1. Introduction
3D Human-object interactions (HOI)
- 인간과 사물이 상호작용하는 모습을 3D로 구현하는 과제
- 그러나 아래의 두 가지 이유 때문에 한계가 존재
- 텍스트 기반 인터렉션 데이터셋이 부족
- 현재 해당 데이터셋은 모션 캡처 혹은 시뮬레이션 데이터셋이 우세.
- 모션 캡처: 그들이 만든 시나리오에 한정적이고 노력이 많이 듦.
- 최근에는 GPT 등의 텍스트 묘사를 바탕으로 3D 휴먼 포즈를 만드는 시도가 존재
- 우리는 이를 HOI 태스크로 확장
- 인간과 물체의 공간적인 관계를 동시에 생성하는 게 어려움
문제점과 해결방안
- text-to-3D를 HOI로 확장하기에 부정확한 결과가 나오는 이유
- 텍스트 기반의 3D HOI 데이터셋이 부족하기 때문
- 디퓨전 모델이 상호작용에 대한 여러 개념을 그려낼 때 문제가 발생
- 다양한 HOI 인터렉션 데이터셋이 매우 적음
- 차라리 텍스트 기반의 묘사로 모델이 유추를 하는 것이 더 실현 가능성 있음
- 이러한 추론은 기하학적인 사전정보로 사용
- 이러한 텍스트 정보가 인체 포즈와 사물 모두에 적절한 제약을 줌
Interfusion
파이프라인
첫 번째 단계
- 인간과 사물이 상호작용하는 데이터셋은 매우 적기 때문에, 다양한 상황에 대해 합성된 이미지를 생성하여 데이터셋을 구축
- 이렇게 합성된 이미지 데이터셋에서 3D 휴먼 포즈를 추출
- 이 포즈를 상호작용에 대한 묘사에 매핑
- CLIP 이미지 임베딩을 활용하여 상호작용 묘사와 3D 포즈간의 코드북을 생성하고, 미묘한 묘사를 정확하게 표현 가능
- 이렇게 생성된 geometry prior는 두 번째 단계에서
두 번째 단계
- 최신 text-to-3D 생성 기술과 NeRF를 활용
- 첫 번째 단계에서 추론한 3D 포즈를 기반으로 현실적이고 고퀄리티의 외형을 생성.
- local-global optimization proces를 활용
- 로컬: 사람(SDS-H)과 물체(SDS-O)가 각각 최적화
- 글로벌: 사람과 물체의 상호작용을 포함한 전체 씬((SDS-I) 최적화
컨트리뷰션
- 텍스트 인풋으로 3D HOI 씬을 생성하는 Interfusion을 개발
- local-global 최적화를 통해 정확한 상호작용 씬을 생성
- 기존의 방법보다 훨씬 나은 결과를 도출
2. Related Works
2.1 HOI Synthesis
POSA
-
인간의 어떤 부위가 물체에 닿을지 사전 정보를 줌
-
이를 바탕으로 3D 씬에서 인간 메쉬의 배치 및 위치를 선정
COINS
-
HOI synthesis 과정에서 의미적 제어(semantic control)를 가능하게 하는 기법입니다.
-
행동(action) 레이블과 상호작용하는 객체(object)를 함께 임베딩(embedding)하여 생성 모델의 조건(condition)으로 사용합니다.
-
이렇게 함으로써, 생성 모델은 단순히 형태뿐 아니라 행동 및 상호작용에 대한 의미 정보를 반영하여 훨씬 더 자연스럽고 의미론적으로 일관된 3D 인간-객체 상호작용을 합성할 수 있습니다.
한계
- 그러나 지금까지의 연구는 지도학습 기반의 데이터셋이 있어야 했음.
- 우리는 이를 극복하고 더 다양한 시나리오에 강건한 모델을 개발.
2.2 Text-to-3D Snythesis
PureCLIPNeRF
-
CLIP (Contrastive Language–Image Pretraining): 텍스트와 이미지의 의미적 연관성을 학습한 사전학습 모델로, 텍스트 설명과 이미지 표현을 같은 임베딩 공간에 매핑합니다. 이를 통해 텍스트와 이미지 간의 유사성을 정량화할 수 있습니다.
-
Neural Radiance Fields (NeRF): 3D 장면을 볼륨으로 표현하고, 어떤 시점에서의 2D 이미지를 렌더링하는 신경망 기반 기술입니다. Density와 color를 예측해서 다양한 시점의 이미지를 생성합니다.
-
PureCLIPNeRF의 핵심 아이디어: CLIP의 텍스트-이미지 연관성 점수를 활용하여 NeRF를 최적화하는 것입니다. 즉, 주어진 텍스트 설명에 부합하도록 NeRF 모델의 파라미터를 업데이트합니다. 이때 3D 데이터와 텍스트의 쌍(pair) 데이터 없이도, zero-shot 방식으로 최적화가 가능한 것이 장점입니다.
-
작동 원리:
- NeRF를 통해 3D 신(scene)을 여러 시점에서 렌더링하여 2D 이미지들을 만듭니다.
- 각각의 렌더링된 이미지와 주어진 텍스트를 CLIP으로 인코딩해 의미적 유사도를 계산합니다.
- 이 유사도를 손실 함수로 삼아, NeRF 파라미터를 조정해 텍스트와 부합하는 3D 장면을 생성하도록 학습합니다.
-
의의: PureCLIPNeRF 방법은 3D 대상의 텍스트 설명만으로 3D 모델을 생성하거나 편집할 수 있게 하여, 직접적인 3D 주석 데이터가 부족한 문제점을 극복할 수 있습니다.
요약하면, PureCLIPNeRF는 CLIP의 텍스트-이미지 연결 능력을 통해 NeRF의 3D 표현을 텍스트 설명에 맞게 최적화하는, 데이터 부족 문제를 해결하는 텍스트-투-3D 생성 기법입니다.
Text2Mesh
Text2Mesh는 텍스트로부터 3D 메쉬를 생성하거나 스타일링하는 방법론입니다.
-
Text2Mesh는 CLIP이라는 사전 학습된 이미지-텍스트 모델을 활용해, 입력된 텍스트와 3D 메쉬 간의 의미적 일치를 최적화합니다.
-
초기에는 구 형태의 기본 메쉬 또는 기존 기본 메쉬를 시작점으로 하여, 텍스트 설명에 맞춰 메쉬의 형태와 텍스처를 변화시킵니다.
-
이 방식은 텍스트 기반 지도를 통해 3D 메쉬를 신속하고 정밀하게 변형시킬 수 있어, 텍스트 설명과 3D 형태의 조화를 높이는 데 효과적입니다.
간단히 말해, Text2Mesh는 텍스트의 의미를 해석해 그것에 맞는 3D 메쉬를 생성하거나 수정하는 기술로, CLIP을 활용해 텍스트-이미지 연관성을 3D 메쉬 형태로 확장하는 방법입니다.
DreamFusion
DreamFusion은 텍스트-기반 3D 생성 분야에서 중요한 방법 중 하나입니다. 이 방법의 핵심 아이디어와 작동 방식을 자세히 설명드리면 다음과 같습니다.
-
DreamFusion은 Neural Radiance Fields (NeRF)를 사용하여 3D 장면을 생성합니다. NeRF는 3D 공간 내에 빛의 산란과 컬러를 학습해 다양한 시점에서 사진처럼 보이는 이미지를 렌더링할 수 있는 기술입니다.
-
기존에는 CLIP이라는 비전-언어 모델을 이용해 3D 모델과 텍스트 간의 의미적 연결을 학습하여, 텍스트 설명에 맞는 3D 형상을 만들었으나, DreamFusion은 한 단계 더 나아가서 사전 학습된 2D 텍스트-이미지 확산모델(diffusion model)을 활용합니다.
-
즉, DreamFusion은 텍스트-이미지 diffusion 모델의 가이던스를 따라 NeRF의 파라미터를 최적화하는 'Score Distillation Sampling (SDS)' 기법을 사용합니다. 이를 통해 텍스트에 부합하는 고품질의 3D 장면을 생성합니다.
-
SDS는 노이즈가 추가된 이미지에 대해 diffusion 모델로부터 예측된 노이즈와 실제 노이즈 간의 차이를 줄이는 방향으로 NeRF 매개변수를 업데이트하는 방식입니다. 이렇게 함으로써 diffusion 모델이 학습한 텍스트-이미지 관계를 NeRF에 효과적으로 전이시킵니다.
-
DreamFusion의 강점은 대규모 paired 텍스트-3D 데이터 없이도, 단지 텍스트로부터 제로샷(zero-shot)으로 3D 장면을 생성할 수 있다는 점입니다. 이는 기존에 어려웠던 3D 생성 문제를 크게 단순화하였습니다.
-
제로샷 학습(zero-shot learning) 이란, 모델이 특정한 3D 씬과 해당 씬에 대한 텍스트 설명의 쌍을 직접적으로 학습하지 않고도, 처음 보는 새로운 텍스트 설명에 대해 3D 씬을 생성할 수 있는 능력을 의미합니다. 즉, 제로샷 3D 씬 생성은 ‘직접적으로 대응하는 3D-텍스트 데이터가 없이’ 텍스트만을 가지고 3D 공간에 씬을 만들어내는 것을 말합니다.
-
하지만, DreamFusion은 주로 단일 객체나 단순한 3D 장면 생성에 집중하며, 복잡한 인간-객체 상호작용과 같은 다중 개념 동시 생성에는 한계가 있습니다.
정리하면, DreamFusion은 사전 학습된 2D 텍스트-이미지 확산모델의 가이던스를 이용해 Neural Radiance Fields를 최적화하여, 텍스트 설명을 바탕으로 3D 장면을 제로샷으로 생성하는 혁신적인 방법입니다. 이는 텍스트-기반 3D 콘텐츠 생성 분야에 큰 영향을 미쳤으며, 본 논문 InterFusion도 DreamFusion의 텍스트-3D 생성 기술을 확장하고 구체적인 인간-객체 상호작용 생성에 맞게 개선한 사례라고 볼 수 있습니다.
2.3 Compositional Scene Generation
-
복합적 요소들의 조합을 통해 3D 장면(scene)을 생성하는 기술로, 하나의 장면을 여러 개별 객체(object) 단위로 나누어 각각을 모델링하고, 이 객체들을 조합하여 전체 씬을 구성하는 방식을 의미
-
각 객체의 위치, 형태, 속성 등을 개별적으로 제어할 수 있어 전체 장면에 대한 세밀한 조작과 높은 표현력을 가능하게 함
-
Segmentation Labels (분할 라벨)
- 이미지나 3D 씬 내에서 각각의 픽셀 또는 점이 어떤 객체에 속하는지에 대한 정보를 제공합니다.
- 예를 들어, 사람이 있는 영역은 '사람' 라벨, 의자 영역은 '의자' 라벨 등으로 구분합니다.
- 이는 객체 경계와 형태를 명확히 구분하는 데 도움을 주어, 씬을 더 세밀하게 다룰 수 있게 합니다.
