이 포스트는 CVPR, 2017에 발표되었던 Image-to-Image Translation with Conditional Adversarial Networks(Pix2Pix) 논문의 실습입니다.
- Summary link -> link
Pix2Pix
- Unpaired Image-to-Image Translation using Cycle Consistent Adversarial Networks
- https://learnopencv.com/paired-image-to-image-translation-pix2pix/

Paired Image-to-Image translation 혹은 pix2pix라 불리는 GAN 모델은 Genretor가 노이즈 벡터를 입력으로 받아서, 이전의 GAN 모델들의 알고리즘들을 가져와서 중요 아키텍쳐를 변화 시켰습니다. Image-to-Image translation은 한 영역의 이미지들을 다른 영역으로 전환하는 task를 하며, 이는 input과 output 이미지들을 매핑하는 것을 학습하며 가능합니다. 따라서 training dataset은 사로 다른 영역의 데이터들을 사용하게 됩니다.
Image-to-Image translation은 paired/unpaired 모두 가능하며, 이번 포스트는 paired translation에 관해 다루도록 하겠습니다!
2. Applications of Pix2Pix
- 흑백 이미지들을 컬러 이미지들로 전환
- edges들을 의미 있는 사진들로 변환
- 항공 사진들을 지도로 전환
- 저해상도 이미지를 고해상도로 전환
3. What is a Pix2Pix GAN?
Pix2Pix는 Berkeley AI Research에서 CVPR 2017에 발표한 Image-to-Image Translation with Conditional Adversarial Networks에 처음 소개되었습니다. 위의 논문은 엄청난 인용횟수를 보여준 만큼, 매우 많이 사용되고 있습니다.
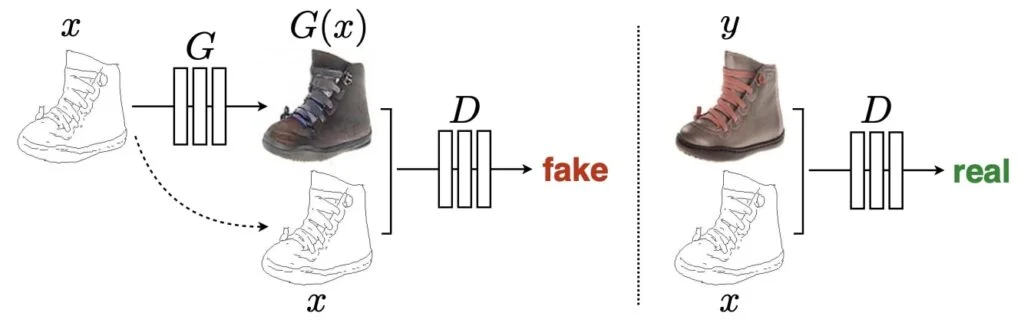 Pix2Pix GAN은 CGAN의 아이디어를 확장시켜서, Paired Image-to-Image translation을 추가한 것입니다. Pix2Pix GAN은 generator에서 노이즈 벡터의 개념을 사용하지 않습니다.
Pix2Pix GAN은 CGAN의 아이디어를 확장시켜서, Paired Image-to-Image translation을 추가한 것입니다. Pix2Pix GAN은 generator에서 노이즈 벡터의 개념을 사용하지 않습니다.
- 이미지가 generator의 입력으로 들어가고, translated된 이미지가 출력됩니다
- Discriminator는 conditional discriminator로 real/fake 이미지와 condition을 입력으로 받습니다. 역할은 기존처럼 real/fake를 판단하는 것입니다.
- Pix2Pix GAN의 최종적인 목표는 다른 GANs과 동일합니다. Discriminator를 속이는 이미지들을 Generator가 생성하게 만드는 것입니다.
