무어의 법칙
무어의 법칙이란, 고밀도 집적회로(IC)의 트랜지스터 수가 약 2년마다 두 배로 증가한다는 관찰이다. 즉, 역사적 추세를 관찰하고 투영하는 것이다.
배우게 될 기술
*.csv파일로 데이터 적재- 선형 회귀를 수행하여 최소 제곱을 사용해 지수 성장을 예측
- 모델 간의 지수 성장 상수를 비교
- 파일 분석 공유하기
*.npz파일로 NumPy 압축*.csv파일
- 50년 동안의 반도체 제조업체의 발전을 관찰해보자.
필요한 것들
필요한 패키지를 가져오자.
import matplotlib.pyplot as plt
import numpy as np
import statsmodels.api as sm지수 성장 법치을 이용하기 때문에 자연 로그와 지수에 대한 약간의 배경 지식이 필요하다.
다음 함수들을 사용할 것이다.
np.loadtxt: 텍스트를 NumPy 배열로 로드np.log: NumPy 배열의 모든 요소에 대한 자연 로그를 취함np.exp: NumPy 배열의 모든 요소의 지수를 취함lambda: 함수 모델을 생성하기 위한 최소한의 함수 정의plt.semilogy: 선형 x 축과 log10y-axis이 있는 그림에 xy 데이터를 그린다.sm.OLS: 최소 제곱 모델을 사용하여 매개 변수 및 표준 오차를 찾음- 슬라이싱 배열 : 작업할 메모리 공간을 로드
- 부울 배열 인덱싱 : 주어진 조건과 일치하는 데이터 부분을 부울 연산으로 인덱싱
np.block: 배열을 2D 배열로 결합np.newaxis: 1D 벡터를 행 또는 열 백터로 변경np.savez및np.savetxt: 두 함수는 배열을 각각 압축된 배열 형식과 텍스트로 저장한다.
지수 함수로 무어의 법칙 만들기
무어의 법칙과 같이 경험적 모델은 반도체당 트랜지스터 수가 기하급수적으로 증가한다고 가정한다.
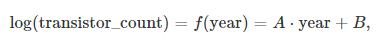
A 와 B 는 적합한 상수이며, 반도체 제조업체의 데이터로 찾을 수 있다.
주어진 년도에 대한 트랜지스터의 초기값, 2, 추가된 트랜지스터 비율을 명시함으로써 무어의 법칙에 대한 상수를 결정할 수 있다.
무어의 법칙을 다음과 같은 공식으로 기술한다.

AM 과 BM 는 2년마다 트랜지스터 수를 두 배씩 늘린 상수이고, 1971년에는 2250개의 트랜지스터로 시작했다.
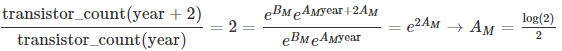
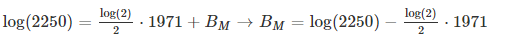
따라서 지수 함수로 명시된 무어의 법칙은 다음과 같다.
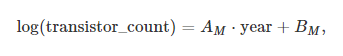
AM = 0.3466
BM = -675.4
무어의 법칙은 다음과같이 lambda 함수를 사용하여 파이썬 함수로 정의할 수 있다.
A_M = np.log(2) / 2
B_M = np.log(2250) - A_M * 1971
Moores_law = lambda year: np.exp(B_M) * np.exp(A_M * year)1971년엔 Intel 4004 칩에 2250 개의 트랜지스터가 있었다.
이때, 고든 무어가 무어의 법칙으로 1973 년의 반도체 수를 확인한다.
ML_1971 = Moores_law(1971)
ML_1973 = Moores_law(1973)
print("In 1973, G. Moore expects {:.0f} transistors on Intels chips".format(ML_1973))
print("This is x{:.2f} more transistors than 1971".format(ML_1973 / ML_1971))In 1973, G. Moore expects 4500 transistors on Intels chips
This is x2.00 more transistors than 1971과거 제조 데이터 로드
이제 칩당 반도체에 대한 과거 데이터를 기반으로 예측해보자.
