논문 링크: https://arxiv.org/pdf/2305.14334
Abstract
-
Diffusion 모델은 고품질의 이미지를 생성할 수 있으며, 이는 모델 내부에 의미 있는 정보인 internal representations가 포함되어 있음을 시사합니다. 하지만 diffusion 모델의 내부 정보를 담고 있는 feature map들은 네트워크의 layer뿐만 아니라 diffusion timestep에도 걸쳐 분포되어 있어, 유용한 feature descriptor를 추출하기 어렵습니다.
-
이러한 문제를 해결하기 위해, 논문은 Diffusion Hyperfeatures라는 새로운 프레임워크를 제안합니다. Diffusion Hyperfeatures는 다양한 scale과 timestep에 걸쳐 있는 feature map들을 통합하여 per-pixel feature descriptor(이미지의 특정 픽셀이나 영역의 특징을 숫자로 표현한 벡터로, 이미지의 한 부분을 다른 이미지의 부분과 매칭하기 위해 사용됨)로 만듭니다. 이러한 descriptor는 이후 다양한 downstream task에 활용될 수 있습니다.
-
Synthetic 이미지와 real 이미지 모두에 대해 generation (모델이 무작위 노이즈에서 시작하여 점진적으로 노이즈를 제거하면서 새로운 이미지를 만들어내는 과정)과 inversion(실제 이미지에서 시작하여 점진적으로 노이즈를 추가하여 결국에는 완전한 노이즈 상태로 만드는 과정) 프로세스를 사용하여 descriptor를 추출할 수 있습니다.
-
논문은 semantic keypoint correspondence(객체의 형태나 외관이 많이 달라져도 의미론적으로 같은 부분을 정확하게 찾아내는 것)라는 task를 통해 Diffusion Hyperfeatures의 유용성을 평가합니다. 연구 결과, 제안하는 방법은 SPair-71k real 이미지 benchmark에서 기존 방법보다 우수한 성능을 달성했습니다.
-
Real 이미지 쌍 (real image pairs): 훈련에 사용된 데이터는 실제 사진 두 장을 짝지어 놓은 것입니다. 이 이미지 쌍들은 서로 유사한 객체를 포함하고 있으며, 이 객체들의 의미론적 대응점(semantic keypoint correspondence) 정보가 주어져 있습니다. 네트워크는 이 실제 이미지 쌍에서 inversion features를 추출하고, 주어진 대응점 정보를 바탕으로 feature aggregation network를 훈련하여 feature를 잘 통합하는 방법을 배우게 됩니다.
-
해당 네트워크는 unseen object and composition을 가진 synthetic 이미지 쌍의 generation features에도 유연하고 transferrable하게 적용될 수 있음
1. Introduction
-
최근 컴퓨터 비전의 발전은 비전 트랜스포머 등의 딥러닝 네트워크에서 추출한 피처들 덕분이다. 이는 수작업 피처와 비교해 뛰어난 성능을 보인다. 확산 모델 또한 다양한 하류 작업(downstream tasks)에 사용될 수 있는 풍부한 내부 표현을 가지고 있을 것으로 예상됩니다.
-
하지만 확산 모델의 내부 정보는 네트워크의 레이어(layers)뿐만 아니라 확산 타임스텝(diffusion timesteps)에 걸쳐 분산되어 있어 유용한 디스크립터(descriptor)를 추출하기 어렵습니다. 기존 연구들은 특정 작업에 가장 적합한 일부 레이어와 타임스텝만 선택하는데, 이는 많은 노력과 실험을 필요로 하며 확산 프로세스 전반에 걸친 잠재적으로 가치 있는 정보를 놓치게 됩니다.
-
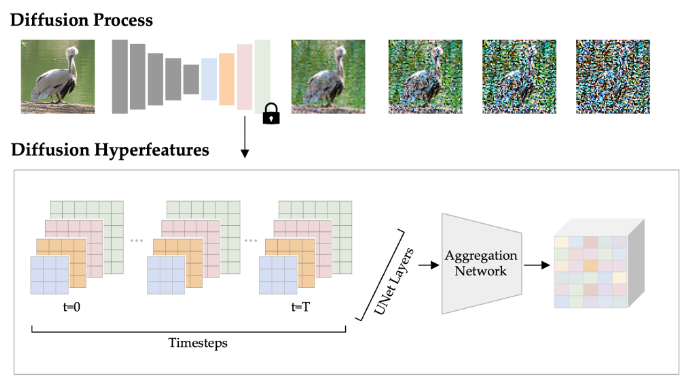
이 논문은 Diffusion Hyperfeatures를 제안합니다. 이는 스케일과 시간 모두에 걸쳐 변화하는 확산 프로세스의 모든 중간 피처 맵(intermediate feature maps)을 픽셀별 단일 디스크립터로 통합하는 프레임워크입니다.
-
이 통합 과정은 피처 애그리게이션 네트워크(feature aggregation network)를 통해 이루어지며, 이 네트워크는 입력으로 확산 프로세스의 모든 중간 피처 맵을 받아 단일 디스크립터 맵을 출력합니다. 이 네트워크는 어떤 피처가 특정 작업에 가장 유용한지 학습하는 가중치를 부여하므로 해석도 가능합니다.
-
주어진 이미지에 대한 Diffusion Hyperfeatures 추출은 해당 이미지에 대한 확산 프로세스를 수행하고 모든 중간 피처를 애그리게이터 네트워크(aggregator network)에 입력하는 것만큼 간단합니다.
-
이 때 합성 이미지의 경우 생성 과정, 실제 이미지의 경우 인버전(inversion) 과정을 수행하며 피처를 결합합니다.
-
연구팀은 semantic keypoint correspondence 작업에서 Diffusion Hyperfeatures의 유용성을 평가했으며, SPair-71k 실제 이미지 벤치마크에서 우수한 성능을 달성했습니다.
