1. Intruduction
기존의 연구
- 단어의 밀도 등을 이용한 통계적 방법
- 그래프 중심의 임베딩
제안된 연구
- 문서의 토픽을 바탕으로 키워드 추출
- 따로 키워드 태깅을 할 필요가 없음
- SelfExplain라는 설명 가능한 문장 분류 모델을 활용
- 해당 모델의 출력을 문서의 핵심 구문으로 간주
- INSPECT: 특수 도메인으로 훈련된 모델
- INSPECT-GEN: 보편적인 언어 모델
2. INSPECT Framework
- 문장 분류 모델이 문장 내의 주요 키워들을 벡터 공간 내에서 활용한다는 가설을 활용
- 따라서 분류 모델인 SelfExplain을 문서 분류로 확장하여 연구
- 해당 연구는 하나의 문장만을 분류했으나, 이를 문서 전체를 분류하는 연구로 확장
- 해당 연구는 태깅된 데이터셋이 필요했으나, 비지도 학습으로 연구 확장
- 주제를 정한 후, 주제와 관련된 키워드를 추출하는 방식으로 모델 설계
2.1 해석 가능한 기본 모델
-
사후 해석 (Post-hoc interpretations of a trained model): 이 방법은 모델을 이미 학습시킨 후에 모델의 예측 결과를 해석하는 방식입니다. 즉, 학습이 완료된 모델이 왜 특정 결과를 예측했는지 사후적으로 분석하는 것입니다. (예시 인용: Towards robust interpretability with self-explaining neural networks, SELFEXPLAIN: A Self-Explaining Architecture for Neural Text Classifiers 등)
-
본질적으로 (설계 단계부터) 해석 가능한 모델 (Intrinsically (by-design) interpretable models): 이 방법은 모델을 설계하고 구축하는 단계부터 해석 가능성을 염두에 두어, 모델 자체가 그 작동 방식이나 예측 과정을 설명할 수 있도록 만드는 방식입니다. 이 논문에서 제안하는 INSPECT 프레임워크는 이 두 번째 접근 방식, 특히 SELFEXPLAIN: A Self-Explaining Architecture for Neural Text Classifiers 모델을 기반으로 합니다.
SelfExplain 네트워크
- 트랜스포머 기반 모델인 RoBERTa를 백본 네트워크로 사용
- Local Interpretability Layer: 입력 문장 내부의 피처 벡터
- Global Interpretability Layer: 훈련 데이터의 관련 문장
저자의 모델 구조
- 입력 샘플에서 중요 구문을 식별하기 위해 LIL 레이어만 사용.
- LIL 레이어는 Activation Difference를 사용해서 해당 문장을 분류하는데 각 구문들의 기여도를 수치화
- LIL레이어의 input data: 문장과 후보 키워드에 해당하는 구문들
- LIL레이어의 기능: 구문들의 기여도를 활성화 차이(activation difference)를 통해 정량화
2.2 Keyphrase Relevance Model
(1) 키워드 추출
-
모든 구문을 키워드 후보로 사용한 SelfExplain과 달리, 명사구를 후보로 사용. (키워드 추출이 목적이기 때문)
-
긴 문서를 구절로 나누고, 명사구가 구절의 주제를 예측하는 기여도를 계산
-
입력 문서(document)를 여러 텍스트 블록(text block)으로 나눕니다. 각 블록을 라고 할 때, 안에서 명사구(noun phrases) 등 후보 구문(candidates)들을 추출하여 집합 으로 만듭니다. N은 후보 구문의 개수입니다.
(2) RoBERTa 임베딩
-
사전학습된 RoBERTa 모델을 이용해서,
- 전체 텍스트 블럭 X에 대한 문맥적 표현을 [CLS] 토큰의 벡터 로 얻고,
- 각 후보 구문에 포함된 토큰들의 RoBERTa 임베딩을 모두 더해 해당 후보 구문의 표현 도 만듭니다.
