Expert-as-a-Service: Towards Efficient, Scalable, and Robust Large-scale MoE Serving
ML System
그동안 WBL 작업이랑 ICML 논문 제출로 인해 블로그 관리에 너무 소홀한 것 같다. 그래서 간만에 준비한 내용으로 MoE랑 ML system 관련한 논문을 준비했다. 어딘가 아직 학회에 올라온 내용은 아니고, 아직은 아카이브에만 떠돌고 있는 논문으로, WBL을 하면서 생각보다 MoE에 대해서 사람들이 많은 관심을 가지고 있는 것 같았다. 사내에서도 따로 MoE 스터디를 하면서 좀 더 MoE inference랑 이걸 지원 할 수 있는 시스템에 대해 생각해보고자 이 논문을 들고 왔다.
MoE Serving의 비효율성
MoE의 경우, 기존의 동일한 파라미터를 가지는 모델에 비해 표현력이 좋고, activation 되는 파라미터는 훨씬 적기 때문에 표현력 대비 연산량이 좋은 방식으로 알려져 있다. 하지만 이걸 학습 시키는 것과 inference 하는 것이 상당히 까다롭다는 문제점이 있다. 학습의 경우, router에서 발생하는 load balancing을 맞춰주는 것이 굉장이 까다롭다. 이 문제의 경우는 오늘 다룰 내용이 아니다.
반면 inference의 경우는 (아마도?) 조금 상황이 낫다. DeepSeek 덕분에 MoE가 주목을 뜨겁게 받기 시작하면서 vLLM이나 SGLang 같은 대표적인 serving framework들이 MoE와 관련된 피쳐들을 제공하기 시작했다. DeepEP 같은 expert parallelism (EP) 관련하여 all-to-all 통신을 최적화한 기능이 대표적인 예시이다. 그럼에도 불구하고 MoE serving은 여전히 문제가 많다. 일단 여전히 MoE는 GPU가 필요하다. 그나마 Qwen3-30B-A3B 같은 작은 사이즈의 MoE도 존재하지만, 일반적으로 MoE는 많은 수의 expert를 할당해야 하고, 대부분의 파라미터가 attention 보다는 expert에 치중되어 있다. 또한 MoE는 대부분의 경우, all-to-all communication으로 인한 통신 문제가 존재한다. MoE는 attention과 expert 사이에 all-to-all 통신으로 토큰을 라우팅 하는 것이 일반적인데, 만약 expert가 DeepSeek 계열처럼 많은 경우라면, 이 통신에서 병목이 발생 될 수 있다.
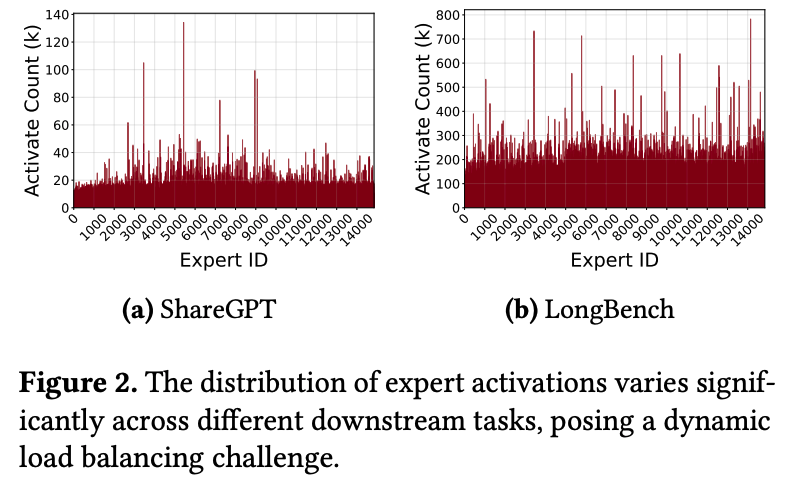
마지막으로는 학습에서 발생하는 load imbalancing 문제는 serving에서도 발생한다. 그렇기 때문에 특정 expert가 과하게 활성화 되면 다른 expert는 idle 상태가 되면서 EP가 비효율로 남게 되는 경우가 발생한다. 위 그래프는 데이터셋에 따라서 활성화 되는 expert의 수를 측정한 기록이다. 특정 expert는 자주 활성화 되지만, 그렇지 않은 expert도 존재한다.
