리뷰에 앞서...
- single image input으로 3D guassian을 fitting하는 방법들 중 대부분이, diffusion model을 사용해 multi-view 이미지를 생성하고, 이렇게 augmented 된 데이터를 기반으로 3D reconstruction을 수행한다.
- 그러나 해당 논문은 input image pixel을 tri-plane hash encoder의 좌표로 매핑하는 모델을 학습시켜 learning 기반의 방식을 제안한다.
- Link: https://real3dportrait.github.io/
1. Introduction

- 기존 Talking head의 연구
- 2D Talking Head
- GAN 기반으로 이미지를 생성하기 때문에, warping artifact, unrealistic distortion, temporal jitters 등이 발생. 특히 이런 오류는 고개가 크게 돌아갈 때 심각해짐.
- GAN의 모드 붕괴 등 모델 훈련 자체가 어려움
- 3D Talking Head
- 2D 방식보다 3D geometry를 더 잘 보존하고, 주름 등의 고주파 texture를 풍부하게 표현 가능
- 그러나 현재까지 다수의 프레임을 포함한 비디오로 하나의 인물에 오버피팅시키는 방식이었음
- input frame을 줄이기 위해 3DMM을 사용하려는 시도가 있었으나, 다음과 같은 문제가 발생
- 3DMM은 간단한 메쉬이므로 주름 등의 미세 표현이 불가능하고, 이러한 정보 손실은 실제 사진같은 토킹 헤드를 합성하는데 장애가 됨.
- 3DMM은 face에 대한 structure prior만 제공하기 때문에, 머리카락, 모자, 안경 등은 구현할 수 없으며, 이것에 의한 occlusion은 정확하지 못한 파라미터 피팅으로 이어짐.
- 옆을 바라보는 등 고개를 많이 돌린 데이터셋이 없기 때문에, 이런 특수한 이미지가 들어올 경우 모델 피팅이 어려움.
- 2D Talking Head
- 저자들의 기여
- (1) image-to-plane model: single image로 3D canonical gaussian을 생성하도록 tri-plane hash encoder를 학습한 모델
- (2) motion adapter: canonical gaussian을 speech audio에 맞춰 deform하는 모델. 이 때, 다른 모델과 달리 인코딩 된 공간인 tri-plane hash encoder에 피처 변분량을 더해 얼굴을 움직이는 방식을 사용. (다른 모델은 직접 가우시안의 움직임을 추정)
- (3) natural torso movement & switchable background: 얼굴의 3DMM 좌표계를 카메라 좌표계로 변환한 뒤, 이것의 움직임을 기반으로 torso 이미지가 워핑되어 자연스럽게 머리를 따라가는 움직임을 생성. 또한 인물이 가리고 있는 배경을 KNN 기반으로 인페인팅하여 자연스러운 배경 생성 및 교체까지 가능.
- (4) audio-to-motion model: 드라이빙 비디오 뿐만 아니라 오디오로부터 자연스러운 토킹 헤드를 생성하는 방법 제안 (이 방법은 사실 GeneFace의 WaveNet Encoder & Decoder 네트워크를 거의 모방한 것)
2. Method
2.1. I2P Model
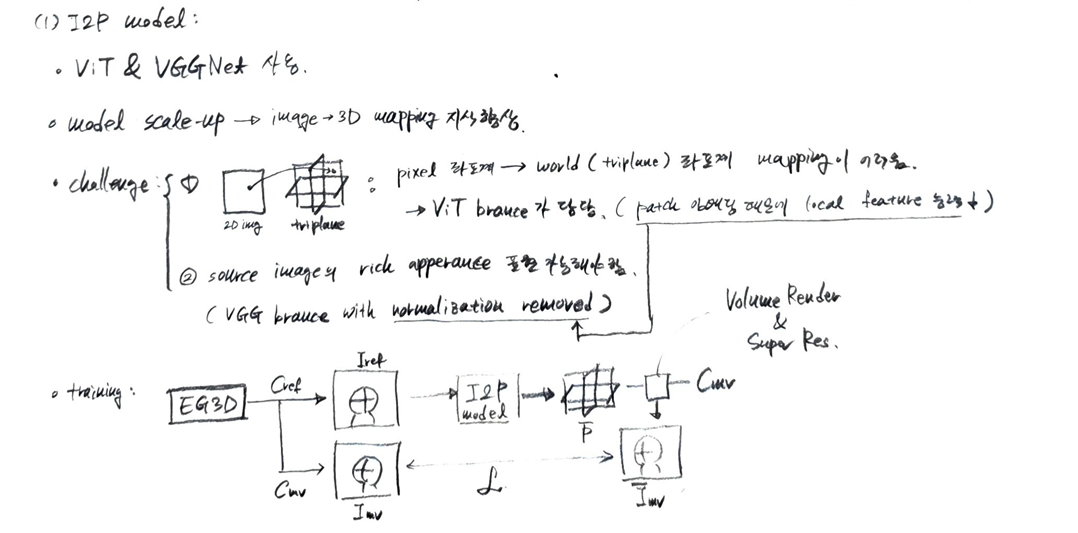

이 이미지는 Real3D-Portrait 모델의 첫 번째 단계인 Image-to-Plane (I2P) 모델의 사전 학습(pretraining) 과정을 보여준다. 이 단계의 목표는 단일 입력 이미지로부터 정확한 3D 얼굴 표현(tri-plane)을 재구성하는 방법을 I2P 모델에 학습시키는 것이다.
-
Fixed Part (고정된 부분)
- : 이는 표준 정규 분포에서 샘플링된 잠재 코드(latent code)이다. I2P 모델 사전 학습 과정에서 3D GAN인 EG3D가 다양한 사람의 얼굴을 합성하기 위한 무작위 입력으로 사용된다.
- EG3D Tri-plane Generator: 이 모듈은 잠재 코드 를 입력받아 3D 얼굴의 Tri-plane 표현을 생성한다. EG3D는 3D 생성 모델로, 다양한 신원(identity)을 가진 고품질 3D 얼굴을 생성할 수 있다. 이 생성기는 사전 학습된 상태로 고정되어(frozen) 있다.
- Tri-plane: EG3D Tri-plane Generator가 생성한 3D 얼굴 표현이다. 얼굴의 형상(geometry)과 외형(appearance) 정보를 3개의 평면(tri-plane) 형태로 인코딩한다.
- EG3D Volume Renderer + SR: 이 모듈은 Tri-plane과 특정 카메라 포즈(reference camera, target camera)를 입력으로 받아, 해당 시점(viewpoint)에서 얼굴 이미지를 렌더링하고 고해상도(Super-Resolution, SR)로 업스케일링한다. 이 모듈 또한 사전 학습된 상태로 고정되어 있다.
- Reference camera, Target camera: 각각 기준 이미지()와 목표 이미지()를 렌더링하는 데 사용되는 가상의 카메라 포즈이다.
- Reference image : Reference camera 시점에서 EG3D Volume Renderer + SR을 통해 렌더링된 이미지이다. 이 이미지는 Image-to-Plane 모델의 입력으로 사용된다.
- Target image : Target camera 시점에서 EG3D Volume Renderer + SR을 통해 렌더링된 이미지이다. 이 이미지는 학습 과정에서 예측된 이미지()와 비교되는 Ground Truth 이미지로 사용된다.
-
Learnable Part (학습 가능한 부분)
- Image-to-Plane Model: 이 모델은 학습 대상이 되는 핵심 네트워크이다. Reference image()를 입력받아 대상 인물의 정규 3D Tri-plane 표현을 재구성하는 것을 목표로 한다. 이 모델은 Vision Transformer (ViT)와 VGG 브랜치를 결합한 하이브리드 구조로 이루어져 있다.
