
n 차원 배열에 대한 선형 대수
이 튜토리얼에서 선형 대수의 행렬 분해인 단수 값 분해를 사용하여 이미지의 압축 근사치를 생성할 것이다.
scipy.misc 묘듈의 face 이미지를 사용할 것이다.
from scipy import misc
img = misc.face()img 는 type 을 사용할 때 볼 수 있는 NumPy 배열이다.
>>> type(img)
<class 'numpy.ndarray'>matplotlib.pyplot.imshow 함수를 통해 이미지를 볼 수 있다.
import matplotlib.pyplot as plt
plt.imshow(img)
모양, 축 및 배열 속성
선형 대수학에서 벡터의 차원은 배열의 항목 수이다.
NumPy 에서는 대신 축의 수를 정의한다. 예로 1D 배열은 [1, 2, 3] 과 같은 벡터이고, 2D 배열은 행렬이다.
먼저 데이터의 모양을 확인하자.
이미지는 2차원이니 2차원 배열로 예상할 수 있다.
그러나 shape 속성을 확인하면 다른 결과가 나타난다.
>>> img.shape
(768, 1024, 3)위는 3차원 배열임을 의미한다. 사실 이것은 컬러 이미지이기 때문에 imread 로 읽어 데이터는 컬러 채널(RGB)를 나타내는 3개의 2D 배열로 구성된다.
∴ 768x1024x3 인 행렬 배열임을 알 수 있다.
또한 ndim 으로도 확인할 수 있다.
>>> img.ndim
3NumPy 는 각 차원을 축으로 참조한다. imread 작동 방식 때문에 세 번째 축의 첫 번째 인덱스는 이미지의 빨간색 픽셀 데이터다.
구문을 사용하여 액세스 할 수 있다.
>>> img[:, :, 0]
array([[121, 138, 153, ..., 119, 131, 139],
[ 89, 110, 130, ..., 118, 134, 146],
[ 73, 94, 115, ..., 117, 133, 144],
...,
[ 87, 94, 107, ..., 120, 119, 119],
[ 85, 95, 112, ..., 121, 120, 120],
[ 85, 97, 111, ..., 120, 119, 118]], dtype=uint8)위 출력에서 모든 값 img[:, :, 0] 이 0 ~ 255 사이 정수 값임을 알 수 있다. 이는 각 이미지 픽셀의 빨간색 수준을 나타낸다.
그리고 이는 768x1024 행렬이다.
>>> img[:, :, 0].shape
(768, 1024)이 데이터에 대해 선형 대수 연산을 수행할 것이기 때문에 RGB 값을 나타내는 행렬의 각 항목에 0 ~ 1 사이의 실수를 갖는 것보다 흥미로울 수 있다.
우린 그렇게 설정할 수 있다.
>>> img_array = img / 255배열을 스칼라로 나누는 작업은 NumPy 의 브로드캐스팅 규칙으로 작동된다.
몇 가지 테스트를 수행하여 위 기능이 작동하는 지 확인해보자.
>>> img_array.max(), img_array.min()
(1.0, 0.0)또는 배열의 데이터 유형을 확인해보자.
img_array.dtype
dtype('float64')슬라이스 구문으로 각 색상 채널을 별도의 행렬에 할당할 수 있다.
>>> red_array = img_array[:, :, 0]
>>> green_array = img_array[:, :, 1]
>>> blue_array = img_array[:, :, 2]축에 대한 작업
선형 대수학의 방법을 사용하여 기존 데이터 집합을 근사화할 수 있다.
여기서 SVD(Singular Value Decomposition) 특잇값 분해를 사용하여 일부 기능을 유지하며 원본 이미지보다 덜 특이값 정보를 사용하는 이미지를 다시 작성하려 한다.
여기선 numpy.linalg 을 사용하여 작업한다.
대부분의 선형 대수 함수에서도 scipy.linalg 가 있어 대부분 실제 응용 프로그램에서는 scipy 모듈을 사용하는 것이 좋다.
하지만 scipy.linalg 모듈은 n 차원 배열에 선형 대수 연산을 적용하는 것이 불가능하다. 자세한 것은 scipy.linalg에서 살펴보자.
다음 모듈을 가져오자.
>>> from numpy import linalg주어진 행렬에서 정보를 추출하기 위해 SVD로 원래 행렬을 얻기 위해 곱할 수 있는 3개의 배열을 얻을 수 있다.
행렬이 주어지면 선형 대수학 이론에서 A 를 다음과 같이 계산할 수 있다.
UΣV^T = A
여기서 U 와 V 는 사각형이고 Σ 는 A 와 같은 크기다.
Σ 는 대각선 행렬이고 가장 큰 것부터 작은 것까지 조직화된 A 의 특잇값을 포함하고 있다. 이 값들은 항상 음수가 아니며 행렬 A 에 의해 표시된 몇 가지 특성의 "중요성" 에 대한 표시기로 사용할 수 있다.
하나의 생렬에만 사용하여 어떻게 작용되는지 보자. colorimetry에 따르면, 상당히 합리적인 컬러 이미지 "GrayScale" 버전을 얻을 수 있다.