-
또한, 이 방법이 유연하고 전이 가능하다는 것을 보여줍니다. 실제 이미지 쌍의 인버전 피처로 학습된 피처 애그리게이션 네트워크를 보지 못했던 객체와 구성을 가진 합성 이미지 쌍의 생성 피처에도 사용할 수 있습니다.
-
모든 특징 맵의 활용: Diffusion Hyperfeatures는 기존 연구와 달리 확산 모델의 모든 레이어와 모든 타임스텝에 걸쳐 변화하는 특징 맵을 추출하여 사용합니다.
-
통합 과정: 이렇게 추출된 방대하고 다양한 특징 맵들은 lightweight aggregation network를 통해 통합됩니다. 이 네트워크는 복잡한 특징들을 픽셀 단위의 단일 특징 디스크립터(per-pixel feature descriptors)로 압축하는 역할을 합니다. 이 결과물이 바로 Diffusion Hyperfeatures입니다.
-
이미지 유형별 특징 추출 방식:
-
실제 이미지(real images)의 경우, 확산 모델의 반전 프로세스(inversion process)를 통해 특징을 추출합니다. 반전 프로세스는 이미지를 노이즈로 변환하는 과정입니다.
-
합성 이미지(synthetic images)의 경우, 이미지 생성 시 사용되는 생성 프로세스(generation process)에서 특징을 추출합니다.
-
-
활용 목적: 이렇게 얻은 Diffusion Hyperfeatures는 다양한 후속 작업에 사용될 수 있습니다. 논문에서는 "semantic keypoint correspondence(의미론적 키포인트 대응)" 작업에 이 디스크립터들을 활용합니다.
-
대응점 탐색: 두 이미지 쌍이 주어졌을 때, 각 이미지에서 추출된 Diffusion Hyperfeatures를 비교하여 가장 유사한 특징을 가진 픽셀들을 대응점(correspondences)으로 찾습니다. 이는 최근접 이웃 탐색(nearest-neighbor search) 방식을 통해 이루어집니다.
2. Related Work
Hypercolumn
-
신경망에서 특정 픽셀 위치에 대해 네트워크의 여러 레이어에 걸친 활성화 값을 모은 것으로, 옵티컬 플로우, 스테레오 매칭 등의 컴퓨터 비전 문제에 적용되었음.
-
Hypercolumn 접근 방식의 주요 목표는 키포인트 감지 및 분할과 같이 정확한 위치 정보가 중요한 작업에서 coarse 스케일 정보와 fine 스케일 정보를 모두 활용하는 것. Semantic correspondence와 같은 작업에서도 널리 사용되었는데, 이는 조명이나 시점 변화에 강하면서도 정확한 매칭이 가능해야 하기 때문
-
본 연구는 이 hypercolumn 개념을 diffusion 모델에 적용합니다. 기존 연구가 주로 스케일 변화에 특화되었다면, diffusion 모델은 생성 과정의 시간(timestep) 축을 따라 특징이 변화한다는 점이 차별화되는 부분
Deep Features for Semantic Correspondence
Aligned image output (정렬된 이미지 결과물)
-
여러 이미지가 특정 기준에 따라 구조적으로나 의미적으로 서로 맞아떨어지도록 변형(warping)되거나 생성된 결과물을 의미합니다.
-
예를 들어, 여러 장의 고양이 사진이 있을 때, 이들을 "정렬된 이미지 결과물"로 만든다면, 모든 고양이의 눈은 이미지의 같은 위치나 상대적인 위치에 오고, 귀는 다른 이미지의 귀와 정확히 대응되도록 이미지가 조정됩니다.
-
논문에서 언급된 연구에서는 GAN이나 Diffusion 모델 같은 생성 모델이 이러한 정렬된 이미지를 만들어내는 능력이 있음을 보여주었습니다.
Useful supervision
-
머신러닝에서 감독 신호(supervision)란 모델을 학습시키기 위해 사용되는 정답 데이터를 의미합니다.
-
그런데 생성 모델이 정렬된 이미지를 출력할 수 있다면, 그 이미지들 간의 대응 관계는 이미 모델 자체에 의해 암시적으로 또는 명시적으로 정렬되어 있다고 볼 수 있습니다. 이 자동으로 얻어진 정렬 정보를 마치 수동으로 라벨링한 정답처럼 사용하여 semantic correspondence를 위한 특징 추출 모델을 학습시키는 데 사용할 수 있습니다.
DINO
-
Self-DIstillation with NO labels의 약자로, 자기 지도 학습(Self-supervised Learning) 방식 중 하나로 제안된 모델
-
Vision Transformer (ViT) 아키텍처를 기반으로 하며, 같은 이미지를 다른 시점으로 보거나 다른 방식으로 변형한 것들 간의 일관성을 학습하는 방식으로 특징을 추출
-
라벨 없이 학습되었음에도 불구하고 이미지의 의미론적(semantic) 정보나 기하학적 구조를 매우 잘 포착한다는 장점. 때문에 DINO에서 추출된 특징(DINO features)은 semantic correspondence, 객체 분할 등 다양한 하위 작업에서 별도의 fine-tuning 없이도 좋은 성능을 보여주어 널리 사용되고 있습니다.
Diffusion Model Representations
-
디퓨전 모델의 피처를 활용하려는 연구는 시멘틱 세그멘테이션, 패놉틱 세그멘테이션, 너프 등에 다양하게 쓰여왔음. 그러나 저자들의 논문은 아래 두 가지에서 차별적임.
-
첫째, 특정 특징 하위 집합을 수동으로 선택하는 대신, Xu et al.의 연구를 기반으로 학습된 특징 애그리게이터(feature aggregator)를 제안합니다. 이 애그리게이터는 확산 프로세스의 모든 레이어와 타임스텝에 걸친 특징들에 가중치를 부여하고, 고정된 채널 크기와 해상도를 가진 하나의 간결한 디스크립터 맵(descriptor map)으로 통합합니다.