-
예를 들어 문장 "사과는 과일"은 토크나이저에 따라 각각 "사과", "는", "과일"로 분리되었다면
입력은 형태가 되어 모델에 들어갑니다. -
모델은 이 토큰들 각각에 대해 벡터 임베딩을 내보내고, 출력은 [, , , ]가 됩니다.
-
여기서 는 통상적으로 전체 문장을 대표하는 벡터 표현으로 사용됩니다.
- BERT 계열 모델에서는 학습 과정에서 [CLS] 토큰 출력 벡터가 문장 레벨 분류 작업에 사용되도록 훈련됩니다.
- 즉, 자연스럽게 모델은 [CLS] 토큰 벡터를 통해 생성된 를 문장을 대표하는 벡터로 만들도록 조정됩니다.
- 이는 많은 실험적 결과에서 좋은 문서・문장 수준 표현으로 활용된다는 사실로 검증되어 왔죠.
- 하지만 완벽한 압축이란 의미보다는 문맥 정보가 응축된 벡터라고 이해하는 편이 정확합니다.
- 모델 구조와 학습 목표에 따라 달라질 수 있으니 완전 무결한 '모든 정보의 축약'은 아니고, 문서 분류에 적합한 임베딩이라고 이해하면 됩니다.
(3) 활성함수의 차이값 계산
-
각 후보 구문이 주제(topic) 예측에 얼마나 중요한지 평가하기 위해, 모델 입력에서 해당 후보 구문의 기여를 제거한 표현 를 계산합니다.
-
여기서는 ReLU 활성화 함수입니다.
-
이 방식은 후보 구문의 표현과 전체 문서 표현 간의 활성화 차이를 의미하며, 후보 구문 없이 모델이 어떻게 반응하는지 나타내려는 의도입니다.
-
-
ReLU 함수를 사용하는 이유
-
ReLU(Rectified Linear Unit)는 음수를 0으로 만들고 양수는 그대로 두는 활성화 함수입니다.
-
후보 구문 기여도 차이를 계산할 때, 음수 값이 있을 경우 부정적인 영향을 제거하거나 과도한 반전을 방지하려고 ReLU를 사용합니다.
-
즉, 음수 값이 포함되어 차연산 후 부호가 바뀌거나 해석이 어려워지는 것을 방지해, 의미 있는 활성화의 차이만 강조하기 위함입니다.
-
따라서 음수 값이 양수로 변하는 문제 자체보다는, 음수 활성화를 0으로 만들어 안정적인 기여도 계산을 하려는 목적입니다.
-
-
와 의 의미 및 정의
- : 후보 구문 i에 해당하는 토큰들의 임베딩 벡터 합산 결과입니다. 후보 구문의 문맥적 표현을 뜻합니다.
- : 전체 텍스트 블록 X 전체의 대표 벡터로, 문서 전체의 문맥 정보를 압축한 표현입니다.
- : 해당 후보 구문이 빠졌을 때의 표현
- : 전체 문장에 대한 표현
- 는 "후보 구문에서 전체 문장 표현을 뺀 차이"를 의미합니다.
- 예를 들어 후보 구문이 '사과'라면 사과에 대한 정보 손실이 얼마인지 알 수 있다. 는 음의 값을 가짐.
(4) 분류 레이어를 통한 확률 계산
-
이렇게 만든를 분류기(classifier) 계층(선형층, 가중치, 편향포함)에 통과시켜 각 후보 구문에 대한 주제 예측 레이블 분포를 구합니다.
-
는 멀티라벨 예측인지(시그모이드 함수) 다중 클래스 예측인지(소프트맥스 함수)에 따라 다릅니다.
-
멀티라벨 문제 (시그모이드 사용)
- 문서가 “스포츠”와 “정치” 두 가지 주제를 동시에 가질 수 있다고 합시다.
- 시그모이드 함수는 각 주제에 대해 독립적으로 확률을 계산하여,
- 스포츠 확률 = 0.8, 정치 확률 = 0.6 일 때, 둘 다 0.5 이상이면 두 주제 모두 속한다고 판단할 수 있습니다.
