1. BERT의 기본 개념

- BERT는
Word2Vec과 같은 context-free 임베딩 모델과는 달리 context-based 임베딩 모델이다. - BERT는 모든 단어의 문맥상 의미를 이해하기 위해 문장의 각 단어를 문장의 다른 모든 단어와 연결시켜 이해한다.
2. BERT의 동작 방식
-
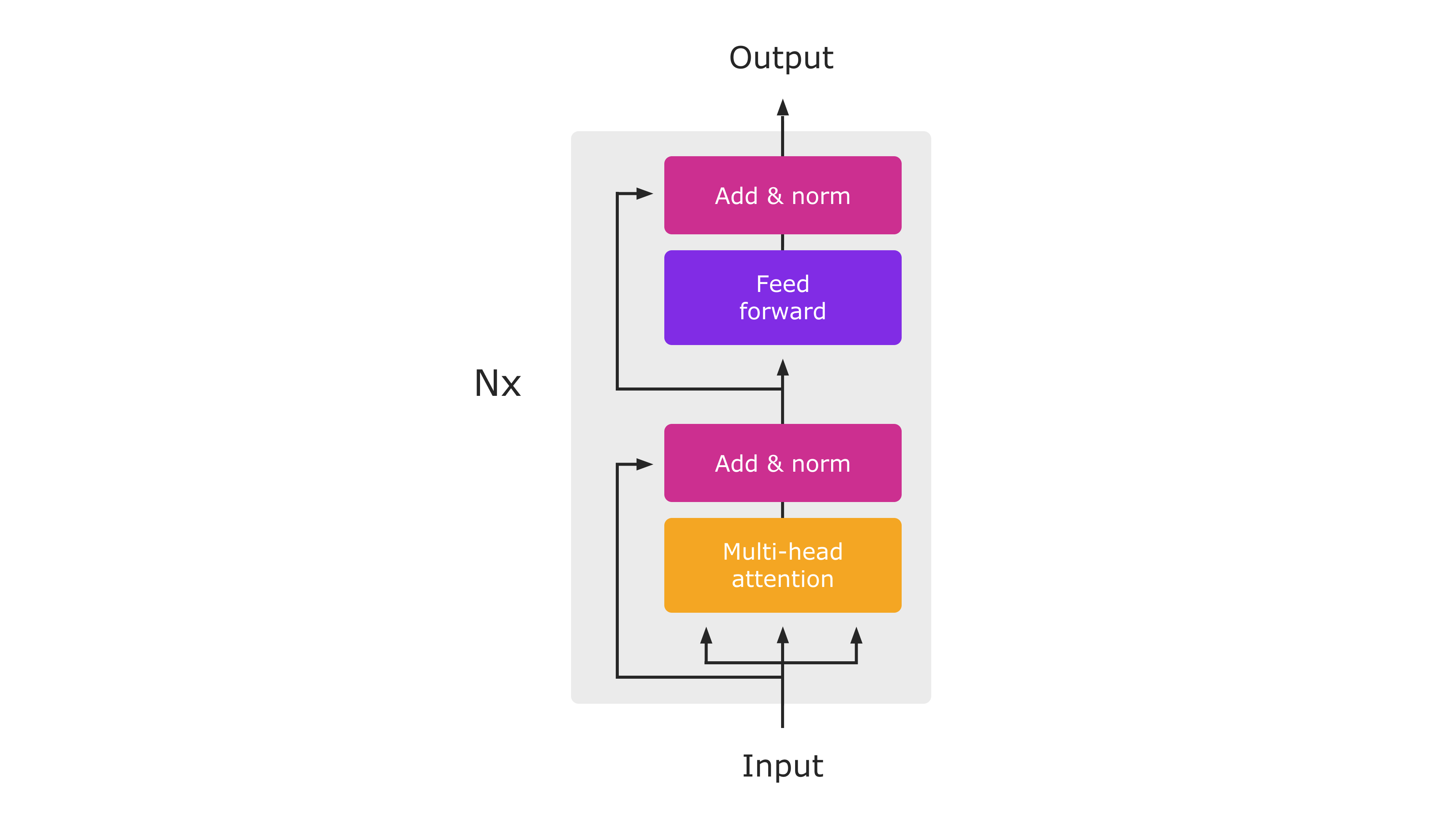
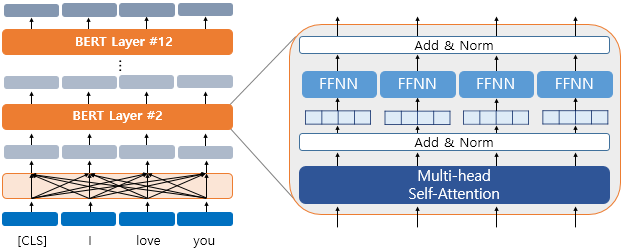
트랜스포머의 인코더에 문장을 입력하면 문장의 각 단어를 표현하는 벡터를 출력으로 반환한다. 이런 방식이 BERT에서도 동일하게 동작한다.
