Abstract
- 핵심 문제: 이미지에서 객체의 포즈를 추정하는 것은 3D 장면 이해에 매우 중요하지만, 기존의 최신 방법들은 학습 데이터에서 보지 못한 새로운 객체(unseen objects)를 다룰 때 성능이 크게 저하되는 문제가 있습니다.
- 원인 분석: 연구자들은 이러한 성능 저하의 주요 원인이 이미지 특징(image features)의 일반화(generalizability) 능력이 부족하기 때문이라고 분석했습니다.
- 새로운 접근 방식: 이 문제를 해결하기 위해, 이 논문에서는 보지 못한 객체 모델링에 상당한 잠재력을 가진 확산 모델(diffusion models, 예: Stable Diffusion High-resolution image synthesis...)의 특징을 심층적으로 분석하고, 이를 객체 포즈 추정에 혁신적으로 도입했습니다.
- 제안하는 방법: 확산 모델의 특징을 효과적으로 포착하고 결합(aggregate)하기 위해 세 가지 고유한 네트워크 구조(architectures)를 제안했습니다. 이를 통해 다양한 세분성(granularity)의 확산 특징을 활용하여 객체 포즈 추정의 일반화 능력을 크게 향상시켰습니다.
- 연구 결과: 제안된 방법은 LM, O-LM, T-LESS의 세 가지 인기 벤치마크 데이터셋에서 최신 방법들보다 상당한 성능 향상을 보여주었습니다. 특히, 보지 못한 객체에 대한 정확도가 이전 최고 성능(Templates for 3d object pose es...)보다 훨씬 높게 나타났습니다 (예: Unseen LM에서 97.9% 대 93.5%, Unseen O-LM에서 85.9% 대 76.3%). 이는 제안된 방법의 강력한 일반화 능력을 증명합니다.
1. Introduction
-
Object Pose Estimation의 중요성: 이미지에서 객체의 Pose를 추정하는 것은 로봇 조작, 증강 현실 등 다양한 실제 응용 분야에서 매우 중요합니다. 그리고 이는 딥 러닝의 발전 덕분에 성능이 크게 향상되었습니다.
-
Unseen Object 문제: 하지만 기존 방법들은 학습 데이터에 없던 객체(Unseen objects)에 대해 성능이 크게 저하되는 문제를 겪습니다. 이는 이미지 특징의 일반화 능력이 부족하기 때문이라고 저자들은 분석합니다.
Contribution
-
Diffusion Feature의 혁신적인 활용: Diffusion model의 특징(Diffusion features)이 Unseen object 모델링에 큰 잠재력이 있음을 심층적으로 분석하고, 이를 객체 Pose Estimation에 창의적으로 통합했습니다. 저자들은 Diffusion features의 Aggregation(통합)을 객체 Pose Estimation에 체계적으로 조사하고 활용한 최초의 연구라고 언급합니다.
-
효과적인 Aggregation 네트워크 제안: Diffusion features의 다양한 동적 특성(dynamics)을 효과적으로 포착할 수 있는 세 가지 Aggregation 네트워크 아키텍처를 제안했습니다. 이를 통해 객체 Pose Estimation의 일반화 성능을 크게 향상시켰습니다.
-
State-of-the-art 성능 달성: 세 가지 주요 벤치마크 데이터셋(LM, O-LM, T-LESS)에서 기존 State-of-the-art 방법들보다 훨씬 뛰어난 성능을 달성했습니다. 특히 Unseen object 데이터셋에서 상당한 성능 향상(Unseen LM에서 97.9% vs. 93.5%, Unseen O-LM에서 85.9% vs. 76.3%)을 보여, 제안 방법의 강력한 일반화 능력을 입증했습니다.
2. Related Works
-
객체 포즈 추정 개요: 이미지에서 객체의 포즈(위치와 방향)를 추정하는 것은 컴퓨터 비전 분야의 기본적인 과제이며, 최근 딥러닝 기술의 발전으로 큰 성과를 거두고 있습니다.
-
학습 기반 접근 방식: 최근 객체 포즈 추정 분야는 학습 기반 접근 방식이 주를 이루고 있으며, 크게 세 가지로 나눌 수 있습니다.
-
간접 방법(Indirect methods): 이미지의 2D 특징점과 객체의 3D 모델 간의 대응 관계를 설정한 후, PnP(Perspective-n-Point) 알고리즘(3D 포인트 클라우드와 2D 이미지 피처 포인트를 알고 있을 때 카메라 포즈를 추정하는 알고리즘) 등을 사용하여 포즈를 계산합니다. 이 방법들은 주로 정확한 2D-3D 대응 관계를 얻는 데 초점을 맞춥니다.
-
직접 방법(Direct methods): 객체의 포즈를 회귀(regression) 문제로 다루어 이미지에서 포즈를 직접 출력합니다. 일부 방법은 포즈 공간을 범주로 나누어 분류 문제로 해결하기도 합니다.