- 각 클래스가 독립적이므로 여러 라벨을 동시에 예측할 수 있는 멀티라벨 분류에 적합합니다.
-
다중 클래스 문제 (소프트맥스 사용)
- 문서가 정확히 한 가지 주제만 가질 수 있다고 합시다. 예를 들어 “사회”, “경제”, “문화” 중 하나.
- 소프트맥스 함수는 세 클래스의 확률 합이 1이 되도록 분포를 만듭니다.
- 예를 들어 “사회”=0.7, “경제”=0.2, “문화”=0.1과 같이 한 주제에 가장 높은 확률을 주고 선택합니다.
- 클래스들이 상호배타적일 때 적합한 함수입니다.
-
(5) 의 평균 계산
-
들을 모두 더해서 를 구하고, 이를 이용해 오차 함수 를 계산하는 것이 어떤 의미가 있는지 예시를 통해 이해해 보겠습니다.
-
상황: 문서 X 내에 3개의 후보 구문(cp_1, cp_2, cp_3)이 있다고 가정합시다. 각 후보 구문에 대해 모델은 주제 예측 확률 분포 , , 를 출력합니다.
-
각 후보 구문별 예측 확률이 다음과 같다고 가정:
- (예: 세 개 주제에 대한 확률)
-
이들을 단순히 평균 내면 (또는 더하면 스케일 차이지만 동일 개념),
-
는 문서 내 모든 후보 구문들이 모여서 형성하는 "전체 후보 구문들의 평균 주제 예측 분포"로 해석할 수 있습니다.
-
오차 함수 는 이 와 실제 주제 라벨 를 비교하며, 즉 "모든 후보 구문들의 기여를 통합한 예측"이 정답과 얼마나 일치하는지를 평가합니다.
-
의미:
- 만약 후보 구문들 중 일부만 주제 예측에 크게 기여하고 나머지는 기여도가 낮다면, 는 자연스럽게 중요한 후보 구문들의 예측 값에 더 영향을 받습니다.
- 즉, 후보 구문 각각이 정확하고 일관된 주제 예측 신호를 낼 때 도 좋은 예측 분포가 되어 오차가 줄어듭니다.
- 반대로 후보 구문들이 엉뚱한 예측을 하거나 일정한 기여를 하지 못하면 역시 정답과 차이가 커집니다.
-
따라서 들의 합 또는 평균인 를 오차에 쓰는 것은 "모든 후보 구문이 종합해서 얼마나 잘 주제를 설명하는가"에 대한 측정이며, 이것이 바로 모델이 각 후보 구문 중요도 뿐 아니라 전체 문서 해석력까지 고려하도록 학습하는 방식입니다.
-
요약하면, 각 후보 구문의 예측을 합쳤을 때 좋은 예측 분포를 만들도록 훈련함으로써, 중요 구문이 주제 예측에 큰 영향을 끼치도록 모델을 유도하는 효과가 있습니다.
(6) 오차함수
-
: 전체 텍스트 정보를 바탕으로 얻은 토픽 분류 확률
-
: 모든 를 평균낸 토픽 분류 확률
-
: 정답 토픽 와 전체 문장을 통한 예측사이의 크로스 엔트로피 손실
(주제 예측 정확도 향상 목적) -
: 모든 후보 구문의 예측 분포의 평균와 정답 간의 크로스 엔트로피 손실
(즉 후보 구문들이 주제 예측에 기여하는지를 반영)
-
최종 손실 함수는 이 둘을 가중합한 형태
- 는 정규화 파라미터로, 두 오차간의 비율 조절
이 과정을 통해 INSPECT는 주제 분류 성능을 높이면서 동시에 주제 예측에 영향력이 큰 후보 구문들을 해석 가능한 형태로 밝힐 수 있습니다. 이 후보 구문들이 바로 문서의 핵심 구문(keyphrases)으로 사용됩니다.