-
Instance Masks (인스턴스 마스크)
- 비슷한 객체가 여러 개 있을 때, 각 개별 객체를 별도로 구분하는 마스크입니다.
- 단순 분할 라벨과 달리, 같은 종류의 객체라도 각 인스턴스를 구분할 수 있습니다.
- 예를 들어, 사람이 여러 명 있으면 각 사람마다 다른 마스크가 있어 독립적으로 처리 가능합니다.
-
Pre-trained Vision-Language Model (사전학습된 비전-언어 모델)
- 이미지와 텍스트 정보를 동시에 이해할 수 있는 인공지능 모델입니다.
- 예를 들어 CLIP 같은 모델은 이미지 특징(feature)과 텍스트 임베딩을 학습해, 텍스트 설명에 맞는 이미지나 3D 씬을 생성하거나 검색할 수 있습니다.
- 이렇게 하면 단순한 이미지 정보뿐 아니라, 텍스트 의미를 기반으로 보다 의미론적으로 일관된 씬 구성이 가능해집니다.
-
Canonical Coordinates (정준 좌표계)
- 3D 모델이나 씬에서 객체들이 공간 내에서 통일된 기준 좌표계를 갖도록 합니다.
- 이를 통해 객체 위치, 방향, 크기 등을 표준화하여, 서로 다른 객체들을 비교하거나 조합하기가 쉬워집니다.
- 예를 들어, 사람과 의자가 씬에 있을 때 각각의 좌표가 일관되게 정의되어야 위치 관계를 정확히 표현할 수 있습니다.
-
Text Prompts (텍스트 프롬프트)
- 사람이나 사물에 대한 설명을 자연어 형태로 입력하여, 인공지능 모델이 이를 기반으로 3D 씬을 생성하는 입력 방식입니다.
- 예: “한 남자가 기타를 연주하고 있다” 같은 텍스트를 넣으면, 그에 맞는 3D 인간-객체 상호작용 장면을 만들 수 있습니다.
- 텍스트 프롬프트는 사용자 의도를 쉽게 반영할 수 있어서, 조작과 생성에 유용한 인터페이스 역할을 합니다.
요약하면, 이 다섯 가지 방법은 3D 씬을 객체 단위로 세밀하게 해석하고, 텍스트 및 이미지 정보를 융합하여 더 정교하고 제어 가능한 씬 생성에 활용됩니다. 특히, 분할 라벨과 마스크는 객체 구분을, 비전-언어 모델은 의미 해석을, 정준 좌표는 공간 정합성을, 텍스트 프롬프트는 생성 명령을 담당하는 중요한 요소들입니다.
3. Method
3.1 Overview
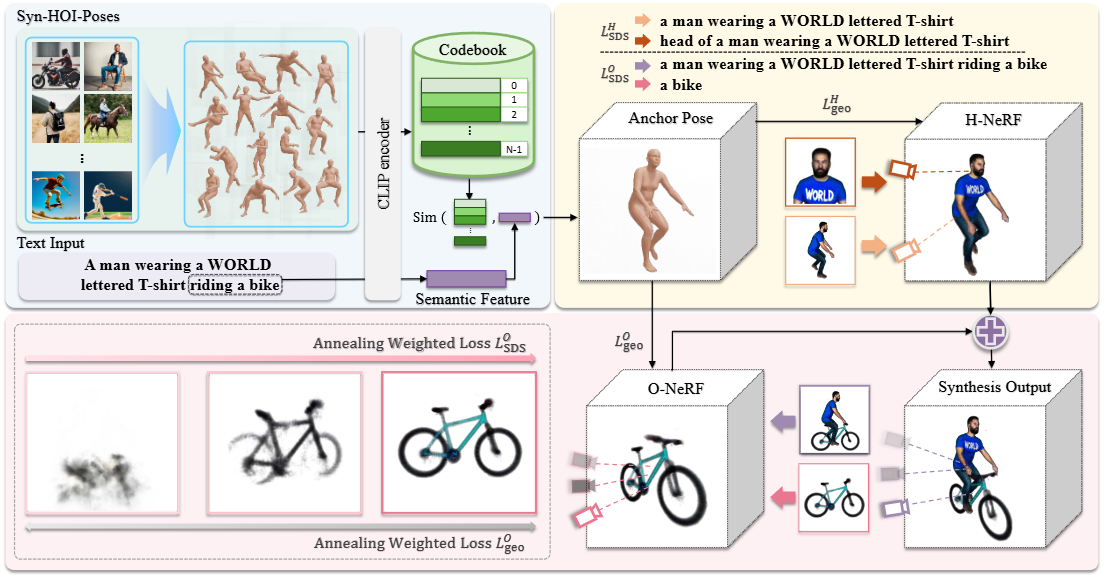
입력 텍스트
- : 인간의 스타일에 대한 설명 (예: 복장, 자세)
- : 객체의 스타일에 대한 설명 (예: 의자, 악기)
- : 상호작용 유형에 대한 설명 (예: ‘앉아 있다’, ‘연주하고 있다’)
출력 결과
- : 사람 모델
- : 객체 모델
- 생성된 3D 씬은 입력된 텍스트의 스타일과 상호작용을 충실히 반영하며, 사람과 객체가 공간적으로 적절히 배치 및 상호작용하도록 만듭니다.
Two-stage 모델 구조
1. 앵커 포즈(anchor pose) 생성
- 입력된 텍스트를 바탕으로 ‘앵커 포즈’라는 대표적인 3D 인간 자세를 생성합니다.
- 이 앵커 포즈는 이후 생성 과정에서 중요한 기하학적 제한 조건으로 사용되어, 상호작용이 자연스럽고 정확하도록 돕습니다.
2. 앵커 포즈 기반 HOI 생성

-
생성된 앵커 포즈를 활용해 사람 모델을 최적화합니다.
-
이후 오브젝트 모델을 생성한 뒤, 두 모델을 동시에 전체 씬 문맥 안에서 정제하여 사람과 객체가 자연스럽고 밀접하게 연관된 3D 상호작용 장면을 완성합니다.
3.2 Preliminaries
접기/펼치기확산모델
1. 확산 모델의 기본 개념 — 확산과 역확산
| 기호 | 의미 |
|---|---|
| 최종적으로 얻고 싶은 깨끗한 이미지 | |
| 시점 에서의 노이즈가 섞인 이미지 | |
| 표준 정규분포에서 뽑은 진짜 노이즈 | |
| 모델(파라미터 )이 예측한 노이즈 (: 텍스트 조건) |
1.1. 정방향 과정
정방향 과정은 모델 훈련시에만 사용한다.
깨끗한 이미지 에 단계별로 가우시안 노이즈를 섞어 간다.
여기서 는 시간이 지날수록 0 에 가까워지는 스케일 계수다.
(보통 ) 이면 는 거의 순수 노이즈가 된다.
1-2. 역방향 과정
목표는 노이즈가 많은 로부터 한 단계 덜 노이즈가 낀 을 복원하는 것이다.
와 에 대한 위 식이 있다면, 추가 샘플링 노이즈를 추가하여 아래와 같이 변형할 수 있다.
- 는 노이즈 감쇠율.
- 은 temperature 조절용 추가 샘플링 노이즈.
모델이 정확히 를 맞히면, 노이즈 제거 항 이
실제 깨끗한 신호에 훨씬 근접한다.
2. 텍스트 조건
- 텍스트 인코더: Transformer가 문장을 임베딩 벡터 로 만든다.
- 크로스 어텐션: UNet의 각 디노이징 블록은
- 쿼리 = 이미지 피처
- 키·밸류 = 문장 피처
로 하여 “이 텍스트가 언급한 시각적 개념이 어디에 있어야 하나?”를 학습한다.
- Classifier-free guidance: 텍스트 없는 예측과 섞어
를 키우면 샘플이 텍스트를 더 강하게 따르지만
예측 오차가 커질 때는 깨지는 현상도 함께 커진다.
3. 노이즈 예측 정확도 ↔ 이미지 품질가 연결되는 이유
| 단계 | 좋은 가 가져오는 효과 |
|---|---|
| (a) 정보 보존 | 오차가 작을수록 에 남는 불필요한 잔여 노이즈가 적다. 결과적으로 세밀한 질감·경계가 흐려지지 않는다. |
| (b) 누적 오류 억제 | 역확산은 수백~천 단계 반복되므로 작은 오차도 누적되면 큰 왜곡·색번짐으로 이어진다. |
| (c) 조건 일관성 | 텍스트 조건은 “이 영역은 고양이 귀여야 한다” 같은 국소 정보를 준다. 노이즈가 잘 제거되어야 그 정보가 다음 단계까지 보존되고, 점차 명확한 형태로 발현된다. |
| (d) Guidance 안정성 | guidance 공식은 두 예측 값의 차에 비례해 이미지를 이동시킨다. 예측이 부정확하면 잘못된 방향으로 크게 이동해 아티팩트가 생긴다. |
-
요약하면, 디퓨전 모델은 “노이즈를 빼서 이미지를 만든다”는 매우 단순한 원리를 수백 번 반복한다.
-
텍스트 → 이미지 경우에는 이 노이즈 제거 연산이 곧 “문장에서 요구한 시각 정보만 남기고 다른 것은 버린다”와 같다. 따라서 을 실제 에 가깝게 예측할수록 텍스트 조건을 충실히 반영하면서도 깨끗하고 선명한 이미지를 얻게 된다.
4. 모델 추론 과정
1. t = T (가장 처음)
- 시작 이미지 는 TV 흐림처럼 완전 잡음.
- 텍스트: “A red vintage car under cherry blossoms.”
2. 각 단계에서
- UNet은 를 계산.
- 예측값이 실제 노이즈와 비슷하면
차감 후 에는 차량 윤곽과 벚꽃 색조 같은 신호가 조금 더 드러난다. - 텍스트 없는 경로와의 guidance 로 빨간색, 빈티지 스타일이 더 강조된다.
3. t → 0
- 남는 노이즈가 거의 0 에 수렴할 때
고해상도, 저아티팩트의 “벚꽃 아래 빨간 빈티지 차” 완성.
4. 만약 이 부정확
- 초기 몇 단계 오차로 인해 차 모양이 일그러짐.
- 후반부 guidance 가 이를 더 증폭 → 흐린 배경, 깨진 휠 같은 품질 저하.
SDS (Score Distillation Sampling)
-
SDS는 DreamFusion에서 처음 소개된 방법으로, 텍스트로부터 3D를 생성하는 과정에서 중요한 역할을 합니다.
-
여기서 는 모델 파라미터 (NeRF 내의 볼륨 렌더러와 MLPs)와 카메라 위치 를 입력받아 렌더링된 2D 이미지 를 의미합니다.
-
SDS는 이 2D 이미지 를 시간 단계 에서 노이즈 이 섞인 로 변경하는데, 이 가 '노이즈가 섞인 이미지'입니다. 사전에 학습된 2D 텍스트-이미지 확산 모델 는, , 시간 , 그리고 텍스트 임베딩 를 바탕으로 노이즈를 예측하는 네트워크 를 제공합니다.
