[논문리뷰] Image-to-Image Translation with Conditional Adversarial Networks, 2017, CVPR
논문 리뷰 및 실습
- paper : link

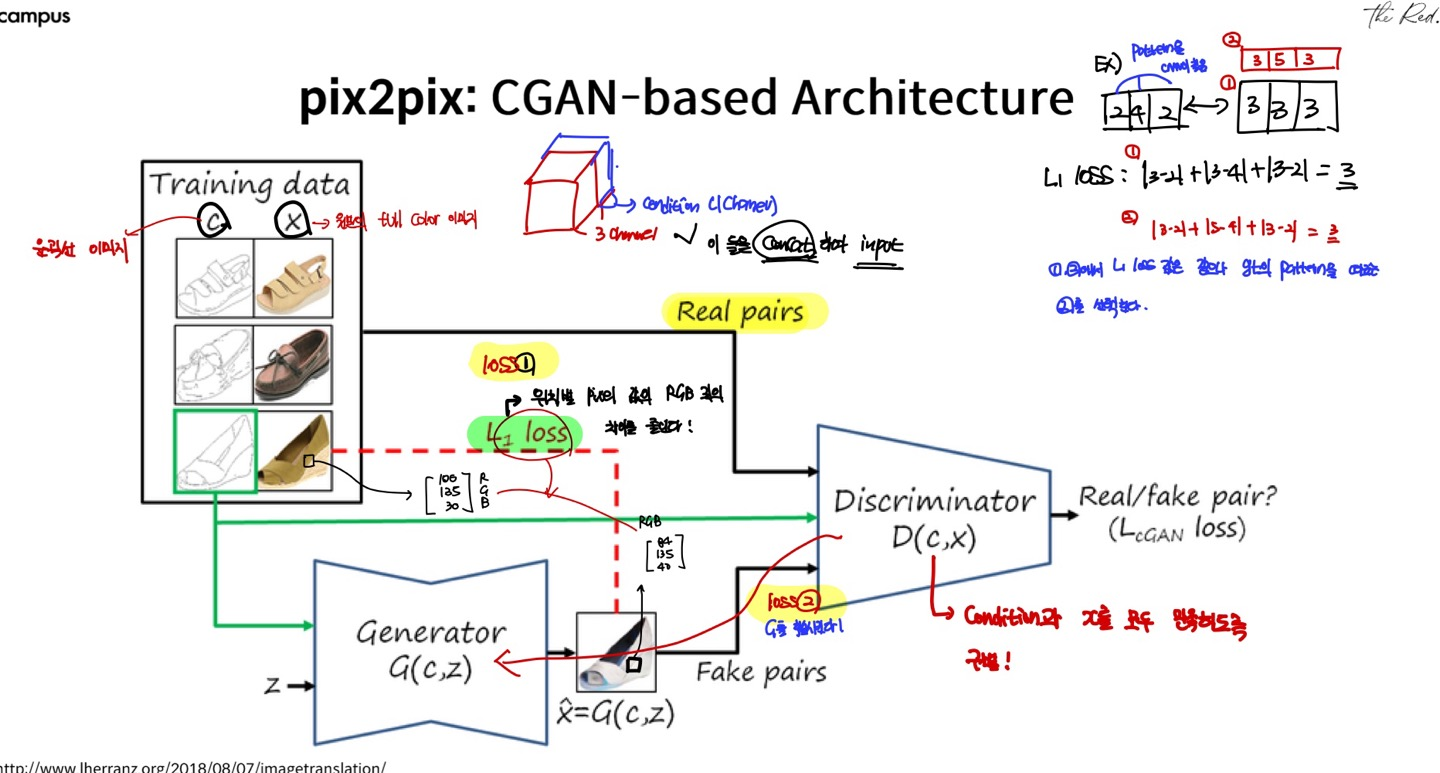
본 논문은 흔히 Pix2Pix로 알려진 아키텍쳐를 제시한 논문입니다. CGAN을 기반으로 하였기에, 입력에 Condition과 Input image를 같이 넣어서 trnslated된 이미지를 출력하게 됩니다. Condition에 부합한 이미지를 생성하게 되며, L1 loss를 통해서 위치별 pixel값의 RGB값과의 차이를 줄입니다.