수식
- : 전체 라벨(토픽)의 개수
- : 실제 정답 레이블 벡터의 j번째 값 (정답인 토픽이면 1, 아니면 0인 다중 라벨 설정)
- : 문서 전체 입력에 관해 모델이 예측한 j번째 토픽에 대한 확률값 (0~1 사이)
예시
- 문서가 3개의 토픽 중 일부에 속한다고 가정합시다 (토픽1, 토픽2, 토픽3).
- 실제 정답 라벨이
[1, 0, 1](즉, 토픽1과 토픽3에 속함) - 모델이 예측한 확률 분포는 =
[0.8, 0.1, 0.7]
그러면
- 여기서 는 자연로그를 사용한다고 가정
- 이므로 두번째 항은 계산에 영향 안 줌
즉, 모델이 토픽1과 토픽3에 대해 높은 확률을 예측할수록 (0.8, 0.7 같이) 이 손실 값은 작아집니다. 손실 값이 작다는 것은 모델 예측이 정답에 가깝다는 뜻입니다.
-
손실 감소를 위해서는 모델이 예측한 확률에서 실제 정답 토픽(1번, 3번) 확률을 더 높여야 합니다.
-
즉, 와 을 더 1에 가깝게 올리도록 학습파라미터가 조정되어야 하며,
-
는 정답이 0이므로 크게 신경 쓰지 않아도 됩니다.
-
모델이 예측한 확률이 개선되어 다음과 같이 예측할 수 있습니다:
- 이 때 손실은,
- 손실 값이 에서 로 감소하여 모델 예측이 정답과 더 가까워졌음을 의미합니다.
요약
- : 전체 문서 수준의 토픽 분류 정확도
- : 키워드 후보들의 예측 분포의 평균에 대한 토픽 분류 정확도
(7) 키워드 추출
전제조건
- 전체 클래스(레이블): Y = {음식, 스포츠, 경제}
- 문장: "사과는 과일이다"
- 후보 키워드: 사과, 과일, 이다
- (음식: 0.85, 스포츠: 0.05, 경제: 0.10)
1단계: 각 후보 키워드에 대한 모델 출력 확률 분포 ()
| 후보 키워드 | |
|---|---|
: 번째 키워드가 삭제되었을 때의 예측 확률
: '이다'가 삭제되고 '사과', '과일'만 남았으므로 오히려 확률이 0.90으로 상승
2단계: 영향도 점수 계산 (각 클래스별 뺄셈 연산)
| 후보 키워드 | 음식 | 스포츠 | 경제 |
|---|---|---|---|
| 0.85 - 0.60 = 0.25 | 0.05 - 0.12 = -0.07 | 0.10 - 0.28 = -0.18 | |
| 0.85 - 0.55 = 0.30 | 0.05 - 0.10 = -0.05 | 0.10 - 0.35 = -0.25 | |
| 0.85 - 0.90 = -0.05 | 0.05 - 0.02 = 0.03 | 0.10 - 0.08 = 0.02 |
3단계: 각 후보 키워드가 어느 클래스에 긍정적인 영향()을 미치는지 판단
| 후보 키워드 | 영향력 있는 클래스 (양수 ) |
|---|---|
| 음식 (0.25) | |
| 음식 (0.30) | |
| 스포츠 (0.03), 경제 (0.02) |
4단계: 키프레이즈 선정 기준에 따라 선택
- 키프레이즈 집합 는 문장의 토픽 에 대해 양의 값을 가진 후보로 구성됩니다.
- 따라서:
(8) Distant Supervisation을 활용한 키워드 추출 기법
Distant Supervisation
-
사람이 직접 일일이 라벨링하지 않고, 기존에 존재하는 다른 정보(예: 자동으로 생성된 주제 레이블, 외부 지식베이스 등)를 활용해 간접적으로 학습 데이터의 레이블을 만들어 모델을 훈련하는 방법.