-
여기서 목표는 예측된 노이즈 와 실제로 이미지에 섞인 노이즈 간의 차이를 줄이는 것인데, 이를 통해 모델 파라미터 를 최적화합니다.
수식
-
- 3D 장면 생성 모델의 파라미터 에 대한 SDS 손실 함수의 그래디언트(기울기)를 의미합니다.
- 이 값은 모델 파라미터 를 어떻게 업데이트할지 방향과 크기를 알려줍니다.
- 는 사전 학습된 2D 텍스트-이미지 확산 모델로, 고정되어 있으며 3D 모델 학습을 위한 참조(teacher) 역할을 합니다.
- 는 3D 장면 생성 모델 파라미터로, 이것만 업데이트 대상입니다.
- 손실 함수 는 가 예측한 노이즈와 렌더링된 이미지 를 기반으로 계산되므로, 와 가 인자로 포함됩니다.
- 즉, 는 고정된 평가자, 는 가 생성하는 렌더링 결과임을 명시적으로 나타내기 위해 적혀 있습니다.
-
- 시간 와 노이즈 에 대해 평균을 취하는 연산입니다.
- 즉, 하나의 특정 와 에서 계산된 값이 아니라, 이를 다양한 와 에 걸쳐 샘플링하여 평균을 낸 값으로 학습의 안정성과 일반성을 높입니다.
- 실제 구현에서는 이 평균값을 미니배치 내의 샘플들에 대해 평균 내는 방식으로 근사합니다.
-
- 시간 에 따른 가중치 함수로, 노이즈 제거 과정에서 각 단계별 기여도를 조절하며, 시간에 따른 선형 증가, 혹은 감소 등의 스케줄링이 이루어집니다.
- 즉, 는 고정된 함수 형태로 주어지며, 특정 단계에서 더 민감한 학습이 이루어지도록 가중치를 부여합니다.
-
- 사전 학습된 2D 텍스트-이미지 확산 모델 가, 노이즈가 섞인 이미지 , 텍스트 임베딩 , 시간 단계 를 참고해 예측한 노이즈 값입니다.
- 즉, 모델이 “이 이미지에 있는 노이즈는 이 정도일 것이다”라고 추정한 값입니다.
-
- 실제로 이미지 에 섞인 랜덤 노이즈 값입니다.
-
- 예측 노이즈와 실제 노이즈의 차이(오차)로, 이 값이 클수록 모델이 노이즈를 잘못 예측했다는 의미입니다.
- 손실 함수에서 를 그대로 사용하는 이유는, 이 값에 제곱(또는 제곱근) 연산을 추가해 차이의 크기를 측정하기 때문입니다.
- 예를 들어, 는 일반적으로 (제곱 오차)를 포함하고, 여기서 단순 차이 는 그래디언트 계산의 기본 단위입니다.
- 절대값 함수는 미분이 불연속이고 그래디언트가 일정하지 않아 최적화가 어려워질 수 있습니다.
- 대신 제곱 오차는 부드러운 미분 가능성을 제공하며, 양수냐 음수냐의 오차 방향을 구분해 파라미터를 적절히 조정할 수 있게 도와줍니다.
- 따라서, 단순 차이를 사용해 그래디언트를 계산하고, 손실함수에서 제곱하여 크기를 평가하는 것이 표준적인 방법입니다.
-
- 3D 파라미터 가 변화할 때 렌더링된 이미지 가 어떻게 변하는지를 나타내는 미분값입니다.
- 즉, 의 변화를 2D 이미지 공간으로 전달해 업데이트 방향을 알려줍니다.
-
전체 흐름
- 확산 모델 가 예측한 노이즈와 실제 노이즈의 차이를 측정합니다.
- 이를 3D 장면 생성 모델 파라미터 에 미분값과 함께 곱해, 를 어떻게 변경해야 이 차이를 줄일 수 있는지 계산합니다.
- 여러 시간 단계 와 노이즈 값 에 대해 평균을 내어, 안정적으로 모델을 학습합니다.
- 가중치 는 각 시간 단계 중요도를 반영해 학습을 조절합니다.
요약하면, 이 식은 “2D 확산 모델이 알려주는 노이즈 예측 오차 신호를 기반으로 3D 모델 파라미터를 업데이트하여, 3D 렌더링 이미지가 텍스트에 맞게 점점 더 좋아지도록 만드는 방법”을 수학적으로 표현한 것입니다.
표기법 에서 콜론(:)과 콤마(,)의 의미 차이
- 표기에서 괄호 안에 있는 세 가지 정보 , , 는 모두 입력 값이지만, 기호가 약간 다르게 쓰인 이유는 문맥에 따라 구분이 있기 때문입니다.
- 에서 ‘;’(세미콜론)는 주 함수 입력과 조건(condition) 입력을 구분하는 데 쓰이고,
- ‘,’(콤마)는 함수의 여러 조건 입력이나 인자를 나열할 때 사용됩니다.
- 구체적으로, 는 네트워크가 노이즈가 섞인 이미지 자체를 주 입력으로 받아들이는 핵심 데이터,
- 반면 와 는 네트워크가 그 이미지를 어떻게 복원할지 예측할 때 참고하는 조건 정보 즉, 텍스트 임베딩 와 시간 단계 를 의미합니다.
- 따라서 는 “입력 노이즈 이미지 를 기반으로, 텍스트 조건 와 시간 단계 를 참조해 노이즈를 예측한다”는 의미로 해석할 수 있습니다.
- 세미콜론은 함수 입력과 조건 입력을 명확히 구분하는 수학적 표기 관례이며, 콤마는 조건 입력 내부에서 여러 변수를 구분하는 역할입니다.'
차이를 줄이려면 왜 ϕ가 아니라 ψ의 파라미터를 최적화하는가?
- 여기서 는 사전에 학습된 2D 텍스트-이미지 확산 모델의 파라미터로, 고정되어 있으며 수정하지 않습니다.
- 반면에 는 NeRF와 같은 3D 장면 생성 모델의 파라미터입니다.
- SDS(Score Distillation Sampling)에서는 사전 훈련된 2D 확산 모델()을 “검사자” 또는 “지도자” 역할로 사용하여, 3D 모델()이 텍스트 조건에 맞는 이미지를 렌더링하도록 유도합니다.
- 즉, 실제 수정 대상은 3D 장면 생성 모델 로, 가 생성하는 이미지 가 2D 확산 모델이 예측하는 노이즈 와 실제 노이즈 차이를 줄이도록 학습됩니다.
- 이렇게 함으로써, 3D 모델 는 2D 확산 모델 의 지식을 빌려 텍스트 조건에 부합하는 3D 장면을 점차 생성하도록 최적화됩니다.
- 요약하면, 는 교사 모델로 고정되고, 가 학습 과정에서 업데이트되는 학생 모델이라는 구조입니다.
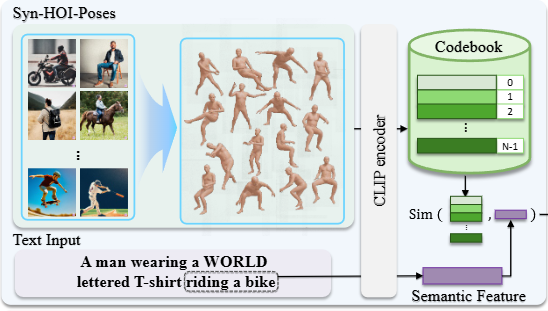
3.3 Anchor Pose Generation
데이터셋 제작
-
기존 mocap 데이터셋은 제한된 환경에서 수집되어 행동 다양성과 공간적 범위가 부족함. 이러한 한계를 극복하기 위해 저자들은 아래와 같은 방식의 데이터셋 구축을 진행.
-
저자들은 Stable Diffusion 같은 텍스트-이미지 확산모델을 활용하여 다양한 인간-객체 상호작용(HOI) 이미지를 대량 생성함.
-
ChatGPT를 사용해 "verb-ing a/an/the object" 형태로 235개의 상호작용 텍스트 프롬프트를 생성해 일상생활의 다양한 상호작용을 포괄함.
-
생성된 이미지 중 인간이 없는 이미지는 필터링함.
-
필터링된 이미지에서 PIXIE라는 사전 학습된 모델로 이미지를 통해 3D 인간 포즈를 추정하여 총 55,000개의 3D pseudo-SMPL 자세 데이터셋(Syn-HOI) 구축.
-
이렇게 생성된 데이터셋은 실제 모캡 데이터보다 다양한 인간-객체 상호작용 패턴을 포함할 수 있음.
-
SMPL 포즈 임베딩과 코드북 구축
-
SMPL (Skinned Multi-Person Linear model) 모델은 사람의 포즈 및 신체 형태 파라미터를 입력받아 삼각형 메쉬 형태로 3D 인간 모델을 생성합니다. 한 각도에서 포착한 이미지를 바탕으로 텍스트와 포즈 사이의 범용적 연관성을 잡기 어렵습니다.
-
이를 해결하기 위해 생성된 3D 포즈 모형을 다양한 각도에서 렌더링하여 2D 이미지들을 만듭니다.
-
이 렌더링된 여러 시점의 이미지를 CLIP의 이미지 인코더에 넣어 이미지 임베딩(feature embeddings)을 얻습니다. CLIP 모델은 이미지와 텍스트를 같은 벡터 공간에 매핑하여 유사성을 계산할 수 있는데, 이를 이용해 포즈 특징을 추출합니다.
-
여러 시점에서 렌더링된 이미지들의 CLIP 임베딩을 평균내어 하나의 대표적인 포즈 임베딩으로 만듭니다. 이렇게 하면 하나의 3D 포즈가 텍스트 정보와 연결될 수 있는 고차원 특징 벡터로 전환됩니다.
-
이렇게 생성된 고차원 특징 벡터는 상응하는 SMPL 파라미터와 쌍으로 구성된 데이터셋이 됩니다.
-
이 임베딩을 기반으로 코드북을 생성하기 위해 K-Means 알고리즘을 적용합니다. 논문에서는 55,000개의 3D 포즈 임베딩을 2048개의 중심점(centroids)을 통해 나누며, 이 중심점들이 바로 '코드북(codebook)'을 구성합니다. 각 중심은 유사한 포즈들의 키 포즈 역할을 하며, 이 코드는 다양한 포즈 범주를 압축해 나타냅니다.
-
이렇게 구축된 코드북은 주어진 텍스트 임베딩(예: “남자가 자전거를 타는 모습”)과 유사한 포즈 임베딩을 검색하는 데 사용됩니다.
텍스트 임베딩과 코드북 검색
검색 수식
-
텍스트 입력에 대해 가장 유사한 3D 포즈를 찾는 과정으로, 수식은 위와 같습니다.
-
: 사용자로부터 입력받은 텍스트 쿼리입니다. 예를 들어, "a person sitting on a chair" 같은 문장입니다.
-
: CLIP 모델의 텍스트 인코더 함수입니다. 이 함수는 텍스트 를 고차원 임베딩 벡터로 변환합니다.
-
: 포즈 데이터셋 내 2048개의 키 포즈(key poses)의 임베딩입니다.