- Reconstructed tri-plane: Image-to-Plane 모델이 Reference image로부터 예측한 Tri-plane 표현이다.
- Volume Renderer + SR: Reconstructed tri-plane과 Target camera 포즈를 입력받아 예측된 이미지()를 렌더링하고 고해상도로 업스케일링한다. 이 모듈은 사전 학습 단계에서 EG3D의 Volume Renderer + SR 모듈에서 가중치를 초기화하며, I2P 모델 학습과 함께 업데이트된다.
- Predicted image : Reconstructed tri-plane을 Target camera 시점에서 렌더링하여 얻은 최종 이미지이다. 이 이미지는 Target image()와 비교되어 모델 학습에 사용된다.
- 손실 함수 (Loss Functions):
- L1 loss (Mean Absolute Error): Predicted image와 Target image 사이의 픽셀 단위 차이를 측정한다.
- VGG loss, VGGFace loss (Perceptual Loss): 미리 학습된 VGG19 📄 Very Deep Convolutional Networks for Large-Scale Image Recognition 및 VGGFace 📄 Deep Face Recognition 네트워크의 특징 맵(feature map) 간의 차이를 측정하여 시각적 유사성을 확보한다.
- Dual Adv. loss (Dual Adversarial Loss): 📄 Efficient Geometry-aware 3D Generative Adversarial Networks에서 제안된 손실 함수로, 이미지의 충실도(fidelity)와 시점 일관성(view consistency)을 향상시킨다.
이 과정의 목적: I2P 모델은 EG3D와 같은 강력한 3D GAN으로부터 3D 사전 지식(prior knowledge)을 증류(distill)하여, 단일 2D 이미지로부터 고품질의 3D 얼굴 표현을 효율적으로 재구성하는 능력을 학습하는 것이다. 이는 나중에 얼굴 애니메이션과 같은 다운스트림 작업의 기반이 된다.
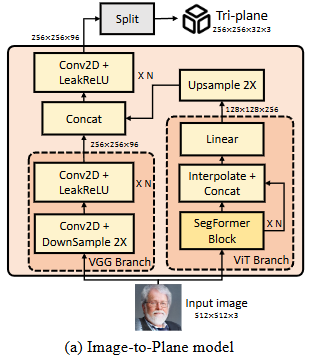
- (a) Image-to-Plane (I2P) 모델 세부 구조
- 목적: 단일 입력 이미지에서 3D 아바타의 정규(canonical) Tri-plane 표현을 재구성하는 모델이다. 이 모델은 I2P 모델의 사전 학습 단계에서 3D GAN인 EG3D로부터 3D 사전 지식(prior knowledge)을 주입받아 얼굴 재구성 능력을 향상하였다.
- 입력: 크기의 소스 이미지()이다.
- 출력: 크기의 Tri-plane이다. 이 Tri-plane은 세 개의 평면으로 구성되어 3D 장면의 형상 및 외관 정보를 인코딩한다.
- 구성:
- VGG Branch: 고주파 외관 특징을 추출하는 역할을 한다. 여러 개의 Conv2D 및 LeakReLU 레이어로 구성되며, DownSample 2X 레이어를 포함한다. VGG Branch에서는 신원(identity)에 특화된 외관 관련 편향(bias)을 유지하기 위해 모든 정규화(normalization)가 제거되었다.
- ViT Branch: 픽셀 좌표를 월드 좌표로 변환하는 데 필요한 어텐션(attention)을 효율적으로 처리한다. SegFormer Block 스택으로 구성되며, Linear 및 Interpolate + Concat 연산을 통해 특징을 결합한다.
- 특징 융합: 두 브랜치의 출력 특징 맵( 및 )은 Concatenate 연산을 통해 융합되고, 이후 추가적인 Conv2D 및 LeakReLU 레이어를 거쳐 Tri-plane을 생성한다. Upsample 2X 연산은 해상도를 맞추는 역할을 한다.
2.2. Efective Facial Motion Adapter
2.2.1. PNCC based Motion Representation
-
PNCC의 정의
- PNCC는 '자세/외모 비의존적(pose/appearance-agnostic)' 특징 맵이다.
- 이는 특정 얼굴 자세나 외모 특징에 얽매이지 않고, 얼굴의 미세한 표정 정보만을 담고 있다.
- 3DMM(3D Morphable Model) 얼굴 모델을 기반으로 얼굴 표정 정보를 상세하게 표현한다.
-
PNCC 획득 과정
- PNCC는 Projected Normalized Coordinate Code를 의미한다. 이는 얼굴의 기하학적 형태를 나타내는 2D 이미지 형태의 특징이다.
- 특정 얼굴에 대한 신원 코드()와 표정 코드() 쌍이 주어지면, 우선 이 정보로 3DMM 얼굴 메쉬를 생성한다.
- 생성된 3DMM 얼굴 메쉬를 '표준 자세(canonical pose)'로 설정한다. 표준 자세는 얼굴의 기준이 되는 디폴트 파라미터의 중립적인 자세를 의미한다.
- Z-Buffer 알고리즘을 사용하여 이 메쉬를 래스터화(rasterizing)한다. Z-Buffer는 3D 객체의 깊이 정보를 이용하여 화면에 보이는 부분을 결정하는 그래픽 렌더링 기술이다.
- 이때 NCC(Normalized Coordinate Code)를 '컬러 맵(colormap)'으로 활용한다. NCC는 3DMM 메쉬의 각 정점(vertex)에 정규화된 3D 좌표값을 부여한 것으로, 이를 색상처럼 사용하여 얼굴의 기하학적 구조를 시각적으로 표현한다.
-
수식
- PNCC를 얻기 위한 수식은 다음과 같다.
- : Z-Buffer 알고리즘을 의미한다. 이는 컴퓨터 그래픽스에서 3D 장면을 2D 이미지로 렌더링할 때, 깊이(depth) 정보를 이용하여 어떤 객체가 카메라에 더 가까운지 판단하고 보이는 부분만 그리는 방법이다. 여기서는 3DMM 메쉬를 2D PNCC 이미지로 변환하는 데 사용된다.
- : 3DMM 얼굴 메쉬의 3D 정점들을 의미한다. 이 정점들은 80차원의 identity code 와 64차원의 expression code 에 의해 결정된다.
- : Normalized Coordinate Code를 의미한다. 이는 3DMM 메쉬의 각 정점에 고유한 3차원 좌표 값을 색상처럼 할당한 것으로, Z-Buffer 알고리즘에서 colormap 역할을 한다.
- 는 3DMM 모델의 파라미터들로 다음과 같이 구성된다.
- : 3DMM 모델의 템플릿 형태(template shape)를 의미한다. 이는 평균적인 얼굴의 3D 형태이다.
- : 3DMM 모델의 identity basis를 의미한다. 이는 개인의 고유한 얼굴 특징을 나타내는 기저(basis)이다.
- : 80차원의 identity code를 의미한다. 이는 특정 인물의 신원(identity)을 나타내는 계수 벡터로, 와 선형 결합하여 개인의 고유한 얼굴 형태를 만든다.
- : 3DMM 모델의 expression basis를 의미한다. 이는 다양한 얼굴 표정(expression)을 나타내는 기저이다.
- : 64차원의 expression code를 의미한다. 이는 특정 표정을 나타내는 계수 벡터로, 와 선형 결합하여 표정 변화를 만든다.
-
Identity-agnostic motion-conditioned face animation의 개념: 3DMM은 얼굴을 정체성(외형)과 표정(움직임)으로 분리하여 표현하는 모델이다. 이러한 특성 덕분에 PNCC를 사용하여 특정 인물의 외형(identity)에 구애받지 않고, 입력되는 표정(motion) 정보에 따라 얼굴 애니메이션을 만들 수 있다. 이는 다양한 사람의 얼굴에 동일한 표정 변화를 적용할 수 있게 해준다.