-
템플릿 기반 방법(Template-Based Methods): 3D 모델을 사용하여 다양한 포즈로 렌더링된 템플릿 이미지 세트를 생성합니다. 입력 이미지와 이 템플릿 이미지를 비교하여 가장 유사한 템플릿의 클래스와 포즈를 입력 이미지에 할당하는 방식입니다. 이 논문에서 중점적으로 다루며, 해당 방식은 단순하고 일반화 가능성이 높다는 장점이 있습니다.
-
-
미등록 객체(Unseen Object) 포즈 추정: 최근 연구에서는 학습 과정에 사용되지 않은 새로운 객체의 포즈를 추정하는 문제에 관심이 높아지고 있습니다. 템플릿 기반 방법이 미등록 객체에 어느 정도 일반화 능력을 보인다는 점에 착안하여, 최근 연구들이 이 문제를 해결하려 시도하고 있습니다. 하지만 여전히 학습된 객체와 미등록 객체 간의 성능 격차가 존재하며, 이 논문은 이 격차를 줄이는 것을 목표로 합니다.
3. Methodology
3.1. Object pose estimation
-
템플릿 기반 방식에서의 Feature(특징)의 역할
-
템플릿 기반 방식에서는 입력 이미지
I와 템플릿 이미지들을 Feature Space로 매핑하여 유사도를 계산합니다. -
이 과정은 다음 수식으로 표현됩니다.
I: 입력 이미지입니다.- : 이미지를 Feature Space로 변환하는 인코더(네트워크)를 의미합니다.
F: 를 통해 입력 이미지I에서 추출된 Feature(특징) 벡터입니다.
-
이 Feature
F가 얼마나 효과적인지가 실제 이미지와 템플릿 이미지 간의 유사도를 정확하게 계산하는 데 결정적으로 중요하며, 이는 Object Pose Estimation의 성공에 매우 큰 영향을 미칩니다.
-
3.2. Motivation: feature matters
이 섹션에서는 보지 못한 객체(unseen objects)에 대한 객체 포즈 추정(Object Pose Estimation)의 어려움과 이를 해결하기 위해 확산 모델(diffusion models)의 피처를 활용하는 동기를 설명합니다. 주요 내용은 다음과 같습니다.
-
문제점: 최근 객체 포즈 추정, 특히 템플릿 기반(template-based) 방법은 학습된 객체(seen objects)에서는 좋은 성능을 보이지만, 보지 못한 객체를 다룰 때 성능이 크게 저하됩니다. 최신 방법들이 보지 못한 객체에 대한 성능을 개선하려 시도했지만, 여전히 학습된 객체와 보지 못한 객체 간의 성능 격차가 존재합니다.
-
원인 분석: 이러한 성능 저하의 주요 원인은 이미지 피처(image features)가 보지 못한 객체에 대해 잘 일반화(generalize)되지 못하기 때문이라고 분석합니다.
-
확산 피처(Diffusion Features)의 잠재력: 텍스트-이미지 확산 모델(text-to-image diffusion models)이 고품질 이미지를 생성하는 데 강력한 성능을 보이며, 다양한 시나리오에 대해 피처가 잘 일반화된다는 점에 주목했습니다. 이러한 일반화 능력은 다음과 같은 요인 덕분이라고 설명합니다.
- 풍부한 의미론적 내용을 가진 Text supervision를 통해 discriminative features를 학습합니다.
- 확산 모델은 다양한 타임스텝(timesteps)에서 정보를 인코딩하여 다양한 세분성(granularity)과 속성을 포착합니다. 여기서 세분성이란, 모델이 초기 단계에서는 이미지의 가장 기본적인 특징(예: 가장자리, 텍스처)과 같은 '미세한(fine)' 세분성의 피처를 학습하고, 후반 단계에서는 객체의 전체적인 모양이나 의미론적인 내용과 같은 '거친(coarse)' 세분성의 피처를 골고루 학습한다는 의미입니다.
- 확산 모델은 장면 기하학(scene geometry), 깊이(depth) 등 3D 특성(3D characteristics)을 인코딩할 수 있습니다.
- Stable Diffusion과 같은 모델은 방대한 학습 데이터의 이점을 통해 다양한 시나리오에서 판별적인 피처를 학습합니다.

-
시각화를 통한 확산모델의 피처 유용성 검증: LINEMOD 데이터셋에서 학습된 객체(램프)와 보지 못한 객체(고양이) 이미지를 선택하여, 최신 방법과 Stable Diffusion의 중간 레이어(Layer 5, Layer 12)에서 추출한 피처를 시각화했습니다.
-
최신 방법의 피처는 학습된 램프 객체에 대해서는 Query 이미지와 Template 이미지 간의 유사도를 잘 측정했지만, 보지 못한 고양이 객체에 대해서는 차이를 보였습니다.
-
반면, Stable Diffusion의 피처는 학습되지 않은 램프와 고양이 객체 모두에 대해서도 유사도를 잘 측정하는 잠재력을 보여주었습니다. 특히, Layer 5는 램프에, Layer 12는 고양이에 대해 더 좋은 성능을 보였습니다. (주성분 분석을 했을 때, 쿼리와 템플릿의 색상이 같을수록 피처 공간에서 비슷한 위치에 있다는 의미입니다.)