-
둘째, 실제 이미지에 대해 기존 연구들이 사용했던 생성 프로세스와 달리, 본 연구는 역전(inversion) 프로세스를 사용합니다. 역전 프로세스를 사용하면 동일한 타임스텝에서 더 고품질의 특징을 추출할 수 있습니다.
3. Diffusion Hyperfeatures
-
문제점: 확산모델은 generation과 inversion 프로세스 모두에서 UNet을 호출하여 이미지에 점차 노이즈를 생성한다. 그리고 여기서 생성되는 피처맵은 의미론적, 텍스처에 대한 특징 모두를 풍부하게 포함하고 있지만, 데이터가 너무 방대하여 사용하기 어렵다.
-
해결방안: 저자들은 이를 해결하기 위해 ligthweight aggregation network를 사용하여 특정 태스크에 대한 피처맵에 대한 상대적 중요성을 파악하도록 한다. 이 때 저자들이 수행한 태스크는 semantic correspondence를 찾아내는 과제이며, 해당 네트워크는 모든 피처맵들을 혼합해 하나의 디스크립터 맵인 Diffusion Hyperfeatures를 생성한다. 이렇게 생성된 디스크립터 맵에서 최근접 이웃 탐색을 통해 GT와 모델의 추론의 비교를 진행한다.
3.1 Diffusion Process Extraction
실제 이미지와 합성 이미지 둘 다에 대해 simplified and unified extraction process을 진행하는 과정
이 공식은 확산 과정의 타임스텝(timestep) 에서의 잡음이 있는 이미지 가 원본 깨끗한 이미지 와 순수한 가우시안 잡음 의 가중치 합으로 표현될 수 있음을 나타냅니다. 각 항은 다음과 같습니다.
-
: 타임스텝 에서의 잡음이 있는 이미지입니다. 확산 과정 중 특정 시점의 이미지 상태를 나타냅니다.
-
: 완전히 깨끗한 원본 이미지입니다. 잡음이 전혀 없는 초기 상태를 의미합니다.
-
: 표준 정규 분포()에서 샘플링된 순수한 가우시안 잡음입니다. 이 잡음이 스케일되어 깨끗한 이미지에 더해져 를 만듭니다. 본문에서는 가 확산 모델이 예측하는 잡음이라고 언급하는데, 역확산 과정(생성 또는 역전)에서는 모델이 이 를 예측하여 이미지에서 잡음을 제거하는 데 사용합니다.
-
: 타임스텝 에 따른 특정 계수로, 확산 과정의 잡음 스케줄과 관련이 있습니다. 는 깨끗한 이미지의 영향력, 는 순수 잡음의 영향력을 나타내며, 와 가 에 얼마나 기여하는지를 결정하는 가중치 역할을 합니다.
이 공식은 DDIM(Denoising Diffusion Implicit Models)에서 이미지를 생성하거나(Generation) 실제 이미지를 잡음으로 바꾸는(Inversion) 과정에 사용됩니다.
-
Generation (생성): 순수한 잡음 (타임스텝 )에서 시작하여 모델이 각 타임스텝의 잡음 를 예측하면, 위 공식의 변형을 이용하여 로부터 잡음을 점진적으로 제거하여 깨끗한 이미지 를 얻습니다. (에서 으로 역방향 진행)
-
Inversion (역전): 깨끗한 이미지 에서 시작하여 위 공식을 이용하여 각 타임스텝 에 해당하는 잡음 를 샘플링하거나 모델이 예측한 잡음을 사용하여 이미지에 잡음을 점진적으로 추가하여 순수한 잡음 를 얻습니다. (에서 로 순방향 진행)
이 논문에서는 실제 이미지의 특징을 추출하기 위해 Inversion 과정을 사용하며, 이때 얻어지는 중간 특징들이 Diffusion Hyperfeatures를 구성하는 데 활용됩니다.
Generation
-
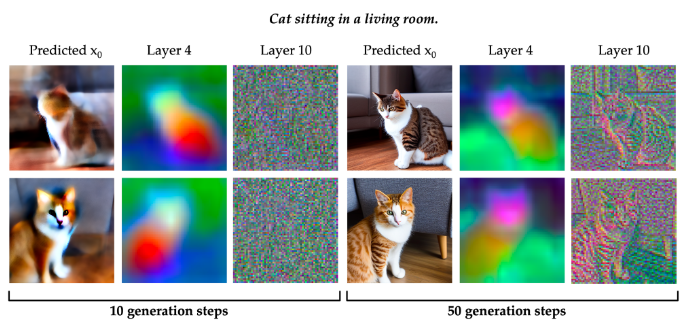
Diffusion 모델의 초기 생성 단계(early generation step)와 후기 생성 단계(late generation step)에서의 Layer 4와 Layer 10 특징 맵에 대한 PCA(Principal Component Analysis, 주성분 분석) 결과를 시각화했습니다. PCA는 고차원 데이터를 저차원으로 줄여 시각화하는 기법으로, 여기서는 Feature Map에 어떤 정보가 담겨있는지를 보여줍니다.
-
레이어별 특징 차이:
-
Layer 4: 텍스트에서 언급된 것처럼, 이 레이어의 특징은 고양이의 얼굴과 몸을 구분하는 등 비교적 거친 수준의 의미론적 특징(semantic characteristics)을 포착하는 경향이 있습니다.
-
Layer 10: 이 레이어의 특징은 이미지의 가장자리(edges)와 같은 미세하고 고주파수의 디테일을 포착하는 경향이 있습니다.
-
-
시간 경과에 따른 특징 변화:
-
생성 과정의 초기 단계에서 후기 단계로 갈수록(시간이 지날수록), 특징은 점차 더 세밀해지고(more fine-grained) 구체적인 이미지 정보를 반영하게 됩니다.
-
초기에는 입력이 거의 순수한 노이즈에 가깝지만, 모델은 최종 이미지를 예측하며 이미지 구조의 일반적인 아이디어를 형성합니다.