초기의 GAN 아키텍쳐에서는, 노이즈 백터는 randomness를 가지고 있어서 다른 output을 만드는데 도움을 주었습니다. 하지만 이 개념은 Pix2Pix에는 사용되지 않고, 논문 저자들은 대신에 Generator의 출력에서 약간의 확률성을 유지하는 방법을 찾았습니다.
4. UNET Generator
 초창기 GANs 아키텍쳐처럼 노이즈 벡터를 입력으로 받는것이 아니라, 이미지들을 입력으로 받아서 마치 AutoEncoder 형태로 generator를 구성합니다. 따라서 Generator에는 encoder,decoder networks가 있습니다. Pix2Pix는 UNET을 Generator로 사용하게 되는데, 이것은 mirrored layers 사이에 skip-connections이 있다는 특징이 있습니다. Skip-connections은 AE에서 downsampling을 할때 손실되는 정보들의 보존(특히 low level features)해주며, backpropagation이 진행될 때 vanishing gradient를 방지해줍니다.
초창기 GANs 아키텍쳐처럼 노이즈 벡터를 입력으로 받는것이 아니라, 이미지들을 입력으로 받아서 마치 AutoEncoder 형태로 generator를 구성합니다. 따라서 Generator에는 encoder,decoder networks가 있습니다. Pix2Pix는 UNET을 Generator로 사용하게 되는데, 이것은 mirrored layers 사이에 skip-connections이 있다는 특징이 있습니다. Skip-connections은 AE에서 downsampling을 할때 손실되는 정보들의 보존(특히 low level features)해주며, backpropagation이 진행될 때 vanishing gradient를 방지해줍니다.
5. PatchGAN Discriminator
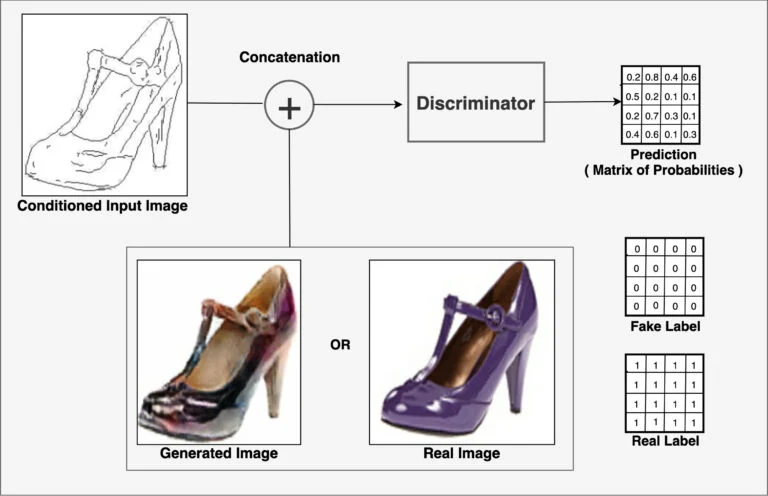 Pix2Pix의 Discriminator역시 다른 GANs과 마찬가지로 real/fake를 구분하는 것이 목적입니다. Pix2Pix는 PatchGAN이라 불리는 Discriminator를 사용하는데, output으로 확률값(scalar)을 내놓는 대신에, 영역의 Tensor값들을 반환합니다. 즉, 입력 이미지에 대해서 discriminator는 행렬값을 반환하게 되는데, 이미지 전체를 한번에 판단하는 것보다, 세부 영역들에 대해 구분한 값을 반환하게 됩니다.
Pix2Pix의 Discriminator역시 다른 GANs과 마찬가지로 real/fake를 구분하는 것이 목적입니다. Pix2Pix는 PatchGAN이라 불리는 Discriminator를 사용하는데, output으로 확률값(scalar)을 내놓는 대신에, 영역의 Tensor값들을 반환합니다. 즉, 입력 이미지에 대해서 discriminator는 행렬값을 반환하게 되는데, 이미지 전체를 한번에 판단하는 것보다, 세부 영역들에 대해 구분한 값을 반환하게 됩니다.
