
Object Detection 분야에 딥러닝을 최초로 적용시킨 모델이자 이전의 Object Detection 모델들과 비교해 성능을 상당히 향상시키고, 이후 여러 수정, 변형 모델들을 나오게 한, 의미있는 모델인 R-CNN에 대해 알아보자. 다음 목차대로 살펴볼 것이다.

Object Detection 이란
딥러닝을 Object Detection에 적용시켰다는데, Object Detection은 무엇인가?
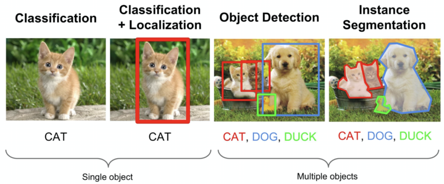
Object Detection이란 한 물체(single object)가 아닌 여러 물체(Multiple objects)에 대해 어떤 물체인지 클래스를 분류하는 Classification 문제와, 그 물체가 어디 있는지 박스를 (Bounding box) 통해 위치 정보를 나타내는 Localization 문제를 모두 포함한다.
(그림 좌측 두 번째의 'Classification+Localization' 은 하나의 object에 대해서 분류하고 위치 정보를 찾는 것이다!)
즉 Object Detection = Multiple Object에 대한 Multi-Labeled Classification + Bounding Box Regression(Localization) 라고 정리할 수 있다.
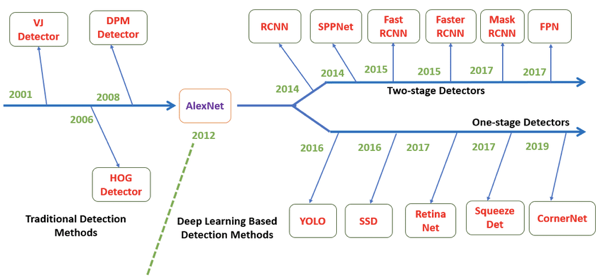
Deep Learning을 이용한 Object Detection은 2014년(실제 논문은 2013년 11월)을 기준으로 나타나기 시작하였으며 크게 1-stage Detector와 2-stage Detector로 구분할 수 있다.
- 가운데 수평 화살표를 기준으로 위 쪽 논문들이 2-stage Detector 논문들이고,
- 아래 쪽 논문들이 1-stage Detector 논문들이다.
Object Detection문제는 앞에서 말했듯이 물체를 식별하는 Classification 문제와, 물체의 위치를 찾는 Localization 문제를 합한 것인데,
- 1-stage Detector는 이 두 가지 task를 동시에 행하는 방법이고,
- 2-stage Detector는 이 두 문제를 순차적으로 행하는 방법이다.
따라서 1-stage Detector가 비교적으로 빠르지만 정확도가 낮고 2-stage Detector가 비교적으로 느리지만 정확도가 높다.
- 2-stage Detector에는 R-CNN부터 Fast R-CNN, Faster R-CNN같은 R-CNN 계열이 대표적이다.
- 1-stage Detector에는 YOLO(You Only Look Once)계열과 SSD 계열 등이 포함된다.
R-CNN의 정의
R-CNN은 'Regions with Convolutional Neural Networks features'의 약자로, 즉 설정한 Region을 CNN의 feature(입력값)로 활용하여 Object Detection을 수행하는 신경망이라는 의미를 담고 있다.
R-CNN은 앞서 강조했다시피, 2014년에 CNN을 Object Detection 분야에 최초로 적용시킨 모델이며 CNN을 이용한 검출 방식이 Classification 뿐만 아닌 Object Detection 분야에도 높은 수준의 성능을 이끌어 낼 수 있다는 것을 보여준 의미 있는 모델이다.