-
이 때, 피처들은 네트워크의 여러 레이어와 스텝에 분포하며, 이들을 다운스트림 태스크에 적용할 수 있는 가능성은 다음과 같은 이유에 있다.
-
의미론적 공유 표현 포함: 10 step의 Layer 4의 이미지를 보면, 둘이 다른 고양이 모습인데도 불구하고 머리는 초록색, 목은 주황색, 몸은 붉은색으로 표현된 것을 볼 수 있다.
-
시간에 따른 특징 변화: 10 step의 10번째 레이어는 노이즈 뿐인데, 50 step에서는 더 명확한 윤곽선이 존재.
따라서 이 두 가지 특성을 잘 융합하면 여러가지 다운 스트림 태스크에 활용할 수 있는 좋은 정보가 될 수 있다.
Generation Feature를 추출하는 기존 방식: Noise then Denoise
-
이 방식은 기존 연구에서 사용했던 방법으로, 실제 이미지를 Diffusion Model의 생성(Generation) 과정과 유사하게 처리합니다.
-
특정 중간 타임스텝
t에서 feature를 얻기 위해, 먼저 원본 실제 이미지에 해당 타임스텝t에 맞는 양의 노이즈를 추가(noise)합니다. -
이렇게 노이즈가 섞인 이미지를 가지고 Diffusion Model의 노이즈 제거(denoising) 과정, 즉 생성 과정을 독립적으로(independently) 수행합니다. 그리고 이 과정 중에 feature를 추출합니다. 그림의 왼쪽은 이 방식을 시각화한 것으로, 실제 고양이 이미지에 노이즈를 섞은 중간 상태에서 모델의 생성 과정을 돌려 feature를 얻습니다.
-
논문에서는 이 방식이 특정 타임스텝에서 독립적으로 이루어지기 때문에, 생성 과정이 원본 이미지의 구체적인 내용을 완전히 유지하지 못하고 디테일을 놓치거나(예: 고양이 배가 배경과 합쳐짐) 임의의 질감(예: 고양이 윤곽선 대신 랜덤 텍스처)을 생성할 수 있다고 설명합니다.
-
Inversion
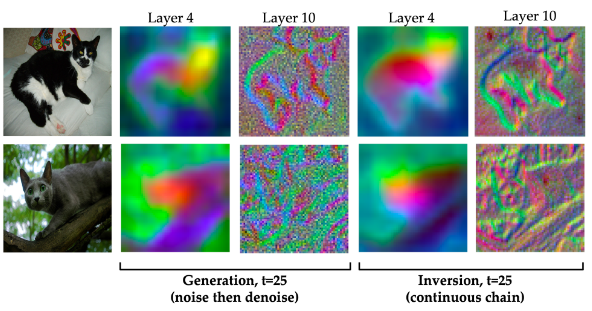
확산 모델에서 인버전 과정은 깨끗한 이미지(x₀)에 점진적으로 노이즈를 추가하여 최종적으로 순수한 노이즈(xₜ)로 만드는 과정입니다.
Inversion Feature를 추출하는 제안된 방식: Continuous Chain
-
이 방식은 본 연구에서 제안하는 방법으로, 실제 이미지에 대해 Diffusion Model의 반전(Inversion) 과정을 사용하여 feature를 추출합니다.
-
반전 과정은 깨끗한 원본 실제 이미지(
x_0, 타임스텝t=0)에서 시작하여, Diffusion Model의 정방향 확산 과정(forward diffusion process), 즉 노이즈를 점진적으로 더해나가는(progressively noise) 과정을 연속적으로(continuous chain) 수행합니다. -
x_0->x_1->x_2-> ... ->x_T(거의 순수 노이즈 상태)의 흐름을 따르며, 이 연속적인 연결(chaining) 과정의 각 타임스텝에서 feature를 추출합니다. -
그림의 오른쪽은 이 방식을 시각화한 것으로, 실제 고양이 이미지에서 시작하여 노이즈를 더해나가는 과정 중 타임스텝 t=25에서의 feature를 얻습니다.
-
-
저자들은 해당 방식이 기존의 방식보다 아래의 두 이유에서 더 효과가 있다고 말합니다.
-
유용한 특징 추출: 저자들은 인버전 과정 중 추출된 중간 특징들이 합성 이미지 생성 과정에서 추출되는 특징들과 유사하게 유용한 정보를 포함하고 있음을 발견했습니다. 예를 들어, 그림의 Layer4에서도 머리, 몸통은 같은 색으로 표현되며, Layer 10에선 고양이의 윤곽이 디테일하게 포착됨.
-
생성(Generation) 과정과의 비교: 심지어 기존의 연구였던 Generation보다 동일 스텝 t=25에서 그 정보가 훨씬 명확한 걸 볼 수 있음. Generation의 경우 Layer 4에서 첫 번째 고양의 배가 배경에 파먹혔으며, 두 번째 고양이는 Layer 10에서 윤곽 정보를 거의 알아볼 수 없음.
-
인버전이 피처 추출에 더 효과적인 이유: 각 단계의 입력의 모델의 이전 출력과 연관이 있기 때문에, 추출된 모든 특징맵들은 연결되어있다.
-
3.2 Diffusion Hyperfeatures Aggregation
- 특정 태스크에 가장 효과적인 정보를 가지고 있는 피처맵과 타임 스텝을 강조하는 과정
-
문제 인식: Diffusion 모델은 이미지 생성 과정에서 네트워크의 여러 레이어와 다양한 확산 타임스텝에서 특징 맵을 생성합니다. 이 특징 맵들은 이미지의 내부 정보를 담고 있지만, 양이 방대하고 해상도나 세부 정보 수준이 다양하여 그대로 사용하기 어렵습니다. 단순히 이 모든 특징 맵을 하나로 이어 붙이면(concatenation) 매우 고차원적인 데이터가 되어 대부분의 후처리 작업에 부적합합니다.