-
학습(Training) 과정:
- 모델을 학습할 때는 실제 학습 비디오에서 3DMM 파라미터(특히 표정 계수 )를 추출한다.
- 이 파라미터들을 사용하여
ground truth PNCC를 생성하는데, 이는 비디오 내의 실제 얼굴 표정 움직임을 나타낸다.
-
추론(Inference) 과정:
- 추론 시에는 최종적으로 얼굴 애니메이션을 만들 driving PNCC ()를 구성한다. 이는 다음의 공식으로 표현된다.
- : 3D Morphable Model (3DMM)을 사용하여 3D 얼굴 메시(mesh)를 생성하는 함수이다.
- : Source image(원본 이미지)에서 추출한
identity coefficient이다. 이는 원본 인물의 고유한 외형(얼굴형, 피부 텍스처 등)을 나타내는 고정된 계수이다. - : Driving
expression coefficient이다. 이는 구동(driving) 비디오에서 추출되거나,audio-to-motion model(Sec. 3.4)을 통해 입력 오디오로부터 예측되는 표정 정보를 나타내는 계수이다.
- : Source image(원본 이미지)에서 추출한
2.2.2. Residual Motion-diff Plane
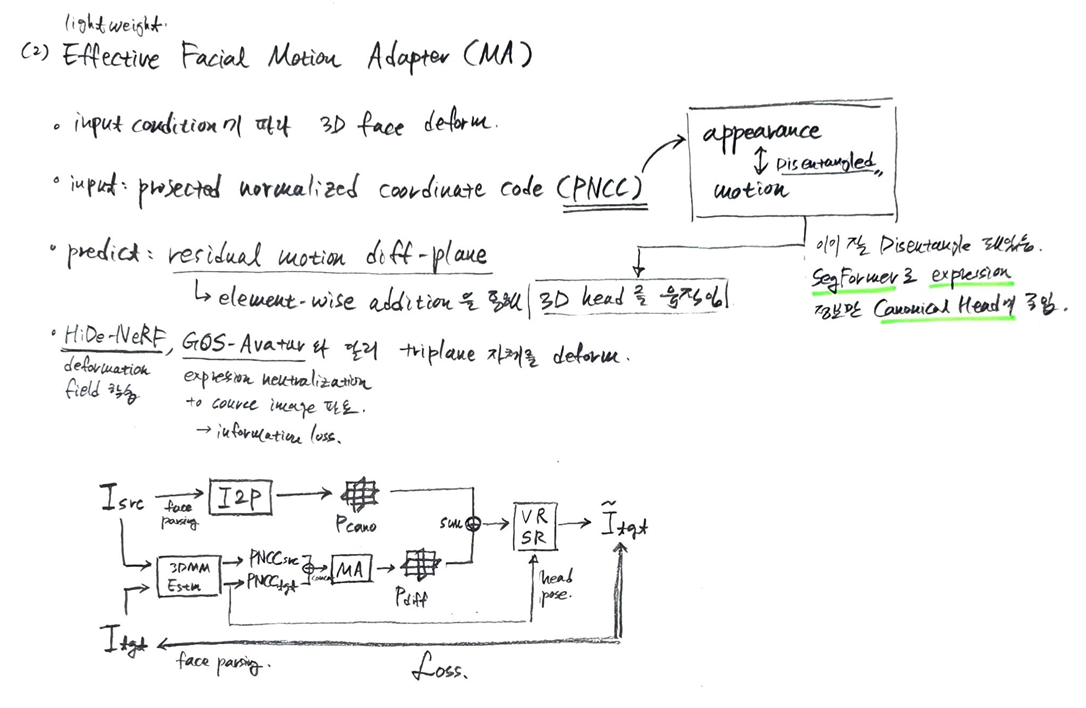
이 섹션은 3D 표현에 모션 조건을 어떻게 주입하여 얼굴 표정을 제어하는지에 대해 설명하고 있다.
-
기존 방식의 한계: 기존의 방식들(예: HiDe-NeRF)은 변형 필드(deformation field)를 사용하여 3D 모델을 변형시켰으나, 이는 예측된 메시(mesh)의 품질 저하로 이어지는 경우가 많았다.
-
새로운 접근 방식: 이 논문에서는 잘 훈련된 Image-to-Plane (I2P) 모델이 정확한 기하학적/텍스처 정보를 가진 3D 표현을 생성하면, 그 위에 가벼운 Motion Adapter (MA)를 사용하여 잔여 모션 diff-plane인 를 예측한다.
- 이 는 정규화된 tri-plane인 에 미세한 기하학적 변화만을 편집하여 다른 모션 조건에 대응하도록 한다.
-
애니메이션 과정:
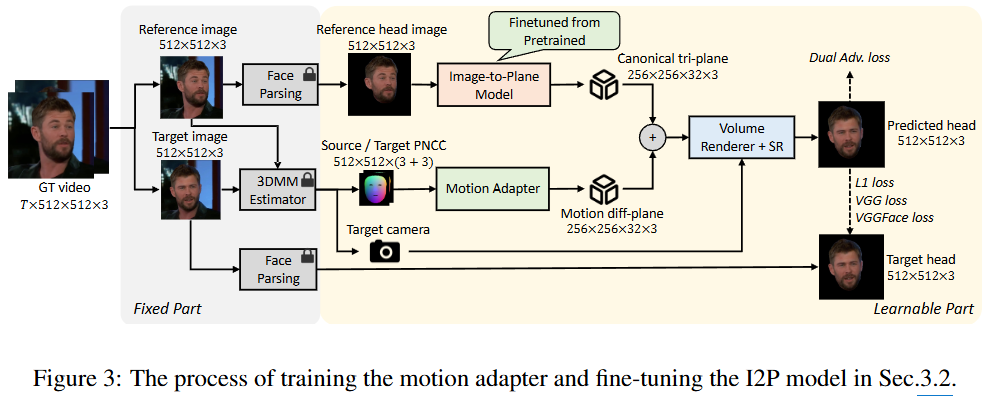
위 이미지는 논문의 공식 파이프라인이나, 기술된 수식이 포함되어있지 않아 아래 직접 그린 그림으로 보충한다.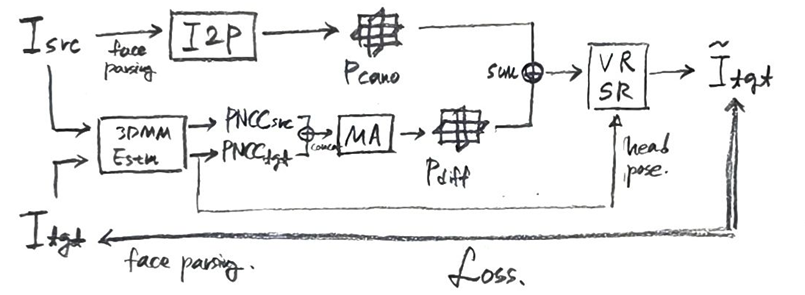
원본 이미지 와 입력 모션 조건 , 카메라 포즈 이 주어졌을 때, 최종 애니메이션된 이미지 는 다음과 같이 표현된다. (그림의 를 와 동일한 의미로, 를 과 동일한 의미로 이해하면 된다.)
- : 최종 렌더링될 구동(driving) 이미지이다.
- : Super-Resolution 모듈이다. Volume Renderer가 생성한 저해상도 이미지를 고해상도로 변환하는 역할을 한다. Off-the-shelf 모델의 구조를 그대로 따른다.
- : Volume Renderer이다. 3D 표현을 2D 이미지로 렌더링하는 모듈로, NeRF에서 제안한 구조를 그대로 따른다.