Y = 0.2126R + 0.7152G + 0.0722B
여기서 Y 는 그레이스케일 이미지를 표시하는 배열이다.
그리고 R, G, B 는 각각 빨강, 파랑, 초록이며 우린 해당 색에 대한 값을 가지고 있다.
@ 연산(배열의 행렬 곱셈 연산자)을 사용하자.
>>> img_gray = img_array @ [0.2126, 0.7152, 0.0722]이것으로 이미지에 해당하는 컬러 맵을 적용해야한다.
우리의 경우엔 그레이스케일 부분을 대략적으로 나타내므로 회색 컬러 맵을 사용할 것이다.
plt.imshow(img_gray, cmap='gray')
이제 linalg.svd 을 행렬에 적용하여 분해값을 얻는다.
>>> U, s, Vt = linalg.svd(img_gray)예상한 것과 같은지 확인해보자.
>>> U.shape, s.shape, Vt.shape
((768, 768), (768,), (1024, 1024))s 는 특정 형태를 갖는 것을 알자. 단순히 하나의 차원인데 이것은 2차원 배열에 대한 선형 함수가 작동되지 않을 수 있음을 의미한다.
예를 들면, 이론적으로는 곱셈에 대해 s 와 Vt 에는 호환이 될 수 있지만, s 는 두 번째 축이 없기 때문에 사실이 아니다.
>>> s @ Vt
Traceback (most recent call last):
...
ValueError: matmul: Input operand 1 has a mismatch in its core dimension 0,
with gufunc signature (n?,k),(k,m?)->(n?,m?) (size 1024 is different from
768)결과적으로 ValueError 가 발생한다. 이것은 1차원 배열을 갖는 s 가 동일한 데이터로 대각 행렬을 구축하는 것보다 실질적으로는 훨씬 더 경제적이기 때문이다.
원래의 행렬을 재구성하기 위해 대각선 행렬 Σ 를 대각선에 있는 s 의 요소와 곱하기하여 적절한 치수로 재구성할 수 있다.
다른 경우엔, U 가 768x768 그리고 Vt 가 1024x1024 이므로 Σ 는 768x1024 이여야 한다.
>>> import numpy as np
>>> Sigma = np.zeros((768, 1024))
>>> for i in range(768):
... Sigma[i, i] = s[i]이제 재구성된 U @ Sigma @ Vt 가 img_gray 행렬에 더 가깝다면 우리가 원하는 체크를 할 수 있다.
Approximation
linalg 모듈은 NumPy 배열에서 재구성된 행렬이나 벡터의 표준을 계산하는 norm 메소드가 포함되어 있다.
예를 들어 위의 SVD 설명을 통해 img_gray 와 재구성된 SVD 간의 차이에 대한 규범이 작을 것으로 예상할 수 있었다.
>>> linalg.norm(img_gray - U @ Sigma @ Vt)
1.3926466851808837e-12또한 numpy.allclose 를 사용하여 재구성된 것이 실제로 원래의 매트릭스에 가까운지 확인할 수 있었다. (두 배열은 차이가 적음)
>>> np.allclose(img_gray, U @ Sigma @ Vt)
True근사치가 적절한지 확인하기 위해 s 단위의 값을 확인할 수 있다.
>>> plt.plot(s)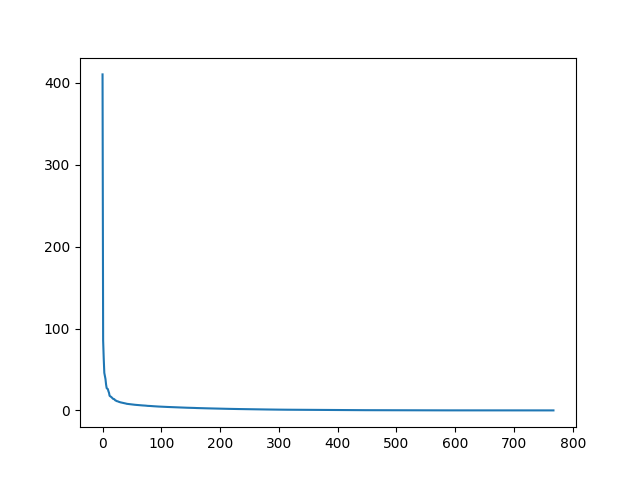
그래프에서 s 에 768개의 특잇값이 있지만 대부분의 특잇값(150번째 입력 후)이 매우 작음을 알 수 있다.
그래서 이미지에 보다 경제적인 근사치를 구축하려면 첫 번째(예로 50) 단수 값과 관련된 정보만 사용하는 것이 타당할 수 있다.
Sigma 의 첫 번째 k 개의 특잇값(s 단위)을 모두 0으로 간주하여 U 와 Vt 를 그대로 유지하고 이런 행렬의 곱을 근사값으로 계산하는 것이 목적이다.
예를 들면, 다음과 같이 선택한다면
>>> k = 10다음을 통해 근사치를 구할 수 있다.
>>> approx = U @ Sigma[:, :k] @ Vt[:k, :]다른 모든 행은 이 근사치에서 제거한 특잇값에 해당하는 0에 곱하기 때문에 Vt 의 첫 번째 k 행만 사용해야 한다.