-
-
결론 및 아이디어:
-
보지 못한 객체에 대한 기존 방법의 피처는 한계가 있는데 반해, Stable Diffusion과 같은 확산 모델의 피처가 보지 못한 객체 모델링에 큰 잠재력이 있음을 시사합니다.
-
또한, 확산 모델의 다른 레이어에서 추출된 피처가 서로 다른 특성을 포착하므로(각 객체에 따라 효율적인 피처맵이 Layer 5인지, 12인지 다름), 이러한 피처들을 통합(aggregation)하면 보지 못한 객체에 대한 강한 일반화 능력을 얻을 수 있을 것이라는 아이디어를 제시합니다.
-
3.3. Diffusion features
3.3.1 Diffusion process
텍스트-이미지 확산 모델(Text-to-image diffusion models)의 확산 과정은 순방향(forward) 과정과 역방향(reverse) 과정을 포함합니다. 논문에서 언급된 DDIM(Denoising Diffusion Implicit Models) 샘플링 절차는 다음과 같이 정의됩니다.
이 공식은 특정 시점()에서의 노이즈가 포함된 샘플()이 어떻게 구성되는지를 보여줍니다. 각 항의 의미는 다음과 같습니다.
- : 시점 에서의 노이즈가 포함된 샘플입니다.
- : 초기 깨끗한 이미지 샘플입니다.
- : 미리 정의된 노이즈 스케줄(noise schedule)입니다. 각 시점마다 얼마나 많은 노이즈가 추가되거나 제거되는지를 결정하는 계수입니다.
- : 표준 정규 분포()에서 무작위로 생성된 노이즈입니다.
이 공식을 바탕으로 확산 과정은 다음과 같이 진행됩니다.
-
순방향 과정 (Forward Process):
-
이 과정은 훈련 데이터셋을 만들기 위해 사용됩니다. 모델 자체를 훈련시키는 과정은 아닙니다.
-
깨끗한 초기 샘플()에서 시작합니다.
-
단계에 걸쳐 가우시안 노이즈()가 점진적으로 추가됩니다.
-
결과적으로 와 같이 노이즈가 점점 많아지는 샘플 시퀀스가 생성됩니다.
-
시점 가 무한대로 접근할수록 최종 샘플()은 등방성 가우시안 분포(isotropic Gaussian distribution)에 수렴합니다.
-
-
역방향 과정 (Reverse Process):
-
이 과정이 바로 신경망 모델을 학습시키는 핵심 단계입니다.
-
모델은 순방향 과정에서 만들어진 노이즈가 포함된 이미지()를 입력받습니다.
-
모델의 목표는 이 에서 추가된 노이즈()를 예측하도록 훈련됩니다.
-
모델이 예측한 노이즈와 순방향 과정에서 얻은 실제 노이즈를 비교하여 오차(Loss)를 계산합니다. 이 오차를 줄이는 방향으로 모델의 가중치를 업데이트합니다.
-
만약 텍스트 프롬프트를 입력받는 모델이라면, 각 denoising 단계()에서 은 이전 샘플 와 텍스트 프롬프트 를 사용하여 결정됩니다.
-
최종 denoising 단계 후, 이 복원되어 깨끗한 이미지 샘플을 얻게 됩니다.
-
본 논문에서는 조건부 프롬프트 없이 깨끗한 이미지에서 직접 특징을 얻기 위해, 비조건부 텍스트 임베딩(unconditioned text embedding)을 사용하고 Stable Diffusion 모델을 매우 작은 시점()에서 한 번만 실행합니다. 시점이 작을 때는 확산 모델의 관점에서 깨끗한 이미지가 주로 denoised된 이미지로 처리되기 때문입니다.
에서 한 번만 실행하는 이유
일반적인 텍스트-이미지 디퓨전 모델의 이미지 생성 과정은 다음과 같습니다.
-
완전한 노이즈 이미지()에서 시작합니다.
-
학습된 신경망 모델(보통 U-Net)을 사용하여 현재 시점()의 노이즈 이미지()에서 노이즈를 예측하고 제거하는 과정을 수십, 수백, 혹은 수천 번 반복(iteratively) 수행합니다.
-
이 반복 과정을 통해 점진적으로 노이즈를 제거하여 최종적으로 깨끗한 이미지()를 얻습니다.
즉, 이미지를 생성하는 과정은 모델을 여러 번 반복적으로 실행하는 것입니다.
반면에 논문을 포함한 여러 연구에서 디퓨전 모델의 특징 맵(Feature Map)을 추출할 때는 이와 다른 방식을 사용합니다. 여기서 '매우 작은 시점(t=0)에서 한 번만 실행한다'는 것은 다음과 같은 의미입니다.
-
입력 이미지 사용: 노이즈에서 시작하는 것이 아니라, 특징을 추출하고자 하는 원본 이미지(깨끗한 이미지)를 모델의 입력으로 사용합니다.
-
특정 시점() 설정: 모델에 이미지를 입력할 때, 이 이미지가 디퓨전 과정의 어느 시점에 해당하는지를 알려주는 '시점 정보'()도 함께 입력합니다. 여기서 '매우 작은 시점()'을 설정하는 것입니다.