- : I2P 모델이 소스 이미지로부터 재구성한 정규화된(canonical) 3D 얼굴 표현인 tri-plane이다. 이는 얼굴의 기본적인 모양과 텍스처 정보를 담고 있다.
- : Motion Adapter (MA)가 예측하는 잔여(residual) 모션 diff-plane이다. 이 diff-plane은 에 더해져 얼굴 표정의 변화를 반영한다.
- : 타겟 카메라 포즈이다. 렌더링 시 얼굴의 방향과 위치를 결정한다.
- : Image-to-Plane 모델이다. 소스 이미지 를 입력으로 받아 를 생성한다.
- : 입력으로 주어지는 원본(source) 이미지이다.
- : Motion Adapter이다. 구동 모션 조건 와 소스 이미지의 PNCC인 를 concat 된 입력으로 받아 를 예측한다. (소스 이미지와 구동 조건의 PNCC를 모두 알아야 올바른 잔차 모션을 구할 수 있기 때문이다.)
- : 구동 모션 조건이다. 이는 수식 (1)에서 정의된 Projected Normalized Coordinate Code (PNCC)를 의미한다. PNCC는 포즈/외형에 독립적인 미세한 얼굴 표정 정보를 나타낸다.
- : 소스 이미지에서 추출한 PNCC이다.
-
Motion Adapter (MA)의 구조:
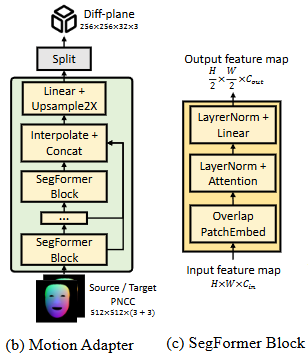
-
(b) Motion Adapter (MA)
- 목적: I2P 모델로 재구성된 정규 Tri-plane에 표정(expression)과 움직임(motion) 조건을 주입하여, 원하는 얼굴 애니메이션을 구현하는 경량 모델이다. 이 모델은 PNCC를 기반으로 Tri-plane의 기하학적 변화를 최소한으로 편집하는 residual motion diff-plane을 예측한다.
- 입력: 크기의 Source/Target PNCC(Projected Normalized Coordinate Code)이다. PNCC는 얼굴 기하학에만 관련되는 외관 비의존적 특징 맵으로, 3DMM 얼굴 메시를 정규 포즈(canonical pose)에서 Z-Buffer 알고리즘을 사용하여 렌더링하여 얻는다.
- 출력: 크기의 Motion diff-plane이다. 이 diff-plane은 정규 Tri-plane에 요소별 덧셈(element-wise addition)으로 적용되어 애니메이션을 만든다.
- 구성: SegFormer Block 스택으로 구성되어 있으며, 효율적인 크로스-코디네이트 변환(cross-coordinate transform)을 위해 attention over feature map patches를 활용한다. Linear + Upsample 2X 및 Interpolate + Concat 연산을 통해 특징을 처리한다.
-
(c) SegFormer Block
- 목적: ViT Branch 및 Motion Adapter에 사용되는 기본 구성 블록이다. SegFormer는 효율성이 높고, 피처 맵 패치(feature map patches)에 대한 어텐션(attention)을 통해 교차 좌표 변환(cross-coordinate transform)을 잘 처리하는 능력이 뛰어나다.
- 입력: 크기의 입력 특징 맵이다.
- 출력: 크기의 출력 특징 맵이다.
- 구성:
- Overlap PatchEmbed: 입력 특징 맵에서 겹치는 패치(patch)를 추출하고 임베딩한다.
- LayerNorm + Attention: 패치 간의 어텐션을 수행하여 장거리 의존성(long-range dependencies)을 포착한다.
- LayerNorm + Linear: 어텐션 결과를 변환하고 정규화한다.
-
2.2.3. Training Process
이 단계의 학습 과정은 모션 어댑터(Motion Adapter)를 처음부터 학습하는 것과, I2P(Image-to-Plane) 모델 및 볼륨 렌더러(Volume Renderer)/슈퍼 레졸루션(Super-Resolution, SR) 모듈을 사전 학습된 가중치에서 미세 조정하는 것을 포함한다.
- 데이터셋 활용: 모델은 CelebV-HQ: A Large-Scale Video Facial Attributes Dataset와 같은 대규모 고충실도 토킹 페이스 비디오 데이터셋으로 학습된다.
- 학습 데이터 쌍 구성: 학습 데이터 쌍을 만들기 위해 비디오에서 무작위로 두 프레임을 선택하여, 이를 각각 소스 이미지 와 타겟 이미지 로 정의한다.
- 전처리: 카메라 포즈는 주로 머리 움직임과 밀접하게 관련되어 있으므로, 이 단계에서는 머리 영역만을 고려하며, 모든 이미지는 얼굴 파싱(face parsing) 모델을 사용하여 머리 부분을 추출하는 방식으로 전처리된다.
- I2P 모델 입력 및 재구성: 소스 머리 이미지 는 I2P 모델에 입력되어 캐노니컬 트라이-플레인 를 재구성한다.
- 모션 어댑터 입력 및 잔여 디프-플레인 획득: 타겟 이미지 에서 추출된 는 모션 어댑터 MA에 입력되어 잔여 모션 디프-플레인 를 얻는다.
- 예측 이미지 생성: 이 정보를 바탕으로, Equation 2에 따라 예측 이미지 를 생성한다.
이 단계의 학습 손실 은 다음과 같이 정의된다.
- : 전체 학습 손실을 나타낸다.
- : L1 손실이다.
- 예측된 이미지 와 실제 이미지 사이의 픽셀별 절대 차이의 합을 계산한다.
- 이는 이미지의 전반적인 충실도(fidelity)를 높이는 데 기여한다.
- : VGG19/Deep Face Recognition 기반의 지각 손실(perceptual loss)이다.
- 두 이미지의 특징 표현(feature representation) 사이의 유사성을 측정하여, 픽셀 단위의 유사성뿐만 아니라 이미지의 내용(content) 및 스타일(style) 측면에서도 유사성을 확보하는 데 사용된다.
- : Efficient Geometry-aware 3D Generative Adversarial Networks에서 제안된 듀얼 적대적 손실(dual adversarial loss)이다.
- 생성된 이미지의 현실감과 일관성을 개선하는 데 사용되는 적대적 학습 기반의 손실이다.
- : 라플라시안 손실(Laplacian loss)이다.
- 인접 프레임의 모션 디프-플레인(motion diff-planes)에 적용되는 정규화(regularization) 항이다.
- 생성된 비디오에서 시간적 지터링(temporal jittering), 즉 프레임 간의 불규칙한 떨림 현상을 줄이는 데 목적이 있다.
라플라시안 손실 는 다음과 같이 정의된다.
- : 라플라시안 손실을 나타낸다.
- : Motion Adapter (MA)가 현재 시점 의 PNCC()를 입력받아 예측한 잔여 모션 디프-플레인(residual motion diff-plane)이다.
- : Motion Adapter (MA)가 이전 시점 의 PNCC()를 입력받아 예측한 잔여 모션 디프-플레인이다.
- : Motion Adapter (MA)가 다음 시점 의 PNCC()를 입력받아 예측한 잔여 모션 디프-플레인이다.
- : 이전 프레임()과 다음 프레임()의 잔여 모션 디프-플레인 평균을 의미한다.
- : L2 노름(norm)의 제곱으로, 현재 프레임의 디프-플레인과 인접 프레임 디프-플레인 평균 간의 유클리드 거리를 측정하여 시간적 부드러움(temporal smoothness)을 강제하는 역할을 한다. 즉, 현재 프레임의 모션이 이전 및 다음 프레임의 모션과 크게 다르지 않아야 한다고 모델에 알려준다.