결국 위 3가지 문제로 인해서 scalability의 문제도 발생하게 된다. 만약 EP로 배포 된 상태에서 하나의 expert가 문제라도 발생하게 된다면, 그 MoE 그룹은 전체적으로 못쓰는 그룹이 되어버린다. 그래서 MoE를 확장성 있게 배포를 하려면 결국 이 모든 것으로 고려해서 fine-grained보다는 coarse-grained한 형태로 배포를 할 수 밖에 없는데, 여기서 다시 비효율이 발생하게 된다.
Stateless Feature of Expert Layer
MoE 배포의 특징 중 하나는 앞서 언급 된 결함적인 내용 말고도 몇가지 흥미로운 점이 더 있다. 대부분의 LLM 아키텍쳐들이 그렇지만, MoE 역시 KV cache를 만들어내는 attention 레이어와 FFN으로 이루어진 expert들이 있다. 이 두 레이어 사이에는 서로 상반되는 다음과 같은 특징이 있다.
- Attenton: sequence가 들어오면 KV cache를 생성하고, 이를 사용한다. 그래서 stateful이다.
- Expert(FFN): token의 hidden state를 받아서 순수하게 출력만을 생성한다. 그래서 stateless다.
MoE 배포는 expert가 stateless한 특성을 가지고 있음에도, stateful인 attention과 결합되기 때문에 위에서 언급한 문제가 발생하게 되는 것이다. 그렇기 때문에 배포의 측면에서는 최악의 결과만을 물려받는 셈이 된다.
EaaS의 경우, expert가 stateless임에 주목하여 replication에 효과적임을 이용한다. 이들은 서로 교체가 가능하기 때문에, 장애가 발생하더라도 attention과 분리만 되어 있다면 KV cache 같은 state 손실 없이 복구가 가능하다. 즉, 기존에는 all-or-nothing이였던 복구 방식을 일시적으로 성능의 저하는 있지만 점진적으로 복구가 가능하도록 robustness를 추가해주는 요소로 바꿀 수 있다. 또한 위 그래프처럼 특정 expert에 부하가 몰리는 상황에서도 추가적인 expert replication만 달아준다면 load-imbalance가 완화 될 수 있다.