-
직접적인 감독학습(supervised learning)과 비지도학습(unsupervised learning)의 중간 단계처럼, 사람이 만든 정확한 라벨 없이도 비교적 신뢰할 수 있는 라벨을 생성해서 학습에 활용하는 기술
저자들의 기법
-
전문 도메인에서 키프레이즈에 대한 주석을 얻는 것은 어렵기 때문에 감독 학습 방식은 한계가 있음
-
INSPECT는 인간이 직접 키프레이즈를 주석하지 않아도 되도록, 주제 분류라는 다중 클래스 태스크의 거리 지도학습(distant supervision) 기법을 사용
-
주제 분류에서 모델 해석을 통해 문서 내 영향력 있는 구문(phrases)을 키프레이즈로 식별함
-
문서의 다양한 주요 주제를 대표하는 키프레이즈 집합 확보가 중요하며, 주제 정보가 이를 도와줌
-
뉴스 등 일부 도메인은 주제 레이블이 있어 감독학습 가능하지만, 과학 논문, 법률 문서 등 주석이 부족한 분야는 비지도 방식으로 주제 레이블을 추출해 활용 가능
-
따라서 INSPECT는 주제 레이블이 있을 때는 이를 활용하고 없으면 주제모델링 같은 비지도 방법으로 생성한 라벨로 학습 가능
3. Experimental Setup
3.1 Evaluation Datasets
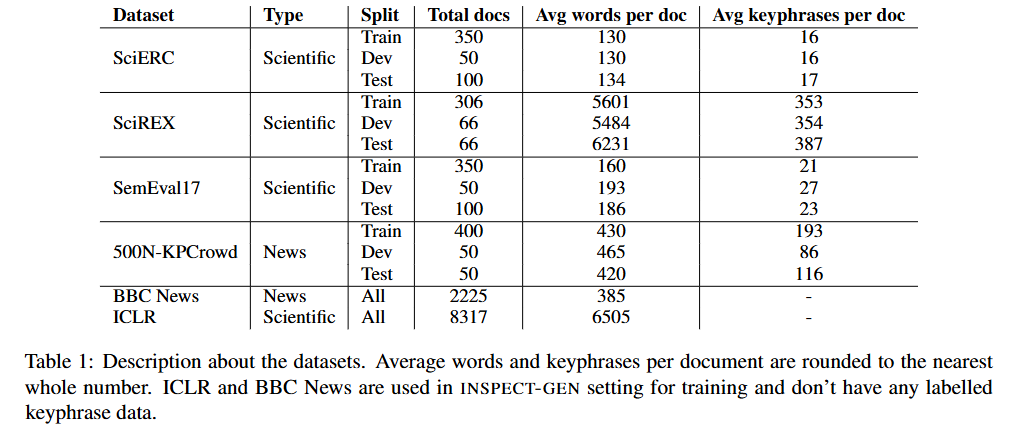
- 과학 출판물과 뉴스, 두 가지 도메인에 대한 키워드 데이터셋
3.2 Topic Labels
- 모델의 간접 지도 학습을 위해 문서마다 토픽을 어노테이션 함
- BBC News, ICLR 데이터셋은 어노테이션 된 라벨이 없음
- 500N-KPCrowd: 스포츠, 정치, 연예 등의 카테고리가 존재하여 이를 그대로 사용 (단일 클래스)
- 과학 문서들은 따로 토픽이 없어서, 토픽 모델(Gallageher et al., 2017)을 통해 생성
- 75개의 토픽을 생성하고, 멀티 레이블로 문서별 어노테이션 진행.
3.3 Training Data and Settings
INSPECT
동일한 토픽의 train 데이터로 학습하고, test로 검증
INSPECT-Gen
-
train 데이터셋에 접근하지 않음.
-
과학 문서에 대한 결과를 보기 위해 ICLR 논문 8,317편을, 뉴스에 대한 결과를 보기 위해 BBC News 2225개를 학습시킴.
-
트레인 데이터와 토픽이 일치하지는 않음. 예를 들어 테스트 데이터로 쓰인 SemEval-2017은 물리학 논문지임.