2.3. Natural Torso Movement & Changeable Background
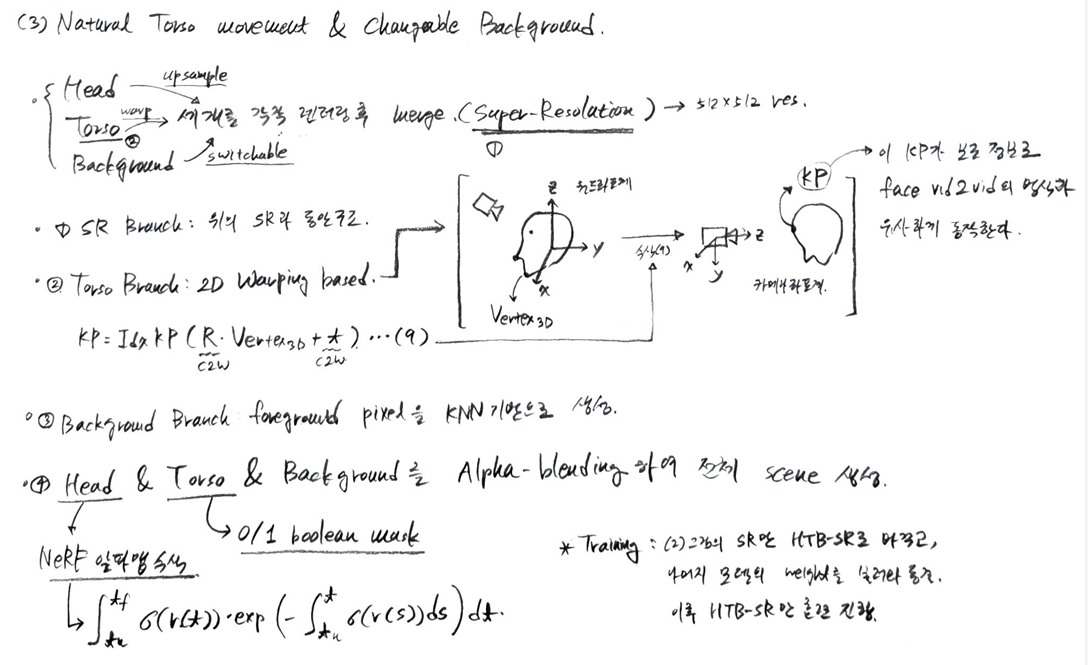
2.4. Audio-to-Motion Model
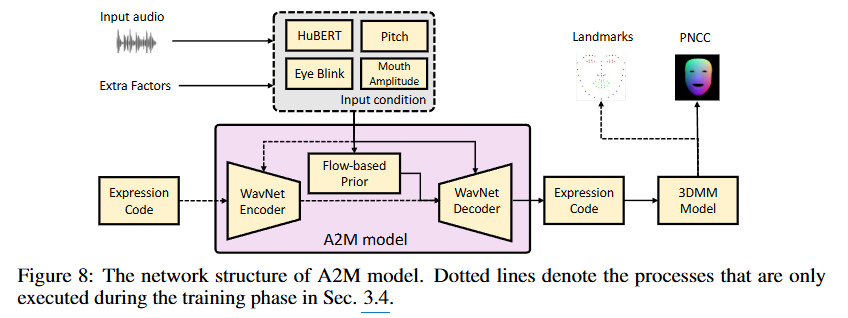
이 이미지는 음성 신호를 기반으로 3D 얼굴 표정(facial motion)을 생성하는 A2M (Audio-to-Motion) 모델의 상세한 네트워크 구조를 보여준다. 이 구조는 GeneFace 논문과 매우 유사하니, 더 깊은 이해가 필요하면 해당 논문을 읽어보자.
-
Input audio (입력 오디오)
- 사용자가 제공하는 원본 오디오 신호이다. 이 오디오는 말하는 얼굴 영상(talking portrait video)을 구동하는 데 사용되는 주요 입력이다.
-
Extra Factors (추가 요인)
- 생성되는 얼굴 움직임을 더욱 세밀하게 제어하기 위한 보조 입력들이다.
- HuBERT: 입력 오디오에서 추출된 음성 특징(speech features)이다. HuBERT HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units는 마스크된 음성 단위를 예측하여 자기 지도 방식으로 음성 표현을 학습하는 모델이다.
- Pitch: 오디오 신호에서 추출된 음성의 높낮이(fundamental frequency) 정보이다. 이는 음성의 억양과 같은 운율적 특징을 포착한다.
- Eye Blink: 눈 깜빡임과 관련된 제어 정보이다. 사용자가 원하는 눈 깜빡임 패턴을 명시적으로 제어할 수 있게 한다.
- Mouth Amplitude: 입 움직임의 크기(진폭)와 관련된 제어 정보이다. 입술 움직임의 강도를 조절하는 데 사용된다.
- 이 모든 요소들은 통합되어 A2M 모델의 'Input condition'을 형성한다.
- 생성되는 얼굴 움직임을 더욱 세밀하게 제어하기 위한 보조 입력들이다.
-
A2M model (분홍색 상자)
- 오디오와 추가 요인들을 얼굴 표정 코드로 변환하는 핵심 모델이다. 이 모델은 VAE (Variational Auto-Encoder) 구조에 흐름 기반(flow-based) 프라이어(prior)를 결합한 형태이다.
- Expression Code (입력): A2M 모델의 WavNet Encoder에 입력되는 표정 코드이다. 이는 3DMM 모델의 64차원 표정 계수()를 나타내며, 모델 학습 시 사용되는 실제 표정 정보이다.
- WavNet Encoder: 입력 Expression Code를 잠재 공간(latent space) 표현으로 인코딩한다. WavNet은 시퀀스 데이터 처리에 강점을 가진 신경망 아키텍처이다.
- Flow-based Prior: VAE의 잠재 변수 분포를 모델링하고 강화하는 데 사용되는 흐름 기반 모델이다. 이는 잠재 공간의 표현력을 높여 더 정확하고 다양한 표정 생성을 가능하게 한다.
- WavNet Decoder: WavNet Encoder의 출력(잠재 코드)과 Input condition을 입력받아 새로운 Expression Code를 디코딩한다.
- Expression Code (출력): A2M 모델의 최종 출력으로, 입력 오디오와 Extra Factors에 상응하는 3DMM 표정 계수() 시퀀스이다.
- 점선 화살표: 훈련 단계에서만 사용되는 연결을 나타낸다. 예를 들어, 인코더의 출력이 Flow-based Prior로 입력되고, Input condition이 디코더로 직접 연결되는 것은 훈련 시 VAE의 손실 함수(특히 KL divergence와 재구성 손실) 계산에 기여하는 부분이다. 본 논문에서는 와 같은 손실 함수를 사용하여 모델을 훈련한다.
-
3DMM Model (3D Morphable Model)
- A2M 모델에서 출력된 Expression Code()를 기반으로 3D 얼굴 메시를 재구성하는 데 사용된다. A morphable model for the synthesis of 3d faces
- 이 모델은 주어진 Expression Code와 함께 소스 이미지에서 추출된 Identity Code()를 사용하여 얼굴의 3D 형태를 정의한다. 3DMM의 꼭짓점()은 다음과 같이 표현된다.
- : 기본 3D 얼굴 형태이다.
- : 각각 얼굴 정체성(identity)과 표정(expression)의 기저(basis)이다.
- : 각각 Identity Code와 Expression Code이다.
- 이 재구성된 3D 얼굴 메시를 사용하여 다음 두 가지를 얻는다.
