Visual Featuers
- 정보 요약: 원본 이미지는 수백만 픽셀로 구성되지만, SLAM에서는 장면 전체를 모두 쓰기보다 “특징점(interest point)”만 뽑아내 맵과 포즈를 추정합니다.
- 효율성: 중요한 포인트만 추려내기 때문에 연산량이 줄고, 실시간 성능을 확보할 수 있습니다.
- 정확도: 잘 설계된 특징은 반복 촬영된 이미지에서 같은 물리 지점을 일관되게 찾아주므로, 카메라 자세 추정과 맵핑의 정확도를 높입니다.
Detector vs. Descriptor
디텍터 (Detector)
1. 코너 기반 (Corner-based)
- 특징
- 영상의 두 개 이상의 경계(edge)가 만나는 지점에서 뚜렷한 강도 변화가 나타나는 지점을 검출
- 대표 알고리즘: Harris, Shi–Tomasi
- 장점
- 정밀한 위치(localization)
- 비교적 조명 변화에 강함
- 단점
- 스케일 변화에 민감 → 멀어지거나 가까워지면 검출율 저하
- 계산량이 다소 높아 실시간 처리에는 추가 최적화 필요
2. 블롭 기반 (Blob-based)
- 특징
- 밝기가 급격히 달라지는 영역(“블롭”)을 검출
- 대표 알고리즘: LoG(Laplacian of Gaussian), DoG(Difference of Gaussian)
- 장점
- 스케일 공간에서 자연스럽게 블롭 위치와 크기를 동시에 찾음
- 멀리 있는 물체나 큰 패턴 검출에 유리
- 단점
- 블롭이 아닌 구조(예: 선, 코너)에는 반응이 약함
- 흐림(blur) 단계가 많아 연산 비용 상승
3. FAST (Features from Accelerated Segment Test)
- 특징
- 픽셀 원형 패턴(보통 반지름 3의 16개 픽셀) 중 중심 대비 밝기 차가 클 때 코너로 판단
- 학습된 기준으로 빠르게 연산
- 장점
- 매우 높은 검출 속도 → 실시간 SLAM에 최적화
- 구현이 단순해 임베디드 환경에서도 가볍게 동작
- 단점
- 회전·스케일 불변성 없음 → 이후 기술자(descriptor) 단계에서 보정 필요
- 노이즈에 민감해 검출된 점이 약간 불안정할 수 있음
기술자 (Descriptor)
스케일 공간 기반 (Scale-Space Based)
1. SIFT (Scale-Invariant Feature Transform)
- 특징
- 여러 스케일의 가우시안 블러 이미지를 생성하고, 이들을 빼서 밝기 변화가 극명한 블롭(DoG) 검출
- 각 키포인트 주변의 방향별 밝기 변화를 히스토그램으로 128차원 벡터 생성하여 회전, 밝기 변화에 강건.
- 장점
- 회전·스케일 불변성 우수
- 다양한 조명·뷰포인트 변화에도 안정적 매칭
- 단점
- 높은 차원(128D)으로 메모리·계산 비용 큼
- 실시간 처리에는 다소 무거움
2. SURF (Speeded-Up Robust Features)
- 특징
- 이미지를 한 번에 누적한 적분 영상(integral image)으로 밝기합 연산을 매우 빠르게 수행.
- 2차 미분 필터를 근사한 박스 필터로 블롭을 검출하여
- 축소된 64차원 벡터로 그래디언트 합산 방식 사용
- 장점
- SIFT 대비 약 2–3배 빠른 연산 속도
- 여전히 우수한 불변성(회전·스케일)
- 단점
- 박스 필터 근사로 인해 SIFT보다 약간 정확도 손실
- 특허 제약이 있어 상용 활용 시 라이선스 확인 필요
3. KAZE
- 특징
- 가우시안 블러 대신 이미지 에지 경계를 보존하면서 노이즈만 제거하는 비선형 확산 방정식 기반 스케일 공간
- 노이즈 억제와 경계(edge) 보존을 동시에 달성
- 장점
- 복잡한 텍스처·경계에서 견고한 키포인트 검출
- 표현력 높은 기술자와 결합 시 매칭 정확도 우수
- 단점
- 비선형 확산 연산으로 계산량 증가
- 실시간 SLAM에는 최적화된 구현이 필요
- 이를 반영하여 연산량을 낮춘 A-KAZE 등장
이진 기술자 (Binary Descriptors)
4. BRIEF (Binary Robust Independent Elementary Features)
- 특징
- 패치 내 임의 픽셀 쌍 밝기 비교해 이진 스트링 생성
- 매우 단순·경량
- 장점
- 계산·매칭 속도 매우 빠름
- 메모리 사용량 적음
- 단점
- 회전·스케일 불변성 없음 → ORB처럼 별도 보정 필요
- 조명 변화에 약간 민감
5. ORB (Oriented FAST and Rotated BRIEF)
- 특징
- FAST로 관심점 검출 → 주변 패치의 주 방향을 분석해 BRIEF 회전 보정 적용