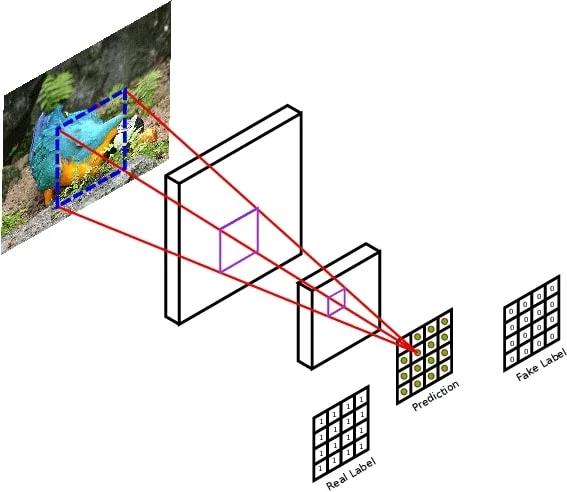
PatchGAN 구조
- Discriminator는 standard Convolution-BatchNormalization-ReLU blocks 구조로 되어있습니다
- 네트워크는 하나의 real/fake predictions의 single feature map을 출력합니다.
- Conditional Discriminator: CGAN의 영향을 받아서, discrminator는 주어진 조건을 이용하여 입력 이미지의 real/fake를 판단합니다. 따라서 입력은 real/fake 이미지들에 condition image들이 concatenate된 형태로 되어있습니다.
- Patch: [256, 256, n_channels] 차원의 입력 이미지가 패치들로 분류된다는 의미는, output이 [30, 30] 형태의 텐서가 반한된다는 의미입니다. 즉 [70, 70] 크기의 patch에 대해 판단된 확률값이 각각의 grid 안에 들어가 있습니다.
위의 그림을 살펴보면, output prediction matrix는 각각의 패치가 real/fake인지 판단된 값들이 저장되어 있습니다. PatchGAN NxN의 패치에 대해 real/fake를 판단한 이후에 평균을 내어서 궁극적인 결과물인 D를 얻어 냅니다 위 논문에서는 70x70 크기의 patch가 가장 effective하다고 소개하고 있습니다. PatchGAN의 장점으로는 discriminator가 real.fake를 잘 판단한다는 점과 generator가 더 잘 속이도록 도와준다는 점입니다. 만약 generator에서 생성된 이미지가 PatchGAN에 들어가면, 0으로 가득찬 matrix를 반환하도록 학습될 것입니다. 반대로 real images에 대해서, PatchGAN은 1로 가득찬 matrix를 반환하도록 학습할 것입니다.
6. Pix2Pix Loss
Generator와 Discriminator를 optimize하기 위해서 standard한 훈련 방법은 gradient step을 G와 D를 번갈아 가며 학습시키는 것입니다. 본 논문에서는 Discriminator의 역할은 변하지 않지만, Generator의 역할은 D를 속이는 거 뿐만 아니라 L2 distance가 ground-truth와 가장 가깝게 만드는 것입니다. 본 논문에서는 또한 L1와 L2를 비교하였는데, L1이 덜 blurring 하다는 결과를 보여주고 있습니다.
Discriminator
Pix2Pix Discriminator는 이전의 GANs모델과 같인 loss함수를 사용합니다. 즉, real과 fake를 구별하기 위해, negative log-likelihood를 최소화하는 것이 목표입니다. 또한 저자는 Generator보다 빨리 학습하는 것을 방지하기 위해 2로 나누어 주었습니다.

Generator
실제 라벨값들은 Generator를 학습시키는데 사용됩니다. 또한 추가적인 L1 loss 항을 본 논문에서는 더해주었는데, error를 최소화하는데 사용됩니다. L1 loss값들은 실제 정답과 예측값들 간의 차이의 절댓값이며, L1 규제를 통해서 translated된 이미지가 target하고 유사하지 않는 경우 penelty를 부여하는 역할을 합니다.
