.],
[8., 5., 5., 7., 1., 8., 6., 7., 1., 8., 1., 0.]])
>>> # a 를 3 으로 나눔
>>> np.hsplit(a, 3)
[array([[6., 7., 6., 9.],
[8., 5., 5., 7.]]), array([[0., 5., 4., 0.],
[1., 8., 6., 7.]]), array([[6., 8., 5., 2.],
[1., 8., 1., 0.]])]
>>> # 세 번째 열과 네 번째 열 뒤에 'a'를 분할
>>> np.hsplit(a, (3, 4))
[array([[6., 7., 6.],
[8., 5., 5.]]), array([[9.],
[7.]]), array([[0., 5., 4., 0., 6., 8., 5., 2.],
[1., 8., 6., 7., 1., 8., 1., 0.]])]vsplit 세로 축을 array_split 에 따라 분할하고 분할할 축을 지정할 수 있다.
복사 그리고 뷰
배열을 조작할 때 새 배열에 복사되는 경우와 그렇지 않은 경우가 있다.
다음 세 가지 경우가 있다.
복사 금지
단순 할당은 복사본을 만들지 않는다.
>>> a = np.array([[ 0, 1, 2, 3],
... [ 4, 5, 6, 7],
... [ 8, 9, 10, 11]])
>>> b = a # 새 객체로 만들어지지 않음
>>> b is a # a 와 b는 동일함
True변경 가능한 객체를 참조하므로 함수 호출은 복사본을 만들지 않는다.
>>> def f(x):
... print(id(x))
...
>>> id(a) # id는 객체의 교유 식별자
148293216 # 서로 다를 수 있음
>>> f(a)
148293216 # 서로 다를 수 있음뷰 또는 얕은 복사
다른 배열 객체는 동일한 데이터를 공유할 수 있다.
이 view 메소드는 동일한 데이터를 보는 새 배열 객체를 만든다.
>>> c = a.view()
>>> c is a
False
>>> c.base is a # c는 a가 보유한 데이터 조회다.
True
>>> c.flags.owndata
False
>>>
>>> c = c.reshape((2, 6)) # a 의 모양은 변하지 않는다.
>>> a.shape
(3, 4)
>>> c[0, 4] = 1234 # a 의 데이터는 변한다.
>>> a
array([[ 0, 1, 2, 3],
[1234, 5, 6, 7],
[ 8, 9, 10, 11]])배열을 슬라이스하면 배열의 뷰가 전환된다.
>>> s = a[:, 1:3]
>>> s[:] = 10 # s[:] 는 s 의 뷰다. s = 10 와 s[:] = 10 는 다르다는 것을 알자.
>>> a
array([[ 0, 10, 10, 3],
[1234, 10, 10, 7],
[ 8, 10, 10, 11]])깊은 복사
이 copy 메소드는 배열과 해당 데이터의 전체 복사본을 만든다.
>>> d = a.copy()
>>> d is a
False
>>> d.base is a # a 에 대한 어떤 것도 공유하지 않는다.
False
>>> d[0, 0] = 9999
>>> a
array([[ 0, 10, 10, 3],
[1234, 10, 10, 7],
[ 8, 10, 10, 11]]때론 원래 배열이 더 이상 필요 없다면 슬라이싱 후 호출해야 한다.
a 가 큰 결과이고 최종 결과 b 는 a 의 작은 부분만 포함되어 있다 가정하자.
이 때 슬라이싱으로 b 를 구성할 때 깊은 복사가 이루어져야 한다.
>>> a = np.arange(int(1e8))
>>> b = a[:100].copy()
>>> del a # a 의 메모리는 양도될 수 있다.b = a[:100] 이 대신 사용될 수 있다면, a 는 b 에 의해 참조될 수 있고 del a 가 실행되도 메모리에 유지된다.
함수 및 메소드 개요
각종 함수에 대한 자세한 사항은 도큐먼트 에서 살펴보자.