EaaS: Expert-as-a-Service
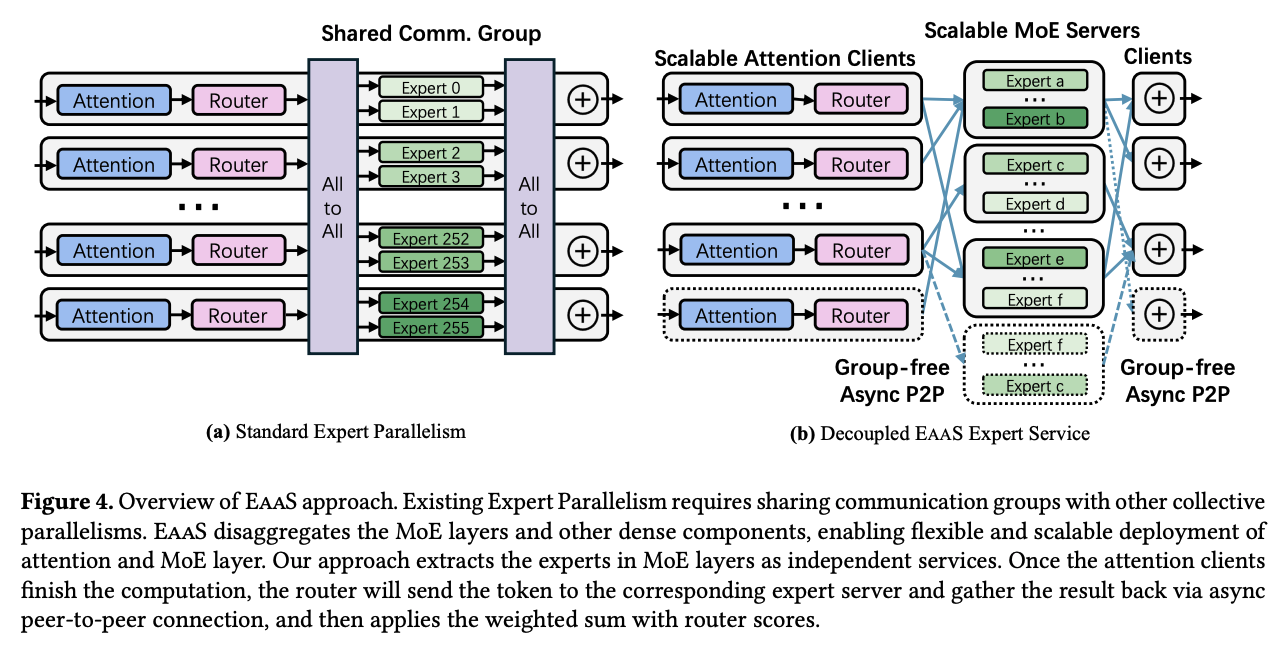
위 그림은 기존의 MoE 배포(a)와 EaaS(b)에서 제안하는 EP 방식의 차이점을 보여주는 그림이다. 기존 EP의 경우, attention과 expert를 정적인 그룹에서 강하게 결합시키는 monolithic 방식을 사용하고 있다. 그래서 어느 한 포인트에 장애가 발생하면 복구를 위해서는 MoE 전체를 재배포 시켜야 한다.
반면 EaaS에서는 attention은 client로써 router에서 peer-to-peer(P2P) 통신을 expert와 수행하게 된다. expert는 scalable한 서버 형태로 attention client들의 부분 집합만을 호스팅하여 독립적인 stateless 서버 형태로 역할을 수행하게 된다.
Shared Communication Buffer
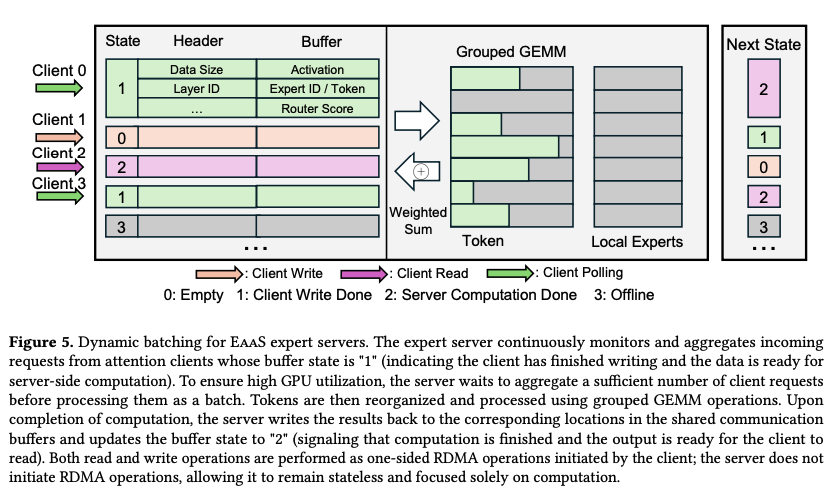
Attention client와 expert server는 효율적이고 비동기 형태의 통신을 수행하기 위해서 shared communication buffer가 필요하다. 각 attention client는 전용 버퍼 슬롯을 할당을 받게 되고, 이는 state, header, data payload로 이루어져 있다.
- State
단일 바이트로 이루어져 있고, 버퍼의 상태를 나타낸다. 예를들어, state=0 값이라면 클라이언트가 데이터를 기록할 수 있는 상태라던가, state=2 값이라면, 서버 연산이 완료되어 클라이언트가 결과를 읽을 수 있음을 의미한다. - Header
요청을 위한 메타데이터가 포함된다. layer의 고유 ID, batch size등이 포함 된다. - Data payload
실제 연산에 필요한 hidden state나 각 토큰에 대한 expert ID 매핑, 그리고 output weight을 위한 router score가 포함 된다.
이러한 설계로 인하여 client는 요청 데이터의 기록과 결과의 읽기를 담당하고, 서버는 요청을 읽어 연산을 수행한 뒤 결과를 기록하는 역할만을 수행한다.