-
트랜스포머는 원래 문장의 모든 단어를 한번에 입력받기 때문에 '양방향(bidirectional)'이라고 할 수 있다.
-
인코더에 문장을 입력하면 인코더는 문장의 각 단어를 다른 모든 단어와 연결하여 관계 및 문맥을 고려해 의미를 학습한 후 문장에 있는 각 단어의 문맥 표현을 출력한다.
3. BERT의 구조
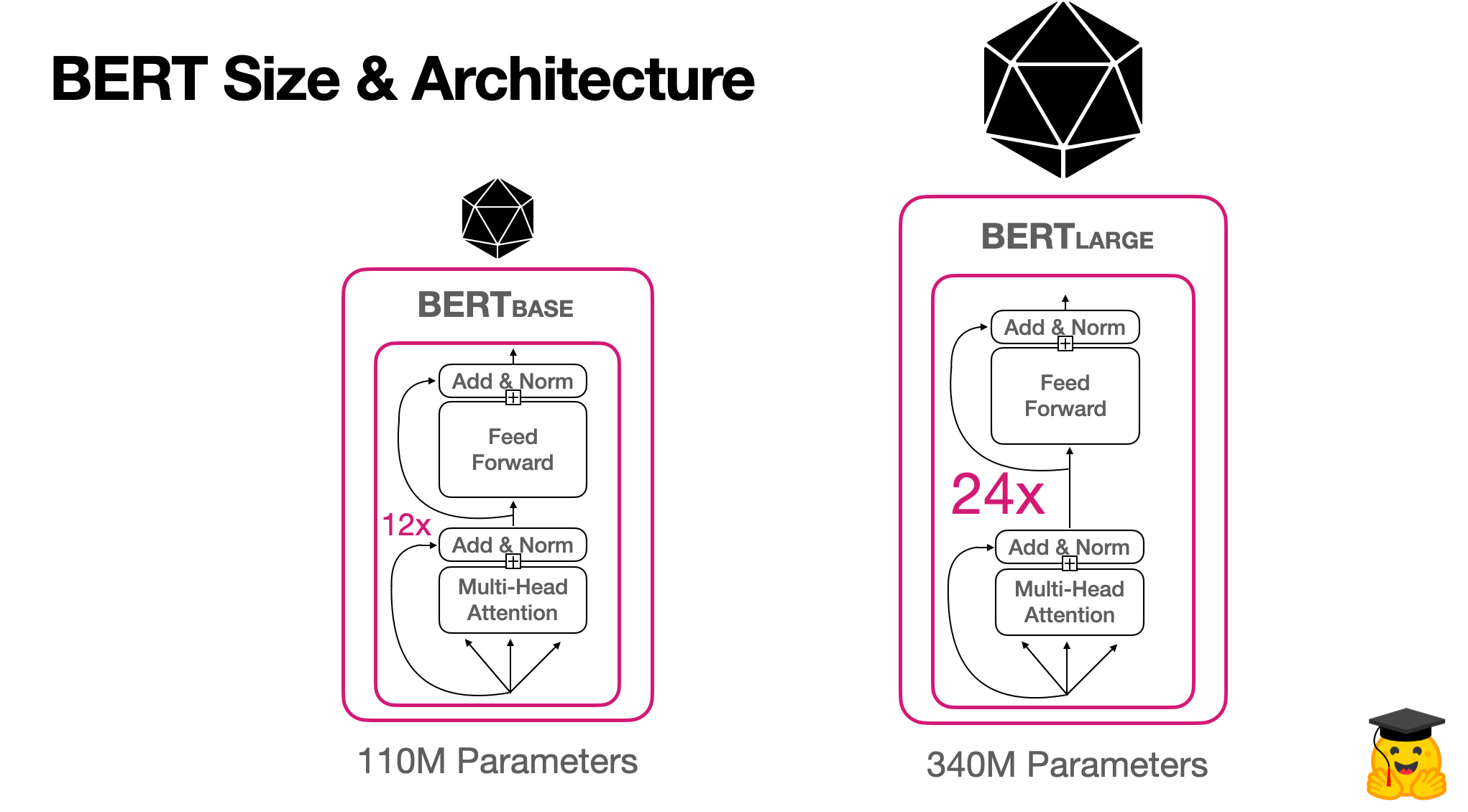
BERT 논문에서는 두가지 형태의 모델이 제시되었다.