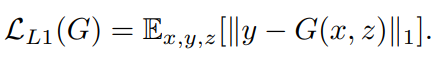
Total Loss
기존 GAN 모델들의 loss함수에 위에서 언급한 L1 loss항을 더해준 것이 최종적인 pix2pix GAN의 Total loss라 할 수 있습니다.
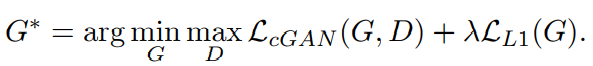
7. Pytorch Implementation

import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as data
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as plt
from math import log10 # For metric function
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'DataLoader
# Load Dataset from ImageFolder
class Dataset(data.Dataset): # torch기본 Dataset 상속받기
def __init__(self, image_dir, direction):
super(Dataset, self).__init__() # 초기화 상속
self.direction = direction #
self.a_path = os.path.join(image_dir, "a") # a는 건물 사진
self.b_path = os.path.join(image_dir, "b") # b는 Segmentation Mask
self.image_filenames = [x for x in os.listdir(self.a_path)] # a 폴더에 있는 파일 목록
self.transform = transforms.Compose([transforms.Resize((256, 256)), # 이미지 크기 조정
transforms.ToTensor(), # Numpy -> Tensor
transforms.Normalize(mean=(0.5, 0.5, 0.5),
std=(0.5, 0.5, 0.5)) # Normalization : -1 ~ 1 range
])
self.len = len(self.image_filenames)
def __getitem__(self, index):
# 건물사진과 Segmentation mask를 각각 a,b 폴더에서 불러오기
a = Image.open(os.path.join(self.a_path, self.image_filenames[index])).convert('RGB') # 건물 사진
b = Image.open(os.path.join(self.b_path, self.image_filenames[index])).convert('RGB') # Segmentation 사진
# 이미지 전처리
a = self.transform(a)
b = self.transform(b)
if self.direction == "a2b": # 건물 -> Segmentation
return a, b
else: # Segmentation -> 건물
return b, a
def __len__(self):
return self.len
train_dataset = Dataset("./data/facades/train/", "b2a")
test_dataset = Dataset("./data/facades/test/", "b2a")
train_loader = DataLoader(dataset=train_dataset, num_workers=0, batch_size=1, shuffle=True) # Shuffle
test_loader = DataLoader(dataset=test_dataset, num_workers=0, batch_size=1, shuffle=False)num_workers는 현재 작업하고 있는 환경 내에서 어떤 프로세스에 데이터를 불러올 것인지 조정하는 파라미터입니다. 0이 Default값이며, 0은 Main Process에 데이터를 불러오는 것을 의미합니다. 만약 Multi-Processing을 이용해서 데이터를 로드할 경우 Process의 개수에 맞게 할당하여 인자값을 조절하기도 합니다.
# -1 ~ 1사이의 값을 0~1사이로 만들어준다
def denorm(x):
out = (x + 1) / 2
return out.clamp(0, 1)
# 이미지 시각화 함수
def show_images(real_a, real_b, fake_b):
plt.figure(figsize=(30,90))
plt.subplot(131)
plt.imshow(real_a.cpu().data.numpy().transpose(1,2,0))
plt.xticks([])
plt.yticks([])
plt.subplot(132)
plt.imshow(real_b.cpu().data.numpy().transpose(1,2,0))
plt.xticks([])
plt.yticks([])
plt.subplot(133)
plt.imshow(fake_b.cpu().data.numpy().transpose(1,2,0))
plt.xticks([])
plt.yticks([])
plt.show()Conv & DeConv function
# Conv -> Batchnorm -> Activate function Layer
'''
코드 단순화를 위한 convolution block 생성을 위한 함수
Encoder에서 사용될 예정
'''
def conv(c_in, c_out, k_size, stride=2, pad=1, bn=True, activation='relu'):
layers = []
# Conv layer
layers.append(nn.Conv2d(c_in, c_out, k_size, stride, pad, bias=False))
# Batch Normalization
if bn:
layers.append(nn.BatchNorm2d(c_out))
# Activation
if activation == 'lrelu':
layers.append(nn.LeakyReLU(0.2))
elif activation == 'relu':
layers.append(nn.ReLU())
elif activation == 'tanh':
layers.append(nn.Tanh())
elif activation == 'none':
pass
return nn.Sequential(*layers)
# Deconv -> BatchNorm -> Activate function Layer
'''
코드 단순화를 위한 convolution block 생성을 위한 함수
Decoder에서 이미지 복원을 위해 사용될 예정
'''
def deconv(c_in, c_out, k_size, stride=2, pad=1, bn=True, activation='lrelu'):
layers = []