Less Basic
브로드캐스트 규칙
브로드캐스팅을 통해 범용 함수는 정확히 같은 모양이 아닌 입력을 의미 있는 방식으로 처리할 수 있다.
규칙은 다음과 같다.
- 모든 입력 배열의 차원 수가 동일하지 않은 경우 모든 배열이 동일한 차원 수를 가질 때까지 더 작은 배열의 모양 앞에
1이 반복적으로 추가된다. - 특정 차원을 따라 크기가 1인 배열이 해당 차원을 따라 가장 큰 모양의 배열 크기를 가진 것처럼 작동한다.
자세한 것은 브로드캐스트에서 확인하자.
고급 인덱싱 및 인덱스 트릭
NumPy 는 일반 파이썬 시퀀스보다 더 많은 인덱싱 기능을 제공한다.
정수 및 슬라이스로 인덱싱하는 것 외에도 이전에 봤듯 배열은 정수 배열 및 부울 배열로 인덱싱할 수 있다.
인덱스 배열을 사용한 인덱싱
>>> a = np.arange(12)**2
>>> i = np.array([1, 1, 3, 8, 5])
>>> a[i]
array([ 1, 1, 9, 64, 25])
>>>
>>> j = np.array([[3, 4], [9, 7]])
>>> a[j]
array([[ 9, 16],
[81, 49]])인덱싱된 배열 a 가 다차원이면 단일 인덱스 배열은 첫 번째 차원을 참조한다.
>>> palette = np.array([[0, 0, 0], # black
... [255, 0, 0], # red
... [0, 255, 0], # green
... [0, 0, 255], # blue
... [255, 255, 255]]) # white
>>> image = np.array([[0, 1, 2, 0],
... [0, 3, 4, 0]])
>>> palette[image]
array([[[ 0, 0, 0],
[255, 0, 0],
[ 0, 255, 0],
[ 0, 0, 0]],
[[ 0, 0, 0],
[ 0, 0, 255],
[255, 255, 255],
[ 0, 0, 0]]])하나 이상의 차원에 대한 인덱스를 제공할 수도 있다.
각 차원의 인덱스 배열은 모양이 같아야 한다.
>>> a = np.arange(12).reshape(3, 4)
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> i = np.array([[0, 1],
... [1, 2]])
>>> j = np.array([[2, 1],
... [3, 3]])
>>>
>>> a[i, j]
array([[ 2, 5],
[ 7, 11]])
>>>
>>> a[i, 2]
array([[ 2, 6],
[ 6, 10]])
>>>
>>> a[:, j]
array([[[ 2, 1],
[ 3, 3]],
[[ 6, 5],
[ 7, 7]],
[[10, 9],
[11, 11]]])파이썬에서도 동일하게 된다. 그래서 인덱싱을 다음과 같이 할 수 있다.
>>> l = (i, j)
>>> # a[i, j] 와 동일
>>> a[l]
array([[ 2, 5],
[ 7, 11]])하지만 이 배열은 첫 번째 차원을 인덱싱하는 것으로 해석되어 i 및 j 배열에 이를 수행할 수 없다.
>>> s = np.array([i, j])
>>> # not what we want
>>> a[s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: index 3 is out of bounds for axis 0 with size 3배열을 대상으로 인덱싱을 사용하여 다음과 같이 할당할 수도 있다.
>>> a = np.arange(5)
>>> a
array([0, 1, 2, 3, 4])
>>> a[[1, 3, 4]] = 0
>>> a
array([0, 0, 2, 0, 0])그러나 인덱스 목록에 반복이 포함되어 있으면 할당이 여러 번 수행되어 마지막 값이 남는다.
>>> a = np.arange(5)
>>> a[[0, 0, 2]] = [1, 2, 3]
>>> a
array([2, 1, 3, 3, 4])다음은 충분히 합리적이지만 파이썬의 += 구조를 사용할 경우 예상한대로 작동하지 않을 수 있다.