Fault Tolerance Mechanism
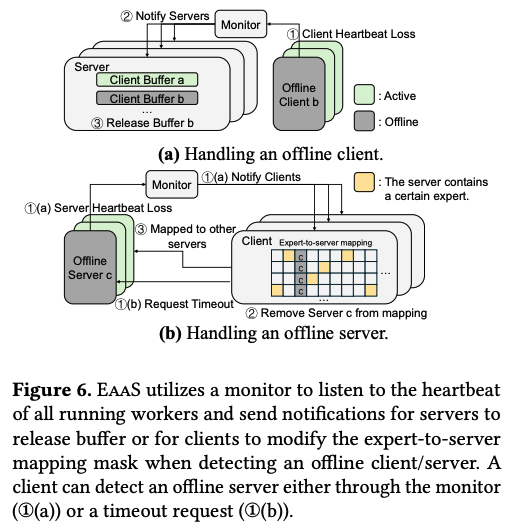
EaaS에서 장애가 발생하게 되면, 이에 대한 복구를 위해서 중앙에서 각 서버들의 heartbeat를 지속적으로 모니터링 한다. 장애 발생은 attention client 장애와 expert server 장애 2가지로 나뉘어 처리가 된다.
우선 (a) 그림과 같은 attention client 측에서 장애가 발생하게 되면, 중앙 모니터링에서 이에 대한 heartbeat를 감지하고 모든 expert 서버에게 알린다. 이를 수신 받은 expert 서버들은 장애가 발생한 attention client에 할당 된 모든 communication buffer를 즉시 해제한다. 이에 따라 resource-lock을 피할 수 있게 되면서 장애는 해당 attention client를 이용하는 요청에만 국한이 되면서 다른 요청들에 대해서는 영향이 최소화 되도록 한다.
(b)의 경우는 expert server 측에서 장애가 발생한 경우이다. 이러한 장애는 2가지 경로로 감지가 되는데, 하나는 expert server에 대한 heartbeat에 문제가 발생한 경우이고, 다른 하나는 attention client에서 요청한 request에서 time-out이 발생한 경우이다. 어느 경우로 발생을 하든, attention client는 즉시 로컬에서 유지하고 있던 expert server 매핑을 갱신하여 장애가 발생한 expert server를 가용 resource 리스트에서 제거한다. 장애가 발생한 expert는 replica를 만들고, replica가 성공적으로 연결이 되면 장애가 발생했던 요청들을 해당 replica 방향으로 돌려서 장애를 처리하게 된다.
Expert Kernel 최적화
EaaS는 MoE의 load-imbalance 문제로 인해서 GPU grid를 활용하는 커널 최적화 기법이 포함되어 있다. 이에 대한 알고리즘은 다음과 같다.

각 블록은 batch 안에 유효한 토큰들에 대해서 iteration을 수행한다. 만약 batch가 비어 있다면 건너뛰고, 그렇지 않다면 shared memory를 활용하여 토큰을 stride 형태로 분배시킨다. 이 방식은 GPU thread에 전반적으로 적용이 되기 때문에 load-balancing을 효과적으로 수행 할 수 있다. 따라서 idle thread나 추가적인 동기화 오버헤드 없이도 서버가 batch imbalace에 유연하게 대응할 수 있도록 한다.
또다른 문제점으로는 다수의 expert를 GPU 하나에 호스팅 해야 할 때 발생한다. 기존 방식인 DeepGEMM은 비활성 되어 있는 expert 그룹을 전체적으로 탐색하고, 각 그룹마다 throughput이 낮은 global memory 접근을 발생시키기 때문에 병목이 일어난다. 그래서 EaaS는 GPU prefix scan을 활용하여 활성화 된 expert 그룹만 골라내고, 해당 메타데이터를 앞부분으로 이동시키는 group-shrink 커널을 도입하였다. 이를 통해 early-stop이 가능해지면서, DeepGEMM 스케줄러는 압축된 텐서를 탐색하게 되기 때문에 shared memory에 한 번만 로드 되고, 이로 인해 반복적이고 효율적인 탐색이 가능하게 된다.