# Deconv.
layers.append(nn.ConvTranspose2d(c_in, c_out, k_size, stride, pad, bias=False))
# Batchnorm
if bn:
layers.append(nn.BatchNorm2d(c_out))
# Activation
if activation == 'lrelu':
layers.append(nn.LeakyReLU(0.2))
elif activation == 'relu':
layers.append(nn.ReLU())
elif activation == 'tanh':
layers.append(nn.Tanh())
elif activation == 'none':
pass
return nn.Sequential(*layers)Generator - UNET
class Generator(nn.Module):
# initializers
def __init__(self):
super(Generator, self).__init__()
# Unet encoder
self.conv1 = conv(3, 64, 4, bn=False, activation='lrelu') # (B, 64, 128, 128)
self.conv2 = conv(64, 128, 4, activation='lrelu') # (B, 128, 64, 64)
self.conv3 = conv(128, 256, 4, activation='lrelu') # (B, 256, 32, 32)
self.conv4 = conv(256, 512, 4, activation='lrelu') # (B, 512, 16, 16)
self.conv5 = conv(512, 512, 4, activation='lrelu') # (B, 512, 8, 8)
self.conv6 = conv(512, 512, 4, activation='lrelu') # (B, 512, 4, 4)
self.conv7 = conv(512, 512, 4, activation='lrelu') # (B, 512, 2, 2)
self.conv8 = conv(512, 512, 4, bn=False, activation='relu') # (B, 512, 1, 1)
# Unet decoder
self.deconv1 = deconv(512, 512, 4, activation='relu') # (B, 512, 2, 2)
self.deconv2 = deconv(1024, 512, 4, activation='relu') # (B, 512, 4, 4)
self.deconv3 = deconv(1024, 512, 4, activation='relu') # (B, 512, 8, 8) # Hint : U-Net에서는 Encoder에서 넘어온 Feature를 Concat합니다! (Channel이 2배)
self.deconv4 = deconv(1024, 512, 4, activation='relu') # (B, 512, 16, 16)
self.deconv5 = deconv(1024, 256, 4, activation='relu') # (B, 256, 32, 32)
self.deconv6 = deconv(512, 128, 4, activation='relu') # (B, 128, 64, 64)
self.deconv7 = deconv(256, 64, 4, activation='relu') # (B, 64, 128, 128)
self.deconv8 = deconv(128, 3, 4, activation='tanh') # (B, 3, 256, 256)
# forward method
def forward(self, input):
# Unet encoder
e1 = self.conv1(input)
e2 = self.conv2(e1)
e3 = self.conv3(e2)
e4 = self.conv4(e3)
e5 = self.conv5(e4)
e6 = self.conv6(e5)
e7 = self.conv7(e6)
e8 = self.conv8(e7)
# Unet decoder
d1 = F.dropout(self.deconv1(e8), 0.5, training=True)
d2 = F.dropout(self.deconv2(torch.cat([d1, e7], 1)), 0.5, training=True)
d3 = F.dropout(self.deconv3(torch.cat([d2, e6], 1)), 0.5, training=True)
d4 = self.deconv4(torch.cat([d3, e5], 1))
d5 = self.deconv5(torch.cat([d4, e4], 1))
d6 = self.deconv6(torch.cat([d5, e3], 1))
d7 = self.deconv7(torch.cat([d6, e2], 1))
output = self.deconv8(torch.cat([d7, e1], 1))
return outputDiscriminator - PatchGAN
5개의 convolution의 receptive field, 즉 patch들만 보고 실제인지 fake인지 판단
class Discriminator(nn.Module):
# initializers
def __init__(self):
super(Discriminator, self).__init__()
self.conv1 = conv(6, 64, 4, bn=False, activation='lrelu')