-
해결책: 논문에서는 이 문제를 해결하기 위해 경량의 특징 통합 네트워크(feature aggregation network)를 제안합니다. 이 네트워크는 모든 중간 특징 맵을 입력받아 단일의 픽셀별 디스크립터인 Diffusion Hyperfeatures를 생성합니다.
-
통합 과정 상세: 통합 네트워크는 다음과 같은 단계를 거칩니다.
-
표준화: 각 특징 맵
r은 표준 해상도로 업샘플링됩니다. -
차원 축소 (Bottleneck Layer): 업샘플링된 각 특징 맵은 bottleneck layer
B를 통과하여 표준 채널 수로 차원이 조정됩니다. -
가중치 적용: bottleneck layer를 통과한 특징 맵은 학습된 mixing weight
w가 곱해져 각 특징 맵의 중요도를 반영합니다. -
합산: 가중치가 적용된 모든 특징 맵들이 최종 Diffusion Hyperfeatures를 만들기 위해 합산됩니다.
-
-
수식 표현: 최종 Diffusion Hyperfeatures를 계산하는 수식은 다음과 같습니다.
-
: 레이어
l의 타임스텝s에서 추출된 원본 특징 맵입니다. -
: 레이어
l에 사용되는 bottleneck layer 함수입니다. 이 함수는 해당 레이어의 특징 맵 를 입력받아 채널 수를 표준화합니다. 논문에서는 타임스텝에 걸쳐 동일한 bottleneck layer를 공유하므로 총 개가 존재합니다. -
: 레이어
l의 타임스텝s에 해당하는 특징 맵에 곱해지는 학습된 mixing weight입니다. 각 레이어-타임스텝 조합마다 고유한 가중치가 학습되면, 이는 총 개입니다. -
: Diffusion 프로세스에서 선택된 모든 타임스텝 (부터 까지)과 네트워크의 모든 레이어 (부터 까지)에 걸쳐 합산합니다. 참고로, 논문의 저자들은 메모리를 보존하기 위해 전체 스텝 중 번의 스텝만 표본으로 집계합니다.
-
-
특징: 이 통합 네트워크는 어떤 레이어와 타임스텝의 특징이 주어진 작업(여기서는 semantic correspondence)에 가장 유용한지를 학습된 mixing weight를 통해 파악할 수 있게 하여 해석 가능성을 제공합니다. 또한, 모든 특징 맵을 고려함으로써 잠재적으로 유용한 정보를 놓치지 않습니다.
4. Experiments
Baselines
제로샷 베이스라인 (Zero-shot Baselines)
- 제로샷 방법은 semantic correspondence에 대해 별도의 학습 없이 바로 적용 가능한 특징을 사용합니다.
- DINO: ImageNet 데이터셋으로 학습된 모델의 Layer9 키 특징과 비교
- DINOv2: LVD-142M 데이터셋으로 학습된 모델의 Layer 11 토큰 특징과 비교
지도 학습 베이스라인 (Supervised Baselines)
- 지도 학습 방법은 특정 작업을 수행하기 위해 레이블링된 데이터셋으로 학습 과정을 거칩니다.
- DHPF, CATS++: ResNet-101의 hypercolumn features를 통합하는 모델. ImageNet으로 사전 학습(pretrained)된 후, semantic correspondence 작업을 위해 SPair-71k 데이터셋으로 추가 학습(finetuned)되었습니다.
확산 모델 베이스라인 (Diffusion Baselines)
- SD-Layer-4: 기존 연구에서 semantic 정보가 풍부하다고 알려진 Layer 4에서 추출된 단일 특징 맵을 사용합니다.
- SD-Concat-All: 모든 레이어에서 추출한 특징 맵을 단순히 연결(concatenate)하여 사용합니다.
Experimental Details
-
기반 모델: Stable Diffusion v1-5 모델을 사용했습니다. 이 모델은 이미지 생성에 사용되는 잠재 확산 모델(latent diffusion model)이며, 대규모 데이터셋인 LAION-5B 15로 학습되었습니다.
-
aggregation network 학습: 추출된 특징들을 통합하는 집합 네트워크(aggregation network)는 SPair-71k 30 데이터셋을 사용하여 학습되었습니다.
- 학습은 최대 5000 스텝(steps) 동안 진행되었습니다.
- 배치 크기(batch size)는 2를 사용했습니다.
- AdamW 2 옵티마이저를 사용했으며, 학습률(learning rate)은 1e-3으로 설정했습니다.
- 집합 네트워크는 bottleneck layers와 mixing weights를 학습하여 특징 맵을 통합합니다.
-
특징 추출 위치: 특징은 UNet 디코더 레이어(Layers 1부터 12까지)에서 추출되었습니다. 구체적으로는 self- 및 cross- attention 블록 이전에 있는 residual block의 출력을 사용했습니다.
-
확산 프로세스 활용:
- 전체 방법(full method)에서는 표준 T=50 스케줄러 타임스텝(scheduler timesteps)을 사용하여 인버전(inversion) 또는 생성(generation) 프로세스를 실행합니다.
- 이 50개의 타임스텝 중 5스텝마다 서브샘플링(subsamples)하여 총 S=11개의 타임스텝에서 특징을 집합합니다.
- "one-step" 프로세스(T=1, S=1)를 사용한 결과도 제시하여 타임스텝의 중요성을 분석했습니다.
-
실제 이미지 처리: 실제 이미지의 경우 인버전 프로세스를 사용하며, 프롬프트는 빈 문자열("")을 입력합니다. unconditional model(프롬프트 정보가 들어가지 않는 모델)에서만 특징을 추출하는 방식을 통해 수동 프롬프트 입력 없이도 고품질의 결과를 얻을 수 있음을 확인했습니다.
-
합성 이미지 처리: 합성 이미지의 경우 이미지 생성에 사용된 프롬프트를 조건으로 하는 conditional model(프롬프트 정보가 들어가는 모델)에서 특징을 추출합니다. 생성 프로세스를 사용하여 특징을 얻습니다.