매 해의 트랜지스터 수를 transistor_data.csv 파일에 넣자.
항상 *.csv 파일을 NumPy 배열에 로드하기 전에 먼저 파일 구조를 확인하는 것이 좋다.
Processor, Designer, MOSprocess 또는 Area 열은 필요없으고 도입 날짜와 트랜지스터 수만 로드하면 된다.
다음과 같이 원하는 형식의 데이터만 가져온다.
delimiter = ',': 구분 기호를 쉼표로 지정usecols = [1, 2]: csv 에서 두 세 번째 열만 가져옴skiprows = 1: 헤더 행이므로 첫 번째 행을 사용하지 않는다.
data = np.loadtxt('transistor_data.csv', delimiter=',',
usecols=[1, 2], skiprows=1)이제 데이터를 관리하기 쉽도록 year 과 transistor_count 에 두 컬럼을 할당한다.
그리고 해당 배열을 [:10] 으로 슬라이싱 하여 10개의 변수를 모두 출력하여 데이터가 옳맞은지 확인한다.
year = data[:, 1]
transistor_count = data[:, 0]
print("year:\t\t", year[:10])
print("trans. cnt:\t", transistor_count[:10])year: [1971. 1972. 1973. 1974. 1974. 1974. 1974. 1975. 1975. 1975.]
trans. cnt: [2250. 3500. 2500. 3000. 4100. 6000. 8000. 4528. 4000. 5000.]이제 독립변수 year 과 종속변수 transistor_count 를 가졌다.
이 독립 변수를 로그로 변환하자.
yi=log( transistor_count[i] )
결과적으로 선형 방적식인 다음과 같다.
yi = np.log(transistor_count)
트랜지스터 과거 성장 곡선 계산
year 의 함수는 yi 다는 것으로 가정한다.
이제 yi 와 A * year + B 사이의 차이를 최소화할 최적의 방법을 찾자.
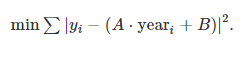
위는 다음과 같이 간결하게 나타낼 수 있다.
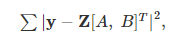
y 는 1D 배열에 있는 트랜지스터의 수에 대한 로그의 관측자이고 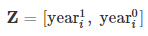 는 첫 번째와 두 번째 컬럼에 있는 yeari 에 대한 다항식 항이다.
는 첫 번째와 두 번째 컬럼에 있는 yeari 에 대한 다항식 항이다.
Z-행렬에 있는 회귀의 집합을 만듦으로써, 일반적인 최소 제곱 통계 모델을 설정한다.
year[:np.newaxis]:(179,)모양의 1D 배열로(179,1)모양의 2D 배열 벡터를 반환한다**[1, 0]: 첫 컬럼year**1과 두 번째 컬럼year**0 == 1으로 두 컬럼을 쌓는다.
Z = year[:, np.newaxis] ** [1, 0]회귀 행렬 Z 가 생성되고 관측치가 벡터 y 에 있으니 이 변수들로 sm.OLS 로 일반 최소 제곱 모형을 만들어야 한다.
model = sm.OLS(yi, Z)이제 적합한 상수인 A, B와 이것에 대한 표준 에러를 조회할 수 있다.
fit을 실행하고 이 결과에 대해 summary 함수를 출력한다.
results = model.fit()
print(results.summary()) OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.360
Model: OLS Adj. R-squared: 0.280
Method: Least Squares F-statistic: 4.503
Date: Wed, 28 Jul 2021 Prob (F-statistic): 0.0666
Time: 00:31:54 Log-Likelihood: -1.9929
No. Observations: 10 AIC: 7.986
Df Residuals: 8 BIC: 8.591
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
x1 0.1746 0.082 2.122 0.067 -0.015 0.364
const -336.3607 162.419 -2.071 0.072 -710.900 38.178
==============================================================================
Omnibus: 2.588 Durbin-Watson: 1.463
Prob(Omnibus): 0.274 Jarque-Bera (JB): 1.174
Skew: 0.835 Prob(JB): 0.556
Kurtosis: 2.831 Cond. No. 3.07e+06
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 3.07e+06. This might indicate that there are
strong multicollinearity or other numerical problems.