- Landmarks (랜드마크): 재구성된 3DMM 얼굴 꼭짓점에서 68개 또는 468개의 얼굴 랜드마크를 추출한다. 이는 얼굴 움직임을 정량적으로 평가하거나 보조 감독 신호로 활용된다. How Far are We from Solving the 2D & 3D Face Alignment Problem? (and a Dataset of 230,000 3D Facial Landmarks)
- PNCC (Projected Normalized Coordinate Code): 3DMM 메시를 표준 포즈에서 래스터화하여 얻는 2D 이미지이다. PNCC는 얼굴의 3D 기하학적 형태와 표정 정보를 포즈나 외형과 독립적으로 표현하며, 모션 어댑터(Motion Adapter)의 입력으로 사용되는 핵심 모션 표현이다.
2.4.1. 훈련 (Training) 과정 (점선 포함)
훈련 과정의 목표는 입력 오디오와 추가 요인으로부터 정확하고 표현력 있는 3DMM 표정 코드()를 예측하는 A2M 모델을 학습하는 것이다. A2M 모델은 Flow-enhanced VAE (Variational Auto-Encoder) 구조를 따른다.
-
입력 준비:
- 훈련 데이터셋(예: CelebV-HQ, VoxCeleb2)에서 추출된 Input audio를 HuBERT 모델로 처리하여 음성 특징을 추출하고, 오디오에서 Pitch 정보를 추출한다.
- 훈련 데이터셋의 비디오 프레임에서 3DMM 피팅을 통해 추출된 Ground Truth(GT) Expression Code()와 해당 프레임의 눈 깜빡임(Eye Blink), 입 움직임의 진폭(Mouth Amplitude)과 같은 Extra Factors를 준비한다.
- 이러한 정보들(HuBERT, Pitch, Eye Blink, Mouth Amplitude)이 합쳐져 Input condition을 형성한다.
- 또한, GT Expression Code()를 3DMM 모델을 통해 Landmarks와 PNCC로 변환하여, 예측된 값과 비교하는 보조 감독 신호(auxiliary supervision signal)로 사용한다.
-
A2M 모델의 VAE 학습:
- GT Expression Code(, 그림 왼쪽)가 WavNet Encoder에 입력되어 잠재 표현()으로 인코딩된다.
- 인코딩된 잠재 표현()은 Flow-based Prior로 전달된다. Flow-based Prior는 VAE의 잠재 공간 분포를 학습하고, KL divergence 손실() 계산에 사용된다. 이 과정에서 잠재 공간이 의미 있는 구조를 갖도록 유도된다.
- Flow-based Prior의 출력(혹은 샘플링된 잠재 코드)과 Input condition이 WavNet Decoder에 입력된다. Decoder는 이 정보들을 바탕으로 표정 코드()를 재구성하려고 시도한다.
- Decoder의 출력인 예측된 Expression Code()는 GT Expression Code()와 비교되어 재구성 손실()을 계산한다.
- 또한, 를 3DMM Model에 입력하여 예측된 Landmarks()를 얻고, 이를 GT Landmarks()와 비교하여 랜드마크 재구성 손실()을 계산한다. 이 손실은 얼굴 랜드마크의 정확도를 높이는 데 기여한다.
- 연속된 프레임의 예측된 Expression Code 시퀀스에는 라플라시안 손실()을 적용하여 시간적 떨림(temporal jittering)을 줄이고 부드러운 움직임을 유도한다.
2.4.2. 추론 (Inference) 과정 (실선만)
추론 과정의 목표는 새로운 오디오 입력과 원하는 추가 제어 값으로부터 3D 얼굴 표정 코드를 생성하는 것이다. 이 단계에서는 모델이 이미 훈련되어 고정된 상태이다.
-
입력 준비:
- 새롭게 주어지는 Input audio에서 HuBERT 특징과 Pitch 정보를 추출한다.
- 사용자가 제어하고자 하는 Extra Factors (Eye Blink, Mouth Amplitude)를 설정한다. 예를 들어, 눈을 깜빡이거나 입을 크게 움직이도록 지시할 수 있다.
- 이 모든 정보들이 통합되어 Input condition을 형성한다.
-
A2M 모델을 통한 표정 코드 생성:
- Input condition은 직접 Flow-based Prior에 입력된다. 훈련 시 학습된 Prior는 Input condition에 조건화되어 표현력 있는 잠재 코드를 생성한다. 이는 모델이 오디오와 제어 신호에 따라 적절한 표정 코드를 생성할 수 있도록 한다.
- Flow-based Prior에서 생성된 잠재 코드는 WavNet Decoder로 전달된다.
- Decoder는 이 잠재 코드를 기반으로 오디오와 추가 요인에 상응하는 예측된 Expression Code()를 출력한다.
-
3D 얼굴 모션 변환:
- A2M 모델에서 출력된 Expression Code()는 3DMM Model에 입력된다. (이때, 3DMM Model은 Source Image에서 추출된 Identity Code()와 결합하여 3D 얼굴 메시를 정의한다.)
- 3DMM Model은 Expression Code를 바탕으로 3D 얼굴 메시를 재구성하고, 이로부터 얼굴 Landmarks (예: 468개 랜드마크)를 추출할 수 있다.
- 또한, 재구성된 3DMM 메시를 Z-버퍼링(Z-Buffer) 기법과 표준화된 좌표 코드(NCC)를 사용하여 PNCC (Projected Normalized Coordinate Code) 이미지로 렌더링한다. PNCC는 외형에 독립적인 정밀한 얼굴 표정 정보를 나타내는 핵심적인 모션 표현이며, 이후 3D 얼굴 애니메이션(Motion Adapter)의 입력으로 사용된다.
요약하자면, 훈련 단계에서는 Ground Truth Expression Code를 통해 A2M 모델의 Encoder-Flow-Decoder 파이프라인을 학습시키고, 추론 단계에서는 학습된 모델이 Input condition만으로 Expression Code를 생성하여 이를 3DMM 모델을 통해 PNCC 및 랜드마크로 변환하는 방식으로 동작한다.
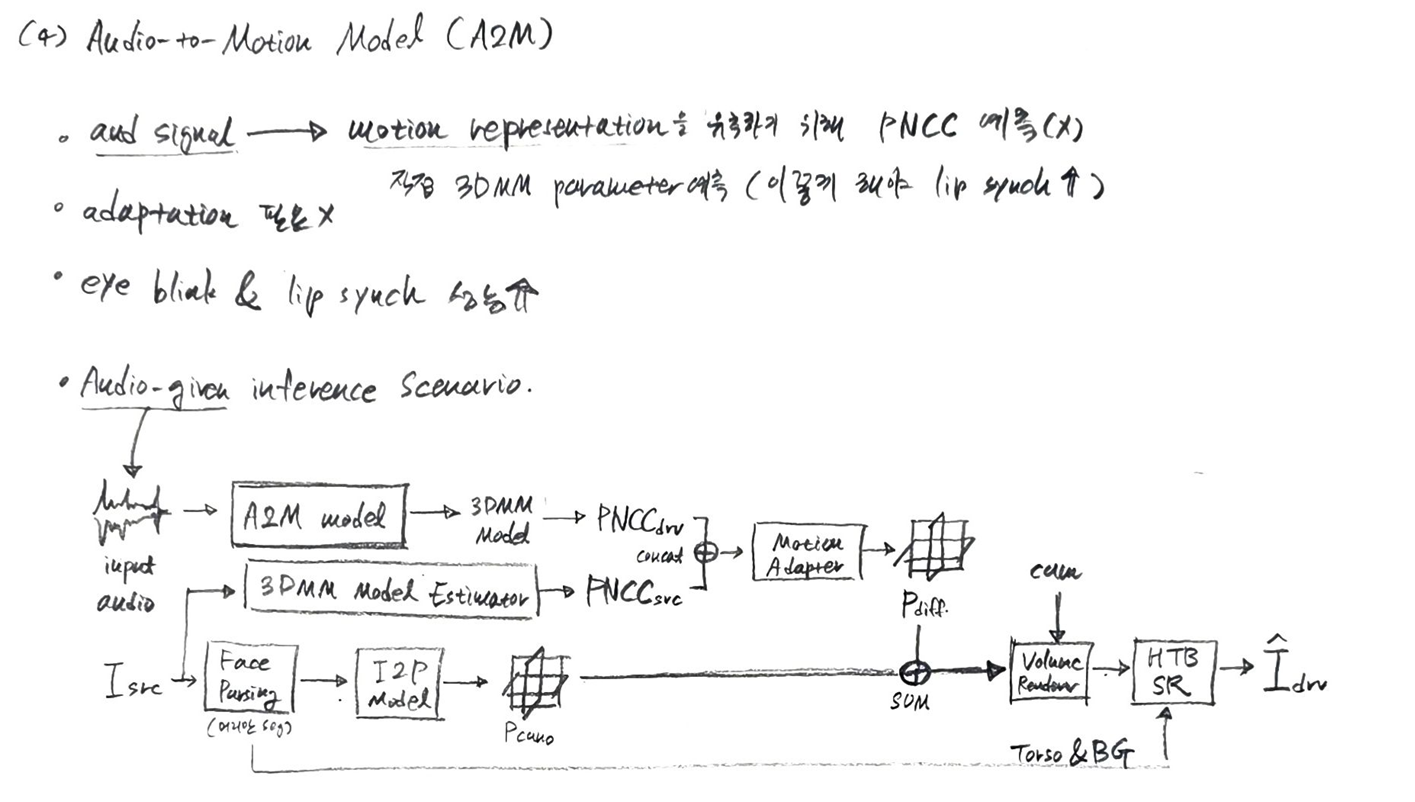
Audio-driven으로 토킹 헤드를 생성하는 전체 파이프라인은 위와 같다.