Metrics
-
평가지표: PCK@는 주어진 임계값 내에서 올바르게 예측된 키포인트의 백분율을 나타냅니다.
-
올바른 예측의 기준: 예측된 키포인트가 "올바르다"고 간주되려면, 해당 키포인트가 실제 정답 위치로부터 특정 반경 내에 있어야 합니다. 이 반경은 다음과 같은 공식으로 정의됩니다.
- (알파)는 사용되는 임계값 파라미터입니다. 이 값이 작을수록 예측이 더 정확해야 올바른 것으로 간주됩니다.
- 는 이미지 또는 객체 바운딩 박스의 높이()와 너비() 중 더 큰 값입니다. 이 값을 사용하는 것은 이미지나 객체의 크기에 비례하여 오차를 허용하겠다는 의미입니다.
-
본 논문의 활용: 본 논문에서는 을 사용합니다. 즉, 예측된 키포인트가 이미지 또는 객체 크기의 최대 10% 반경 내에 있으면 올바른 것으로 간주됩니다.
- PCK@0.1img (Percentage of Correct Keypoints at 0.1 image dimension): 이미지 전체 크기(높이와 너비 중 더 큰 값)의 10% 반경 내에서 예측된 키포인트가 실제 키포인트와 일치하는 경우를 정확하다고 판단하여 계산한 정확도입니다.
- PCK@0.1bbox (Percentage of Correct Keypoints at 0.1 bbox dimension): 객체 바운딩 박스 크기(바운딩 박스의 높이와 너비 중 더 큰 값)의 10% 반경 내에서 예측된 키포인트가 실제 키포인트와 일치하는 경우를 정확하다고 판단하여 계산한 정확도입니다.
두 메트릭 모두 높을수록 좋은 성능을 의미합니다.
4.1 Semantic Keypoint Matching on Real Images
-
표의 구성:
-
# Layers (L): 해당 방식이 사용하는 모델 레이어의 개수입니다.
-
# Timesteps (S): Diffusion 모델의 시간 스텝(timestep) 개수입니다. Diffusion 모델은 이미지를 점진적으로 노이즈 제거하거나(생성) 노이즈를 추가하는(반전) 과정을 여러 스텝에 걸쳐 수행하며, 각 스텝에서 중간 피처 맵을 생성합니다.
-
SPair-71k: SPair-71k 데이터셋에서의 성능입니다.
-
CUB: CUB 데이터셋에서의 성능입니다.
-
↑ PCK@0.1img, ↑ PCK@0.1bbox: 각각의 데이터셋에 대한 PCK 성능을 나타내며, 위쪽 화살표(↑)는 값이 높을수록 좋음을 의미합니다.
-
-
평가 데이터셋: 연구팀은 두 가지 벤치마크 데이터셋을 사용하여 성능을 평가했습니다.
- SPair-71k: 동물, 차량, 가전제품 등 18가지 객체 카테고리의 이미지 쌍으로 구성된 대규모 시맨틱 키포인트 대응 벤치마크입니다. 이 중 360개의 무작위 이미지 쌍(카테고리별 20쌍)을 테스트에 사용했습니다.
- CUB (Caltech-UCSD Birds 200): 다양한 조류 종의 시맨틱 키포인트를 포함하는 데이터셋입니다. 이 데이터셋은 SPair-71k에 없는 객체 카테고리에 대한 모델의 전이성(transferability)을 테스트하기 위해 사용되었습니다.
-
비교 대상 방식들:
-
DINO: Self-supervised Vision Transformer 기반의 피처를 사용하는 이전 연구들입니다.
-
DHPF: Supervised Hypercolumn 피처를 사용하는 이전 연구들입니다. Hypercolumn은 ConvNet의 여러 레이어에 걸친 피처를 활용하는 개념입니다.
-
SD-Layer-4: Stable Diffusion 모델의 단일 레이어(레이어 4)에서 추출한 피처를 사용하는 간단한 베이스라인입니다.
-
SD-Concat-All: Stable Diffusion 모델의 모든 레이어에서 추출한 피처를 단순히 연결하여 사용하는 베이스라인입니다.
-
Ours (Diffusion Hyperfeatures): 본 논문에서 제안하는 방식으로, Diffusion 모델의 여러 레이어와 시간 스텝에 걸친 피처를 통합 네트워크를 통해 결합하여 사용합니다.
-
Ours-One-Step: 제안된 방식의 변형으로, 1개의 시간 스텝만 사용하여 피처를 추출하고 통합합니다.
-
SD-Layer-Pruned: 본 논문의 통합 네트워크 학습 결과 가장 높은 가중치를 받은 단일 레이어의 피처를 사용하는 베이스라인입니다.
-
Ours-Pruned: SD-Layer-Pruned와 동일하게 가장 높은 가중치를 받은 단일 레이어의 피처를 사용하지만, 본 논문의 bottleneck layer를 거친 후의 결과를 사용합니다.
-
Ours-SDv2-1: Stable Diffusion v1-5 대신 SDv2-1 모델을 사용하여 Diffusion Hyperfeatures를 추출하고 통합한 결과입니다.
-
-
평가 결과:
-
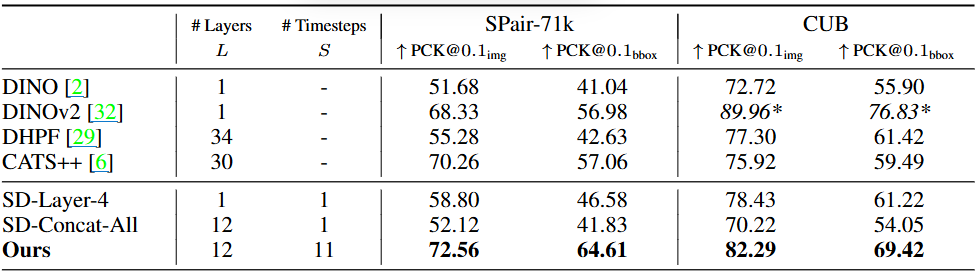
제안된 Diffusion Hyperfeatures 방법이 SPair-71k 및 CUB 데이터셋 모두에서 기존 최신 baseline들(DINOv2, CATS++)보다 우수한 성능을 달성했습니다 (Table 1 참고). SPair-71k에서 72.56% PCK@0.1img, CUB에서 82.29% PCK@0.1img를 기록했습니다.
