[논문리뷰] VoxelNextFusion: A Simple, Unified and Effective Voxel Fusion Framework for Multi-Modal 3D Object Detection, arXiv 2024
논문 리뷰 및 실습
Overview
LiDAR Camera sensor fusion시, 각각의 modality에서 얻은 feature를 어떻게 fusion할 수 있는지 방법을 제안하는 논문이다.
Problem
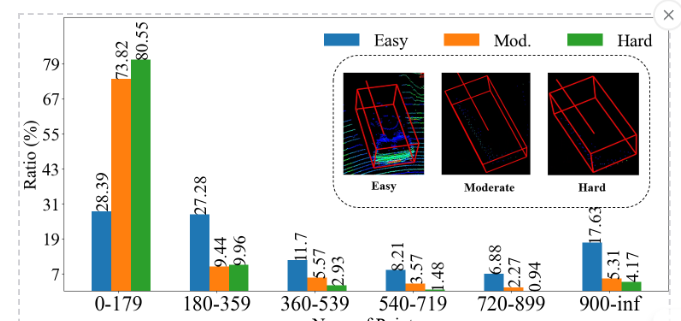
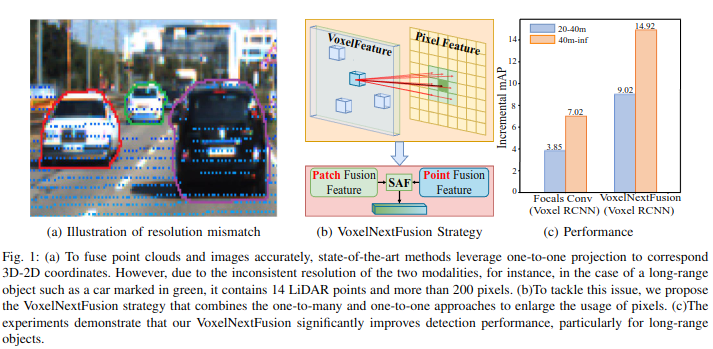
3D 객체 탐지는 자율 주행의 핵심 기술입니다. LiDAR는 거리 정보가 풍부하지만 희소하고 구조가 불완전하며, 카메라는 연속적이고 의미적인 정보가 풍부하지만 깊이 정보가 부족함기존의 Voxel 기반 멀티모달 탐지 방법은 각 Voxel과 이미지 픽셀을 1:1로 매핑하며, 이 과정에서 이미지의 장점을 충분히 살리지 못해 성능 저하가 발생합니다. (이미지 정보를 많이 사용하지 못함) 실제로 위의 초록색 경계의 차는 200 pixel에 고작 14개의 LiDAR point가 매핑되어 비효율적이며, 위의 도표 역시 3D object bounding box내 매핑되는 LiDAR points 갯수를 보여주며 hard할수록 더 적은 포인트 갯수가 있다고 함.
Solution: VoxelNextFusion
본 논문은 이 문제를 해결하기 위한 새로운 Voxel 기반 멀티모달 융합 프레임워크인 VoxelNextFusion을 제안함. 크게 Patch-to-Point Fusion 기법과 FB-Fusion으로 구성됨. 필자는 연구에 Patch-to-Point Fusion 기법이 필요하여, 이 위주로 정리하고자 함.
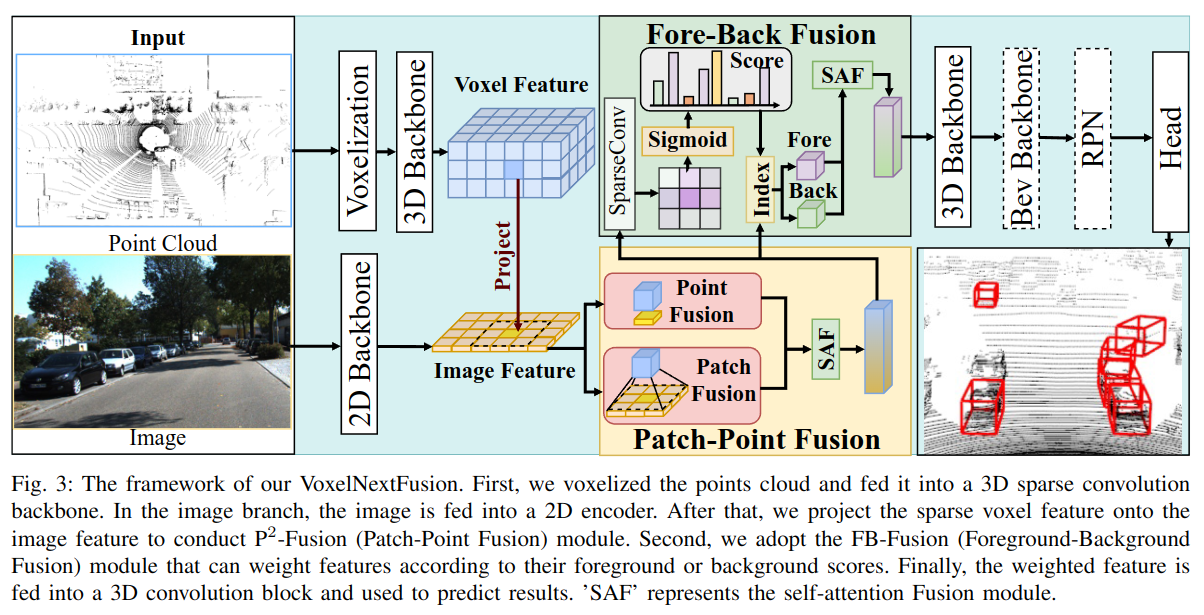
P2-Fusion (Patch-to-Point Fusion)
- Voxel을 하나의 픽셀이 아닌 여러 픽셀(Patch)로 매핑.
- Self-Attention 메커니즘을 통해 의미 있고 연속적인 이미지 정보를 보다 정교하게 융합.
- Point Fusion + Patch Fusion을 결합하여 더 풍부한 이미지 특징을 반영.