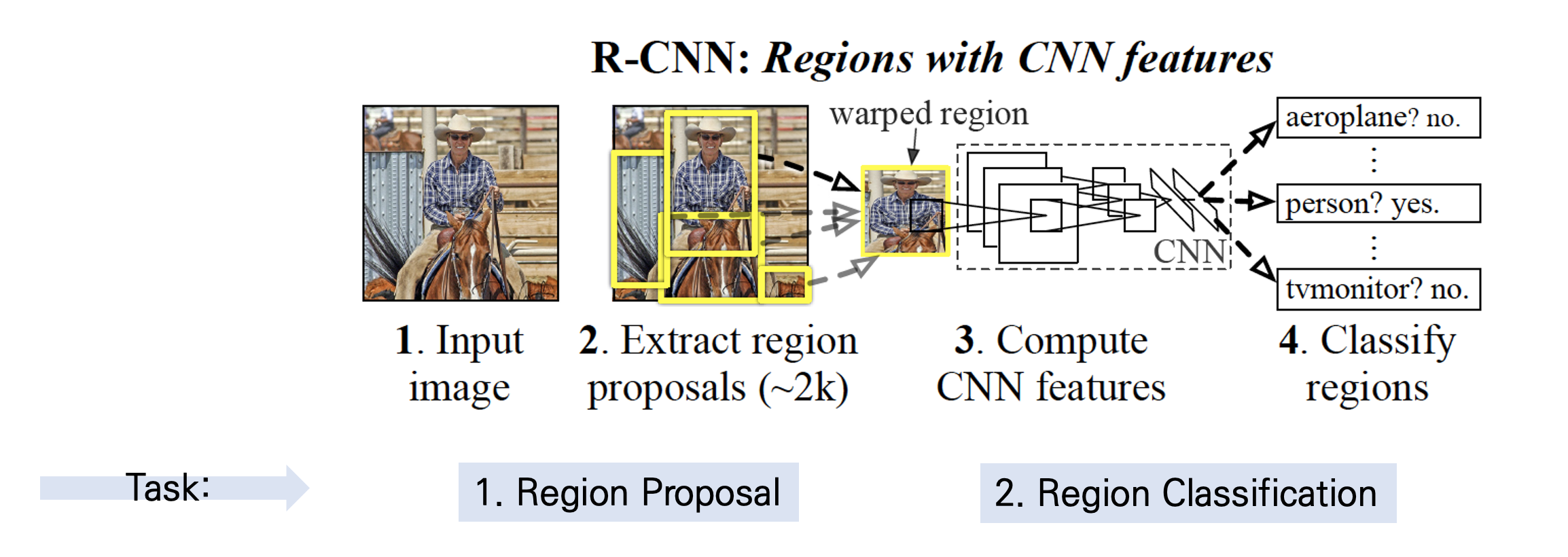
R-CNN의 기본적인 구조는 2-stage Detector라고 한 것처럼 전체 task를 두 단계로 나눌 수 있는데, 우선 물체의 위치를 찾는 Region Proposal, 그리고 물체를 분류하는 Region Classification 이다. 이 두 가지 task를 처리하기 위해 수행되는 R-CNN의 구조를 총 네 가지 모듈로 나눠서 살펴볼 것이다.
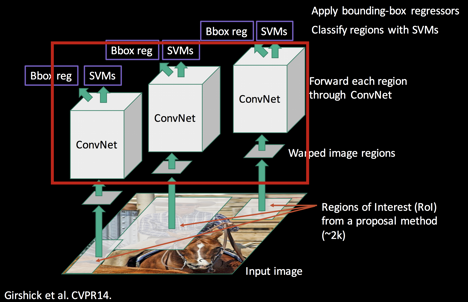
- 이미지에 있는 데이터와 레이블을 투입한 후 카테고리에 무관하게 물체의 영역을 찾는 Region Proposal.
- 그리고 proposal 된 영역으로부터 고정된 크기의 Feature Vector를 warping/crop 하여 CNN의 인풋으로 사용한다. 여기서 CNN은 이미 ImageNet을 활용한 사전훈련된 네트워크를 사용한다.
- CNN을 통해 나온 feature map을 활용하여 선형 지도학습 모델인 SVM(Support Vector Machine)을 통한 분류, 그리고
- Regressor를 통한 bounding box regression을 진행한다.