-
: 두 임베딩 벡터 집합 와 간의 코사인 유사도를 구해, 집합에서 에 가장 유사한 상위 개의 벡터를 반환하는 함수입니다.
GPT-4V 추가 활용
-
선정된 후보 중 GPT-4V를 활용해 가장 정확하고 텍스트 의미와 부합하는 앵커 포즈(anchor pose) 하나를 최종 선정합니다.
-
필요에 따라 GPT-4V를 이용하는 방법 말고, 같은 클러스터 내 다양한 포즈 샘플을 골라 모델 생성의 다양성을 키울 수 있습니다.
COAP를 추가 활용
-
COAP(Compositional Articulated Occupancy Prediction)는 SMPL 파라미터 기반의 신경망(neural network) 구조로, 사람의 관절형 태그(body articulation)를 반영한 점유 여부를 학습함
-
입력으로 포즈 θ(자세 정보)와 형태 β(신체 형태 정보)를 받음
-
주어진 3D 공간 내 쿼리 점 p에 대하여, 점이 사람 몸체 내부에 속하는지를 나타내는 점유 값(occupancy value)을 f(x; β, θ)를 통해 예측
-
이 점유 값은 3D 생성 과정에서 특정 공간 점이 신체 내부에 있어야 하는지, 아니면 비어 있어야 하는지에 대한 구조적 제약조건 역할을 함
-
예를 들어, 신체 내부 점은 높은 점유 값으로 강제하여 신체가 생성되도록 하고, 비어 있어야 하는 공간엔 낮은 점유 값을 부여해 겹침 또는 침투 방지에 도움
-
이를 통해 3D 인간 모델 생성 시 포즈에 따른 정확한 해부학적 형상과 공간적 위치를 반영하며, 생성된 형태와 텍스처의 품질 및 일관성을 높임
3.4 Pose-Guided HOI Generation
"DeepFloyd [6] 모델과 같은 SDS(Score Distillation Sampling)의 다양한 텍스트 조건화 기법"이라는 문구는 텍스트 설명을 기반으로 3D 장면을 생성하는 데 사용되는 핵심 기술과 그 구체적인 활용 방식을 의미합니다.
여기서 중요한 세 가지 개념은 다음과 같습니다:
-
SDS (Score Distillation Sampling):
- 개념: SDS는 DreamFusion에서 처음 소개된 기술로, 2D 이미지-텍스트 확산 모델(text-to-image diffusion model)의 강력한 생성 능력을 활용하여 3D 콘텐츠를 만드는 방법입니다.
- 목표: 3D 데이터를 직접 학습하지 않고도 텍스트 입력만으로 고품질의 3D 모델(예: NeRF)을 생성하는 것이 목표입니다. 이는 주로 3D 상호작용 데이터가 부족하다는 문제를 해결하기 위한 것입니다.
- 작동 방식: SDS는 3D 모델의 파라미터()를 최적화하여, 이 3D 모델에서 렌더링된 2D 이미지()가 주어진 텍스트 조건()에 따라 사전 학습된 2D 확산 모델()의 "노이즈 제거(denoising)" 예측과 일치하도록 유도합니다. 즉, 확산 모델이 생각하는 '텍스트에 맞는 좋은 이미지'가 나오도록 3D 모델을 계속 조정하는 것입니다.
- 수학적 표현: 논문에서 제시된 SDS의 손실 함수(loss function)는 다음과 같습니다:
- : 3D 모델()에 의해 렌더링된 2D 이미지.
- : 사전 학습된 2D 텍스트-이미지 확산 모델(예: DeepFloyd).
- : 텍스트 임베딩(입력 텍스트 프롬프트에서 파생됨).
- : 노이즈 스텝(noise step).
- : 샘플링된 노이즈.
- : 노이즈가 추가된 이미지 , 노이즈 스텝 , 텍스트 임베딩 가 주어졌을 때 확산 모델의 노이즈 예측입니다.
- : 노이즈 스텝 에서의 가중치 항.
- : 렌더링된 이미지의 3D 모델 파라미터에 대한 그래디언트(미분 가능한 렌더링이 필요합니다).
이 손실 함수는 3D 모델이 렌더링하는 이미지가 2D 확산 모델의 예측과 일치하도록 파라미터를 조정하여, 결과적으로 텍스트 프롬프트에 충실한 3D 장면을 생성하게 합니다.
-
DeepFloyd [6]:
- 개념: DeepFloyd IF는 DeepFloyd라는 연구 그룹에서 개발한 텍스트-이미지 확산 모델입니다. 이는 이미지 생성 분야에서 높은 품질과 사실적인 결과물을 생성하는 것으로 잘 알려져 있습니다.
- InterFusion에서의 역할: InterFusion은 SDS 과정에서 "안내(guidance)"를 제공하는 핵심적인 사전 학습된 2D 확산 모델로 DeepFloyd IF를 사용합니다. 즉, DeepFloyd 모델이 텍스트 설명을 바탕으로 "어떤 이미지가 생성되어야 하는지"에 대한 강력한 신호(스코어 그래디언트)를 제공하며, InterFusion의 3D 모델은 이 신호에 따라 최적화됩니다.
-
텍스트 조건화 기법:
- 개념: 텍스트 조건화는 입력된 텍스트 프롬프트가 모델의 생성 과정에 영향을 미쳐 원하는 결과물을 얻도록 하는 방법을 의미합니다. 확산 모델에서 텍스트는 보통 텍스트 인코더(예: CLIP의 텍스트 인코더)를 통해 임베딩(숫자 벡터)으로 변환되어 모델의 노이즈 제거 네트워크에 입력됩니다.
- InterFusion에서의 활용:
- 세분화된 프롬프트: 사람 스타일(), 객체 스타일(), 상호작용 유형()을 명확하게 지정하는 세 가지 텍스트 설명의 트리플렛을 입력으로 받습니다.
- 특정 부분에 대한 집중: 예를 들어, 사람 모델(H-NeRF)의 얼굴 부분을 더 자세히 생성하기 위해 "∗ the head of ∗"와 같은 특정 프롬프트를 사용하여 해당 영역에 집중적인 최적화를 유도합니다.
classifier-free guidance: 이 기술은 텍스트 프롬프트에 강력하게 조건화된 결과물을 얻기 위해 사용됩니다. 논문에서는 이 가이던스 강도를 20으로 설정했다고 언급하며, 이를 통해 생성 품질을 높입니다.- 프롬프트 엔지니어링: 보충 자료에 따르면, "a photo of"와 같은 접두사, "8K, HD"와 같은 해상도 및 품질을 높이는 접미사, 그리고 카메라 뷰에 따라 "front view", "side view", "overhead view" 등과 같은 시점 의존적 접미사를 사용하여 텍스트 조건을 더욱 정교하게 만듭니다.
H-NeRF
각 항의 의미는 다음과 같습니다:
-
: H-NeRF 모델의 파라미터 에 대한 SDS 손실 함수 의 그래디언트를 의미합니다. 이는 모델의 파라미터를 조정하여 손실을 최소화하는 방향을 나타냅니다.
-
: 노이즈 추가 시간()과 실제 추가된 노이즈()에 대한 기댓값을 의미합니다. 이는 다양한 노이즈 조건에서 모델이 안정적으로 작동하도록 합니다.
-
: 시간 단계 에서의 가중치 항입니다. 확산 모델의 최적화 과정에서 특정 시간 단계에 더 큰 중요성을 부여할 수 있습니다.
-
: 사전 학습된 2D 텍스트-이미지 확산 모델 가 예측한 노이즈를 나타냅니다. 여기서 는 노이즈가 추가된 인간 이미지, 는 인간 스타일에 대한 텍스트 임베딩, 는 시간 단계입니다.
-
: 실제로 이미지 에 추가된 노이즈입니다. SDS는 예측된 노이즈 와 실제 노이즈 간의 차이를 줄이는 것을 목표로 합니다.
-
: 미분 가능한 렌더러(differentiable renderer)를 통해 렌더링된 인간 이미지 가 H-NeRF 모델의 파라미터 에 대해 얼마나 변화하는지를 나타내는 그래디언트입니다.
-
두 번째 항: 이 항은 전체 SDS 손실 중 인간의 머리 영역에 특화된 최적화를 담당합니다.
- : 노이즈가 추가된 인간 머리 영역 이미지입니다.
- : 인간 머리 영역에 대한 텍스트 임베딩입니다 (예: "a man with blond hair wearing a brown leather jacket"의 경우, "the head of a man with blond hair wearing a brown leather jacket"). 이를 통해 머리 부분의 세부 사항이 강화됩니다.
- : 렌더링된 인간 머리 이미지 가 H-NeRF 모델의 파라미터 에 대해 변화하는 그래디언트입니다.
-
기하학적 사전 지식 제공 (Geometric Prior):
COAP는 주어진 인간의 포즈()와 형상() 파라미터를 사용하여 3D 쿼리 포인트()가 3D 인체 내부에 존재하는지 여부를 나타내는 점유 값(occupancy value)을 예측하는 네트워크 ()를 제공합니다.- 이는 인체의 구조적인 사전 지식(structural prior)을 제공하여, 텍스트로부터 얻은 3D 포즈를 기반으로 인체 형상과 외관을 최적화하는 데 사용됩니다. 즉, 생성된 인체가 물리적으로 그럴듯하고 텍스트에 묘사된 포즈와 일치하도록 도와줍니다.
-
인체 기하학 최적화 제약 (Geometric Constraint for Human Body):
InterFusion의 두 번째 단계인 '앵커 포즈 가이드 HOI 생성' 과정에서,H-NeRF(인간 모델)의 기하학적 제약 조건()을 형성하는 데COAP가 활용됩니다.COAP는 앵커 포즈 내의 점들이 인체에 의해 점유되어야 함을 강제하고, 앵커 포즈 바깥의 점들은 앵커 표면에서 멀어질수록 점유될 확률이 감소하도록 유도합니다. 이를 통해 모델이 텍스트에 묘사된 인간 스타일과 일치하면서도 앵커 포즈에 기반한 일관된 구조를 유지하도록 합니다.
-
머리 영역 최적화 지원 (Head Region Optimization):
H-NeRF생성 과정에서, 특히 해상도를 높이기 위해 머리 영역에 대한 특화된 최적화가 이루어집니다. 이때COAP는 주어진 포즈에 대한 머리의 정확한 위치를 결정하는 데 사용됩니다.- 이를 통해 논문의 수식 (3)에서 보듯이, 전체 인간 모델 최적화와 함께 머리 영역()에 대한 별도의 SDS 손실을 적용하여 머리 부분의 디테일을 강화할 수 있습니다.
요약하자면, COAP는 InterFusion 프레임워크 내에서 3D 인간 모델의 구조적 일관성과 사실성을 보장하는 핵심적인 역할을 수행하며, 특히 텍스트 기반 3D 생성 과정에서 인체의 기하학적 제약을 효율적으로 통합할 수 있도록 돕습니다.
LHgeo는 InterFusion에서 H-NeRF(Human Neural Radiance Field)를 생성할 때 사용되는 기하학적 제약 손실 함수입니다. 이 손실 함수는 생성되는 인간 모델이 앵커 포즈(Anchor Pose)를 기반으로 하면서도 텍스트 설명에 맞는 세부적인 기하학적 형태를 가질 수 있도록 돕습니다.