-
Diffusion 모델의 단일 레이어 특징(SD-Layer-4)만 사용하더라도 기존 DINO나 DHPF보다 성능이 좋았는데, 이는 기저 모델(Stable Diffusion)이 더 크고 다양한 데이터셋으로 학습되었기 때문일 수 있습니다.
-
반면, 모든 레이어 특징을 단순히 연결한 방식(SD-Concat-All)은 성능이 저하되었습니다. 이는 각 특징 맵이 다른 종류의 정보(예: 시맨틱 또는 텍스처)를 담고 있어 단순 합산이 효과적이지 않음을 시사합니다.
-
Diffusion Hyperfeatures는 모든 레이어와 타임스텝의 특징을 통합함으로써 SD-Layer-4 대비 PCK@0.1img에서 14%p라는 큰 성능 향상을 보였습니다. 이는 단일 레이어만으로는 충분한 정보를 담지 못하며, 다양한 레이어와 타임스텝에 걸쳐 분포된 정보가 시맨틱 대응 작업에 매우 유용함을 나타냅니다. 특히 확산 모델의 내부 정보가 UNet의 단일 통과만으로는 완전히 포착되지 않고 여러 타임스텝에 걸쳐 분산되어 있다는 것을 의미합니다.
-
질적 평가(Figure 4 참고)에서도 Diffusion Hyperfeatures는 기존 baseline들이 미세한 부분이나 시각적으로 유사한 영역에서 혼동을 일으키는 반면, 더 정확하고 신뢰할 수 있는 시맨틱 대응을 찾아냈습니다.
-
4.2 Ablations

-
Ours-One-Step
-
의미: 이는 제안된 Diffusion Hyperfeatures 방법에서 확산 과정을 단 한 단계(T=1, S=1)만 사용하여 피처를 추출하고 Aggregation Network를 튜닝한 결과입니다. 인버전(Inversion) 과정은 깨끗한 이미지
x0에서 시작하여 노이즈를 점진적으로 추가해 나갑니다 (t=0에서 T로 진행). 'One-step inversion process'는 이 과정을 단 한 단계만 수행하는 것을 의미하며, Table 1의 "Timesteps: 1"은 이 단일 단계, 즉 t=1 시점에서 추출된 피처를 사용했음을 나타냅니다. 이는 인버전 과정에서 가장 처음 노이즈가 추가된 시점의 피처라고 할 수 있습니다. -
분석 결과: Ours-One-Step은 모든 레이어를 사용하더라도 (Layers: 12), 단일 시간 단계(Timesteps: 1)만으로는 전체 방법(Ours, Timesteps: 11)보다 성능이 크게 떨어집니다 (PCK@0.1img에서 최소 5% 차이). 이는 Figure 5의 가중치 분석에서도 확인되듯이, Semantic Correspondence에 유용한 정보가 확산 과정의 초기 여러 시간 단계에 걸쳐 분포되어 있으며, 단일 시간 단계의 피처만으로는 충분하지 않음을 보여줍니다. 시간 차원의 피처들이 이미지의 서로 다른 주파수 정보를 담고 있기 때문에, 이들을 종합하는 것이 성능 향상에 필수적입니다.
-
-
SD-Layer-Pruned
-
의미: 이는 제안된 방법(Ours)을 튜닝하는 과정에서 학습된 혼합 가중치(mixing weights,
wl,s)가 Semantic Correspondence 작업에 가장 중요하다고 식별한 특정 레이어(Layer)와 특정 시간 단계(Timestep) 조합의 원본(raw) 피처 맵 성능을 측정한 것입니다. Table 1의 "Layers: 1", "Timesteps: 1" 표시는 단일 레이어와 단일 시간 단계의 피처를 사용했음을 의미합니다. 논문의 Section 3.2에서 설명된 것처럼, Aggregation Network는 각 레이어/시간 단계 피처에 대해 가중치l,s를 학습하며, SD-Layer-Pruned는 이l,s값이 가장 큰 (l, s) 쌍을 찾아 해당l,s원본 피처 맵을 평가에 사용한 것입니다. 예를 들어, SDv1-5 모델의 경우 Layer 5, Timestep 10이 가장 높은 가중치를 가졌습니다. 단 해당 모델은 Bottleneck 레이어는 태우지 않았습니다. -
분석 결과: Section 4.2의 "Pruning"에서 분석됩니다. SD-Layer-Pruned는 이전 연구에서 수동으로 선택된 SD-Layer-4와 "비슷한(comparably)" 성능을 보였습니다. 이는 제안된 방법의 학습된 가중치가 실제로 Semantic Correspondence에 유용한 단일 피처 맵을 자동으로 잘 식별해 냈음을 보여줍니다.
-
-
Ours-Pruned
-
의미: SD-Layer-Pruned와 마찬가지로 학습된 가중치가 가장 중요하다고 식별한 단일 레이어, 단일 시간 단계 피처 맵을 사용합니다. 하지만 여기서는 이 단일 피처 맵을 제안된 Aggregation Network의 구성 요소인 학습된 Bottleneck Layer를 통과시킨 후의 성능입니다. Bottleneck Layer는 피처 맵의 해상도를 표준화하고 채널 수를 줄이는 역할을 하며, Ours-Pruned는 이 변환 과정을 거친 단일 피처의 성능을 평가합니다.