-
모델의 단일 실행 (Single Pass): 이미지를 입력하고 시점을 으로 설정한 후, 모델의 신경망(U-Net 등)을 단 한 번만 통과(forward pass)시킵니다. 이미지를 생성할 때처럼 반복적인 노이즈 제거 과정을 수행하지 않습니다.
-
중간 레이어 출력 사용: 이 단 한 번의 실행 과정에서 신경망의 중간 레이어들에서 나오는 활성화 값(activations)이나 출력 값들을 특징 맵으로 사용하는 것입니다.
왜 이렇게 할까요?
-
: 디퓨전 모델에서 시점 은 이론적으로 노이즈가 전혀 없는 깨끗한 이미지 상태를 의미합니다. 따라서 깨끗한 원본 이미지를 입력하고 시점을 으로 설정하면, 모델은 해당 이미지를 '가장 노이즈가 적은 상태'로 인식하고 내부적으로 처리하게 됩니다. 이때 모델의 중간 레이어에서 나오는 특징들은 입력된 원본 이미지 자체의 시각적 특성을 잘 반영하게 됩니다. 시점이 커질수록 모델은 입력 이미지를 노이즈가 많이 섞인 상태로 인식하고, 이때 추출되는 특징은 노이즈의 영향이나 생성 과정 중의 다른 정보가 더 많이 포함될 수 있습니다. 따라서 은 원본 이미지의 순수한 특징을 얻기에 적합한 시점입니다.
-
한 번만 실행: 특징 추출은 이미지를 생성하는 작업이 아니라, 주어진 이미지를 분석하여 그 정보를 벡터나 맵 형태로 표현하는 작업입니다. 신경망 모델의 각 레이어는 입력 이미지를 변환하면서 다양한 수준의 특징을 추출합니다. 따라서 모델을 한 번만 통과시켜도 이미 각 레이어에서 입력 이미지에 대한 풍부한 정보가 담긴 중간 특징 맵이 나오게 됩니다. 반복적인 실행은 이미지를 점진적으로 변화시키는 생성 과정에 필요한 것이며, 특징 추출에는 불필요합니다.
3.3.2 Diffusion features aggregation
확산 모델의 특징들을 효과적으로 결합하여 객체 포즈 추정에 사용하기 위한 '확산 특징 집계(Diffusion features aggregation)' 방법입니다. 이 섹션의 목표는 확산 모델의 여러 레이어에서 얻은 특징들을 통합하여 보이지 않는(unseen) 객체에 대해서도 높은 일반화 성능을 보이는 특징을 만드는 것입니다. 이 과정은 다음과 같이 설명됩니다.
-
필요성: 이전 섹션(3.2 Motivation)의 분석 결과(Fig. 2)에서 보듯이, 확산 모델의 각기 다른 레이어에서 추출된 특징들이 객체의 종류(예: 보이는 '램프', 보이지 않는 '고양이')에 따라 다른 유용성을 보인다는 것을 발견했습니다. 즉, 어떤 레이어의 특징은 특정 객체에 더 적합할 수 있습니다. 따라서 다양한 레이어의 특징을 '집계(aggregation)'하면 여러 종류의 객체 및 시나리오에 대해 더 잘 일반화될 수 있는 특징을 얻을 수 있다는 아이디어에서 출발합니다.
-
집계 과정: 논문에서는 확산 모델의 개의 레이어에서 얻은 원본 확산 특징들 을 하나의 통합된 특징 으로 만들기 위해 학습 가능한 아키텍처를 사용합니다. 이 과정은 두 가지 핵심 구성 요소로 이루어집니다.
- Extractor (): 원본 확산 특징들의 차원(dimension)을 동일하게 맞추고, 객체 포즈 추정이라는 특정 작업에 적합한 특징을 학습하는 역할을 합니다. 논문에서는 와 같이 각 레이어 특징에 대한 Extractor를 개별적으로 적용할 수 있음을 나타냅니다.
- Aggregator (): Extractor를 거친 특징들을 최종적으로 결합하여 하나의 특징 을 만듭니다.
-
표준화된 표현: 이 집계 과정은 다음의 수식으로 표현될 수 있습니다.
- : 여러 레이어에서 추출 및 가공된 특징들을 최종적으로 집계하여 얻은 특징입니다. 이 특징이 객체 포즈 추정을 위한 최종 특징으로 사용됩니다.
- : 확산 모델의 서로 다른 개의 레이어에서 추출된 원본 특징 맵(raw diffusion feature maps)들의 집합입니다.
- : 특정 레이어 에서 추출된 원본 특징 에 적용되는 Extractor 함수입니다. 이 함수는 특징의 차원을 통일하고(e.g., 업샘플링, 컨볼루션 레이어) 객체 포즈 추정 작업에 유용한 정보가 강조되도록 변환합니다.
- : 각 레이어의 원본 특징들이 Extractor를 거쳐 변환된 특징들의 집합입니다.
- : 변환된 특징들의 집합을 입력으로 받아 하나의 통합된 특징 을 출력하는 Aggregator 함수입니다. 이 함수가 여러 레이어의 정보를 최종적으로 융합하는 역할을 합니다.