>>> a = np.arange(5)
>>> a[[0, 0, 2]] += 1
>>> a
array([1, 1, 3, 3, 4])부울 배열을 사용한 인덱싱
부울 인덱스는 정수 인덱스와 달리 접근 방식이 다르다.
가장 자연스러운 방버은 원래 배열과 모양이 동일한 부울 배열을 사용하는 것이다.
>>> a = np.arange(12).reshape(3, 4)
>>> b = a > 4
>>> b
array([[False, False, False, False],
[False, True, True, True],
[ True, True, True, True]])
>>> a[b]
array([ 5, 6, 7, 8, 9, 10, 11])이 속성은 할당할 때 매우 유용하다.
>>> a[b] = 0
>>> a
array([[0, 1, 2, 3],
[4, 0, 0, 0],
[0, 0, 0, 0]])다음 예에선 부울 인덱싱을 사용하여 Mandelbrot set의 이미지를 생성하는 방법을 확인할 수 있다.
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> def mandelbrot(h, w, maxit=20, r=2):
"""Returns an image of the Mandelbrot fractal of size (h,w)."""
x = np.linspace(-2.5, 1.5, 4*h+1)
y = np.linspace(-1.5, 1.5, 3*w+1)
A, B = np.meshgrid(x, y)
C = A + B*1j
z = np.zeros_like(C)
divtime = maxit + np.zeros(z.shape, dtype=int)
for i in range(maxit):
z = z**2 + C
diverge = abs(z) > r # who is diverging
div_now = diverge & (divtime == maxit) # who is diverging now
divtime[div_now] = i # note when
z[diverge] = r # avoid diverging too much
return divtime
>>> plt.imshow(mandelbrot(400, 400))
>>> plt.show()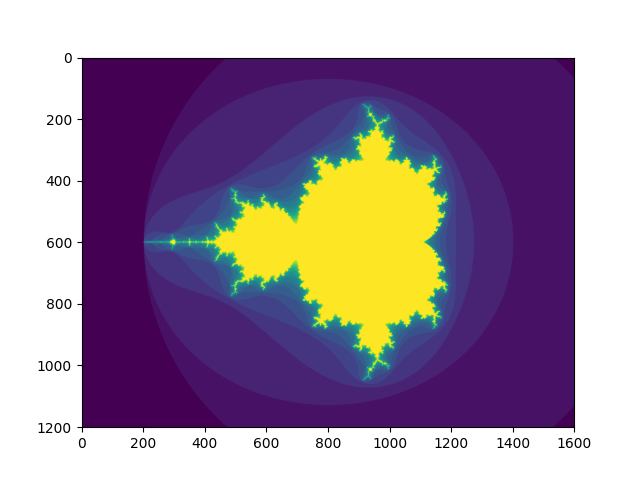
부울로 인덱싱하는 두 번째 방법은 정수 인덱싱과 더 유사하다.
배열의 각 차원에 대해 원하는 슬라이스를 선택하는 1D 부울 배열을 제공한다.
>>> a = np.arange(12).reshape(3, 4)
>>> b1 = np.array([False, True, True])
>>> b2 = np.array([True, False, True, False])
>>>
>>> a[b1, :]
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> a[b1]
array([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> a[:, b2]
array([[ 0, 2],
[ 4, 6],
[ 8, 10]])
>>>
>>> a[b1, b2]
array([ 4, 10])1D 부울 배열의 길이는 슬라이스하려는 차원(또는 축)의 길이와 일치해야 한다.
앞의 예에서 b1 의 길이 3, b2의 2축 인덱스가 적합하다.
ix_()함수
ix_ 함수는 가 u-uplet 에 대한 결과를 얻기 위해 다른 벡터를 결합하는데 사용할 수 있다.