즉 정리하면,
1. Region Proposal
2. (pre-trained) CNN
3. SVM
4. Bounding Box Regression (사실 SVM과 같이 봐도 되지만 조금 더 자세히 다루기 위해 따로 빼놓았다.)
1. Region Proposal
우선 첫 번째로 데이터와 레이블을 투입해야 한다.
R-CNN에는 일반적으로 이미지를 데이터로 사용하며, 레이블은 정답 Bounding Box 를 주게 된다. 그런데 이미지를 어떻게 데이터 형식으로 사용할까? 바로 이미지 픽셀들을 vertex로 표현하고, 그 vertex들의 연결을 edge라고 보면 이해가 쉽다.
그래프이론에서 G=(V,E)로 표현되는 vertex(node)와 Edge
결국 R-CNN은 이런 이미지 데이터를 입력받아서 물체를 인지하고 분류하는 Bounding Box를 잘 찾는 게 목적이라고도 할 수 있다!
R-CNN은 이 단계에서 Selective Search라는 알고리즘을 이용해서 ‘임의의’ Bounding Box를 설정한다. Selective Search 알고리즘은 Segmentation 분야에 많이 쓰이는 알고리즘이며, 객체와 주변간의 색감(Color), 질감(Texture) 차이, 다른 물체에 애워 쌓여 있는지(Enclosed) 여부 등을 파악해서 인접한 유사한 픽셀끼리 묶어 물체의 위치를 파악할 수 있도록 하는 알고리즘이다.

Selective Search 방식은 위 그림으로 간단하게 설명할 수 있는데,
우선 1) Bounding box들을 Random하게 작게 많이 생성을 한다. 2) 그리고 이것들을 계층적 그룹핑 알고리즘을 사용해 조금씩 Merge 해나간다. 3) 이를 바탕으로 ROI(Regions of Interest)라는 영역을 제안하는 Region Proposal 형식으로 진행된다.
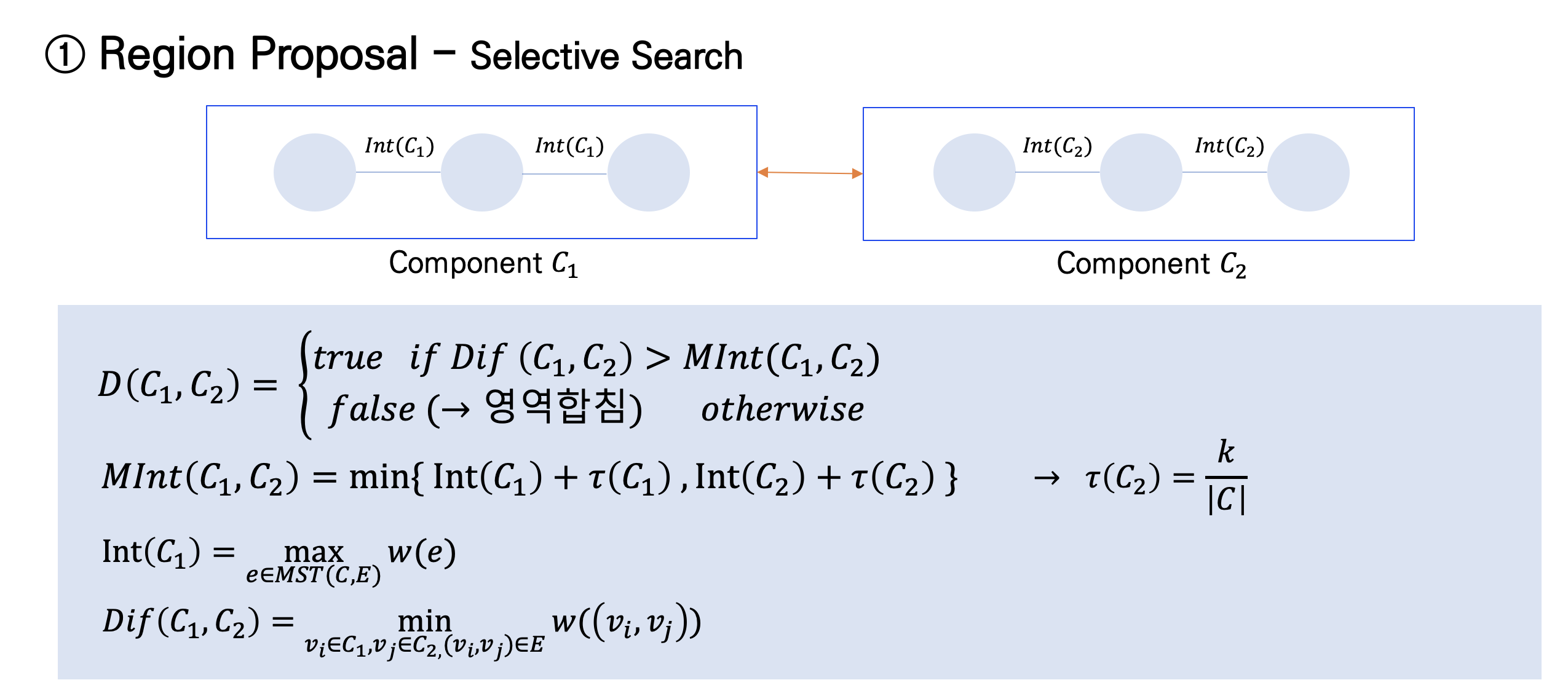
우선 작은 영역들을 처음에 설정하는 방법은 다음과 같은 수식으로 표현 가능하며 그리 어렵지 않기 때문에 간단히 흐름을 이해하고 넘어갈 것이다.