-
ICLR 혹은 BBC News 코퍼스를 통하여 토픽 모델이 생성한 75개의 레이블을 기준으로 테스트 데이터의 키워드를 검증하는 방식. 이 중 22개의 무의미한 레이블은 지우고, 나머지 레이블들로 멀티 레이블을 할당.
-
BBC News 코퍼스는 활용하며, 각 문서는 미리 지정된 5개 주제(비즈니스, 엔터테인먼트, 정치, 스포츠, 기술) 중 하나로 레이블링 되어있음.
-
이러한 학습 방법은 토픽에 의존적이지 않은 모델 성능을 검증할 수 있음.
모델 학습 및 하이퍼 파라미터 세팅
-
문서 전처리: 학습과 추론 시 문서를 512 토큰 크기의 텍스트 블록으로 나누고, 블록들은 128 토큰 정도 겹치도록 설정함.
-
후보 구 추출: Shang et al. (2018) (https://aclanthology.org/2020.acl-main.30.pdf)의 방법론과 동일하게 각 블록에서 명사 구(Noun Phrases, NP)를 후보 구로 간주하고, Berkeley Neural Parser를 사용해 명사 구를 추출함.
-
하이퍼파라미터: SciERC 개발 세트 성능을 기준으로 모든 하이퍼파라미터를 결정함.
-
최종 학습 설정: 배치 크기 8, 학습률 2e-5, 학습 에폭 10으로 최종 설정.
-
분류기 층 차원: 64로 설정.
-
정규화 파라미터 α: 0.5로 설정, 이는 설명 손실과 분류 손실을 적절히 결합하는 데 사용됨.
-
부록 A.2에 구현 세부사항과 하이퍼파라미터 탐색 과정을 자세히 설명함.
-
하이퍼파라미터 선정:
- SciERC 데이터셋의 개발셋 성능을 기준으로 하이퍼파라미터를 선택함.
- 실험한 학습률: , , , , 중 최종적으로 를 선택.
- 배치 크기: 4, 8, 12, 16 중 8을 선택.
- 분류기 층 가중치 행렬 크기: 16, 32, 64, 128 시도 후 64 선택.
- 정규화 하이퍼파라미터 : 0.5로 고정, 0.1~0.9 사이 값을 시험했으나 큰 차이 없음.
-
모델:
- RoBERTa와 XL-NET 기반 인코더를 고려했으나, 계산 시간을 줄이기 위해 RoBERTa 선택.
-
훈련:
- 주제 예측 task의 평가 지표인 가중 F1 점수를 기준으로 모델 저장.
- 2대의 Nvidia 2080Ti GPU 환경에서 3시간 미만 소요 (ICLR 데이터셋의 경우 8시간 소요).
- 모든 결과는 단일 실행에서 도출.
이런 구성은 모델 효율성과 성능 간의 균형을 맞추기 위한 실험적 선택임을 알 수 있습니다.
3.4 Baselines
-
본 논문에서는 7가지의 기존 비지도 키프레이즈 추출 기법과 비교합니다.
-
기법들은 크게 세 가지 유형으로 나뉩니다:
- 통계 기반 방법: Yake, TF-IDF, AutoPhrase
- 그래프 기반 방법: TopicRank
- 신경 임베딩 기반 방법: SifRank, UKE-CCRank, MDERank(BERT)
-
INSPECT 설정에서는 학습 데이터 문서만 활용하는 기법(TF-IDF, TopicRank, Yake, AutoPhrase, UKE-CCRank, MDERank)과 비교합니다.
-
INSPECT-GEN 설정에서는 외부 코퍼스로 학습한 TF-IDF, AutoPhrase, 그리고 SifRank(외부 코퍼스를 활용해 각 구의 사전 확률을 산출)와 비교합니다.
-
이처럼 각 설정에 따라 비교 대상과 외부 데이터 활용 여부가 달라, INSPECT의 범용성과 성능을 다양한 상황에서 평가합니다.
-
INSPECT는 문서 내에서 각각의 키프레이즈 발생 위치(스팬 단위)를 식별할 수 있는 반면, SifRank, AttentionRank, UKE-CCRank, MDERank는 키프레이즈 단위(문구 단위)만 식별함.