Abstract
Conditional adversarial networks를 기반으로 범용적인 image-to-image translation task를 수행하는 방법을 제기합니다. 신경망은 input->output으로 가는 mapping 뿐만 아니라, 이 mapping을 학습시키는 loss function도 학습하게 됩니다.

1. Introduction
이미지 분야에 있어 많은 문제들은 input image를 output image로 translate하는 것과 연관이 있습니다. 이러한 task들을 image-to-image translation이라 부릅니다. 본 논문의 목적은 이러한 image-to-image translation의 일반적인 framework를 제시하는 것이라 하고 있습니다.
CNNs은 image prediction 문제를 해결하는데 많이 사용되고 있으며, loss function을 최소화하는 방향으로 학습하여 좋은 결과를 내며, 학습과정도 automatic하지만, effective loss를 설계하는데 많은 노력이 필요합니다. 즉, CNN에게 어떤 것을 최소화해야 할지 알려주어야 합니다.
GAN은 데이터에 맞게 loss를 학습하기 때문에, 여러 task에 활용될 수 있다고 합니다. cGAN은 특히 입력이미지에 조건을 같이 주어 해당되는 출력값을 주기에 image-to-image translation tasks에 적합하다고 합니다.
본 논문의 contribution으로는 CGANs기반으로 다양한 문제를 해결할 수 있으며, 이에 대한 simple한 framework를 제공한다는 점입니다.
2. Related works
본 논문은 관련 연구로 Structured losses for image modeling과 conditional GAN을 소개하고 있습니다.
3. Method
GANS은 random noise vector z에서 output image y로의 mapping(G:y->z)를 학습하는 생성 모델입니다. Conditional GAN은 조건으로 입력되는 이미지 x와 random noise vector z에서 y로의 mapping(G:x,y->z)를 학습하는 것입니다. Generator는 실제이미지와 구별이 안되는 이미지를 생성하려는 반면, Discriminator는 생성된 이미지를 fake로 판별하려 합니다.
3.1 Objective
conditional GAN의 목적함수는 다음과 같습니다. 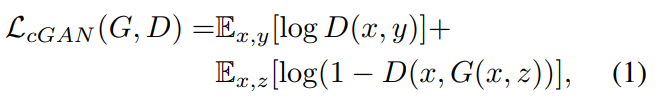 G는 loss를 최소화하려는 반면, D는 loss를 최대화하려 합니다. 이전 연구들에서 GAN의 loss함수에 L2, L1과 같은 traditional loss를 섞는 것이 beneficial하다는 것이 밝혀졌습니다. Discriminator의 역할은 변하지 않지만, Generator는 Discriminator를 속이는 것에 더하여 ground truth값이 traditional loss에 따라 가까워지도록 학습되니다. 본 논문에서는 L2 distance보다 L1을 사용하는 것이 less bluring하다고 하여, L1 loss를 아래와 같이 추가하였다고 합니다.
G는 loss를 최소화하려는 반면, D는 loss를 최대화하려 합니다. 이전 연구들에서 GAN의 loss함수에 L2, L1과 같은 traditional loss를 섞는 것이 beneficial하다는 것이 밝혀졌습니다. Discriminator의 역할은 변하지 않지만, Generator는 Discriminator를 속이는 것에 더하여 ground truth값이 traditional loss에 따라 가까워지도록 학습되니다. 본 논문에서는 L2 distance보다 L1을 사용하는 것이 less bluring하다고 하여, L1 loss를 아래와 같이 추가하였다고 합니다. 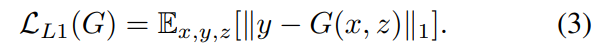
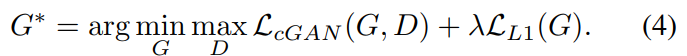 저자들은 기존의 condtional GANs처럼 noise z를 단순히 generator의 input으로 같이 넣어주는 것은, generator가 학습과정에서 노이즈를 무시하기 때문에 효율적이지 않다고 생각하였다고 합니다. 따라서 noise를 dropout form의 형태로, 여러층에서 제공될 수 있도록 하였다고 합니다. Conditional GAN은 대게 stocahstic output을 출력하기 때문에, model의 conditional distribution을 capture하는 것이 중요하며, 이것은 현재 연구되어야 할 부분이라고 하고 있습니다.