위 그림에서 하늘색 원들을 각각의 vertex라 하자. 이 vertex들이 연결되어 있는 덩어리를 component, 그리고 거기서 의미있는 영역을 segment라고 이해하면 된다. 따라서 Component가 그림처럼 C1과 C2 두 덩어리가 있다고 치자.

여기서 main 수식을 살펴보면, 그 의미는 즉,
- Dif(C1, C2) = C1과 C2간의 차이를 나타내는 값, 그리고
- MInt(C1, C2) = C1 내부에서의 어떤 값과 C2 내부에서의 값을 계산한 어떤 값
을 비교해서 Dif(C1, C2)가 (Component 외부의 계산값 ) 더 크다면 두 componenet(영역)들을 그대로 놔두는 거고, MInt(C1, C2) (내부의 어떤 계산값 )이 더 크다 하면 두 컴포넌트를 merge하게 된다. 즉 true일 때는 그대로 두고, false를 리턴할 때 두 Component, 즉 영역들을 합치겠다는 것이다.
그래서 이러한 수식을 통해 나오는 여러 segment 된 이미지들을 계층적 병합 알고리즘(Hierarchical Grouping Algorithm)을 사용해서 merge하게 되고 여기까지 region proposal 된 영역, ROI를 이제 CNN의 입력값으로 넣어주는 것이다!
2. CNN
AlexNet(ImageNet) 구조 재사용
CNN은 인풋값의 크기가 고정되어 있기 때문에, 이들을 모두 CNN에 넣기 위해 여러 사이즈로 나온 Bounding Box들을 같은 사이즈(227x227)로 통일시키는 작업(Warping)을 거친다.
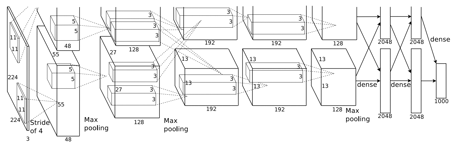
(위 AlexNet 도식에서는 input의 크기가 224x224로 나와 있고 논문에는 227x227로 나와있는데 이는 도식이 잘못된 것이라 한다. 227이 맞다.)

위의 그림처럼 원래는 각기 다른 사이즈로 제안된 Bounding Box들을 모두 같은 정사각형으로 자르고 줄여서 만든 이미지들이다.
