[논문리뷰] Three Pillars improving Vision Foundation Model Distillation for Lidar, CVPR 2024
논문 리뷰 및 실습
최근 LiDAR에 2D vision foundation 모델을 많이 적용하려하는 시도가 많이 존재한다. 이 논문도 그러한 시도를 한 논문인데, distilation을 잘하기 위해 3가지 point를 짚고 넘어간다. 그리고 무엇보다 Pre-trained weight랑 코드가 공개된 점이 매우 맘에 든다. (NVIDIA는 공개한다 해놓고 6개월 넘도록 안하는데... ) 쨋든 연구에 요긴하게 써먹을 수 있을 것 같다.
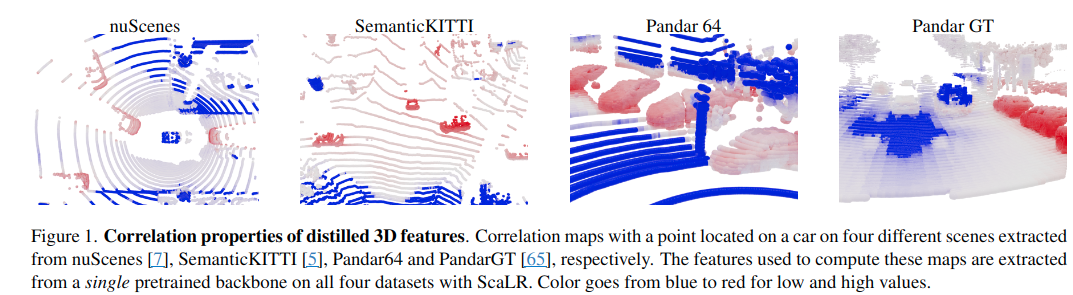
Overview
최근 LiDAR에서 2D Image model을 distillation하여 큰 가능성을 보임. 하지만 distillation된 모델의 성능이 여전히 fully-supervised 모델보다 낮음이 linear probing을 통해 발견됨. 이 논문에서는 3가지 관점에서 distillation을 바라봄. 1) 3D backbone, 2) Pre-trained 2D backbones, 3) Pretraining-dataset. 제안기법인 (ScaLR, Scalable LiDAR Representation)은 scaling된 2D·3D backbone과 다양한 데이터셋을 활용해 대규모 distillation을 수행함. 이를 통해 fully-supervised 3D features보다 성능을 높였으며, LiDAR sensor간 domain gap과 noise에도 robust하다고 한다.
Problem
Self-supervised 3D backbone은 크게 1) Sequential한 LiDAR only data를 사용하는 방식과 2) Image representation을 3D backbone에 distillation하는 방식이 있음. 이 논문에서는 후자를 다룸. 본 논문에서는 distillation된 모델들이 여전히 linear probing을 통한 검증을 통해, supervised 모델보다 낮은 gap이 있음을 문제로 지적.
Solution from paper
1) 3D backbone, 2) Pre-trained 2D backbones, 3) Pretraining-dataset을 rethinking하여, 대용량의 2D&3D 모델과 diverse dataset에서의 pre-training이 feature quality 향상에 기여함을 보임. 저자들은 distillation 방식보다도 위 3가지 포인트가 더 중요하다고 주장함.
< Backbones >
- 3D backbone Input: Intensity를 포함한 point cloud
- 2D backbone Input: RGB 픽셀과 Foundation 모델의 픽셀 별 feature. (RGB image of M pixels and outputs deep features of dimension F2D for all
pixels: ). Feature의 경우 RGB와의 scale을 맞추기 위해 bilinear interpolation을 적용했다고 함.
< 3D Projection head >
Linear projection head가 3D network 후반부에 있음. 3D feature를 2D backbone space로 projection하는 역할을 함. distliation 이후에는 사라짐.
< Point-pixel mapping & Similarity loss >
Projected된 3D feautre와 2D feature간 pointwise loss를 줬다고 함. 이 때, f와 g vector는 모두 normalized 되었다고 가정.
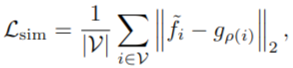
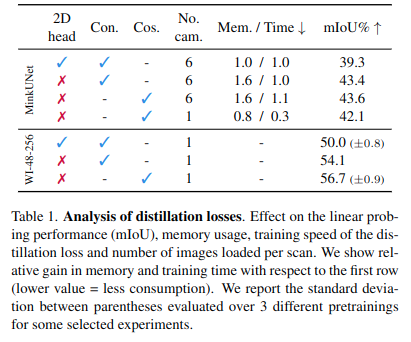
< 2D projection head & Absence of false negatives>
- 2D head가 있으면 original feature가 망가짐. 저자들은 이거를 없에는게 더 좋은 3D feature를 얻을 수 있다고 함.