Projection (투영 과정)
1) Projection: calibration matrix)을 사용하여 Voxel의 3D 좌표계를 이미지의 픽셀 좌표계로 변환.
2) 이미지 특징 추출: 사전 학습된 의미 분할기(Semantic Segmenter)인 DeepLabV3를 사용해 인코딩 진행: .
3) Voxel 특징 추출 및 3D 좌표 변환: 첫 번째 3D Sparse Convolution 레이어를 거친 후, Voxel 특징을 생성 -> 이 과정은 3D point cloud와 이미지 간의 정확한 매핑을 가능하게 하며, 추후의 patch fusion 및 self-attention fusion의 기반이 되는 좌표 정렬 기법임.

즉, 특징 맵은 다운샘플된 해상도를 가지고 있지만, LiDAR 포인트를 투영하는 좌표는 원래 이미지 해상도 기준이기 때문에 불일치 문제가 발생하여, 위 논문에서는 Bilinear Interpolation)을 사용하여 원본 이미지 크기의 업샘플링(해상도 복원)을 수행. 위 과정을 통해 새로운 이미지 텐서: 생성.
저자들은 One-to-One 매핑은 각 LiDAR 포인트를 정확하게 해당 카메라 픽셀에 위치시킬 수 있지만, 데이터 손실이나 불완전한 기하학적 대응 문제를 언급하고, One-to-Many 매핑은 매칭 정확도를 향상시키고 센서 오차를 보완할 수 있으나,계산 복잡도 증가, 가중치 설계의 어려움, 가림(occlusion)의 영향 등을 수반할 수 있다고 함.
Point-Fusion (One-to-one)
Voxel 중심들의 포인트 좌표들을 () calibration matrix를 이용하여 이미지 평면 상의 픽셀 좌표계 로 투영 진행. ((x,y)는 이미지 상에서의 픽셀 좌표를 나타냄). 이미지 특징 과 Voxel 특징 을 얻었지만, shape이 달라 바로 fusion이 불가능한 상황. 따라서 저자들은 투영된 픽셀 좌표 를 이용하여 복셀 특징 에 해당하는 이미지 특징 를 먼저 얻어 shape을 맞춤. 이후 concatenation 혹은 덧셈을 활용하여 와 를 fusion함.
Patch-Fusion (One-to-Many)
Point-fusion과 같은 one-to-one은 sparse한 image feature만 사용한다는 문제가 있음. 따라서 One-to-Many 방식을 사용하여, 이미지 패치와 voxel 매핑을 진행함. 기존 pixel 좌표 에 K개의 주변 픽셀 좌표 오프셋 을 더하여 패치 내 모든 픽셀 좌표 를 얻음. 의 이미지 feature 을 추출함. 복셀 feature를 repeat하여 텐서의 shape을 와 동일하게 만든 후 (), Concat 혹은 덧셈을 통해 fusion을 진행.
- concat:
- Add: F_{KIV}=F_{v(repeat) + F_{KI} ∈ R^{N×K×(C)}
SAF 모듈로 와 fusion
- -> reshape -> (N, KxC)
- Point Fusion 결과 -> repeat -> (N, KxC)
- 1,2 를 덧셈 -> MLP -> Fused feature 를 획득
- Self-Attention 통과 → 최종 융합 특징 을 획득
위의 전체 과정을 요약하면 아래 알고리즘 차트와 같음.

FB-Fusion (Foreground-Background Fusion)
- Patch 안에 포함된 배경 정보(예: 도로, 나무)가 탐지에 방해가 되는 문제 해결.
- 각 픽셀의 중요도를 계산하고 Foreground / Background를 분리하여 중요도가 높은 영역만 융합에 사용.
- 중요도가 높은 Foreground Feature는 주변 영역으로 확장하여 Voxel 희소성 극복.
성능 및 결과
- KITTI와 nuScenes 데이터셋에서 실험.
- 기존 Voxel R-CNN 대비 KITTI에서 Hard 난이도 기준 +3.20% AP 향상.
- Long-range 객체(원거리 차량 등)의 탐지 성능이 특히 크게 향상됨.
- 모델 KITTI Car(Hard) 개선 폭: Voxel R-CNN 77.42% / + VoxelNextFusion 80.62% +3.20%