Attention Client에서의 Double-Batch Overlap (DBO)
DBO는 원래 DeepSeek에서 제안 된 Dual-Batch Overlap을 의미하는데, 여기서는 Double-Batch Overlap으로 사용 되었다. 단어는 다르지만 메커니즘은 똑같다. EaaS에서 관측 할 수 있는 또다른 병목으로는 attention client에서 remote expert server로 토큰을 전송 할 때 발생하는 latency가 있다. 이에 따라서 통신과 연산을 중첩 시켜야 할 필요가 있는데, 여기서 DBO가 사용 된다.
Attention client 쪽 pipeline에는 2개의 활성화 된 batch를 유지시킨다. 이렇게 되면 GPU에서는 지속적으로 연산에 참여하는 것을 보장하게 된다. 예를들어, batch A가 remote expert 서버에서 처리 되는 동안, attention client GPU는 대기하지 않고 즉시 다음 batch B에 대해 연산량이 큰 attention 연산을 수행시킨다. 이렇게 되면 batch B의 attention 연산이 batch A의 통신 및 원격 expert 연산을 숨길 수 있게 된다. batch A가 리턴이 되는 시점에는 이미 batch B는 전송 준비가 완료 된 상태가 된다.
EaaS의 Communication Optimization
IBGDA 기반 P2P 통신 방식
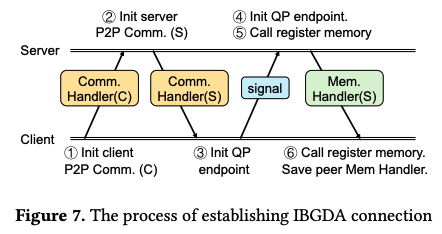
EaaS 방식의 배포를 위해서 저자들은 InfiniBand GPUDirect Async(IBGDA)을 사용하였다. 위 그림은 새로운 IBGDA 연결 설정을 위한 방식이 나타나있다.
- 클라이언트는 자신의 IBGDA P2P 통신 handler를 포함한 http 요청을 서버로 전송한다.
- request를 받은 서버는 mirroring 연산을 수행한다.
- client는 QP state를 변경하고, 이를 서버쪽에 알린다.
- client와 server는 GPU 버퍼 등록을 완료하고 각자의 MR 및 버퍼 주소를 교환한다.
앞서 fault tolerance에서 언급 된 중앙 모니터링 컴포넌트는 IBGDA 통신 제어에도 관여를 한다. 이는 모든 client와 server의 상태를 추적하고, 특정 rank가 온라인 또는 오프라인 상태로 전환될 때 이를 broadcast 시키는 방식으로 동작의 on-off를 알리게 된다.
Dynamic Load-Balancing
EaaS는 vLLM에서 사용 되는 EPLB 같이 expert를 재정렬하고 중복 expert를 추가함으로써 expert parallelism instance 사이에 부하를 분산하는 기존의 대표적인 MoE 부하 분산 기법들과 호환이 된다. 거기에 3가지 확장이 가능한 요소가 포함 된다.
- 기존 EP와는 달리, EaaS에서는 각 expert 서버에 배치되는 expert 수가 동일할 필요가 없다. 이는 서버별 expert가 stateless로 유지 되기 때문에, 부하를 분산할 수 있는 여지를 제공한다.
- IBGDA 연결 메커니즘을 기반으로, EaaS는 hot expert와 cold expert에 대해 서비스 instance 수를 동적으로 확장 또는 축소함으로써 부하를 조절할 수 있다.
- Attention과 분리 된 expert 배포 구조 덕분에 expert가 호스팅되는 인스턴스의 연산 및 메모리 사양을 변경하는 방식으로도 부하 분산이 가능하다.
실험 결과
실험 환경
EaaS를 실험하기 위해서 저자들은 DeepSeek-R1 모델을 8x16대의 Hopper 아키텍쳐 GPU를 사용했다고 한다. 데이터셋은 SharedGPT가 사용 되었고, long-tail 현상을 완화 시키기 위해서 응답 토큰은 768 토큰으로 제한하였다고 한다.