Process finished with exit code 0OLS 회귀 결과를 중요한것만 요약하면 다음과 같다.
coef std err
--------------------------------
x1 0.1746 0.082
const -336.3607 162.419
================================x1 는 기울기 A = 0.1746 이고, const 는 절편 B = -336.3607이고 std error 는 상수 A = 0.342±0.006 의 정밀도를 제공하며, 여기서 단위는 log(transistors/chip) 이다.
이제 지수 모델을 만들었다. 배열 AB 에 results.params 를 저장하고 A 와 B 에 각각 x1 과 constant 를 할당하자.
AB = results.params
A = AB[0]
B = AB[1]이제 최종 공식을 가지고 계산을 진행해보자.
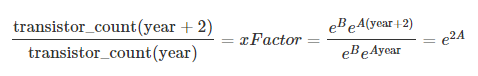
여기서 트랜지스터의 증가는 xFactor, 년 수는 2 이고 A 는 semilog 함수에 가장 적합한 기울기이다.
예측 오류인 Δ(xFactor) 는 표준 오차 ΔA=0.006 로 계산된 상수 정밀도 A 에서 온다.
print("Rate of semiconductors added on a chip every 2 years:")
print(
"\tx{:.2f} +/- {:.2f} semiconductors per chip".format(
np.exp(A * 2), 2 * A * np.exp(2 * A) * 0.006
)
)Rate of semiconductors added on a chip every 2 years:
x1.42 +/- 0.00 semiconductors per chip최소 제곱 회귀 모델을 기반으로 반도체 수는 1.98±0.01 의 오차로 약 2년 마다 매년 반도체 수를 예측한다.
이제 모든 트랜지스터 수를 플로팅한다.
여기서 plt.semilogy 를 사용하여 로그 스케일에 트랜지스터 수를 표시하고 선형 스케일에 연도를 표시한다.
다음 세 개의 배열을 정의했다.
yi=log(transistor_count)
yi=A⋅year+B
그리고
log(transistor_count)=A⋅year+B 이다.