공식은 다음과 같습니다:
각 항의 의미는 다음과 같습니다:
- (Cross-Entropy): 교차 엔트로피 손실 함수를 나타냅니다. 이는 두 확률 분포 간의 차이를 측정하는 데 사용됩니다. 여기서는 특정 지점이 점유될 확률과 실제 점유 여부 간의 차이를 최소화하는 데 사용됩니다.
- : 앵커 포즈 내부에 있는 점()을 의미합니다. 이 점들은 인간 모델의 단단한 기반을 형성하기 위해 점유되어야 한다고 가정합니다.
- : 앵커 포즈 내부에 있는 점 의 알파(alpha) 값으로, 해당 점의 불투명도를 나타냅니다. 즉, 점유될 확률을 의미합니다.
- : COAP(Compositional Articulated Occupancy of People) 모델 []에서 제공하는 점 의 점유 예측 값입니다.
- : 앵커 포즈 내부에 있는 점들이 실제로 점유되도록 강제하는 손실 항입니다. 이는 앵커 포즈가 인간 모델의 '확고한 기반'이 되도록 합니다.
- : 앵커 포즈 외부에 있는 점()을 의미합니다. 이 점들은 앵커 포즈 표면에서 멀어질수록 점유될 확률이 감소하도록 제어됩니다.
- : 앵커 포즈 외부에 있는 점 의 알파(alpha) 값입니다.
- : COAP 모델에서 제공하는 점 의 점유 예측 값입니다.
- : 앵커 포즈 표면으로부터의 점()의 거리를 나타냅니다.
- : 감쇠(decaying) 정도를 제어하는 하이퍼파라미터입니다. 이 값이 클수록 앵커 포즈에서 멀리 떨어진 점들도 점유될 가능성이 높아지고, 작을수록 앵커 포즈에 가까운 영역만 점유될 가능성이 높아집니다.
- : 앵커 포즈 표면에서 멀어질수록 점유될 확률이 기하급수적으로 감소하도록 하는 가중치 항입니다. 즉, 앵커 포즈 외부의 점들이 점유될 수도 있지만, 앵커 포즈 표면에서 멀어질수록 그 가능성이 줄어든다는 것을 의미합니다.
- : 앵커 포즈 외부에 있는 점들이 앵커 포즈 표면과의 거리에 따라 점유될 확률을 제어하는 손실 항입니다. 이는 앵커 위에 기하학적 세부 사항을 추가하면서도 앵커 포즈에 뿌리를 둔 일관된 구조를 유지할 수 있도록 합니다.
이 는 가중치(weight) 역할을 합니다.
LHgeo의 두 번째 항인 를 다시 살펴보겠습니다:
- 목표: 앵커 포즈 외부에 있는 점들()의 경우, 앵커 표면에서 멀어질수록 해당 점들이 점유될 확률(occupancy probability)이 감소하도록 만드는 것이 목표입니다. 즉, 멀리 있는 점들은 비어있도록 학습되어야 합니다.
- : COAP 모델에서 예측하는 점유 값으로, 일반적으로 앵커 포즈에서 멀리 떨어진 공간()의 점들은 값이 에 가깝습니다 (즉, 점유되지 않은 것으로 예측됩니다).
- : 이 교차 엔트로피 항은 모델이 예측한 점유 확률()이 목표 점유 확률()에 가까워지도록 합니다. 앵커 포즈에서 멀리 떨어진 점의 경우 가 에 가깝기 때문에, 이 항은 를 에 가깝게 만들려고 합니다.
이제 여기에 가중치 가 곱해지는 효과를 보겠습니다:
- 가 작을 때 (앵커 표면에 가까울 때): 값은 에 가깝습니다. 따라서 손실 함수의 두 번째 항 전체가 매우 작은 값을 갖게 됩니다. 이는 앵커 표면 바로 바깥쪽에 있는 점들이 완전히 비어있지 않아도 (즉, 가 보다 약간 커도) 패널티가 크지 않다는 것을 의미합니다. 이를 통해 모델은 앵커 포즈 위에 디테일한 기하학적 형태를 추가할 수 있는 유연성을 확보합니다.
- 가 클 때 (앵커 표면에서 멀리 떨어져 있을 때): 값은 에 가까워집니다. 이 경우 손실 함수의 두 번째 항이 거의 에 가까운 가중치로 곱해집니다. 만약 멀리 떨어진 점이 점유되어 있다면 (가 이 아니라면), 항의 값은 커지게 되고, 여기에 에 가까운 큰 가중치가 곱해지면 총 손실이 매우 커집니다. 모델은 이 큰 손실을 최소화하기 위해 해당 점의 값을 강하게 으로 만들도록 학습됩니다.
결론적으로, 사용자님의 말씀처럼 가중치 자체는 거리가 멀어질수록 커지는 것이 맞습니다. 하지만 이 가중치가 커진다는 것은 앵커 포즈에서 멀리 떨어진 공간이 점유되는 것에 대한 패널티가 더욱 강해진다는 의미입니다. 이렇게 강해진 패널티 때문에 모델은 멀리 있는 공간을 비어있도록 학습하게 되어, "앵커 포즈 표면에서 멀어질수록 점유될 확률이 감소"하는 결과를 만들어냅니다.
O-NeRF
이 수식은 InterFusion 프레임워크에서 객체 모델(O-NeRF)의 파라미터()를 최적화하는 데 사용되는 Score Distillation Sampling (SDS) 손실 함수()의 기울기(gradient)를 나타냅니다. 이 손실 함수는 텍스트 설명을 기반으로 사실적이고 문맥적으로 일관된 3D 인간-객체 상호작용(HOI) 장면을 생성하기 위해 객체의 외형과 상호작용을 동시에 지도하는 역할을 합니다.
수식은 다음과 같습니다:
각 항의 의미는 다음과 같습니다:
- : O-NeRF 모델의 파라미터 에 대한 SDS 손실 함수 의 기울기입니다. 이 기울기는 O-NeRF 모델의 파라미터를 업데이트하여, 주어진 텍스트 설명에 따라 객체의 모양과 상호작용을 정확하게 나타내도록 최적화하는 데 사용됩니다.
- : 시간 단계 와 노이즈 에 대한 기댓값(expectation)을 의미합니다. 이는 다양한 노이즈 레벨과 시간에 걸쳐 계산된 기울기의 평균을 취함으로써, 최적화 과정의 안정성을 높이는 역할을 합니다.
- : 시간 단계 에 대한 가중치(weighting term)입니다. 이 가중치는 특정 시간 단계에서 예측된 노이즈와 실제 노이즈 간의 차이가 전체 최적화에 미치는 영향의 중요도를 조절합니다.
- : 사전 훈련된 2D 텍스트-이미지 Diffusion 모델 가 노이즈가 추가된 이미지 , 텍스트 임베딩 , 그리고 시간 단계 를 입력으로 받아 예측하는 노이즈(predicted noise)입니다. 이 모델은 입력 텍스트 에 부합하는 이미지를 생성하는 방법을 학습했습니다.
- : 훈련 과정에서 이미지에 실제로 추가된 무작위 노이즈(sampled noise)입니다.
- : H-NeRF(인간 모델)와 O-NeRF(객체 모델)를 알파 컴포지션(alpha-composited rendering)하여 생성된 노이즈가 추가된 3D 상호작용 장면 이미지(interaction scene image)입니다. 이는 인간과 객체가 함께 있는 전체 장면을 나타냅니다.
- : 전체 상호작용 유형을 설명하는 텍스트 프롬프트의 임베딩(text embedding)입니다. 예를 들어 "자전거를 타는 사람"과 같은 상호작용에 대한 설명입니다.
- : O-NeRF를 렌더링하여 생성된 노이즈가 추가된 객체 이미지(object image)입니다. 이는 오직 객체 자체만을 나타냅니다.
- : 객체 스타일을 설명하는 텍스트 프롬프트의 임베딩(text embedding)입니다. 예를 들어 "빨간 자전거"와 같은 객체 자체에 대한 설명입니다.
- : 상호작용 장면 이미지 가 O-NeRF 모델의 파라미터 에 대해 변화하는 정도를 나타내는 미분값(derivative)입니다. 이 항은 O-NeRF가 전체 상호작용 장면의 문맥과 일관되도록 객체를 조절하는 데 기여합니다.
- : 객체 이미지 가 O-NeRF 모델의 파라미터 에 대해 변화하는 정도를 나타내는 미분값(derivative)입니다. 이 항은 객체 자체의 모양, 질감, 색상 등이 에 의해 지정된 객체 스타일에 정확하게 부합하도록 만듭니다.
이 수식은 두 가지 SDS 항을 결합하여 객체 모델을 최적화합니다. 첫 번째 항은 전체 상호작용 장면()의 맥락에서 객체가 상호작용 텍스트()에 부합하도록 지도하며, 두 번째 항은 객체 자체의 외형()이 객체 스타일 텍스트()에 맞게 생성되도록 지도합니다. 이는 "local-global" 최적화 전략의 일환으로, 객체가 전체 상호작용에 잘 통합되면서도 자체적인 스타일을 유지하도록 돕습니다.
이러한 SDS 기반 최적화는 DreamFusion과 같은 최신 텍스트-3D 생성 방법론의 발전을 활용하며, 텍스트만으로 3D 객체를 생성하는 데 효과적입니다. 특히 이 논문에서는 단일 객체 생성에서 더 나아가 인간과 객체 간의 복잡한 상호작용을 효과적으로 생성하기 위해 SDS를 확장하여 적용했습니다. 이를 통해 기존 텍스트-3D 방법들이 여러 개념을 동시에 생성하거나 복잡한 공간 관계를 처리하는 데 겪었던 어려움을 극복하고, 더 높은 품질의 3D HOI 장면 생성을 가능하게 합니다.
제시된 아래의 두 공식은 InterFusion 모델의 두 번째 단계인 'Pose-Guided HOI Generation'에서 상호작용 장면()을 생성하기 위한 알파 합성 렌더링(alpha-composited rendering) 공식을 나타냅니다. 이 공식은 인간 모델(H-NeRF)과 객체 모델(O-NeRF)을 통합하여 최종 상호작용 이미지를 만들어내는 방법을 설명합니다.
공식은 다음과 같습니다:
각 항의 설명은 다음과 같습니다.
-
첫 번째 공식 ():
- : 최종 렌더링된 상호작용 장면의 색상(또는 이미지)을 나타냅니다. 이는 광선을 따라 샘플링된 모든 점의 색상을 가중합한 결과입니다.
- : 광선을 따라 샘플링된 모든 점()에 대한 합산을 의미합니다.
- : 광선 상의 번째 샘플 지점의 가중치를 나타냅니다. 이 가중치는 해당 지점의 불투명도()와 그 이전에 있는 모든 지점의 투명도()를 곱하여 계산됩니다. 즉, 번째 샘플이 얼마나 장면에 기여하는지를 나타냅니다.