비교 대상으로는 vLLM과 SGLang이 사용 되었다. SGLang의 경우, Mooncake를 이용하여 PD disaggregation이 적용이 되었으며, EaaS 역시 Mooncake를 베이스로 개발이 되었다고 한다. vLLM의 경우에는 DeepEP를 이용한 EP와 TP를 동시에 적용하였다고 한다. 거기에 비슷한 연구로는 MegaScale-Infer와 StepMesh가 있는데, 두 방식은 CPU를 통신 과정에 사용하는 GDRCopy 기반의 비대칭 통신 라이브러리를 사용한다. 그러나 MegaScale-Infer는 오픈소스가 아니기 때문에, StepMesh만을 비교했다고 한다.
MegaScale-Infer는 이전 글에서 리뷰를 했었다!
https://velog.io/@with1015/SIGCOMM25-MegaScale-Infer-Serving-Mixture-of-Experts-at-Scale-with-Disaggregated-Expert-Parallelism
End-to-End evaluation
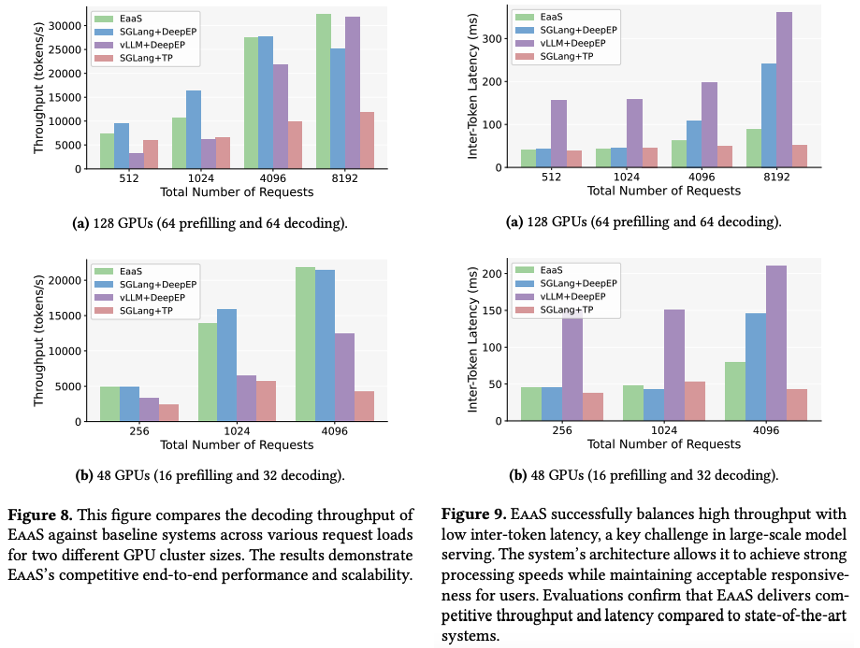
위 그래프들은 EaaS를 다양한 비율로 PD disaggregation을 수행했을 때의 throughput 결과이다. (a) 그래프에서 사용 된 설정은 128대의 GPU에서 prefill에 64개, decoding에서 64개로 나누었고, (b)에서는 48대의 GPU를 16대의 prefill, 32대의 decode로 사용했다.
decoding을 할 때, SGLang+DeepEP는 완전한 EP 구조가 사용 되었다. 이 설정에서 각각 EP size를 64와 32로 설정을 했다. 반면 EaaS는 client-server 구조를 사용하여 각각 32개의 client와 32개의 server, 또는 16 client 16 server를 사용했다. SGLang+TP는 TP의 제약으로 인해 16 GPU 단위로만 동작 할 수 있다. 그래서 TP를 사용하는 경우, 두 설정에서 model weight을 각각 4번, 2번 복제해야 했다고 한다.
request가 비교적 적을 때는 SGLang+DeepEP가 throughput과 ITL에서 괜찮은 성능을 보여준다. 하지만 트래픽이 증가 할 수록 long-tail latency가 관찰 되었다. 이는 DP가 적용 된 attention rank들 사이에 communication overhead와 load-balancing의 한계로 인한 문제에서 기인하는 것으로 보인다. SGLang+TP는 inference 단위가 16 GPU 정도로 낮기 때문에 안정적인 ITL을 볼 수 있따. 하지만 이러한 작은 단위의 크기는 model weight의 replica를 여러개 요구하게 된다. 그 결과, GPU당 가용 메모리가 감소하기 때문에 최대 batch size가 제한이 된다. 이는 throughput 저하로 이어지게 된다.