>>> plt.imshow(approx, cmap="gray")
이제 다른 k 값으로 이 실험을 해볼 수 있다.
선택한 값에 따라 더 나은 이미지를 제공할 수 있다.
모든 색상에 적용
배열의 차원이 2개 이상인 경우 SVD 로 모든 축에 한 번에 적용할 수 있다. 그러나 NumPy 의 선형 대수 함수는 첫 번째 축이 행렬의 수를 나타내는 (N, M, M) 형식의 배열을 볼 수 있다.
지금의 경우엔,
>>> img_array.shape
(768, 1024, 3)(3, 768, 1024) 와 같은 모양을 얻기 위해선 이 배열의 축을 변형해야 한다. 다행히, numpy.transpose 함수로 가능하다.
np.transpose(x, axes=(i, j, k))축 순서를 변경하여 전치 배열의 최종 모양인 지수 (i, j, k) 에 따라 순서가 변경될 것이다.
배열에 어떻게 적용되는지 보자.
>>> img_array_transposed = np.transpose(img_array, (2, 0, 1))
>>> img_array_transposed.shape
(3, 768, 1024)이제 SVD 를 적용해보자.
>>> U, s, Vt = linalg.svd(img_array_transposed)마지막으로, 전체 근사화 이미지를 얻으려면 이런 행렬을 근사화로 재조립해야 한다.
>>> U.shape, s.shape, Vt.shape
((3, 768, 768), (3, 768), (3, 1024, 1024))n 차원 배열
NumPy 로 1차원이나 2차원 배열로만 작업 했다면 numpy.dot 과 numpy.matmul ( 또는 @ 연산자 )를 서로 바꾸어 사용할 수 있다.
그러나 n 차원 배열의 경우엔 매우 다른 방식으로 작동할 수 있다.
이제 근사치를 작성하려면 먼저 특잇값이 곱할 준비가 되었는지 확인해야 하는데, 이전에 한것과 비슷한 Sigma 를 만든다.
Sigma 배열은 치수 (3, 768, 1024) 를 가지고 있어야 한다.
시그마의 대각선에 특잇값을 더하기 위해서 numpy.fill_diagonal 함수를 사용할 것이며, Sigma 의 3 행렬 각각에 대한 대각선과 같은 s 의 3 행의 각각에 사용한다.
>>> Sigma = np.zeros((3, 768, 1024))
>>> for j in range(3):
... np.fill_diagonal(Sigma[j, :, :], s[j, :])이제 SVD로 재구성되었다면 다음과 같이 할 수 있다.
>>> reconstructed = U @ Sigma @ Vt
>>> reconstructed.shape
(3, 768, 1024)
>>> plt.imshow(np.transpose(reconstructed, (1, 2, 0)))
원본 이미지에서 수행한 조작이라 예상될 수 있어 Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). 와 같은 경고가 나타날 수 있다.
이제 근사를 구하려면 각 색상 채널에 대한 첫 번째 k 개의 단수 값만 선택해야 한다.
>>> approx_img = U @ Sigma[..., :k] @ Vt[..., :k, :]Sigma 에 대한 마지막 축의 첫 번째 k 부분만 선택했으며, Vt 의 마지막 축의 첫 번째 k 만 선택했음을 나타낸다.
줄임표 구문을 잘 모른다면 다른 축의 자리 표시자라는 것만 알자.
>>> approx_img.shape
(3, 768, 1024)이미지를 표시하기에 적합한 모양이 아니니 마지막으로, 축을 원래 모양 (768, 1024, 3) 으로 다시 재정렬하여 근사값을 보자.
>>> plt.imshow(np.transpose(approx_img, (1, 2, 0)))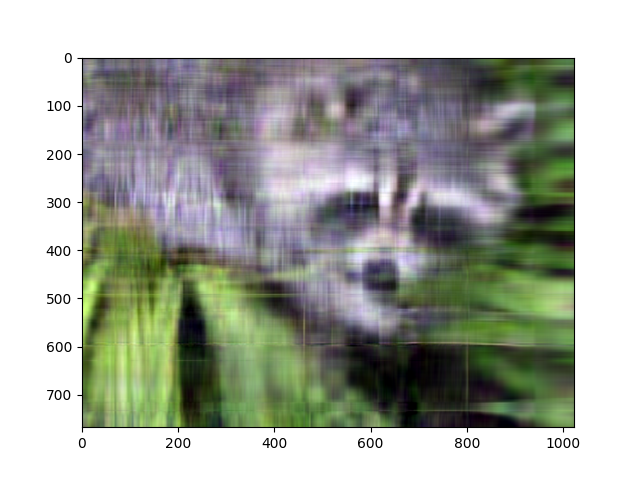
특잇값 k 의 수를 작게하여 이미지가 선명하지 않아도 값을 높여서 복구할 수 있다.
마지막으로
물론 이렇게 이미지를 근사화하는 것은 가장 좋은 방법은 아니지만 실제로 위에서 만든 근사가 원래 행렬에 도달할 수 있는 최선의 선형 대수란 결과를 알 수 있다.