- : 광선 상의 번째 샘플 지점의 합성된 색상을 나타냅니다. 이 색상은 사람과 객체의 색상이 통합된 결과입니다.
- : 광선 상의 번째 샘플 지점의 알파 값(밀도 또는 불투명도)입니다. NeRF(Neural Radiance Fields) 기반 모델에서 밀도(density)로부터 파생되며, 해당 지점이 빛을 얼마나 흡수하거나 방출하는지를 나타냅니다.
- : 광선 상에서 부터 까지의 모든 이전 샘플 지점들의 투명도()를 곱한 값입니다. 이는 현재 번째 샘플 지점에 도달하기까지의 누적된 투명도를 나타냅니다.
-
두 번째 공식 ():
- : 광선 상의 번째 샘플 지점에서의 사람 모델()과 객체 모델()이 합성된 최종 색상을 나타냅니다.
- : 광선 상의 번째 샘플 지점에서의 인간 모델(H-NeRF)의 알파 값입니다.
- : 광선 상의 번째 샘플 지점에서의 객체 모델(O-NeRF)의 알파 값입니다.
- : 광선 상의 번째 샘플 지점에서의 인간 모델의 색상입니다.
- : 광선 상의 번째 샘플 지점에서의 객체 모델의 색상입니다.
- 이 공식은 특정 샘플 지점에서 사람과 객체가 모두 존재할 때, 각 모델의 알파 값에 비례하여 색상을 혼합하는 방법을 보여줍니다. 알파 값이 높을수록 해당 모델의 색상이 더 많이 반영됩니다. 즉, 이는 사람과 객체 모델이 겹치는 부분에서 두 모델의 색상과 불투명도를 고려하여 하나의 일관된 색상을 만들어내는 방식을 나타냅니다.
이 두 공식은 NeRF 기반 렌더링의 핵심 원리 중 하나인 알파 합성(alpha compositing)을 활용하여 인간과 객체 모델을 하나의 3D 장면으로 통합하는 과정을 설명합니다. 특히, 두 번째 공식은 단일 광선 상의 한 지점에서 인간 모델과 객체 모델의 색상 및 밀도 정보를 어떻게 결합하여 최종 상호작용 장면의 색상으로 변환하는지를 보여줍니다. 이 과정을 통해 텍스트 프롬프트에 기반한 사실적이고 고품질의 3D HOI(Human-Object Interaction) 장면을 생성할 수 있습니다.
이 논문은 기존의 DreamFusion과 같은 텍스트-3D 생성 방식이 단일 객체에 중점을 두어 다중 개념(인간과 객체)의 상호작용을 제대로 표현하지 못했던 한계를, 인간의 포즈를 기하학적 제약으로 활용하고 로컬-글로벌 최적화 과정을 통해 해결하고 있습니다. 이를 통해 더 복잡하고 현실적인 3D 장면 생성이 가능해졌습니다.
InterFusion 프레임워크에서는 3D 사람-객체 상호작용(HOI) 장면을 생성할 때 사람 모델(H-NeRF)과 객체 모델(O-NeRF)을 별도로 최적화하지만, 최종 장면에서는 이들이 응집력 있고 사실적으로 통합되어야 합니다. 이때 가장 중요한 문제 중 하나는 사람과 객체가 공간적으로 겹치는 것을 방지하는 것입니다. 이 문제를 해결하기 위해, 연구팀은 아래와 같은 특정 손실 함수를 정의했습니다.
이수식은 InterFusion 프레임워크에서 객체 모델(O-NeRF)의 기하학적 제약을 정의하는 손실 함수입니다.
- : O-NeRF에 대한 기하학적 손실(Geometric constraint loss for O-NeRF)을 나타냅니다. 이 손실은 객체 모델이 인간 모델의 앵커 포즈(anchor pose) 공간을 침범하지 않도록 제약하는 역할을 합니다.
- : 교차 엔트로피(Cross-Entropy)를 의미합니다. 이는 이진 분류 문제에서 예측 값과 실제 레이블 간의 차이를 측정하는 데 사용되는 손실 함수입니다. 여기서는 특정 3D 공간 점이 객체에 의해 점유될 '확률'과, 앵커 포즈에 의해 '점유되지 않아야 할' 실제 상태 간의 차이를 최소화하는 데 사용됩니다.
- : 앵커 포즈(anchor pose), 즉 미리 추정된 인간 자세의 3D 바디 내부에 있는 샘플링된 점 들을 나타냅니다. 이 점들은 객체 모델이 '차지해서는 안 되는' 공간에 해당합니다.
- : 렌더링 과정에서 점 의 알파 값(opacity)을 의미합니다. 이 값은 해당 점이 얼마나 불투명한지를 나타내며, NeRF(Neural Radiance Fields)에서 밀도(density)로부터 계산됩니다. 객체가 특정 공간을 점유하고 있다면 값은 높아집니다.
- : COAP [32] 모델에서 점 가 3D 인체 내부에 있는지 여부를 예측하는 점유 예측 네트워크(occupancy prediction network)의 출력값입니다. 즉, 가 인간 모델의 일부일 확률을 나타냅니다.
- : 점 가 3D 인체 내부에 있지 않을 확률을 의미합니다. 이 손실 함수는 앵커 포즈 내부에 있는 점()에 대해, 객체()가 그 공간을 차지하지 않아야 한다는 것을 강제하기 위해, 가 에 가깝게 되도록 최적화합니다. 만약 가 1에 가깝다면 (즉, 점이 인간 내부에 확실히 있다면), 는 0에 가까워지므로 도 0에 가깝게 만들어서 객체가 그 공간을 점유하지 못하게 합니다.
이 수식의 목적은 다음과 같습니다.
- 이 손실 함수는 객체 모델(O-NeRF)이 인간의 앵커 포즈가 차지하고 있는 공간을 침범하지 않도록 물리적 충돌을 방지하는 핵심적인 역할을 합니다.
- 이를 통해 인간과 객체가 서로 겹치거나 부자연스럽게 합쳐지는 것을 방지하여 3D 휴먼-객체 상호작용(HOI) 장면의 사실성과 기하학적 일관성을 높입니다.
- 논문에서는 순전히 의미론적(semantic) 가이드만으로는 객체가 인간 신체 외부 공간에 생성되어야 한다는 목표를 달성하기 어렵다고 지적합니다. 이 기하학적 제약()은 이러한 문제를 해결하여, 객체가 인간의 앵커 포즈를 기반으로 정확하게 배치되고 정렬되도록 추가적인 제약을 제공합니다.
Camera tracing
- 카메라 트레이싱 (Camera tracing)
- 목적: O-NeRF(객체 Neural Radiance Field)의 생성 품질을 향상시키기 위해 도입된 동적 모듈입니다.
- 작동 방식: SDS(Score Distillation Sampling) 프레임워크 내에서 카메라의 포즈(위치와 방향)를 자동으로 조정합니다.
- 초점 조절: 카메라가 전체 상호작용 장면 또는 객체 생성 중인 객체 자체의 중심에 집중하도록 합니다.
- 정렬 기준: 점유 확률(occupancy probability)이 0.5를 초과하는 복셀(voxel)들의 평균 위치에 카메라를 정렬합니다.
- 효과: 이를 통해 장면 또는 객체의 가장 중요한 부분에 일관된 초점을 맞춰 최적의 디테일 캡처와 사실적인 렌더링을 보장합니다.
Optimization
- 최적화 (Optimization)
- InterFusion의 전체 손실 함수는 다음과 같이 정의됩니다.
- 각 항의 설명:
- : 모델의 전체 손실(Total Loss)을 나타냅니다. 이 값을 최소화함으로써 모델이 원하는 3D HOI 장면을 생성하도록 학습됩니다.
- : 인간 모델(H-NeRF)에 대한 SDS(Score Distillation Sampling) 손실입니다. Equation (3)에 자세히 설명되어 있으며, 텍스트 설명(인간 스타일)에 맞춰 인간 아바타를 생성하고 머리 영역에 대한 세부적인 최적화를 포함합니다.
- : 객체 모델(O-NeRF)에 대한 SDS 손실입니다. Equation (5)에 자세히 설명되어 있으며, 상호작용 유형과 객체 스타일에 맞춰 객체를 생성하도록 돕습니다.
- : 인간 모델(H-NeRF)의 기하학적 제약 손실입니다. Equation (4)에 자세히 설명되어 있으며, 인간 모델의 형상이 앵커 포즈(anchor pose)에서 직접적으로 발전하도록 보장합니다. 앵커 포즈 내부의 점들은 점유되어야 하고, 외부의 점들은 앵커 표면에서 멀어질수록 점유 확률이 감소하도록 제약합니다.
- : 객체 모델(O-NeRF)의 기하학적 제약 손실입니다. Equation (7)에 자세히 설명되어 있으며, 객체 모델이 앵커 포즈(인간의 몸) 내부의 공간을 점유하는 것을 방지하여 인간과 객체 모델 간의 물리적 충돌을 막고 겹침이 없도록 합니다.
- : 정규화(Regularization) 손실입니다. Equation (9)의
Lorient는 법선 벡터가 카메라를 향하도록 유도하고, Equation (10)의Lopacity는 불필요한 부유를 방지하고 배경으로부터의 분리를 장려합니다. 이는 모델의 안정적인 학습과 사실적인 결과물 생성에 기여합니다. - : 각 손실 항에 대한 가중치(loss weights)입니다. 이 가중치들은 최적화 과정에서 '가중치 어닐링(weight annealing)'이라는 기법을 사용하여 동적으로 조절됩니다. 예를 들어, 은 학습 초기에는 낮게 시작하여 점차 증가하고, 는 초기 및 마지막 단계에서는 작게, 중간 단계에서는 크게 설정되어 객체의 초기화, 중복 정보 제거, 그리고 최종적인 인간과의 접촉을 유도합니다.
- InterFusion의 전체 손실 함수는 다음과 같이 정의됩니다.
4. Experiments

이 표는 다양한 3D 인간-객체 상호작용(HOI) 생성 방법들의 정량적 평가 결과를 보여줍니다. 이 연구에서 제안하는 InterFusion(본문에서는 Ours-HC로 표기) 방법과 여러 최신 Text-to-3D 베이스라인(DreamFusion [44], Magic3D [24], TextMesh [59]) 및 저자들이 직접 설계한 오브젝트 중심 베이스라인(Ours-OC)을 비교하고 있습니다.
- CLIP score:
- 설명: CLIP score는 입력 텍스트 프롬프트와 생성된 3D 인간-객체 상호작용(다양한 시점에서 렌더링된 이미지) 간의 유사성을 측정하는 지표입니다. CLIP (Contrastive Language–Image Pretraining) 모델의 임베딩을 사용하여 계산됩니다.
- 의미: 이 점수가 높을수록 생성된 3D 장면이 주어진 텍스트 설명과 의미론적으로 더 잘 일치한다는 것을 의미합니다.
- GPT-4V select (%):
- 설명: GPT-4V select는 GPT-4V GPT-4V라는 강력한 시각 언어 모델이 여러 방법으로 생성된 결과물 중에서 "가장 3D적으로 타당한"(예: 완전한 인체, 완전한 객체, 정확한 물리적 상호작용) 결과물을 선택한 비율을 나타냅니다.