- 또한 constrastive loss를 사용하게 되는 경우, 유사한 2개의 타겟 샘플에 대해 하나는 가깝게 하고 다른 하나는 멀게 만드는 경우가 문제가 될 것이라 판단하였음.
- 결과적으로 cosine similarity loss 사용하는 것이 가장 좋다고 주장함.
Results
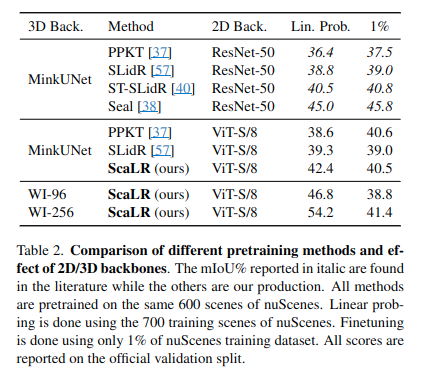
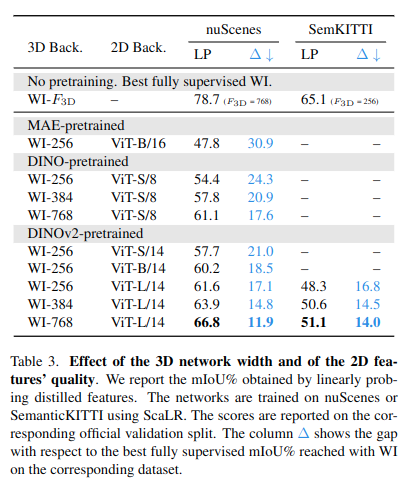
- ResNet -> ViT구조가 성능 향상에 도움이 됨.
- ScaLR이 다른 기법 대비 3D feature를 잘 획득함. 저자들은 cosine-loss를 사용해서 그렇다고 함.
- Dino pretrained가 좋은 성능을 보임.
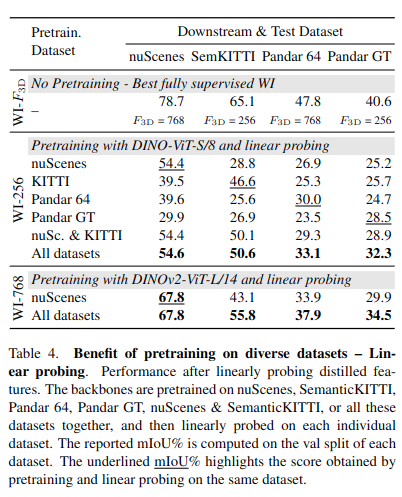

- 일반화 성능을 ScaLR은 다량의 pretrained 데이터셋 덕분에 높아짐.
- robustness 또한 타 기법대비 높음.
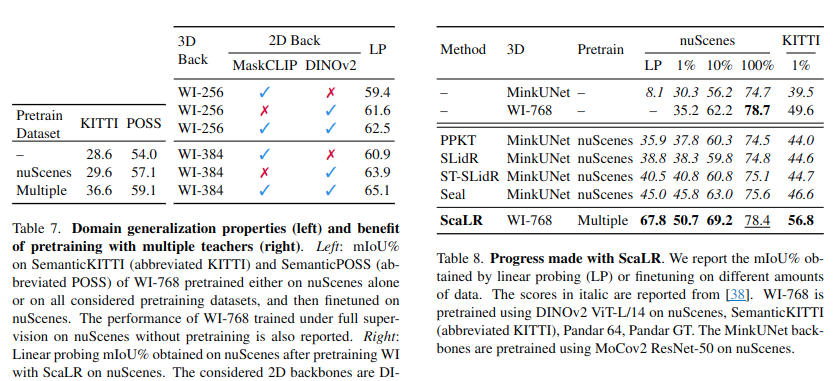
- 다양한 dataset에서의 사전 훈련 + Dinorv2 구조를 사용하는 것이 가장 효과적
- 여러 teacher (2D model)을 사용할 때 성능이 더 개선될 수 있다고 함. 2D feature는 각 모델의 특징을 concat하였으며, 3D feature는 MLP를 별도로 두어 3D feature dimension을 수정하였다고 함.
Remarkable points
- 지금 당장 사용 가능한 self-supervised LiDAR feature backbone인것 같다. 다른 방법들은 코드가 없거나, pre-trained도 배포가 안됨....ㅠㅠ
- 위 논문에서는 segmentation에 초점을 두었으나, object detection이나 localization 등에서도 robust하게 사용 가능할지는 궁금.