논문에서는 이러한 집계 과정을 구현하기 위한 구체적인 아키텍처 세 가지(Arch. (a), Arch. (b), Arch. (c))를 제안하며, 이들이 어떻게 Extractor와 Aggregator를 구성하고 특징을 결합하는지 설명합니다.
-
Arch. (a): Vanilla Aggregation (바닐라 통합)
- 다양한 레이어에서 추출된 원본 확산 특징들()을 표준 해상도로 업샘플링합니다.
- 각 특징에 대해 3x3 컨볼루션 레이어를 사용하여 객체 자세 추정 작업에 특화된 특징으로 변환하고, 모든 특징의 채널 수를 동일하게 맞춥니다. 이 변환 과정을 추출기()가 수행합니다.
- 변환된 특징들을 단순히 요소별 덧셈(Element-wise Addition)으로 합쳐 최종 통합 특징()을 생성합니다.
- 이 수식은 통합할 개의 특징에 대해, 각 특징 를 추출기 로 변환한 후, 이 변환된 특징들을 모두 더하여 최종 통합 특징 를 얻는 과정을 나타냅니다.
-
Arch. (b): Nonlinear Aggregation (비선형 통합)
-
Arch. (a)의 한계: Arch. (a)는 입력 피처에 대해 선형 변환(3x3 컨볼루션)만 적용하고, 이를 단순히 합산합니다. 이러한 선형적인 방식으로는 복잡한 데이터 패턴이나 비선형성을 충분히 포착하기 어렵습니다.
-
Arch. (b) 소개: 이러한 한계를 해결하기 위해 저자들은 비선형성을 도입한 Arch. (b)를 설계했습니다. Arch. (b)는 Arch. (a)에서 사용한 선형 변환(3x3 Conv) 대신 "병목 계층(bottleneck layer)"을 사용합니다.
-
병목 계층의 구성: 이 병목 계층은 세 개의 컨볼루션 레이어와 ReLU 활성화 함수, 그리고 스킵 커넥션(skip connection)으로 구성되어 있습니다. 이는 📄 Deep residual learning for image recognition (ResNet [8])의 병목 구조와 유사한 형태를 가집니다. 이를 통해 네트워크에 비선형성을 추가하고 표현력을 높입니다.
-
파라미터 증가와 일반화 문제: 하지만 병목 계층 사용으로 인해 네트워크의 파라미터 수가 증가하게 됩니다. 사용 가능한 학습 데이터가 제한적일 경우, 파라미터가 많은 모델은 학습 데이터에 과적합되어 보지 못한 객체(unseen objects)에 대한 일반화 성능이 저하될 수 있습니다.
-
일반화 문제 해결: 이 문제를 완화하기 위해 저자들은 Adding Conditional Control to Text-to-Image Diffusion Models(ControlNet [45])에서 영감을 받아 해결책을 도입했습니다. 병목 계층 내의 마지막 컨볼루션 레이어의 가중치를 0으로 초기화합니다. 이는 학습 시작 시에는 이 레이어의 출력이 0이 되어 기존 피처에 큰 변화를 주지 않도록 하고, 학습 과정을 통해 점진적으로 필요한 비선형성을 학습하도록 유도하여 일반화 성능을 개선하는 전략입니다.
-
-
Arch. (c): Context-aware Weight Aggregation (컨텍스트 인지 가중치 통합)
- Arch. (c)는 확산 모델의 여러 레이어에서 추출된 특징들을 '문맥(context)'에 기반하여 최적의 가중치를 학습하고 이를 이용하여 결합하는 방식입니다. Arch. (a)와 (b)는 단순히 특징들을 동등한 가중치(1)로 합하는 것과 달리, Arch. (c)는 각 특징의 중요도를 데이터로부터 직접 학습하여 더 효과적인 특징 표현을 얻는 것을 목표로 합니다.
-
확산 모델의 서로 다른 n개의 레이어에서 얻은 원시 특징들 을 사용합니다.
-
각 특징 를 표준 해상도로 업샘플링합니다.
-
업샘플링된 각 특징을 Arch. (b)와 동일한 보틀넥 레이어 로 구성된 특징 추출기를 통과시켜 객체 자세 추정 작업에 특화된 특징 표현 를 얻습니다.
-
여기서, 는 확산 모델의 번째 레이어에서 얻은 원시 특징, 는 번째 특징을 처리하는 특징 추출기(보틀넥 레이어), 는 특징 추출기를 통과한 후의 번째 특징 표현입니다.
-
문맥 표현 및 가중치 학습:
-
각 특징 표현 에 평균 풀링(average pooling)을 적용하여 1차원 특징 를 만듭니다.
-
모든 1차원 특징들 을 연결(concatenate)하여 전체 문맥을 표현합니다.
-
이 연결된 문맥 표현을 MLP(Multi-Layer Perceptron)와 Softmax 함수를 통과시켜 각 특징 에 대한 가중치 를 결정합니다.
-
여기서, 는 특징 표현 에 평균 풀링을 적용한 1차원 특징, 는 다층 퍼셉트론, 는 모든 가중치의 합을 1로 만들어주는 활성화 함수입니다. 는 번째 특징 에 할당될 가중치입니다.