BERT-baseBERT-large
3-1. BERT-base
BERT-base는 12개의 인코더 레이어가 쌓인 형태로 구성되어 있다.- 모든 인코더는 12개의 어텐션 헤드를 사용하며, 인코더의 FFNN은 768개의 hidden unit으로 구성된다.
- 따라서
BERT-base를 통해 얻은 각 단어의 표현 크기는 768이다.
3-2. BERT-large
BERT-large는 24개의 인코더 레이어가 쌓인 형태로 구성되어 있다.- 모든 인코더는 24개의 어텐션 헤드를 사용하며, 인코더의 FFNN은 1024개의 hidden unit으로 구성된다.
- 따라서
BERT-large를 통해 얻은 각 단어의 표현 크기는 1024이다.
4. BERT 사전학습
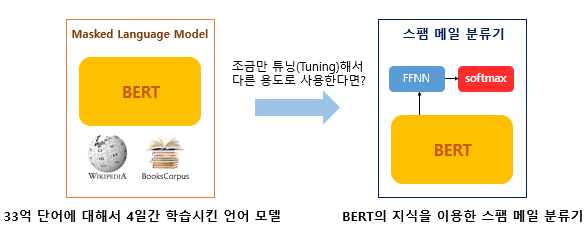
⭐️
사전학습(Pretraining)&미세 조정(fine-tunning):
모델을 대규모 데이터셋으로 학습시키고 학습된 모델을 저장한다. 이후 새로운 태스크가 주어졌을 때 모델을 새롭게 처음부터 학습시키는 대신 사전 학습된 모델을 사용하여 새로운 태스크에 따라 가중치를 조정한다.
- BERT는
MNM과NSP라는 두 가지 태스크를 이용하여 거대 말뭉치를 기반으로 사전학습을 진행한다.MNM: Masked Language ModelingNSP: Next Sentence Prediction
- 이후 새로운 태스크가 주어질 경우 사전 학습된 BERT를 기반으로 새 태스크에 대한 가중치를 조정(파인튜닝)한다.
4-1. BERT의 입력표현
BERT에 데이터를 입력하기 전에 다음 3가지 임베딩 레이어를 통해 입력 데이터를 임베딩해야한다.
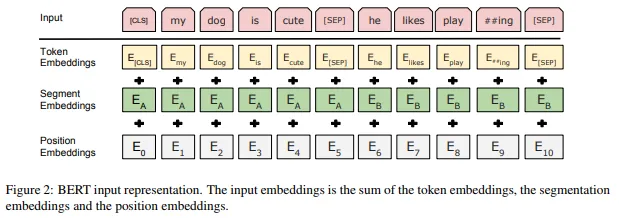
-
Token Embedding(토큰 임베딩)[CLS]토큰은 첫 번째 문장의 시작 부분에만 추가되며 분류 작업에 사용된다.[SEP]토큰은 모든 문장의 끝에 추가되어 끝임을 나타내기 위해 사용된다.- 토큰화된 문장에 특수 토큰을 추가한 이후
Token Embedding이라는 임베딩 레이어를 통해 각 토큰을 임베딩 벡터로 변환한다. - 는
[CLS]토큰의 임베딩을 나타낸다.