이제 변수 transistor_count, year 및 yi 는 동일한 차원 (179,) 를 가진다.
NumPy 배열은 플롯을 만들기 위해 동일한 차원이어야 한다.
현재로써 예상되는 트랜지스터 수는 다음과 같다.

플롯에서 fivethirtyeight 스타일 시트를 사용하자.
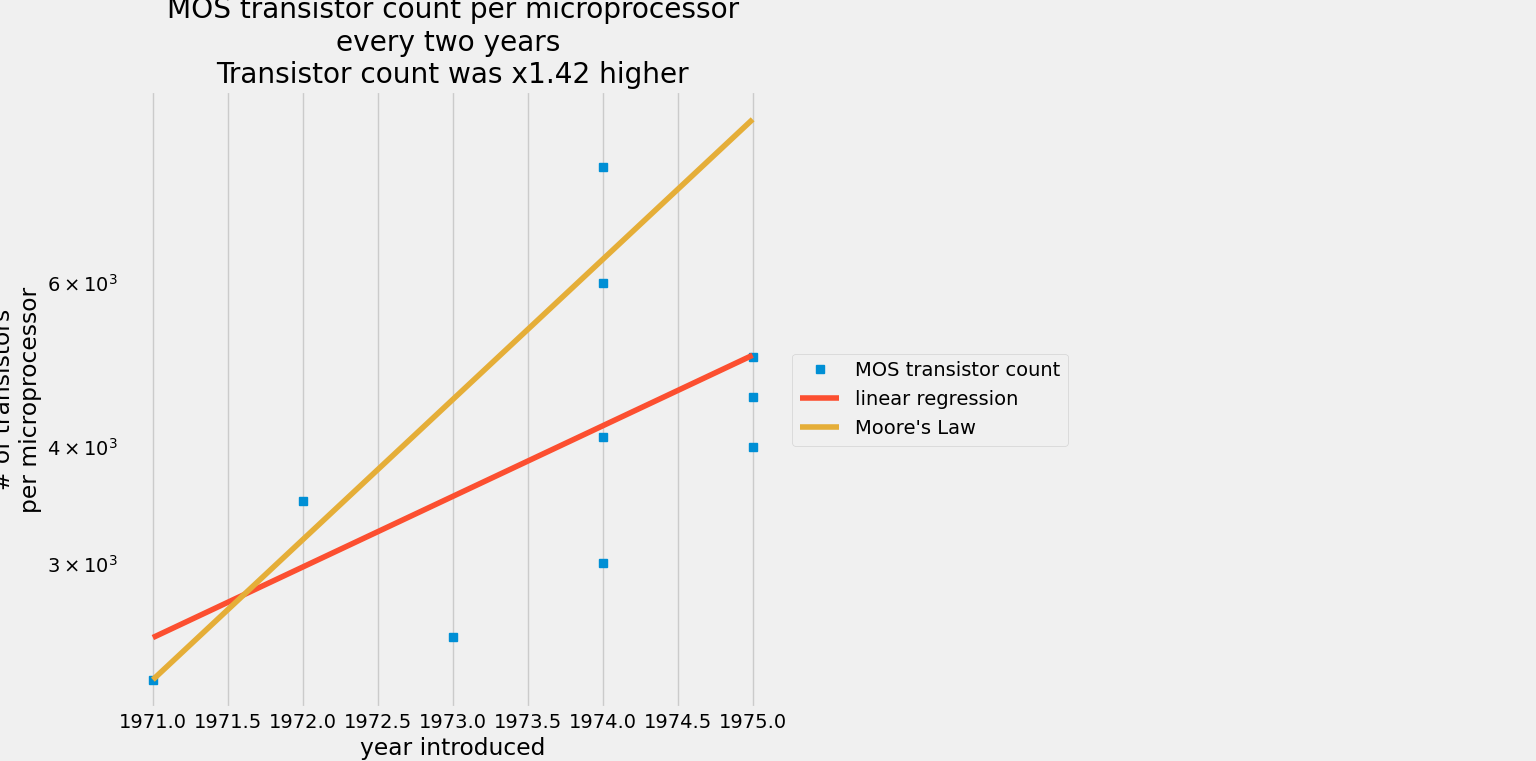
필자는 데이터셋을 10개밖에 사용하지 않았지만 1970 ~ 2020 년 까지의 데이터를 이용한다면 1.98 이라는 예측이 나온다.
일단 2017년의 트랜지스터 수를 예측한다고 생각하자.
그러기 위해 먼저 2017년의 트랜지스터 수를 가져온다.
year == 2017
그 후 위에서 정의했던 Moores_law 값으로 적합한 상수를 함수에 연결한다.
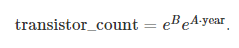
이 측정값을 통해 예측 해본다.
plt.plot 옵션을 사용하여 alpha=0.2 데이터로 투명도를 높인다.
transistor_count2017 = transistor_count[year == 2017]
print(
transistor_count2017.max(), transistor_count2017.min(), transistor_count2017.mean()
)
y = np.linspace(2016.5, 2017.5)
your_model2017 = np.exp(B) * np.exp(A * y)
Moore_Model2017 = Moores_law(y)
plt.plot(
2017 * np.ones(np.sum(year == 2017)),
transistor_count2017,
"ro",
label="2017",
alpha=0.2,
)
plt.plot(2017, transistor_count2017.mean(), "g+", markersize=20, mew=6)
plt.plot(y, your_model2017, label="Your prediction")
plt.plot(y, Moore_Model2017, label="Moores law")
plt.ylabel("# of transistors\nper microprocessor")
plt.legend()19200000000.0 250000000.0 7050000000.0결과는 다음과 같다.