-
-
가중치 합계:
-
학습된 가중치 를 사용하여 각 특징 표현 를 가중치 합하여 최종 집계된 특징 를 얻습니다.
-
여기서, 는 최종 집계된 특징 표현, 는 i번째 특징 의 가중치, 는 특징 추출기를 통과한 번째 특징 표현입니다.
-
이러한 문맥 인식 가중치 학습을 통해 Arch. (c)는 다양한 입력 이미지와 객체에 따라 특징 결합 방식을 유연하게 조절함으로써 특히 학습 데이터에서 보지 못한 객체(unseen objects)에 대한 일반화 성능을 크게 향상시키는 효과를 보여줍니다
4. Experiment
4.1. Experimental settings
4.1.1. Implimentation details
- 사용된 Diffusion Model: 특징 추출을 위해 Stable Diffusion (SD) v1-5 [32] 모델을 사용했습니다. 이 모델은 대규모 데이터셋인 LAION-5B [33]로 학습된 generative latent diffusion model입니다.
- 입력 이미지 해상도: Stable Diffusion 모델에 입력되는 이미지의 해상도는 512x512입니다.
- 특징 추출 및 통합: Stable Diffusion 모델의 UNet에 있는 모든 레이어에서 특징을 추출하고, 이 특징들을 통합하여 최종적으로 32x32 크기의 출력 특징을 생성합니다.
- 학습 설정:
- 총 20 Epoch 동안 네트워크를 학습시켰습니다.
- 학습률(learning rate)은 사용하는 데이터셋에 따라 다릅니다. LM dataset에는 1e-3을, T-LESS dataset에는 1e-4를 적용했습니다.
- Diffusion Model 사용 방식: 학습 중에는 입력 이미지에 어떤 노이즈도 추가하지 않고 Stable Diffusion 모델에 직접 입력했습니다. (이는 섹션 3.3.1에서 설명된
t=0과 유사한 방식입니다.)
4.1.2. Training and test
-
핵심 전략: 객체 자세 추정을 위해 Stable Diffusion(SD) 모델의 가중치는 고정하고, 논문에서 새로 제안한 Aggregation Networks만 학습시킵니다. 이는 미리 학습된 SD 모델의 강력한 Feature 추출 능력을 활용하되, 자세 추정이라는 특정 작업에 맞게 Feature를 효과적으로 결합하는 방법을 배우도록 합니다.
-
손실 함수:
InfoNCE loss는 입력 이미지의 Feature와 템플릿 이미지 Feature 간의 유사도를 학습하는 데 사용됩니다. 입력 이미지 Feature를 앵커(anchor)로 보고, 올바른 자세/클래스의 템플릿 Feature를 Positive Sample로, 나머지 템플릿 Feature를 Negative Sample로 간주할 수 있습니다. 수식은 다음과 같습니다.
-
수식 해석
-
: 계산된 InfoNCE loss 값입니다. 학습 목표는 이 값을 최소화하는 것입니다.
-
: 입력 이미지 로부터 추출된 Feature 벡터입니다. 논문에서는 Diffusion Model과 Aggregation Network를 통과하여 얻어진 Feature를 의미합니다.
-
: 템플릿 이미지 로부터 추출된 Feature 벡터입니다.
-
: 입력 이미지에 대한 올바른 자세/클래스를 가진 Positive Template 의 Feature 벡터입니다.
-
: 입력 이미지에 대한 잘못된 자세/클래스를 가진 Negative Template 들의 Feature 벡터입니다. 논문에서는 개의 Negative Template을 사용합니다.
-
: 두 Feature 벡터 와 사이의 유사도를 측정하는 함수입니다. 일반적으로 Cosine Similarity나 Dot Product가 사용됩니다. 논문에서는 Cosine Similarity를 사용한다고 언급합니다.
-
: Temperature parameter입니다. 유사도 값의 스케일을 조절하며, 학습의 난이도나 안정성에 영향을 미치는 하이퍼파라미터입니다. 값이 작을수록 Positive Sample의 유사도를 훨씬 더 크게 강조하게 됩니다.
-
: Exponential 함수입니다. 유사도 값을 양수로 변환하고, 유사도가 높을수록 값이 커지도록 하여 Softmax와 유사한 형태로 만들 수 있게 합니다.
-
분자 (): 입력 이미지 Feature 와 Positive Template Feature 사이의 유사도를 나타냅니다. 이 값이 커지도록 학습됩니다.
-
분모 (): 입력 이미지 Feature 와 Positive Template Feature , 그리고 개의 Negative Template Feature 모두와의 유사도를 합한 값입니다. 이는 Softmax의 정규화 항과 유사한 역할을 합니다.
-
: 입력 이미지 Feature가 Positive Template Feature와 비교했을 때, 전체 개의 템플릿(1개 Positive + 개 Negative) 중에서 Positive Template일 확률을 나타냅니다.
-
: 확률값에 음의 로그를 취한 것입니다. 이 값을 최소화하는 것은 곧 괄호 안의 확률 값을 최대화하는 것과 같습니다. 즉, 입력 이미지 Feature가 Positive Template Feature와 가장 높은 유사도를 갖도록 모델을 학습시키는 것입니다.