-
Segment Ebedding(세그먼트 임베딩)- 주어진 문장들을 구분하기 위해서 모델에 일종의 지표를 제공해야 한다.
- 토큰의 임베딩 벡터를 입력으로 받아 , 를 출력한다. 입력 문장이 A 문장에 속하면 토큰이 에 매핑되고, B문장에 속하면 에 매핑된다.
-
Position Embedding(위치 임베딩)- 트랜스포머의 인코더와 마찬가지로 모든 단어를 병렬로 처리하므로 단어 순서와 관련된 정보를 제공해야 한다.
- 위치 임베딩을 통해 문장의 각 토큰에 대한 위치 임베딩을 출력한다.
❗️ 주어진 입력 문장을 토큰으로 변환하고 토큰을 토큰 임베딩, 세그먼트 임베딩, 위치 임베딩 레이어를 통과시켜 각각의 임베딩을 얻은 후 모든 임베딩을 합산하여 인코더의 입력으로 사용한다.
4-2. Maksed Language Modeling(MLM)
-
language modeling(언어 모델링)
'Paris is a beatufiful city. I love Paris.'라는 문장이 주어졌을 때 'city'라는 단어를 제거하고 공백을 추가한 뒤 모델이 해당 공백을 예측하도록 학습한다고 가정하자.
auto-regressive language modeling(자동 회귀 언어 모델링): 단방향 예측forward prediction(전방 예측): Paris is beautiful ___.backward prediction(후방 예측): ___. I love Paris.
- ⭐️
auto-encoding language modeling(자동 인코딩 언어 모델링): 양방향 예측- Paris is beatuful ___. I love Paris
- BERT는 자동 인코딩 언어 모델로,
MLM은 주어진 입력 문장에서 전체 단어의 15%를 무작위로 마스킹하고 마스킹된 단어([MASK])를 예측하도록 모델을 학습시킨다.
-
Masked Langugae Modeling❗️
[MASK]토큰을 예측하는 방식으로 BERT를 사전 학습 시키고, 감정 분석과 같은 다운스트림 태스크를 위해 사전 학습된 BERT를 파인 튜닝할 때 입력 문장에는[MASK]토큰이 없기 때문에 MLM 방식으로 토큰을 마스킹하면 사전 학습과 파인 튜닝 사이에 불일치가 발생한다. 이 문제를 극복하기 위해 '80-10-10%' 규칙을 적용한다.- 15% 중 80%의 토큰을
[MASK]토큰으로 교체한다. - 15% 중 10%의 토큰을 임의의 토큰으로 교체한다.
- 15% 중 10%의 토큰은 어떤 변경도 하지 않는다.
- 15% 중 80%의 토큰을
-
Ex)
My dog is cute. he likes playing[CLS],my,dog,is,cute,[SEP],he,likes,play,##ing,[SEP]로 토큰화된 이후 3가지 임베딩 레이어를 거쳐 입력으로 사용된다.
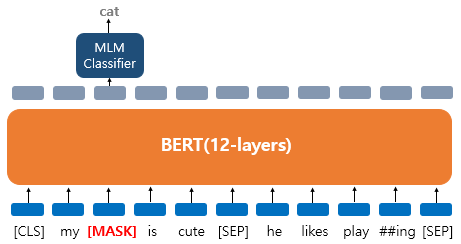
- 우선
dog는[MASK]로 변경되었다고 가정해보자. - BERT는
[MASK]가 무엇인지 예측하기 위해dog위치의 출력층의 벡터만을 사용한다. (손실함수에서 다른 위치에서의 예측은 무시한다) - 단어 집합의 크기만큼의 FC layer에 소프트맥스 활성화를 통해 원래의 단어가 무엇인지 예측한다.