저자들은 기존의 condtional GANs처럼 noise z를 단순히 generator의 input으로 같이 넣어주는 것은, generator가 학습과정에서 노이즈를 무시하기 때문에 효율적이지 않다고 생각하였다고 합니다. 따라서 noise를 dropout form의 형태로, 여러층에서 제공될 수 있도록 하였다고 합니다. Conditional GAN은 대게 stocahstic output을 출력하기 때문에, model의 conditional distribution을 capture하는 것이 중요하며, 이것은 현재 연구되어야 할 부분이라고 하고 있습니다.
3.2 Network architectures
3.2.1 Generators with skips
기존의 많은 연구들이 encoder-decoder network을 사용하였습니다. Input 이미지들은 여러 layer을 통과하여 downsampling 됩니다. 모든 정보들이 layers들을 통과하게 됩니다. 수많은 iamge translation problems에서 low-level information이 input과 output에 공유되고, 이 정보를 net전체에 전달하는 것이 바람직하다 합니다. 예를 들어서 colorization의 경우, input과 output은 주요한 선들의 위치를 공유하게 됩니다.
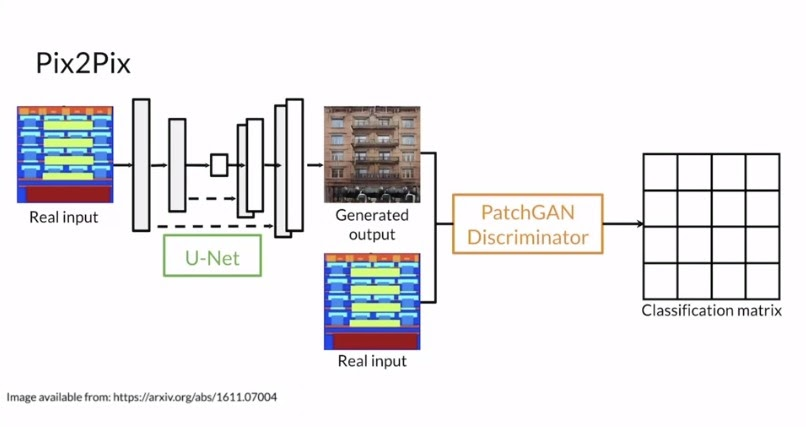
따라서 저자는 skip-connections를 사용한 U-Net generator를 사용하였다고 합니다! 이를 통해 low-level 정보들이 보존되어 input & output에 사용된다고 합니다 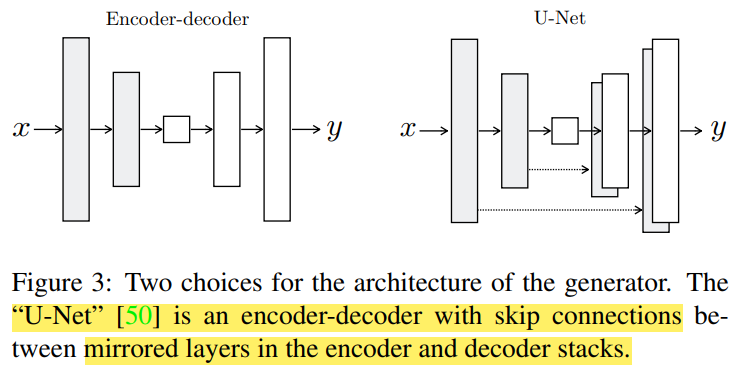
3.2.2 Markovian discriminator(PatchGAN)
 위의 그림처럼 L2, L1 loss만을 사용하게 되면 blurry한 결과들이 생성되는 문제가 있다고 합니다. 하지만 L1 loss는 low frequencies를 정확하게 capture한다는 장점이 있다고 합니다. 이로인해 GAN discriminator은 high-frequency structure을 모델링하고, 나머지는 low-frequency는 L1에 맞겨두면 된다고 합니다. High frequncies를 모델링하기 위해서, 저자는 local image patches에 집중하는 것만으로 충분하다고 하고 있으며, 필자들은 disciminator acrhitecture를 patchGAN이라 불리는 구조를 사용했다고 합니다. Disciminator는 NxN patch크기로 patch가 real/fake를 판단하며, 모든 이미지 패치들에 대한 convolution을 통해서 output을 얻게 됩니다. Patch size N은 매우 작아도 high quality result를 만들어낸다고 하며, 적은 파라미터수와 빨리 된다는 장점이 있다고 합니다.
