Bag-of-Words
1. 개요
Bag of Words (BoW)란?
- 원래는 문서 내 단어 빈도 기반 정보 검색 기법.
- 이를 이미지 분류에 응용한 것이 Bag-of-Features (BoF) 혹은 Bag-of-Visual-Words (BoVW).
- 객체는 지역적 특징들의 모음으로 표현됨 (local features collection).
- 지역 특징들은 부분적인 가림(occlusion), 스케일, 회전에 강인함.
2. 핵심 가정
Spatial 정보를 무시해도 객체 인식에 충분하다
→ 이미지 내의 위치 정보 없이 특징만으로도 분류가 가능하다는 가정.
3. 역사적 배경
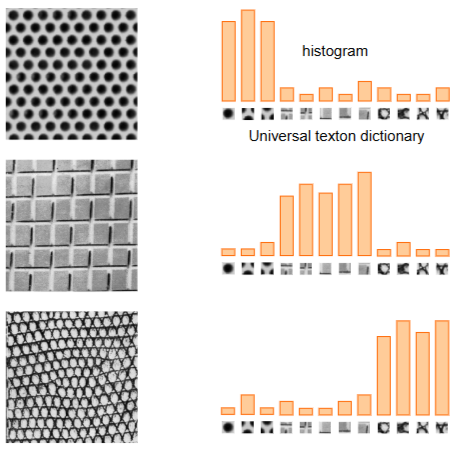
- 텍스처 인식과 정보 검색에서 유래.
- 대표 논문:
- Sivic & Zisserman (2003)
- Csurka et al. (2004)
- 이미지 분류 분야에서 잘 작동함 (Caltech6 등).
4. BoW 모델 구조
(1) 벡터 공간 모델 (Vector Space Model)

- 문서(또는 이미지)는 각 단어(또는 시각 특징)의 카운트 벡터로 표현됨.
- 코사인 유사도 등의 거리 측정을 통해 유사도 계산.
(2) 단어 중요도 보정: TF-IDF
- TF (Term Frequency): 특정 단어의 문서 내 등장 빈도
- IDF (Inverse Document Frequency): 전체 문서에서의 희귀성
- 자주 나오는 단어는 가중치를 낮춤 (e.g., "the", "a")
5. 표준 BoW 파이프라인 (Image Classification)
단계별 설명:
(1) Dictionary Learning (시각 단어 사전 생성)
- 이미지에서 SIFT 등을 이용해 지역 특징 추출
- K-means 등의 클러스터링으로 ‘시각 단어(Visual Word)’ 생성
(2) Encoding (특징 벡터화)
- 각 이미지의 특징을 가장 가까운 시각 단어로 할당 (Quantization)
- 시각 단어 출현 빈도수 기반 히스토그램 생성
(3) Classification
- 생성된 BoW 히스토그램을 사용하여 분류기 학습 (e.g., SVM)
6. Feature Extraction 방법
- Regular Grid Sampling: 일정 간격의 픽셀 블록
- Interest Point Detector: 특징점 기반 (SIFT, SURF 등)
- Random Sampling, Segmentation-based Patch
7. K-means 클러스터링
알고리즘 요약:
- 초기 중심점 k개 랜덤 설정
- 각 데이터 포인트를 가장 가까운 중심점에 할당
- 각 클러스터의 평균으로 중심점 재계산
- 할당이 더 이상 변하지 않을 때까지 반복
8. 사전 학습 및 일반화
- 시각 단어 사전은 별도 학습용 데이터로부터 생성 가능
- 충분히 대표성 있는 데이터라면 범용적 사용 가능
9. 예시

(1) Feature Extraction (특징 추출)
- 입력 이미지에서 로컬 특징(local features) 을 추출합니다.
- 예: SIFT, SURF, ORB 등을 사용하여 눈, 입, 손, 다리 등의 윤곽선, 모서리 등을 검출
- 보통 수백~수천 개의 특징점이 추출됨
사람 사진 예시:
- 머리카락, 눈썹, 입술, 손가락 끝, 옷 주름 등의 지역적 구조를 감지
(2) Dictionary Learning (시각 단어 사전 생성)
- 여러 사람 이미지에서 추출된 특징들을 K-means로 클러스터링
- 각 클러스터 중심은 하나의 Visual Word (= 시각 단어)
예:
- 클러스터 #1: 눈 끝 모양
- 클러스터 #2: 옷 주름
- 클러스터 #3: 손가락 끝
- …
- 이렇게 생성된 시각 단어들을 묶어 "시각 단어 사전(codebook)" 을 구성
(3) Encoding (BoW 벡터 생성)
- 새 이미지(사람이 걷고 있는 사진 등)에 대해 특징을 추출한 후
- 각 특징을 가장 가까운 시각 단어로 양자화(Quantization)
- 그리고 해당 시각 단어의 등장 빈도를 히스토그램 형태로 표현
예:
| 시각 단어 (cluster) | 등장 횟수 |
|---|---|
| 눈 끝 | 5 |
| 손가락 끝 | 8 |
| 옷 주름 | 12 |
| … | … |
→ 최종적으로 이 히스토그램 벡터가 BoW 표현입니다.
(4) Classification (분류)
-
학습 단계: 여러 이미지에 대해 위의 BoW 벡터를 생성하고, 이와 대응되는 레이블(예: 웃는 사람 vs 걷는 사람)을 사용해 분류기(SVM 등)를 학습
-
테스트 단계: 새 이미지에 대해 BoW 벡터를 생성하고 학습된 분류기를 통해 어떤 클래스인지 예측

상어 인형을 좋아하는 사람