3. Experiment
3.1. Experimental Setting
이 섹션은 제안하는 Real3D-Portrait 모델의 실험 환경 및 설정에 대해 설명한다.
-
데이터 준비 (Data Preparation)
- I2P 모델 사전 학습: EG3D, 즉 3D 얼굴 생성 모델을 사용하여 학습 중 다양한 합성 인물의 tri-plane을 생성하고 다중 뷰 이미지 쌍을 온라인으로 생성한다.
- 모션 어댑터 및 HTB-SR 모델 학습: CelebV-HQ 데이터셋을 사용한다. 이 데이터셋은 약 65시간 분량의 고화질(512x512 해상도) 말하는 얼굴 비디오 클립 35,666개와 15,653명의 인물을 포함한다.
- A2M 모델 학습: VoxCeleb2 데이터셋을 사용한다. 이 데이터셋은 저화질이지만 2,000시간에 달하는 대규모 립 리딩(lip-reading) 데이터셋으로, 오디오-모션 매핑의 일반화 능력을 보장한다.
- 전처리: 비디오 프레임은 상용 랜드마크 추출기(MediaPipe)와 얼굴 파서로 전처리된 후, 투영된 랜드마크 오차를 기반으로 3DMM 파라미터가 피팅된다. 오디오 트랙에서는 HuBERT 특징과 피치 윤곽선이 추출된다.
-
비교 기준선 (Compared Baselines)
- Real3D-Portrait는 여러 비디오/오디오 구동(video/audio-driven) 기준 모델과 비교되었다.
- Face-vid2vid (Wang et al., 2021): 널리 사용되는 워핑 기반 비디오 구동 말하는 얼굴 시스템이다.
- OT-Avatar (Ma et al., 2023): 사전 학습된 3D GAN을 활용하는 최근의 one-shot 비디오 구동 방식이다.
- HiDe-NeRF (Li et al., 2023a): 변형 필드를 사용하여 얼굴 애니메이션을 수행하는 최신 one-shot 3D 말하는 얼굴 시스템이다.
- MakeItTalk (Zhou et al., 2020) 및 PC-AVS (Zhou et al., 2021): 오디오-립 동기화를 잘 달성하는 두 가지 one-shot 오디오 구동 말하는 얼굴 방법이다.
- RAD-NeRF (Tang et al., 2022): NeRF 기반 방법으로, 특정 인물 비디오에 과적합(over-fitting)하여 높은 현실적인 품질을 달성한다. 이 방법은 one-shot 방법과 비교하기에는 불공정하지만, 최신 인물별(person-specific) 방법의 성능과 Real3D-Portrait의 성능 간의 격차를 보여주기 위해 포함되었다.
- Real3D-Portrait는 여러 비디오/오디오 구동(video/audio-driven) 기준 모델과 비교되었다.
3.2. Quantitative Evaluation
정량적 평가는 Real3D-Portrait 모델의 성능을 수치적인 지표를 사용하여 평가하는 부분이다. 모델이 비디오 및 오디오 구동 환경에서 어떻게 작동하는지 비교 평가한다.
-
비디오 구동 동일/교차 아이덴티티 재연 (Video-driven same/cross-identity reenactment)
- 목표: 참조 비디오에서 움직임(motion)과 헤드 포즈(head pose)를 얻어 3D 아바타를 재연하는 것이다.
- 설정:
- 동일 아이덴티티 (Same-identity): 참조 비디오의 첫 프레임을 소스 이미지로 사용한다. 즉, 생성되는 아바타는 소스 이미지와 동일 인물이다.
- 교차 아이덴티티 (Cross-identity): 소스 이미지가 참조 비디오와 다른 인물이다. 생성되는 아바타는 소스 이미지의 인물에 참조 비디오의 움직임을 적용한다.
- 평가 지표:
- 동일 아이덴티티: (픽셀 차이), (최대 신호 대 잡음비), (구조적 유사성), (지각적 거리), (프레셰 시작 거리), (아이덴티티 임베딩의 코사인 유사도), (평균 표정 거리), (평균 포즈 거리), (평균 키포인트 거리) 등을 사용하여 이미지 품질, 아이덴티티 보존, 애니메이션 정확도를 평가한다.
- 교차 아이덴티티: Ground Truth (GT)가 없으므로 , , , 등을 사용하여 아이덴티티 보존, 이미지 품질, 애니메이션 정확도를 평가한다.
- 결과: Real3D-Portrait (VD)는 측면에서 가장 우수한 이미지 품질을 보였다. 또한, 가장 높은 을 달성하여 소스 이미지의 아이덴티티를 잘 보존하는 것을 보여주었다. 에서도 가장 좋은 성능을 기록하여 입력 조건에 따라 3D 아바타를 정확하게 애니메이션할 수 있음을 입증한다.
-
오디오 구동 대화 얼굴 생성 (Audio-driven talking face generation)
- 목표: 입력 오디오로부터 구동 움직임 조건(driving motion conditions)을 예측하여 대화하는 얼굴을 생성한다.
- 설정: 교차 아이덴티티 재연과 유사하게 GT 샘플이 없다.
- 평가 지표: (아이덴티티 보존), (이미지 품질), (오디오-립 동기화), Sync score (오디오-립 동기화)를 측정한다.
- 결과: Real3D-Portrait (AD)는 기존의 원샷(one-shot) 2D 방식인 MakeItTalk나 PC-AVS와 비교했을 때 아이덴티티 유사성(), 이미지 품질(), 립 동기화(, Sync score)에서 현저히 우수한 성능을 보인다. 특정 인물에 과적합(over-fit)된 3D 방식인 RAD-NeRF와 비교해도 더 나은 립 동기화를 달성하며, 이미지 품질과 아이덴티티 보존에서도 견줄 만한 성능을 보인다.
3.3. Qualitative Evaluation
정성적 평가는 모델의 시각적 결과물에 대한 주관적인 품질 평가를 다루는 부분이다. 정량적 지표만으로는 파악하기 어려운 시각적 현실성, 자연스러움, 그리고 사용자 경험을 중점적으로 평가한다.