-
- 유사도 측정
-
Feature 맵 추출: 먼저 입력 이미지와 각 템플릿 이미지로부터 Feature 맵을 추출합니다. 논문에서는 Aggregation Network를 거쳐 32x32 크기의 Feature 맵 를 얻는다고 언급했습니다. 즉, 입력 이미지 Feature 맵 와 각 템플릿 이미지 의 Feature 맵 가 준비됩니다. 이 Feature 맵의 각 위치(pixel/patch)는 해당 영역의 국소적인 Feature 벡터를 담고 있습니다.
-
국소적인 코사인 유사도 계산: 입력 이미지 Feature 맵 와 특정 템플릿의 Feature 맵 의 동일한 공간적 위치(x, y)에 있는 Feature 벡터들 간에 코사인 유사도를 계산합니다.
- 예를 들어, Feature 맵의 위치에 있는 입력 이미지 Feature 벡터를 , 템플릿 Feature 벡터를 라고 할 때, 이 위치에서의 유사도는 로 계산됩니다.
- 이 계산은 Feature 맵의 모든 공간적 위치에 대해 수행되며, 결과적으로 입력 이미지와 템플릿 Feature 맵 간의 유사도를 나타내는 Spatial Similarity Map ()이 생성됩니다. 이 의 크기도 32x32와 같습니다.
-
임계값(Threshold) 필터링: 생성된 에 저장된 각 유사도 값에 대해 특정 임계값()을 적용합니다. 인 위치의 유사도 값은 무시하거나 0으로 설정합니다. 이 단계는 의미 없거나 낮은 유사도를 가지는 영역의 영향을 줄여줍니다.
-
템플릿 마스크(Template Mask) 적용: 각 템플릿 이미지는 해당 템플릿이 나타내는 객체의 실루엣이나 관심 영역을 정의하는 마스크를 가지고 있습니다. 이 마스크는 Feature 맵의 해상도에 맞춰 조정됩니다.
- 이 템플릿 마스크를 임계값 필터링이 적용된 에 적용합니다. 마스크에서 객체 영역(값이 1 또는 True인 부분)에 해당하는 위치의 유사도 값만 유지하고, 객체 영역이 아닌 부분(값이 0 또는 False인 부분)의 유사도 값은 무시하거나 0으로 설정합니다. 이 단계는 오직 객체 자체에 해당하는 Feature 유사도만을 고려하도록 합니다.
-
남은 값들의 평균 계산: 임계값 필터링과 템플릿 마스크 적용 후, 최종적으로 남은 (즉, 객체 영역에 해당하고 특정 임계값 이상의 유사도를 가지는) 유사도 값들의 평균을 계산합니다. 이 평균값이 입력 이미지와 해당 템플릿 간의 최종 유사도 점수가 됩니다.
4.1.3. Dataset
- LINEMOD (LM): 객체 자세 추정 분야에서 많이 사용되는 표준 데이터셋입니다. 각 시퀀스마다 하나의 객체가 있고 해당 객체의 실제 자세 정보가 포함되어 있습니다.
- Occlusion-LINEMOD (O-LM): LINEMOD 데이터셋에 객체 가려짐(occlusion) 상황을 추가하여 더 어렵게 만든 데이터셋입니다. 학습 시에는 볼 수 없었던 객체(unseen objects)에 대한 테스트도 진행합니다.
4.1.4. Evaluation metrics
- LM 및 O-LM 데이터셋 평가 지표:
- 이 데이터셋에서는 주로 회전 오차(pose error)를 측정하며, 이는 두 회전 행렬 사이의 geodesic distance를 계산하여 구합니다.
- Geodesic distance 공식은 다음과 같습니다.
- : 예측된 회전 과 실제 회전 사이의 geodesic distance입니다. 값이 작을수록 정확도가 높습니다.
- : 실제 3D 회전(ground truth 3D orientation)입니다.
- : 모델이 예측한 3D 회전(predicted 3D orientation)입니다.
- : 행렬의 대각합(trace)을 의미합니다. 행렬의 대각 성분을 모두 더한 값입니다. 이 값은 두 회전 행렬이 얼마나 유사한지를 나타냅니다.
- : 역 코사인 함수입니다.
- : 파이(약 3.14159)입니다. 결과값을 라디안에서 정규화된 형태로 변환합니다.
- 보이지 않는(unseen) 객체의 경우, 객체 클래스(object class)도 추정해야 하므로 정확도(Accuracy)는 다음 두 가지 조건을 모두 만족하는 테스트 이미지의 비율로 정의됩니다.
- 최적의 각도 오차(best angle error)가 특정 임계값(λ)보다 작아야 합니다.
- 예측된 객체 클래스()가 실제 클래스()와 같아야 합니다.
- 논문에서는 template-pose [24] 방식을 따라 Acc15 지표를 사용하며, 이 때 임계값 λ는 15로 설정됩니다.
4.2 Ablation study
4.2.1. Timestep
이 섹션에서는 확산 모델(Diffusion Model)의 시간 단계(timestep)가 객체 포즈 추정 성능에 미치는 영향을 분석하기 위한 제거 연구(ablation study)를 설명합니다.