이러한 이미지 2000개를 227x227 Pixel Size로 각각 모두 (2000번) CNN에 인풋으로 넣어 주는데, 이 논문에서 CNN은 사전학습된 AlexNet의 구조를 거의 그대로 가져다 썼으며, Object Detetion 용으로 마지막 부분만 조금 수정하였다. (마지막층의 1000을 200, 20 으로 바꿔서 썼다고 한다.)
3. SVM (Support Vector Machine)
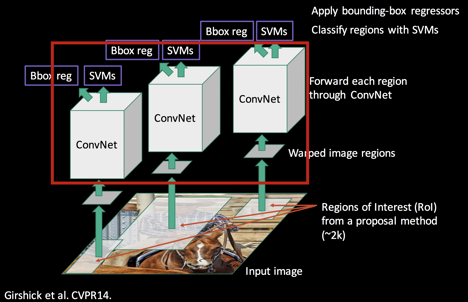
드디어 CNN을 거치고 나와 R-CNN의 분류를 수행하는 주요 모듈인 SVM까지 왔다.
CNN 모델로부터 Feature가 추출이 되고 Training Label이 적용되고 나면 우선 Linear SVM을 이용하여 classification을 진행한다.
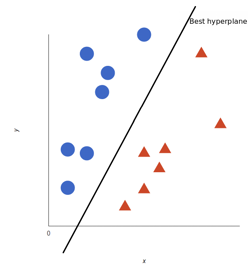
SVM은 기계학습 분야에서 패턴 인식이나 자료 분석을 위해서 쓰는 지도 학습 모델이고 주로 분류나 회귀 분석을 위해 사용한다. 간략하게 설명하자면, 위 그림에서 동그라미와 세모가 모두 벡터들인데, 임의의 두 서포트벡터를 연결한 직선과, 그 직선을 그대로 평행이동하였을 때 처음 다른 벡터와 접하는 시점에서의 직선과의 거리가 최대가 될 때의 값들을 구하는 기법이다.
여기서 R-CNN이 Classifier로 Softmax를 쓰지 않고 그 당시에도 연식 있는 전통적인 분류 모델 SVM을 사용한 이유는 R-CNN 논문에서 Appendix B 부분에 기재해놓은 바와 같이 VOC2007 데이터셋 기준으로 Softmax를 사용하였을 때 mAP값이 54.2%에서 50.9%로 떨어졌다고 한다. 즉 경험에 의한 선정!
R-CNN 논문에서는 CNN을 fine-tuning 할 때는 각 클래스별로 IoU가 0.5가 넘으면 positive sample 로 두고, 그렇지 않으면 "background"라고 labeled 해두는데,
반면 SVM을 학습할 때는 IOU 기준이 0.3으로, ground-truth boxes(정답 박스)만 positive example로 두고, IoU가 0.3미만인 영역은 모두 negative로 두었으며, 나머지는 전부 무시했다.
-> CNN 학습 때랑 SVM 학습 때 IOU기준이 다른 이유 역시 경험상 더 잘되었다고 한다.
4. Bounding Box Regression
도식에서 bBox reg라고 쓰여진 상자를 따로 그려줬는데, 이 Bounding Box Regression은 처음에 y로 줬던 레이블과, CNN을 통과해서 나온 Bounding Box, 이 두 가지의 차이를 구해서 차이를 줄이도록 조정하는 선형회귀 모델 절차이다. 이렇게 Bounding Box Regression을 통해서 나온 값을 CNN 단계 전으로 전달하게 되고 이걸 이용해서 Region Proposal이 더 잘 되도록 하게 해준다.