-
즉, INSPECT는 구체적으로 텍스트 내 위치까지 구분하여 키프레이즈를 추출하지만, 다른 기법들은 문서 전반에 걸친 키프레이즈 목록만 생성함.
-
공통된 평가를 위해, 다른 기법들의 키프레이즈를 문서 내 모든 발생 위치와 매칭하여 스팬 단위 평가로 맞춤.
-
INSPECT는 문구마다 관련성 점수가 양성인 모든 구간을 선택하는 기준을 사용하기 때문에, 상위 K개의 후보만 선택하는 방식과 직접적인 비교가 어려움.
-
따라서, 평가의 공정성을 위해 INSPECT가 평균적으로 선택하는 키프레이즈 개수를 기준으로 K값을 설정하여 다른 기법들의 결과를 비교함.
-
Span Level Keyphrase (스팬 레벨 키프레이즈):
-
텍스트 내에서 키프레이즈가 위치한 특정 시작과 끝 지점(구간, 즉 span)을 명확하게 구분하고 표시하는 방식입니다.
-
예를 들어, 문장 내에서 "neural networks"라는 키프레이즈가 10번째 단어부터 11번째 단어까지 위치한다고 정확히 지정합니다.
-
각각의 키프레이즈 출현 위치를 별도로 구분하기 때문에 문서 내에서 중복된 키프레이즈가 여러 번 나오면 각각 모두 인식할 수 있습니다.
-
문서 내 키프레이즈의 정확한 위치 정보를 활용할 수 있어, 세밀한 분석이나 후속 처리가 가능하다.
-
-
Phrase Level Keyphrase (프레이즈 레벨 키프레이즈):
-
단순히 문서 내에 존재하는 키프레이즈 문구(phrase)들을 식별하는 방식으로, 문서 내 위치나 출현 횟수를 고려하지 않고 중복 없이 문구 단위로 추출합니다.
-
SifRank, AttentionRank, UKE-CCRank, MDERank가 이에 해당.
-
"neural networks"라는 키프레이즈가 문서 내 여러 군데 나와도 하나의 키프레이즈로만 처리합니다.
-
즉, 키프레이즈 텍스트 자체의 존재 여부가 중요하며, 위치 정보는 제공하지 않습니다.
-
평가 시 키프레이즈 단위의 정확도만 측정할 수 있고, 위치 기반 분석에는 부적합할 수 있습니다.
-
따라서 평가를 할 때는 각 키프레이즈와 매치 되는 모든 곳을 매핑하여 INSPECT와 비교.
-
정리하자면,
| 구분 | 의미 | 위치 정보 | 중복 인식 | 활용 용도 |
|---|---|---|---|---|
| Span Level | 텍스트 내 구간(시작-끝 위치)까지 지정 | 있음 | 있음 | 상세 위치 기반 분석, 문서 내 정확한 위치 활용 |
| Phrase Level | 키프레이즈 문구 단위로만 추출 | 없음 | 없음 | 문서 내 키프레이즈 목록 추출, 위치 정보 불필요한 경우 |
3.4 Evaluation Metrics
Topic Prediction
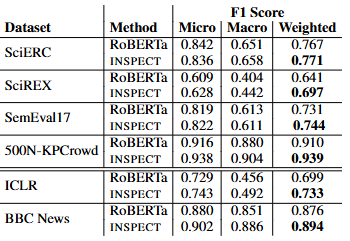
토픽 예측의 경우 RoBERTa보다 INSPECT가 더 높은 확률을 보였음.
Keyphrase Extraction Evaluation
- 논문에서 제안하는 keyphrase 추출 평가 방식은 "정확한(Exact Match)"과 "부분 일치(Partial Match)" 두 가지를 모두 반영합니다.
- 정확한 일치(Exact Match)는 예측된 keyphrase가 참조(keyphrase의 정답)와 완전히 동일한 경우만을 인정하는 엄격한 평가입니다.