-
시간 단계(Timestep)의 의미:
- 확산 모델은 이미지에 점진적으로 노이즈를 추가하는 순방향 프로세스(forward process)와 노이즈가 있는 이미지에서 노이즈를 제거하여 원본 이미지를 복원하는 역방향 프로세스(reverse process)를 포함합니다.
- 수학적으로는 DDIM [34] 등의 샘플링 절차를 사용하며, 시간 단계 는 노이즈 수준을 나타냅니다. 와 같이, 시간 단계가 증가함에 따라 이미지 에는 더 많은 노이즈 가 추가됩니다 (여기서 는 원본 이미지, 는 노이즈 스케줄입니다).
- 이 연구에서는 조건부 프롬프트 없이 깨끗한 이미지에서 특징을 얻기 위해 시간 단계 과 같은 매우 작은 시간 단계를 사용합니다. 이는 확산 모델 관점에서 깨끗한 이미지가 주로 노이즈 제거된 이미지로 간주되기 때문입니다.
-
실험 방법:
- 저자들은 Stable Diffusion (SD) v1-5 [32] 모델에서 다양한 시간 단계(0부터 1000까지 균등하게 샘플링된 11개의 시간 단계)로 특징을 추출했습니다.
- 추출된 특징을 집계하기 위해 가장 기본적인 네트워크인 Arch. (a) (Vanilla Aggregation)를 사용했습니다.
- 성능 평가는 Seen LM 및 Seen O-LM 데이터셋의 split #1 객체에 대해 정확도(accuracy) 지표를 사용하여 빠르게 진행되었습니다.
-
실험 결과 (Fig. 4 참조):
- 시간 단계가 증가함에 따라 LM 및 O-LM 데이터셋 모두에서 정확도가 감소하는 경향을 보였습니다.
- 이는 시간 단계가 작을수록 확산 모델이 입력 이미지에 노이즈가 적다고 가정하며, 이것이 본 연구에서 사용하는 깨끗한 이미지 시나리오와 잘 일치하기 때문이라고 설명합니다.
-
결론:
- 가장 높은 정확도를 보인 시간 단계 0을 이후 모든 실험에서 사용하기로 결정했습니다.
4.2.2. Other models pre-trained at large scale
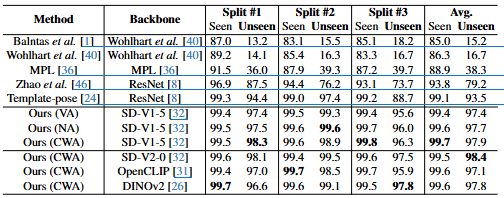
-
표의 구성:
Method: 객체 포즈 추정에 사용된 방법입니다. 기존 연구와 본 논문에서 제안하는 방법(Ours)들이 나열되어 있습니다.Backbone: 각 방법에서 이미지 특징을 추출하기 위해 사용된 백본 네트워크입니다. ResNet [8], SD-V1-5 [32], SD-V2-0 [32], OpenCLIP [31], DINOv2 [26] 등이 사용되었습니다.Split #1,Split #2,Split #3: LM 데이터셋을 세 가지 분할로 나누어 'Seen' 객체와 'Unseen' 객체에 대한 정확도(Accuracy)를 측정한 결과입니다.Avg.: 세 가지 분할 결과의 평균 정확도입니다. 'Seen' 객체와 'Unseen' 객체에 대한 평균이 각각 표시되어 있습니다.
-
주요 결과 분석:
- 기존 방법들은 'Seen' 객체에 비해 'Unseen' 객체에서 성능 저하가 뚜렷하게 나타납니다. 예를 들어, 최신 기술인 Template-pose [24]는 'Seen' 객체에서 평균 99.1%의 정확도를 보이지만, 'Unseen' 객체에서는 93.5%로 5.6%p 감소합니다.
- 본 논문에서 제안하는 확산 특징(Diffusion Features) 기반의 방법들은 'Unseen' 객체에서 기존 방법들보다 훨씬 뛰어난 성능을 보여줍니다. 특히,
Ours (CWA)(SD-V1-5 [32] 백본 사용)는 'Unseen' 객체에서 평균 97.9%의 정확도를 달성하여 Template-pose [24]보다 4.4%p 높은 성능을 보였습니다. - 본 논문에서 제안한 세 가지 집계 네트워크(
VA: Vanilla Aggregation,NA: Nonlinear Aggregation,CWA: Context-aware Weight Aggregation) 중CWA가 대부분의 경우 가장 좋은 성능을 보였습니다. 이는 문맥 기반 가중치 학습이 특징 집계에 효과적임을 시사합니다. - 다른 대규모 사전 학습 모델 (SD-V2-0 [32], OpenCLIP [31], DINOv2 [26])을 백본으로 사용한 경우도 좋은 성능을 보였지만, Stable Diffusion v1-5 [32]가 대부분의 벤치마크에서 가장 우수한 결과를 얻었습니다. 이는 확산 모델의 중간 특징이 객체 포즈 추정 작업에 특히 효과적임을 나타냅니다.