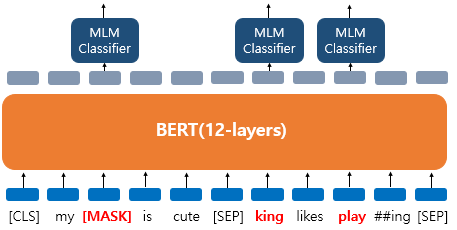
dog가[MASK]로 변경되었을 뿐만 아니라he가 단어 집합에 있는 임의의 단어king으로 변경되었다고 가정해보자.- BERT는
[MASK]로 교체된 토큰, 임의의 토큰으로 교체된 토큰, 어떤 변경도 되지 않은 토큰 모두에 대해서 원래의 단어가 무엇인지 예측한다. 해당 단어의 변경 여부를 모델은 알 수 없기 때문이다.
4-3. Next Sentence Prediction(NSP)
- 전체의 50%는 후속 문장이 되도록 샘플링하고, 나머지 50%는 후속 문장이 되지 않도록 샘플링한다.
isNext: B 문장은 A 문장의 후속 문장이다.notNext: B 문장은 A 문장의 후속 문장이 아니다.❗️
NSP에서 BERT의 목표는 문장 쌍이isNext범주에 속하는지 여부를 예측하는 것이다.(이진 분류) NSP를 수행함으로써 BERT는 두 문장 사이의 관계를 파악할 수 있게 된다.
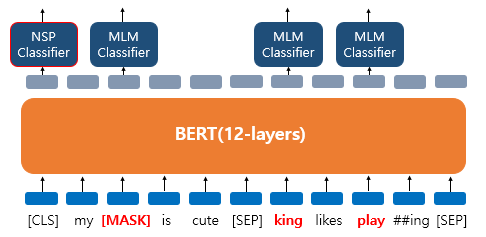
- 각 문장의 끝에
[SEP]토큰을 넣어줌으로써 문장을 구분한다. - 두 문장이 실제로 이어지는 문장인지 아닌지의 여부는
[CLS]토큰의 출력 표현 를 가져와 FC layer에 통과시킨 후 소프트맥스 함수를 적용하여 확률로 확인할 수 있다. NSP를 통해 BERT를 사전학습함으로써 fine-tuning 이후 QA나 NLI와 같은 다운스트림 태스크에 유용한 결과를 가져올 수 있다.MLM과NSP에 대해서 BERT는 동시에 학습이 이루어진다.
4-4. Pretraining
Dataset: Tronto BookCorpus, Wikipidia- 데이터셋에서 두 문장을 샘플링하여
MLM및NSP태스크를 사용하여 사전 학습한다.(두 작업을 동시에 사용하여 BERT를 학습한다.) - 샘플링한 두 문장의 총 토큰 수의 합의 최대를 512로 제한한다.
- 100만 step
batch size: 256learning rate:- : 0.9, : 0.999
optimizer: Adamwarmup: 10000 stepdroupout ratio: 0.1activation function: GELU(Gaussian Error Linear Unit)
4-5. subword tokenization algorithm
하위 단어 토큰화(subword tokenization) 알고리즘은 OOV(Out-Of-Vocabulary) 단어 처리에 효과적이다.
Byte-Pair Encoding(BPE): 빈도를 기준으로 문자 쌍을 병합한다.
1. 빈도수와 함께 저어진 데이터셋에서 단어 추출
2. 어휘 사전 크기 정의
3. 단어를 문자 시퀀스로 분할
4. 문자 시퀀스의 모든 고유 문자를 어휘 사전에 추가
5. 빈도가 높은 기호 쌍을 선택하고 병합
6. 어휘 사전 크기에 도달할 때까지 앞의 과정을 반복- ⭐️
WordPiece: 가능도(likelihood)를 기준으로 문자 쌍을 병합한다.
1. 빈도수와 함께 주어진 데이터셋에서 단어 추출
2. 어휘 사전 크기 설정
3. 단어를 문자 시퀀스로 분할
4. 문자 시퀀스의 모든 고유 문자를 어휘 사전에 추가
5. 주어진 데이터셋(training set)에서 언어 모델 빌드
6. 학습셋에서 학습된 언어 모델의 최대 가능도(Maximum Likelihood)를 가진 기호 쌍을 선택하여 병합
7. 어휘 사전 크기에 도달할 때까지 앞의 과정을 반복