위의 그림처럼 L2, L1 loss만을 사용하게 되면 blurry한 결과들이 생성되는 문제가 있다고 합니다. 하지만 L1 loss는 low frequencies를 정확하게 capture한다는 장점이 있다고 합니다. 이로인해 GAN discriminator은 high-frequency structure을 모델링하고, 나머지는 low-frequency는 L1에 맞겨두면 된다고 합니다. High frequncies를 모델링하기 위해서, 저자는 local image patches에 집중하는 것만으로 충분하다고 하고 있으며, 필자들은 disciminator acrhitecture를 patchGAN이라 불리는 구조를 사용했다고 합니다. Disciminator는 NxN patch크기로 patch가 real/fake를 판단하며, 모든 이미지 패치들에 대한 convolution을 통해서 output을 얻게 됩니다. Patch size N은 매우 작아도 high quality result를 만들어낸다고 하며, 적은 파라미터수와 빨리 된다는 장점이 있다고 합니다. 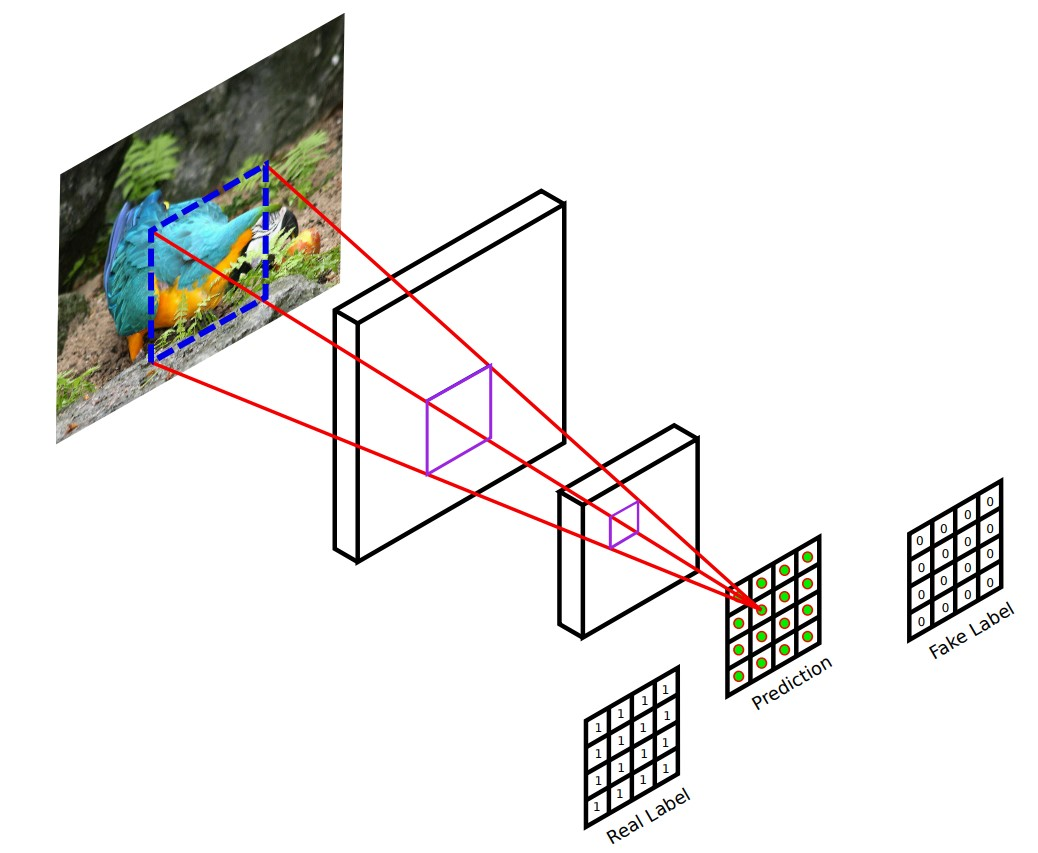
3.3 Optimization and Inference
신경망을 최적화하기 위해서 필자는 D와 G를 번갈아가며 gradient descent step을 진행하였다고 합니다. 또한 D를 학습시키는 동안 loss를 절반으로 나눠서, G에 학습속도에 맞게 하였다고 합니다.