- 사례 연구(Case Study)
- 저자들은 데모 비디오와 추가 시각화 결과들을 제공하여 테스트된 모든 방법들 간의 명확한 시각적 비교를 제시한다.
- 특히, PNCC(Projected Normalized Coordinate Code)가 3D 아바타를 어떻게 애니메이션하는지, 큰 머리 포즈(head pose)에서도 자연스러운 몸통 움직임(torso movement)을 어떻게 생성하는지, 배경 전환(switchable background) 기능을 어떻게 지원하는지, 그리고 제안된 오디오-모션 모델(Audio-to-Motion model)이 오디오-립 동기화(audio-lip synchronization)를 어떻게 달성하는지를 구체적인 예시로 보여준다.
- 사용자 연구(User Study)
- 생성된 샘플의 품질을 평가하기 위해 사용자 연구가 진행되었다.
- 10개의 다른 언어로 된 오디오 클립과 10개의 다른 신원을 사용하여 각 방법에 대해 비디오를 생성한 후, 20명의 참가자가 평가에 참여하였다.
- 평가 프로토콜로는 MOS(Mean Opinion Score) 등급 시스템을 채택하였으며, 1점에서 5점 척도로 평가되었다.
- 참가자들은 다음 세 가지 측면에서 비디오를 평가하도록 요청받았다:
- 신원 보존(identity preserving): 원본 이미지의 신원과 비디오 속 신원의 유사성.
- 시각적 품질(visual quality): 이미지 충실도(image fidelity)와 시간적 부드러움(temporal smoothness)을 포함한 전반적인 시각적 품질.
- 립 싱크(lip synchronization): 오디오와 입술 움직임 간의 의미론적 수준의 동기화.
- 표 3에 제시된 평균 MOS 점수는 Real3D-Portrait가 기존의 원샷(one-shot) 방법들보다 신원 보존 및 시각적 품질 측면에서 더 우수하며, 개인 맞춤형(person-specific) 방법인 RAD-NeRF와도 유사한 성능을 보임을 보여준다. 특히, 립 싱크 측면에서는 Real3D-Portrait가 개인 맞춤형 오디오-구동 방식인 RAD-NeRF에 비해 명백한 우위를 보인다. 이는 제안된 모션 어댑터(motion adapter)가 입력 모션 조건에 따라 아바타를 정확하게 애니메이션하는 효과를 입증한다.
3.4. Ablation Study
-
I2P 모델 및 모션 어댑터 관련 연구
- 사전 학습(pre-training) 없이(): I2P 모델을 multi-view 이미지 데이터셋에서 사전 학습하지 않고 비디오 데이터셋에서 처음부터 학습한 경우이다.
- 결과: Table 4의 첫 번째 줄과 Appendix D.4의 Fig. 14에 따르면, 사전 학습 과정이 없으면 신원 유사도(CSIM), 이미지 품질(FID), 표정 정확도(AED)가 크게 저하된다.
- 의미: I2P 모델이 3D 재구성을 위한 3D 사전 지식(prior knowledge)을 효과적으로 학습하는 데 사전 학습이 필수적이라는 것을 보여준다.
- 미세 조정(fine-tuning) 없이(): Sec. 3.2에서 모션 어댑터 학습 시 사전 학습된 I2P 모델의 가중치를 고정하고 미세 조정하지 않은 경우이다.
- 결과: AED 수치가 높아져 표정 애니메이션의 정확도가 떨어졌다.
- 의미: 사전 학습된 I2P 모델은 소스 이미지의 표현을 재구성하는 데 특화되어 있으므로, 다양한 타겟 표현을 지원하고 이미지 데이터셋과 비디오 데이터셋 간의 도메인 차이를 극복하기 위해 미세 조정이 필요하다는 것을 시사한다.
- I2P 모델 크기(): I2P 백본의 파라미터 수를 40M, 87M(기본 설정), 200M으로 변경하여 실험한 경우이다.
- 결과: 87M 모델은 40M 모델에 비해 이미지 품질이 크게 향상되었지만, 200M 모델과의 성능 차이는 뚜렷하지 않았다.
- 의미: 모델 크기가 증가함에 따라 성능이 향상되지만, 특정 임계값을 넘어서면 성능 향상이 미미해질 수 있음을 나타낸다.
- Laplacian 손실 없이(): Eq. 3의 학습 목표에서 Laplacian 손실()을 제거한 경우이다.
- 공식:
- 는 현재 시점 의 를 입력받아 모션 어댑터 가 예측한 모션 디프 플레인(motion diff-plane)이다.
- 과 은 각각 이전 시점 과 다음 시점 의 모션 디프 플레인이다.
- 이 손실 함수는 현재 프레임의 모션 디프 플레인이 인접한 두 프레임의 평균 모션 디프 플레인과 유사하도록 강제한다.
- 는 L2 노름(norm)으로, 예측 값과 목표 값 사이의 유클리드 거리를 최소화하는 역할을 한다.
- 결과: Laplacian 손실이 모션 기반 헤드 애니메이션의 개선에 필수적임을 확인하였다.
- 의미: 이 손실 항은 생성된 비디오의 시간적 떨림(temporal jittering)을 줄여 영상의 부드러움을 향상시키는 데 기여한다.
- 공식:
- 사전 학습(pre-training) 없이(): I2P 모델을 multi-view 이미지 데이터셋에서 사전 학습하지 않고 비디오 데이터셋에서 처음부터 학습한 경우이다.
-
HTB-SR 모델 관련 연구
- 비지도 키포인트 사용(): 얼굴-비드2비드(Face-vid2vid)와 유사하게 비지도 학습 방식으로 키포인트(key points)를 추출하여 몸통 애니메이션에 사용한 경우이다 (기본 방식은 3DMM 얼굴 정점의 미리 정의된 키포인트를 사용한다).
- 결과: 추가 예측기 네트워크의 불안정성으로 인해 시각적 품질이 저하되었다.
- 의미: 미리 정의된 3DMM 기반 키포인트를 사용하는 것이 더 안정적이고 고품질의 몸통 애니메이션을 가능하게 한다.
- 채널별 연결(): Eq. 5에서 제안된 알파-블렌딩(alpha-blending) 방식의 융합 모듈 대신 헤드/몸통/배경 특징 맵을 단순히 채널별로 연결(concatenate)한 경우이다.
- 결과: Table 4의 두 번째 줄에서 신원 보존(CSIM) 및 이미지 품질(FID)이 나빠지고, Appendix D.4의 Fig. 15에서 알 수 있듯이, 머리카락 영역의 '비어 있는' 아티팩트(hollow artifact)와 헤드-몸통 경계 영역의 흐릿한 결과가 발생했다.
- 의미: 알파-블렌딩 방식의 융합이 각 세그먼트 간의 정보 전파를 제어하여 사실적이고 고품질의 합성 이미지를 얻는 데 필수적이다.
- 배경 인페인팅 없이(): 배경 이미지에 대해 KNN 기반 인페인팅(K-nearest-neighbor-based inpainting) 과정을 제거한 경우이다.
- 결과: 배경 인페인팅 과정 제거 시 이미지 품질이 저하되었다.
- 의미: 배경 인페인팅이 소스 이미지의 전경(사람)에 의해 가려진 영역을 자연스럽게 채워 넣어 최종 비디오의 사실감을 높이는 데 기여한다.
- 비지도 키포인트 사용(): 얼굴-비드2비드(Face-vid2vid)와 유사하게 비지도 학습 방식으로 키포인트(key points)를 추출하여 몸통 애니메이션에 사용한 경우이다 (기본 방식은 3DMM 얼굴 정점의 미리 정의된 키포인트를 사용한다).