- 반면, 부분 일치(Partial Match)는 예측된 keyphrase와 참조 keyphrase가 단어 수준에서 일부 겹치는 경우도 인정하여 평가하는 좀 더 관대한 방식입니다.
- Rousseau and Vazirgiannis (2015)은 부분 일치 방식을 탐색하였으나, 이것이 때때로 너무 관대해서 실제 성능을 과대평가할 수 있다고 지적합니다.
- Papagiannopoulou and Tsoumakas (2019)는 경험적 연구를 통해, 정확한 일치와 부분 일치 F1 점수의 평균을 평가 지표로 사용하는 것이 더 적절하다고 제안합니다.
- 이 논문은 이 권고를 받아들여, keyphrase 예측 성능을 정확한 일치 F1과 부분 일치 F1의 평균값을 사용하여 평가합니다.
- 이렇게 하면 지나치게 엄격하거나 관대하지 않은 균형 잡힌 평가가 이루어집니다.
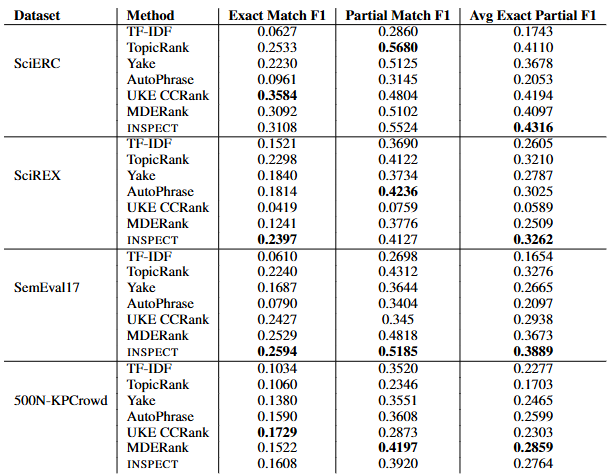
- 표는 4개 데이터셋(SciERC, SciREX, SemEval17, 500N-KPCrowd)에 대해 여러 방법들의 정확한 일치(Exact Match F1), 부분 일치(Partial Match F1), 그리고 이 둘의 평균 값(Avg Exact Partial F1)을 보여줌
- INSPECT는 대부분의 경우에서 부분 일치 F1 점수에서 가장 높거나 두번째로 높은 점수를 기록
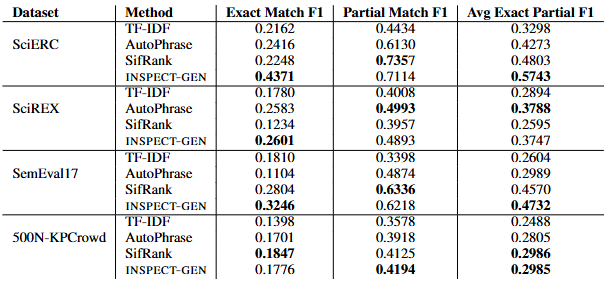
- 표는 네 개의 데이터셋(SciERC, SciREX, SemEval17, 500N-KPCrowd)에 대해 네 가지 방법(TF-IDF, AutoPhrase, SifRank, INSPECT-GEN)의 keyphrase 추출 성능을 Exact Match F1, Partial Match F1, 그리고 이 두 값을 평균한 Avg Exact Partial F1로 비교.
- INSPECT-GEN이 모든 데이터셋에서 평균 F1 점수가 가장 높거나 거의 최고 수준임을 보여주어, 제안한 방법의 우수함을 입증.
- 특히, ICLR 컴퓨터 논문이나 BBC 뉴스를 통해 키워드를 학습한 모델이 전혀 다른 장르인 물리 논문 등에서 잘 작동.
- 이는 새로운 도메인에서 INSPECT가 강건하게 작동함을 의미.
- 또한 인간이 라벨링한 뉴스 데이터셋과, 토픽 모델이 붙인 토픽에 대해서도 모두 강건하게 작동함.