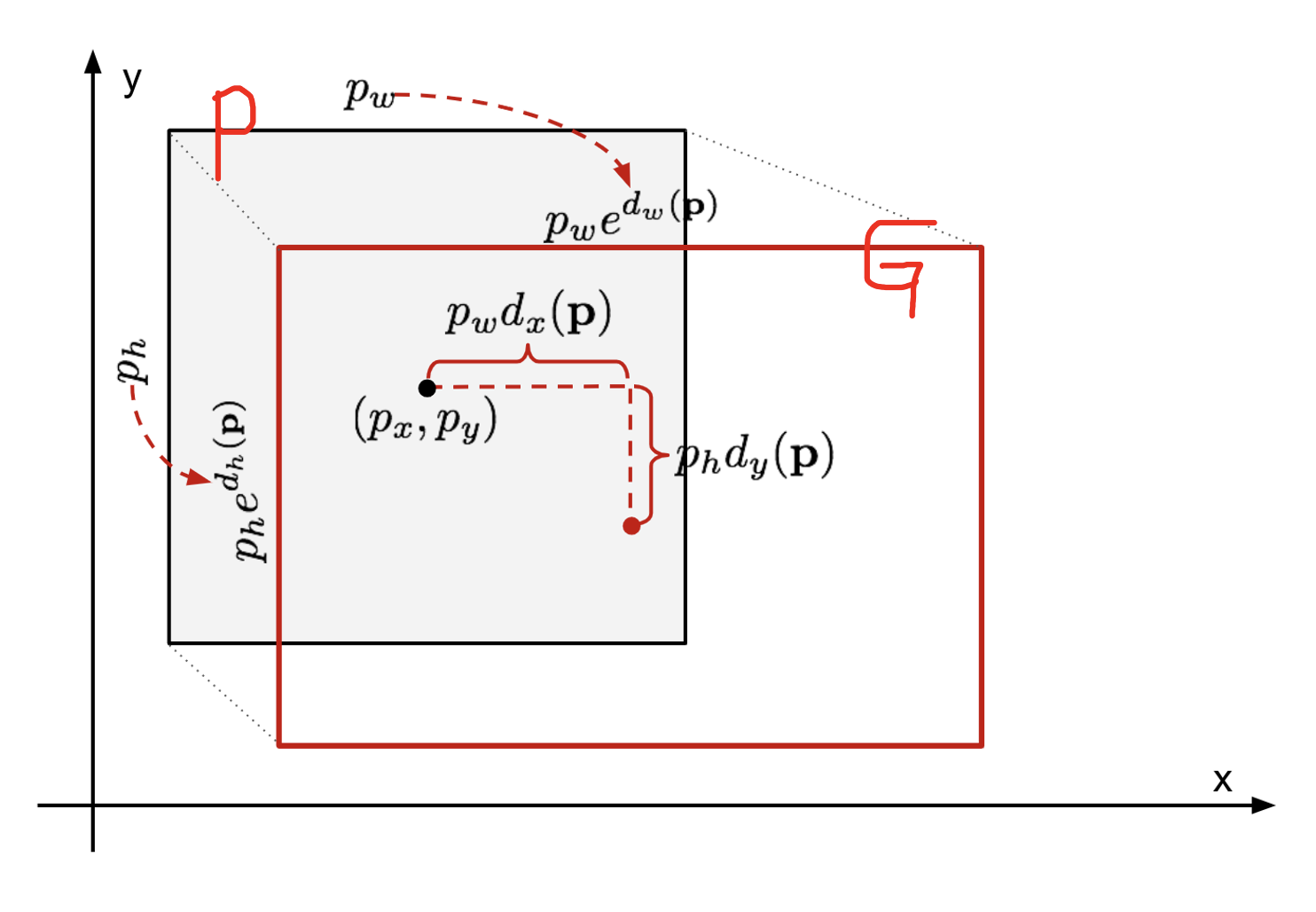
즉 위 그림에서 P가 처음에 region proposal을 통해서 제안된 Bounding Box이고, G는 Ground Truth Bounding Box(정답 박스)입니다.
여기서 P를 정답 G에 맞추도록 transform 하는 것을 학습하는 것이 바로 Bounding Box Regression의 목표이다!

Bounding Box Regression 식은 생긴 것보다는.. 비교적 이해하기 쉽다.
bBox의 input값은 N개의 Training Pairs로 이루어져 있다. 위의 식에서 x, y 는 각각 Bounding Box의 중심의 x, y 좌표, w, h 는 박스의 width(너비), height(높이)를 나타낸다.