4. Experiments

4.1 Metrics
본 논문에서는 생성 모델의 성능 지표로 AMT perceptual studies와 FCN-score을 사용다고 합니다. AMT perceptual 지표는 사람들이 직접 생성된 이미지와 실제 이미지에 대해서 real/fake를 판단하는 것입니다. FCN-score은 pre-trained semantic classfier(FCN-8s)를 이용하여 생성된 이미지들의 segmanctic segmentation 결과를 통해서 realistic한지 판단하는 것입니다.
4.2 Analysis of the objective function
필자는 loss를 L1 term, GAN term으로 분리하여 각각만 사용해본 경우와 비교해보고, input에 condition을 준 경우와 그렇지 않은 경우의 discriminator를 비교하였다고 합니다.
L1 loss만을 사용하는 경우에는 그럴듯 하지만, blurry한 결과를 얻는다고 합니다. cGAN loss만을 사용하는 경우에는 sharper한 result를 얻지만 시각적인 인공물들이 군데군데 생겼다고 합니다. Condition을 주지 않는 경우에는 input-output 간의 mismatch를 penalize하지 않는다고 합니다.
Loss는 input과 output간의 mismatch를 측정하는 지표이며, cGAN이 GAN보다 좋은 결과를 낸다고 합니다. 또한 L1 term을 추가함으로써, ground truth과 output의 distance를 줄여주여서, input과 match될 수 있도록 해준다고 합니다. 또한 L1은 ground truth와 분포보다 narrow 만들고 이를 cGAN이 넓혀준다고 합니다.
4.3. Analysis of the generator architecture
U-Net 아키텍쳐를 통해 low-level 정보들이 신경망 전체에 전달된다고 합니다. Encoder-Decoder에 skip-connection을 더하면 U-Net구조를 만들 수 있습니다.
4.4. From PixelGANs to PatchGANs to ImageGANs
이 섹션에서는 patch size N을 1(pixel단위)부터 이미지 전체 크기까지 receptive field를 넓혀가며 비교한 결과를 제시하고 있습니다. 70x70 patch 사이즈가 가장 잘 된다고 하네요.  pixel단위의 patch는 공간적인 sharpness는 없었지만, colorfulness를 잘 살렸다고 합니다. 16x16 사이즈는 sharpness가 증가하였고 좋은 FCN-score을 달성했지만, 인공물이 생겼다고 합니다. 70x70이 가장 잘 되었고 장애물들이 생성되지 않았다고 합니다.
pixel단위의 patch는 공간적인 sharpness는 없었지만, colorfulness를 잘 살렸다고 합니다. 16x16 사이즈는 sharpness가 증가하였고 좋은 FCN-score을 달성했지만, 인공물이 생겼다고 합니다. 70x70이 가장 잘 되었고 장애물들이 생성되지 않았다고 합니다.
4.5 & 4.6 Perceptual validation and Semantic segmentation
본 노문에서는 perceptual realism을 보여주기 위해 다양한 task의 translation 결과를 보여주고 있습니다.
Aerial photo <-> map

Segmentation

5. Conclusion
본 연구는 conditional adversarial networks를 사용한 범용적인 image-to-image translation 방법에 대해 제시하였다고 합니다. 신경망은 task와 data에 맞게 loss를 학습하며 이를 통해 여러 setting이 가능하다고 합니다!
Reference
- Fast campus, The Red 주재걸 교수님 강의 中