-
분석 결과: Ours-Pruned는 SD-Layer-Pruned보다 SPair-71k에서 6% 더 나은 성능을 보였습니다. 이는 학습된 Bottleneck Layer가 원본 피처 맵의 유용한 정보를 유지하면서도 Semantic Correspondence 작업에 더 적합하도록 피처를 "개선(refines)"하는 효과가 있음을 입증합니다. 하지만 Ours-Pruned와 여러 피처를 모두 사용한 전체 방법(Ours) 사이에는 여전히 9%의 성능 차이가 있습니다. 이는 단일 최적 피처 + Bottleneck Layer 조합만으로는 부족하며, 여러 레이어와 시간 단계의 피처들을 부드럽게 혼합(soft mixing)하는 것이 전체 방법 성능의 핵심 동력임을 시사합니다.
-
-
Ours-SDv2-1
- 의미: 제안된 전체 Diffusion Hyperfeatures 방법(Layers: 12, Timesteps: 11)을 SDv1-5 모델 대신 SDv2-1 Diffusion 모델의 피처로 튜닝하고 평가한 결과입니다. 이는 기반이 되는 Diffusion 모델이 바뀌었을 때 제안된 Aggregation Network가 얼마나 잘 적응하고 성능을 유지하는지를 보여주기 위한 실험입니다.
- 분석 결과: SDv2-1의 가장 큰 차이는 CLIP 보다 강력한 OpenCLIP 텍스트 인코더를 사용한다는 점입니다. 이로 인해 SDv2-1 모델의 내부 피처 특성이 SDv1-5와 달라집니다 (예: SDv2-1의 Layer 4는 SDv1-5의 Layer 4와 달리 Semantic Correspondence에 매우 나쁜 성능을 보임). 하지만 제안된 Aggregation Network는 이러한 기반 모델의 변화에 맞춰 Semantic Correspondence에 가장 유용한 레이어와 시간 단계(SDv1-5와는 다른 패턴)를 자동으로 학습합니다. 이는 제안된 방법이 특정 Diffusion 모델에 국한되지 않고, 기반 모델 특성에 "동적으로 적응(dynamically adjust)"하여 성능을 끌어낼 수 있음을 보여줍니다.
4.3 Transfer on Synthetic Images

-
평가 목표: 실제 이미지(real images)의 인버전 특징으로 학습된 Aggregation Network가 다음 두 가지 상황에서 얼마나 잘 일반화되는지를 테스트합니다.
-
인버전(inversion) 과정이 아닌 생성(generation) 과정에서 추출된 특징에 대한 일반화 능력: 이 논문에서는 인버전 특징으로 학습된 네트워크를 생성 특징에 적용할 때 시간 축(timestep ordering) 순서를 단순히 뒤집어서 사용합니다. 논문은 Diffusion 모델의 UNet이 각 시간 단계에서 생성하는 특징 맵이 해당 시간 단계에서의 '이미지 상태'(얼마나 노이즈가 섞여 있는지)에 따라 다른 정보를 담고 있음을 발견했습니다. 예를 들어, 노이즈가 적은 초기/후기 단계의 특징은 미세한 디테일이나 질감을 잘 포착하고, 노이즈가 많은 중간/후기 단계의 특징은 더 coarse한 구조나 semantic한 정보를 담는 경향이 있습니다. 따라서 인버전 특징으로 학습된 Aggregation Network를 생성 특징에 적용할 때는, 인버전 과정의 시점에서 학습된 가중치를 생성 과정의 시점의 특징에 적용하는 방식으로 '시간 축 순서를 뒤집는' 것입니다.
-
학습 데이터셋에 없는 객체 카테고리: SPair-71k 데이터셋에 없는 새로운 객체 및 구성으로 생성된 합성 이미지에 대한 일반화 능력.
-
-
실험 결과: 놀랍게도, 인버전 특징으로 학습된 네트워크가 합성 이미지의 생성 특징에서도 잘 작동하는 것으로 나타났습니다.
-
이는 DINO나 원시적인 SD-Layer-4 특징과 같은 다른 기준선(baselines)보다 우수한 성능을 보였습니다.
-
특히 미세한 부분(fine-grained subparts)에 대한 더 신뢰할 수 있는 Semantic Correspondence를 예측했으며, 이전에 보지 못한 질감(textures)이나 카테고리(categories)를 포함하는 어려운 경우에도 잘 작동했습니다.
-
-
핵심 시사점:
-
일반화 성능:
- Aggregation Network가 inversion 학습에 사용된 특징 유형을 정 반대 과정인 generation에 적용할 수 있음.
-
개방형 도메인 지식의 활용:
-
개방형 도메인 지식(Open-Domain Knowledge): 여기서 '개방형 도메인 지식'은 Diffusion 모델, 특히 Stable Diffusion과 같이 매우 크고 다양한 이미지-텍스트 데이터셋(예: LAION-5B)으로 학습된 모델이 갖게 되는 방대하고 일반적인 세상을 이해하는 능력을 의미합니다. 이 모델들은 학습 과정에서 다양한 객체, 장면, 스타일, 개념 및 그들 간의 관계를 학습합니다. 이 지식은 특정 카테고리나 특정 유형의 이미지에 국한되지 않고 광범위하게 적용 가능합니다. 따라서 이를 활용하면 특정 데이터셋의 객체 카테고리에 크게 의존하지 않고 효과적으로 작동함.
-
지식의 위치: 이러한 개방형 도메인 지식은 Diffusion 모델, 특히 UNet의 가중치(parameters) 내에 암묵적으로 저장되어 있으며, 이미지를 처리하는 동안 생성되는 중간 특징 맵(intermediate feature maps)에 그 정보가 담겨 있습니다. 다른 레이어와 시간 단계의 특징은 이 지식의 다른 측면(예: 저수준 시각 정보 vs. 고수준 semantic 정보)을 반영합니다.
-
활용(Utilize): 이 연구에서 제안하는 Diffusion Hyperfeatures는 Diffusion 모델의 UNet이 생성하는 모든 레이어와 모든 시간 단계의 중간 특징 맵을 Aggregation Network의 입력으로 사용합니다.
-
-