첫 번째 식은 P의 x값이 업데이트 되는 수식인데, P의 x값에 P width값과 P의 x에 대한 Transformation 함수 값을 곱한 걸 더해준다. d_x는 x에 대한 Transformation 함수인데, 아래 빨간색으로 줄 쳐놓은 부분인 바로 d_i (d_x, d_y, d_w, d_h) 식이다.
y값도 마찬가지로 P의 height 값에다 P의 y 값에 대한 함수 값을 곱한 것을 더해주며 업데이트한다. width와 height 는 지수 함수를 통해서 업데이트가 된다.
-> 즉 결과적으로는 t_i와 d_i의 차이를 최소로 줄여 나가는 식이라고 보면 된다!
정리
그래서 마지막으로 R-CNN이 무엇이냐? 하면,
- 이미지마다 임의의 영역들로 잘게 잘라서 merge 하고 warping 한 후,
- CNN의 input으로 통과하여 Feature vector를 추출하고,
- 적용된 label들을 이용해 SVM 분류와 Bounding Box Regression을 수행해서 영역 위치까지 예측을 하게 되는 모델이
바로 R-CNN이다!!!
R-CNN의 한계
이렇게 R-CNN의 구조를 열심히 뜯어보았는데, 이러한 R-CNN은 Object Detection에 딥러닝을 최초로 적용시키고 이전 Object Detection 모델들에 비해 뛰어난 성능을 보였다는 것은 분명하지만, 명확한 몇 가지 단점을 가진다.
우선 모델이 너무 복잡하다. (여기서 4가지로 나눠서 정리했지만) 일단 모델이 3가지 이상이나 사용된다. 또한 R-CNN의 첫 번째 모듈인 Region Proposal에서 사용되는 Selective Search는 CPU를 사용하는 알고리즘이다..! 그리고 이 Selective Search에서 뽑아낸 2000개의 영역 이미지들에 대해서 모두 CNN 모델에 넣는다.
GPU 에서 이미지 한 장당 대략 13초가 걸리는데, CPU로는 53초가 걸린다고 한다. 이걸 2000장 반복하는 것이다..! 따라서 당연히 시간이 오래 걸릴 수밖에 없다. 또한 각 모듈이 동시에 일어나지 않고 시간도 오래 걸리므로 real-time 분석이 어렵다는 단점 역시 있다.
이러한 여러 한계점들로 인해 보완된 모델들이 계속 나오게 되는데 오늘 R-CNN의 기본 구조에 대해 이해하고 있다면 이후 모델들은 더 쉽게 공부할 수 있을 거라고 생각된다!
Paper:
Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(v5), Ross Girshick Jeff Donahue Trevor Darrell Jitendra Malik, UC Berkeley
논문 링크 https://arxiv.org/pdf/1311.2524.pdf
Selective Search for Object Recognition, J.R.R. Uijlings∗1,2, K.E.A. van de Sande†2, T. Gevers2 , and A.W.M. Smeulders2
논문 링크 http://www.huppelen.nl/publications/selectiveSearchDraft.pdf
이미지 출처
https://medium.com/zylapp/review-of-deep-learning-algorithms-for-object-detection-c1f3d437b852
https://www.researchgate.net/figure/Milestones-of-object-detection-In-2012-the-major-turning-point-was-the-use-of-DCNN_fig1_341099304
https://nuggy875.tistory.com/21
https://cv-tricks.com/object-detection/faster-r-cnn-yolo-ssd/
https://nuggy875.tistory.com/21
https://monkeylearn.com/blog/introduction-to-support-vector-machines-svm/
https://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html

3개의 댓글

region proposal 사진의 Int 함수가
C의 최소신장트리의 엣지 중 가장 큰 값의 가중치를
구하는 함수라고 이해했는데 혹시 맞을까요..?
안녕하세요, 포스팅에 사용하신 이미지와 일부 정리 내용들을 혹시 스터디 활동에서 정리겸 작성하는 위키독스 문서에 사용 가능할까요?(영리목적이 없고, 출처를 기재해 놓겠습니다!)