>>> a = np.array([2, 3, 4, 5])
>>> b = np.array([8, 5, 4])
>>> c = np.array([5, 4, 6, 8, 3])
>>> ax, bx, cx = np.ix_(a, b, c)
>>> ax
array([[[2]],
[[3]],
[[4]],
[[5]]])
>>> bx
array([[[8],
[5],
[4]]])
>>> cx
array([[[5, 4, 6, 8, 3]]])
>>> ax.shape, bx.shape, cx.shape
((4, 1, 1), (1, 3, 1), (1, 1, 5))
>>> result = ax + bx * cx
>>> result
array([[[42, 34, 50, 66, 26],
[27, 22, 32, 42, 17],
[22, 18, 26, 34, 14]],
[[43, 35, 51, 67, 27],
[28, 23, 33, 43, 18],
[23, 19, 27, 35, 15]],
[[44, 36, 52, 68, 28],
[29, 24, 34, 44, 19],
[24, 20, 28, 36, 16]],
[[45, 37, 53, 69, 29],
[30, 25, 35, 45, 20],
[25, 21, 29, 37, 17]]])
>>> result[3, 2, 4]
17
>>> a[3] + b[2] * c[4]
17다음과 같이 감소를 구현할 수도 있다.
>>> def ufunc_reduce(ufct, *vectors):
... vs = np.ix_(*vectors)
... r = ufct.identity
... for v in vs:
... r = ufct(r, v)
... return r다음과 같이 사용하자.
>>> ufunc_reduce(np.add, a, b, c)
array([[[15, 14, 16, 18, 13],
[12, 11, 13, 15, 10],
[11, 10, 12, 14, 9]],
[[16, 15, 17, 19, 14],
[13, 12, 14, 16, 11],
[12, 11, 13, 15, 10]],
[[17, 16, 18, 20, 15],
[14, 13, 15, 17, 12],
[13, 12, 14, 16, 11]],
[[18, 17, 19, 21, 16],
[15, 14, 16, 18, 13],
[14, 13, 15, 17, 12]]])트릭과 팁
자동 재형성
배열의 차원을 변경하려면 크기 중 하나를 생략하면 자동으로 추론된다.
>>> a = np.arange(30)
>>> b = a.reshape((2, -1, 3))
>>> b.shape
(2, 5, 3)
>>> b
array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14]],
[[15, 16, 17],
[18, 19, 20],
[21, 22, 23],
[24, 25, 26],
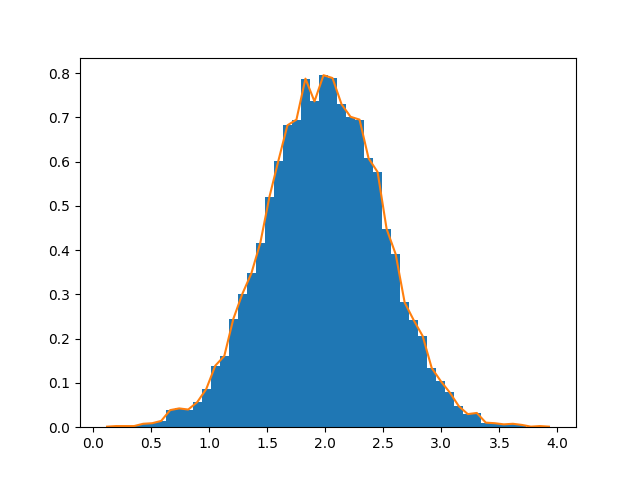
[27, 28, 29]]])히스토그램
histogram 배열에 적용된 NumPy 함수는 한 쌍의 벡터, 즉 히스토그램과 Bin 경계의 벡터를 반환한다.
>>> import numpy as np
>>> rg = np.random.default_rng(1)
>>> import matplotlib.pyplot as plt
>>> # 분산이 0.5^2이고 평균이 2인 10000 정규 편차의 벡터 만듦
>>> mu, sigma = 2, 0.5
>>> v = rg.normal(mu, sigma, 10000)
>>> # 50개의 bin 을 정규화된 히스토그램 표시
>>> plt.hist(v, bins=50, density=True) # matplotlib version (plot)
>>> # 히스토그램 계산 후 그림 표시
>>> (n, bins) = np.histogram(v, bins=50, density=True)
>>> plt.plot(.5 * (bins[1:] + bins[:-1]), n)