- 의미: 이 비율이 높을수록 해당 방법이 생성한 결과물이 시각적으로 더 사실적이고 상호작용의 물리적 정확성이 뛰어나다고 평가되었음을 의미합니다.
결과 분석:
- InterFusion(Ours-HC)의 우수성:
- CLIP score: InterFusion(Ours-HC)은 0.3308로 가장 높은 CLIP score를 기록하여, 다른 베이스라인 방법들보다 입력 텍스트 프롬프트와의 의미론적 일치성이 가장 높음을 보여줍니다. 이는 InterFusion이 텍스트 설명을 3D HOI 장면으로 효과적으로 변환하는 능력이 뛰어남을 나타냅니다.
- GPT-4V select(%): InterFusion(Ours-HC)은 65.57%라는 압도적으로 높은 GPT-4V select 비율을 보여줍니다. 이는 GPT-4V가 InterFusion의 결과물을 다른 방법들보다 훨씬 더 사실적이고 물리적으로 정확한 3D HOI 장면으로 평가했음을 의미합니다. 특히, DreamFusion 44, Magic3D 24, TextMesh 59와 같은 기존 Text-to-3D 방법들과 비교했을 때 그 성능 차이가 매우 큽니다.
- 오브젝트 중심 베이스라인(Ours-OC): Ours-OC는 기존 Text-to-3D 베이스라인(DreamFusion, Magic3D, TextMesh)보다 CLIP score와 GPT-4V select 모두에서 더 나은 성능을 보였습니다. 이는 객체 중심의 사전 정보(object prior)를 활용하는 것이 3D HOI 생성에 긍정적인 영향을 미침을 시사합니다. 하지만 InterFusion(Ours-HC)만큼의 성능은 내지 못했는데, 이는 인간 포즈에 대한 충분한 사전 정보가 없었기 때문으로 분석됩니다.
- 전반적인 성능 향상: 본 논문에서 제안하는 InterFusion은 "인간과 객체를 효과적으로 동시 생성하고, 응집력 있는 상호작용 정보와 결합"함으로써 기존 방법론이 겪었던 문제를 해결하고, 훨씬 더 안정적이고 고품질의 3D HOI 결과를 생성할 수 있음을 정량적으로 입증했습니다.

-
Figure 5(a): 포즈 생성 비교 (AvatarCLIP vs. Ours)
- 이 섹션은 InterFusion의 포즈 생성 단계가 얼마나 효과적인지 보여줍니다.
- AvatarCLIP [15]: 기존 방식인 AvatarCLIP은 모션 캡처(mocap) 데이터셋인 AMASS [29]를 기반으로 코드북을 구축하고 CLIP [47]을 사용하여 텍스트 프롬프트에 해당하는 포즈를 검색합니다. 하지만, mocap 데이터셋은 특정 시나리오에 한정되어 있어 다양한 상호작용 포즈를 생성하는 데 한계가 있습니다. 이미지에서 "ride motorcycle"이나 "play guitar" 같은 포즈에서 AvatarCLIP이 생성한 포즈는 다소 어색하거나 부정확한 것을 볼 수 있습니다.
- Ours (InterFusion): InterFusion은 대규모 합성 이미지 데이터셋에서 3D 인간 포즈를 추정하여 "Syn-HOI 포즈 데이터셋"을 구축하고 이를 통해 더 넓고 다양한 상호작용 포즈를 표현하는 코드북을 만듭니다. 이를 통해 입력 텍스트에 더 잘 맞는 앵커 포즈를 생성할 수 있습니다. 이미지에서 "ride motorcycle", "read laptop", "play guitar", "hold box" 등 모든 예시에서 InterFusion이 생성한 포즈가 AvatarCLIP보다 훨씬 자연스럽고 정확하게 상호작용의 의도를 반영하고 있음을 확인할 수 있습니다.
-
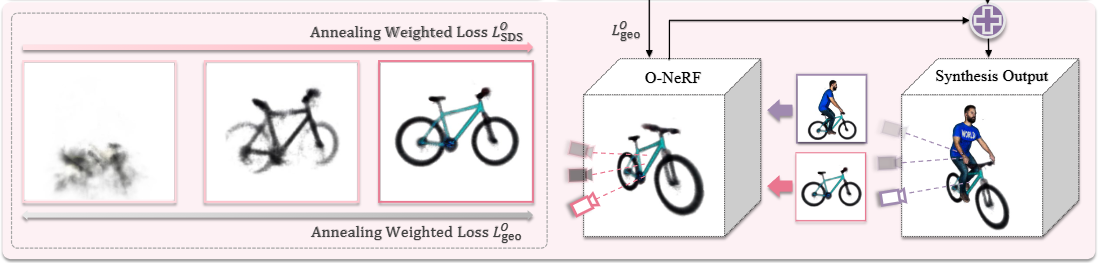
Figure 5(b): 포즈 기반 HOI 생성 중 손실 항 어블레이션 연구
-
이 섹션은 InterFusion의 두 번째 단계인 포즈 기반 HOI 생성 과정에서 사용되는 다양한 손실(loss) 항들의 중요성을 분석합니다. 예시로는 '자전거를 타는 사람'의 상호작용 장면이 사용되었습니다.
-
Ours (전체 모델): InterFusion의 완전한 파이프라인으로 생성된 결과입니다. 객체(자전거)와 인간 모델이 자연스럽게 결합되어 있으며, 텍스트 프롬프트('자전거를 타는 사람')에 따라 정확하고 일관된 상호작용을 보여줍니다. 객체 전용(Object-Only)과 인간-객체(Human-Object) 모두 높은 품질을 유지합니다.
-
w/o Interaction Semantic in (에서 상호작용 의미론적 가이던스 제거):
- 여기서 는 객체 모델(O-NeRF) 생성을 안내하는 SDS 손실입니다. 이 손실은 다음 수식으로 표현됩니다:
(Eq. 5)
이 항은 객체 모델이 상호작용 장면()에 대한 텍스트 설명()에 따라 최적화되도록 돕는 첫 번째 부분입니다. - 이 구성 요소를 제거하면 객체와 인간 간의 상호작용에 대한 의미론적 일관성이 사라집니다. 이미지에서 자전거 자체는 생성되지만(Object-Only), 인간 모델과 자전거 간의 상호작용이 부자연스럽고, 인간이 자전거를 '타는' 동작이 제대로 표현되지 않습니다(Human-Object). 텍스트에서 언급된 것처럼, 객체는 공간 내에 존재하지만 인간과 상호작용하지 않고 분리되어 보입니다.
- 여기서 는 객체 모델(O-NeRF) 생성을 안내하는 SDS 손실입니다. 이 손실은 다음 수식으로 표현됩니다:
-
w/o Geometric Constraint in (에서 기하학적 제약 제거):
- 는 객체 모델이 인간 모델의 공간을 침범하지 않도록 하는 기하학적 제약 손실입니다. 이 손실은 다음 수식으로 표현됩니다:
(Eq. 7)
여기서 은 인간 앵커 포즈 내부의 점들을 나타냅니다. 이 손실은 객체가 이러한 점들에서 '점유되지 않도록' 하여 인간과 객체가 겹치지 않게 합니다. - 이 제약이 없으면 객체가 인간 모델과 공간적으로 충돌하게 됩니다. 이미지에서 객체(자전거)는 형태가 심하게 왜곡되거나 흐릿하게 나타나고, 인간과 자전거가 서로 겹쳐서 물리적으로 불가능한 모습을 보입니다(Human-Object). 이는 "생성된 객체가 퇴화하거나 최종 상호작용이 결함이 있는" 결과를 초래합니다.
- 는 객체 모델이 인간 모델의 공간을 침범하지 않도록 하는 기하학적 제약 손실입니다. 이 손실은 다음 수식으로 표현됩니다:
-
w/o Object Semantic in (에서 객체 의미론적 가이던스 제거):
- 의 두 번째 항은 객체 모델() 자체에 대한 텍스트 설명()에 따라 최적화되도록 돕는 부분입니다.
- 이 구성 요소를 제거하면 객체 자체의 의미론적 일관성이 저하됩니다. 이미지에서 객체(자전거)는 존재하지만, 그 형태가 흐릿하거나 세부적인 묘사가 부족하며, 인간 모델의 영향을 받아 노이즈가 섞인 듯한 모습이 나타납니다(Object-Only 및 Human-Object). 텍스트에서 언급된 것처럼, 객체의 의미론적 일관성이 손상되어 노이즈가 많고 접촉 영역이 제대로 추출되지 않을 수 있습니다.
-
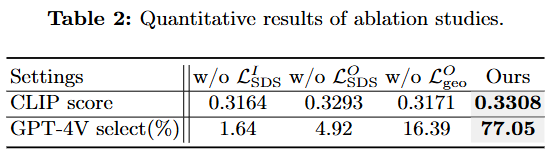
제공된 표는 InterFusion 논문의 Ablation Studies(제거 연구) 결과를 정량적으로 보여줍니다. 이는 InterFusion 모델의 다양한 구성 요소, 특히 다양한 손실(loss) 항이 전체 성능에 미치는 영향을 평가합니다.
-
설정 (Settings)
- w/o : 상호작용 시멘틱 가이던스 손실()을 제거했을 때의 성능을 나타냅니다. 이 손실은 전체 상호작용 장면의 생성을 텍스트 설명에 맞춰 유도합니다.
- w/o : 객체 시멘틱 가이던스 손실()을 제거했을 때의 성능을 나타냅니다. 이 손실은 객체 모델 생성을 객체 스타일에 대한 텍스트 설명에 맞춰 유도합니다.
- w/o : 객체 기하학적 제약 손실()을 제거했을 때의 성능을 나타냅니다. 이 손실은 객체가 인간 모델의 공간을 침범하지 않도록 제약합니다.
- Ours: 제안된 모든 손실 항을 포함한 InterFusion의 전체 모델 성능을 나타냅니다.
-
평가 지표 (Metrics)
- CLIP score: 입력 텍스트 프롬프트와 생성된 3D 인간-객체 상호작용 간의 시맨틱 유사성을 측정하는 지표입니다. 점수가 높을수록 생성된 내용이 텍스트 설명과 더 잘 일치한다는 것을 의미합니다.
- GPT-4V select(%): 여러 시점에서 렌더링된 이미지에 대해 객체의 완전성과 물리적 상호작용의 정확성을 평가하는 지표입니다. GPT-4V를 사용하여 가장 3D적으로 타당한 결과를 선택하며, 높은 백분율은 객체 완성도와 상호작용 정확도 면에서 더 나은 성능을 나타냅니다.
CLIP score 계산 과정
CLIP score는 생성된 3D 인간-객체 상호작용 장면이 입력된 텍스트 프롬프트와 얼마나 의미론적으로 유사한지를 측정하는 지표입니다.
-
생성된 3D 장면 렌더링:
- InterFusion은 텍스트 프롬프트에 따라 3D 인간-객체 상호작용 장면을 생성합니다.