- 장점
- BRIEF의 속도 장점 유지하면서 회전 불변성 확보
- 특허 제약 없음, 오픈소스 친화적
- 단점
- 스케일 변화에는 별도 피라미드 처리 필요
- BRIEF 기반 한계로 매우 복잡한 뷰포인트 변화에는 약함
6. FREAK (Fast Retina Keypoint)
- 특징
- 인간 망막 시각 구조 모방, 원형 패턴의 비선형 샘플링
- 패치 주변부 세밀한 샘플링으로 높은 판별력
- 장점
- 작은 포맷(512비트)에도 높은 매칭 정확도
- 속도·정밀도 균형 우수
- 단점
- 구현 복잡도↑
- 하드웨어 가속 없으면 일반 BRIEF 대비 느릴 수 있음
7. BRISK (Binary Robust Invariant Scalable Keypoints)
- 특징
- 원형 샘플링 패턴 + 중심 대칭 비교로 이진 스트링 생성
- 스케일 피라미드 이용해 자연스러운 스케일 불변성
- 장점
- 회전·스케일 불변성 동시에 제공
- 매칭 속도 빠르고, 메모리 효율적
- 단점
- BRIEF/ORB 대비 약간 더 무거운 샘플링 구조
- 매우 세밀한 구조에서는 SIFT/SURF보다 정밀도 낮음
Matching
KD-Tree
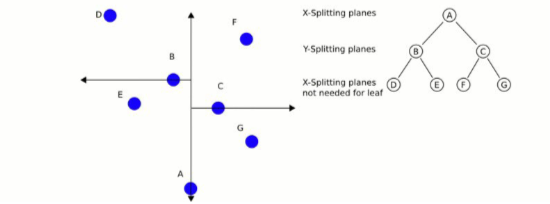
- 목적: 고차원 기술자(descriptor) 공간에서 ‘가장 가까운 이웃’을 빠르게 찾기 위한 자료 구조
- 원리:
- 기술자 벡터를 이진트리 형태로 분할(각 노드가 특정 축과 기준값을 기준으로 공간을 반으로 나눔)
- 검색 시, 전체 벡터를 순차 탐색하는 대신 트리를 타고 내려가며 후보 집합을 좁혀 나감
- 특징:
- 대량의 기술자를 비교할 때 Brute-Force 대비 훨씬 빠름
- 근사(NN Approximate)를 허용하면 속도가 더 빨라짐
Bag of Words (BoW)
- 목적: 이미지(또는 프레임)를 ‘단어의 집합’으로 표현해, 문서 검색처럼 유사 이미지 검색·매칭
- 원리:
- Visual Vocabulary: 수천~수만 개의 ‘시각 단어(visual word)’를 미리 학습
- 인덱싱: 각 이미지의 특징자를 가장 가까운 단어에 할당 → 히스토그램(단어 등장 빈도) 생성
- 매칭: 히스토그램 간 유사도를 비교해 이미지 유사도 측정
- 적용: Video Google, DBoW, FAB-MAP 등
Video Google
- Google의 문서 검색 아이디어를 영상 키프레임 매칭에 적용한 초기 연구
- 키프레임을 BoW로 표현 후, “이 키프레임이 비디오의 어디에 나오는가”처럼 검색 문제를 풀어냄
Bag of Words Vocabulary
- 생성:
- 수만 개 특징자를 클러스터링(k-means 등)해 ‘단어 사전’을 만듦
- 사전 크기와 클러스터링 품질이 매칭 성능에 직접 영향
- 활용 팁:
- 사전은 범용(여러 환경·카메라) 데이터로 학습해야 일반화가 좋음
- 클러스터 개수(K)가 너무 작으면 표현력이 떨어지고, 너무 크면 잡음 단어가 많아짐
DBoW (Database of Words)
- 라이브러리 형태로 제공되는 BoW 프레임워크
- 특징:
- 사전 학습, 인덱싱, 검색 기능을 패키지화
- 로컬 SLAM 시스템(ORB-SLAM 등)에서 빠른 키프레임 매칭·루프 클로징에 널리 사용
FAB-MAP
- BoW 접근에 확률 모델을 더한 매칭 기법
- 핵심 아이디어:
- 단순 빈도 기반이 아닌, 단어의 공출현 패턴을 이용해 실제 같은 장소인지 확률적으로 판단
- “이 장소에 이 단어들이 함께 나올 확률”을 모델링해 False Positive를 크게 줄임
- 응용: 장거리 루프 클로징, 큰 스케일 SLAM
VLAD (Vector of Locally Aggregated Descriptors)
- BoW 히스토그램의 한계를 보완하기 위해 등장
- 아이디어:
- 각 단어 클러스터에 속한 특징자들이 ‘클러스터 중심과 얼마나 차이나는지’ 벡터로 집계
- 히스토그램 대신, 차이 벡터를 모두 연결해 더 풍부한 표현 생성
- 특징:
- BoW 대비 더 작은 차원으로 높은 표현력
- 매칭 정확도 개선, 단 이질감 검증이 필요
NetVLAD
- VLAD를 신경망 안에 통합한 딥러닝 기반 기법
- 구성:
- CNN 피처 맵 위에 VLAD pooling 레이어 삽입 → End-to-End 학습
- 장점:
- 데이터셋 특성에 맞춰 최적화된 사전 학습 없이도 강력한 장소 인식 성능
- 전통적인 VLAD 대비 로버스트니스, 어댑티브한 특성 학습

상어 인형을 좋아하는 사람