self.conv2 = conv(64, 128, 4, activation='lrelu')
self.conv3 = conv(128, 256, 4, activation='lrelu')
self.conv4 = conv(256, 512, 4, 1, 1, activation='lrelu')
self.conv5 = conv(512, 1, 4, 1, 1, activation='none')
# forward method
def forward(self, input):
out = self.conv1(input)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
return outTrain
# Generator와 Discriminator를 GPU로 보내기
G = Generator().cuda()
D = Discriminator().cuda()
criterionL1 = nn.L1Loss().cuda()
criterionMSE = nn.MSELoss().cuda()
# Setup optimizer
g_optimizer = optim.Adam(G.parameters(), lr=0.0002, betas=(0.5, 0.999))
d_optimizer = optim.Adam(D.parameters(), lr=0.0002, betas=(0.5, 0.999))
# Train
for epoch in range(1, 100):
for i, (real_a, real_b) in enumerate(train_loader, 1):
# forward
real_a, real_b = real_a.cuda(), real_b.cuda()
real_label = torch.ones(1).cuda()
fake_label = torch.zeros(1).cuda()
fake_b = G(real_a) # G가 생성한 fake Segmentation mask
#============= Train the discriminator =============#
# train with fake
fake_ab = torch.cat((real_a, fake_b), 1)
pred_fake = D.forward(fake_ab.detach())
loss_d_fake = criterionMSE(pred_fake, fake_label)
# train with real
real_ab = torch.cat((real_a, real_b), 1)
pred_real = D.forward(real_ab)
loss_d_real = criterionMSE(pred_real, real_label)
# Combined D loss
loss_d = (loss_d_fake + loss_d_real) * 0.5
# Backprop + Optimize
D.zero_grad()
loss_d.backward()
d_optimizer.step()
#=============== Train the generator ===============#
# First, G(A) should fake the discriminator
fake_ab = torch.cat((real_a, fake_b), 1)
pred_fake = D.forward(fake_ab)
loss_g_gan = criterionMSE(pred_fake, real_label)
# Second, G(A) = B
loss_g_l1 = criterionL1(fake_b, real_b) * 10
loss_g = loss_g_gan + loss_g_l1
# Backprop + Optimize
G.zero_grad()
D.zero_grad()
loss_g.backward()
g_optimizer.step()
if i % 200 == 0:
print('======================================================================================================')
print('Epoch [%d/%d], Step[%d/%d], d_loss: %.4f, g_loss: %.4f'
% (epoch, 100, i, len(train_loader), loss_d.item(), loss_g.item()))
print('======================================================================================================')
show_images(denorm(real_a.squeeze()), denorm(real_b.squeeze()), denorm(fake_b.squeeze()))생성 결과
Epoch [99/100], Step[400/400], d_loss: 0.2500, g_loss: 1.5049 ======================================================================================================```

왼쪽 순으로 Facade 입력 이미지, 실제 이미지(ground truth), 생성된 이미지(Facade->RGB) 결과를 확인할 수 있습니다.
Reference
- https://github.com/eriklindernoren/PyTorch-GAN
- Fastcampus, The Red 주재걸 교수님 실습 자료 中