- 이 생성된 3D 장면을 다양한 시점(multiview)에서 2D 이미지로 렌더링합니다.
-
CLIP 임베딩 추출:
- 텍스트 임베딩: 입력된 텍스트 프롬프트("a person in a military uniform riding a bike"와 같은)를 CLIP (Contrastive Language–Image Pretraining) 모델의 텍스트 인코더(text encoder)를 사용하여 벡터 형태의 임베딩으로 변환합니다.
- 이미지 임베딩: 다양한 시점에서 렌더링된 각 2D 이미지들을 CLIP 모델의 이미지 인코더(image encoder)를 사용하여 벡터 형태의 임베딩으로 변환합니다.
-
유사도 계산:
- 텍스트 임베딩과 각 이미지 임베딩 간의 코사인 유사도(cosine similarity)를 계산합니다.
- 코사인 유사도는 두 벡터가 가리키는 방향이 얼마나 비슷한지를 나타내며, 값이 1에 가까울수록 유사도가 높다는 것을 의미합니다.
- 이 논문에서는 "입력 텍스트 프롬프트와 생성된 3D 인간-객체 상호작용의 다양한 시점(different views) 간의 CLIP score를 계산"한다고 언급되어 있습니다 (11 페이지, "Evaluation prompts and criteria" 섹션). 일반적으로 여러 시점의 CLIP score를 평균하거나 특정 방식으로 집계하여 최종 CLIP score를 도출합니다.
-
의미: CLIP score는 생성된 시각적 내용(이미지)이 주어진 텍스트 설명의 의미를 얼마나 잘 반영하고 있는지를 정량적으로 평가하는 데 사용됩니다. 점수가 높을수록 텍스트와 이미지 간의 의미론적 일치도가 높다는 것을 의미합니다.
GPT-4V select 계산 과정
-
총 평가 프롬프트 수: 논문에서는 총 61개의 독특하고 다양한 텍스트 프롬프트를 사용했다고 명시되어 있습니다 (11 페이지).
-
모델별 결과 생성: 각 텍스트 프롬프트에 대해, 평가 대상이 되는 모든 방법(InterFusion의 Ours-HC, Ours-OC, DreamFusion, Magic3D, TextMesh 등)이 3D 인간-객체 상호작용 장면을 생성합니다. 이 3D 장면들은 여러 시점에서 2D 이미지로 렌더링됩니다.
-
GPT-4V의 선택 과정:
- 프롬프트당 비교: 61개의 각 텍스트 프롬프트에 대해, GPT-4V에게 해당 프롬프트로 생성된 모든 모델의 결과물들(렌더링된 이미지 세트)을 함께 보여줍니다.
- 최고 결과 선택: GPT-4V는 이들 결과물 중에서 "가장 3D적으로 정당성 있는(most 3D justifiable)" 것을 하나 선택하도록 지시받습니다. 여기서 "3D적 정당성"은 "완전한 인간 신체", "완전한 객체", "정확한 물리적 상호작용" 등의 기준을 포함합니다.
- 공정성: GPT-4V에게는 문맥 내 예시(in-context examples)가 주어지지 않으며, 결과물들의 순서는 무작위로 섞여 제시됩니다.
-
% 계산:
- 특정 방법(예: Ours-HC)이 61개의 전체 프롬프트 중에서 GPT-4V에 의해 "최고의 결과"로 선택된 횟수를 셉니다.
- 이 횟수를 총 프롬프트 수(61)로 나누고, 100을 곱하여 백분율을 얻습니다.
예시:
만약 InterFusion의 Ours-HC 모델이 61개의 프롬프트 중 40개의 프롬프트에서 GPT-4V에 의해 "최고의 결과"로 선택되었다면:
따라서, 표 1에서 Ours-HC의 GPT-4V select 값이 65.57%라는 것은, GPT-4V가 61개의 평가 프롬프트 중 약 65.57%의 경우에 Ours-HC가 생성한 결과물을 다른 비교 모델들의 결과물보다 더 우수하다고 판단하여 선택했다는 의미입니다. 이는 해당 모델이 인간-객체 상호작용의 물리적 타당성과 완성도 측면에서 얼마나 뛰어난 성능을 보이는지를 나타내는 지표가 됩니다.
모델 파이프라인 총정리
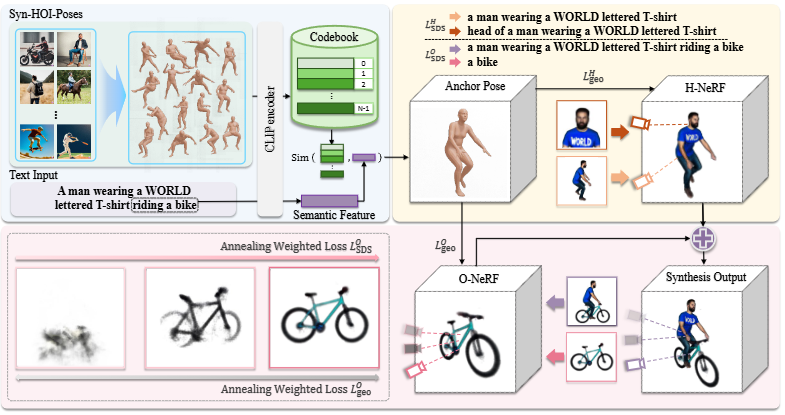
InterFusion는 텍스트 설명을 기반으로 3D 인간-객체 상호작용(HOI)을 생성하는 2단계 프레임워크를 보여줍니다.
-
1단계: 앵커 포즈 생성 (Anchor Pose Generation)
- 목표: 입력 텍스트 설명(
Text Input)에 해당하는 3D 인간의 상호작용 포즈, 즉 '앵커 포즈(Anchor Pose)'를 추출합니다. - 과정:
Syn-HOI-Poses(합성 HOI 포즈): 논문 저자들이 Stable Diffusion과 같은 텍스트-이미지 확산 모델을 활용하여 다양한 인간-객체 상호작용 이미지를 대규모로 생성합니다. 이 이미지들로부터 미리 학습된 PIXIE [9] 모델을 사용하여 3D 인간 포즈를 추정하고Syn-HOI pose dataset을 구축합니다.CLIP encoder: 구축된 데이터셋의 3D 포즈들을 여러 시점에서 렌더링한 후, CLIP 이미지 인코더를 사용하여 포즈 특징 임베딩을 추출합니다. 이 임베딩들의 평균값이 해당 포즈의 특징으로 사용됩니다.Codebook: 추출된 포즈 특징 임베딩들을 K-Means 클러스터링하여 2,048개의 핵심 포즈 centroid로 구성된 코드북을 만듭니다. 각 클러스터는 유사한 상호작용을 나타내는 포즈들의 하위 집합을 포함합니다.Semantic Feature&Sim: 주어진 텍스트 입력(A man wearing a WORLD lettered T-shirt riding a bike)은 CLIP 텍스트 인코더(ftext)를 통해 의미론적 특징 임베딩으로 변환됩니다. 이 임베딩은 코드북 내의 포즈 임베딩(θE)과 코사인 유사도(TOPk)를 기반으로 가장 유사한 상위 k개(k=7사용)의 포즈를 검색하는 쿼리 역할을 합니다 (식 2). 최종 앵커 포즈는 GPT-4V를 사용하여 가장 정확한 포즈로 선택됩니다.
- 목표: 입력 텍스트 설명(
-
2단계: 포즈 가이드 HOI 생성 (Pose-Guided HOI Generation)
- 목표: 1단계에서 생성된 앵커 포즈를 기하학적 제약 조건으로 활용하여 상세한 3D 인간-객체 상호작용 장면을 생성합니다.
- 구성 요소 및 과정:
- H-NeRF (Human Neural Radiance Field):
- 인간 모델(
ψH)을 표현하는 데 사용됩니다. LSDSH(Score Distillation Sampling for Human) 손실 함수를 통해 텍스트 프롬프트(예:a man wearing a WORLD lettered T-shirt,head of a man wearing a WORLD lettered T-shirt)에 따라 인간의 스타일을 생성합니다. 특히, 얼굴 영역의 해상도와 품질을 높이기 위해 머리 영역에 대한 별도의 최적화가 포함됩니다.- (식 3)
- 이 식은 H-NeRF 모델 파라미터 를 최적화하여 렌더링된 이미지 가 텍스트 와 일치하도록 합니다. 두 번째 항은 인간의 머리 영역 에 대한 추가 최적화를 나타냅니다. 는 시간 스텝 에서의 가중치, 는 사전 학습된 2D 확산 모델이 예측한 노이즈, 은 실제 추가된 노이즈입니다.
LHgeo(Human Geometric Loss) 손실 함수를 통해 앵커 포즈로부터 인간 모델의 기하학적 구조를 제약합니다. 앵커 내부의 점들은 점유되어야 하며, 외부의 점들은 앵커 표면에서 멀어질수록 점유 확률이 감소합니다.- (식 4)
- 이 식은 인간 모델의 기하학적 일관성을 강화합니다. 은 앵커 내부의 점들, 은 앵커 외부의 점들, 와 는 해당 점들의 투명도(opacity), 는 COAP [32] 모델을 통해 예측된 점 의 점유 값입니다. 는 앵커 표면으로부터의 거리, 는 감쇠 정도를 조절하는 하이퍼파라미터입니다.
- 인간 모델(
- O-NeRF (Object Neural Radiance Field):
- 객체 모델(
ψO)을 표현하는 데 사용됩니다. LSDS_O(Score Distillation Sampling for Object) 손실 함수를 통해 상호작용 유형(예:riding a bike)과 객체 스타일(예:a bike)에 맞춰 객체를 생성합니다.- (식 5)
- 이 식은 O-NeRF 모델 파라미터 를 최적화합니다. 첫 번째 항은 상호작용 장면 가 전체 상호작용 텍스트 와 일치하도록 유도하며, 두 번째 항은 객체 가 객체 텍스트 와 일치하도록 합니다.
LOgeo(Object Geometric Loss) 손실 함수를 통해 객체 모델이 인간 모델의 앵커 포즈 영역(p_i ∈ Pin)을 침범하지 않도록 제약합니다.- (식 7)
- 이 식은 객체 모델이 앵커 포즈 내부의 공간을 점유하지 않도록 강제하여, 인간 모델과의 물리적 충돌을 방지합니다. 는 투명도, 는 점유 값입니다.
- 객체 모델(
- Camera Tracing: O-NeRF 최적화 과정에서 카메라 포즈를 동적으로 조정하여 장면 또는 객체의 가장 중요한 부분에 초점을 맞춥니다.
- Synthesis Output: H-NeRF와 O-NeRF는
xI(식 6)와 같이 알파 합성 렌더링을 통해 통합되어 최종 3D 인간-객체 상호작용 장면을 생성합니다. - Total Loss: 모든 손실 항들을 통합하여 최종 최적화를 수행합니다 (식 8).
λ1,λ2,λ3는 각 손실 항의 가중치이며, 어닐링(annealing) 기법을 사용하여 최적화 과정에서 조정됩니다.
- H-NeRF (Human Neural Radiance Field):