vLLM의 PD disaggregation은 아직 최적화가 제대로 이루어지지 않았다. 그래서 EaaS와의 비교 실험에서는 prefill과 decode를 동일 노드에 할당을 하고, 공정한 비교를 위해 prefill overhead를 제외하여 64/32 GPU에 대한 decode 성능만 평가하였다고 한다. vLLM의 경우, 대규모의 구성에서 throughput이 좋게 나오지만, 다른 방식에 비해서 ITL이 높다는 단점을 보였다.
EaaS의 경우, 적절한 ITL과 함께 어느 규모에서든 throughput이 높게 측정이 되었다. 적은 트래픽에서는 비록 SGLang+DeepEP 보다는 낮은 throughput을 보이긴 했지만, 배포의 측면에서도 이점이 존재하기 때문에 충분히 경쟁력을 보인다고 할 수 있다.
Scalability
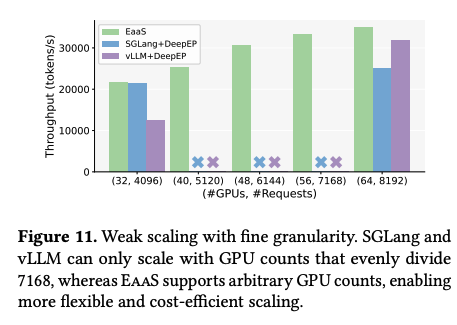
위 그래프는 EaaS의 scalability 측정을 위해서 GPU 수와 요청 수를 늘렸을 때의 throughput 측정 결과이다. EaaS의 경우, 32 GPU에서 64 GPU까지 늘렸을 때, 거의 linear 하게 throughput이 증가했다. 반면 SGLang과 vLLM의 경우에는 32 GPU에서 64 GPU 사이의 설정에서 동작이 불가능 했다. 이는 vLLM과 SGLang이 monolithic한 구조를 사용하기 때문에 표준 GPU 개수 외의 설정에서는 동작이 불가능함을 시사한다.
이에 비해 EaaS는 fine-grained한 확장성으로 인한 이점으로는, 만약 8192 트래픽에서 5120으로 감소하는 경우, vLLM과 SGLang은 여전히 64개의 decode GPU를 유지해야 한다. 하지만 EaaS는 GPU 개수를 축소 함으로써 연산 자원 절감이 가능하다.
Fault tolerance
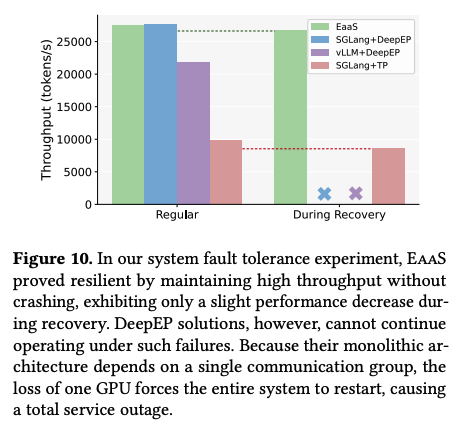
EaaS의 fault tolerance를 평가하기 위해서, 저자들은 GPU 10개를 하나씩 무작위로 비활성화 시킨 뒤, 복구 과정 동안 발생하는 평균 decoding throuhgput을 측정하였다. 그 결과는 위 그래프와 같았다. SGLang과 vLLM은 모든 decoding GPU가 단일 communication group을 사용하기 때문에 복구 과정에서 serving이 전부 중단이 된다. 즉, 단 하나의 GPU라도 장애가 발생하면 전체 그룹을 재시작 해야한다.
반면 SGLang+TP는 16 GPU를 하나의 그룹으로 묶어서 사용하기 때문에 하나의 그룹만 재시작하면 되었다. EaaS는 attention client는 서로 독립적으로 동작하고, clinet에 장애가 발생하더라고 PD disaggregation의 routing 메커니즘 덕분에 효율적으로 처리가 된다. 그래서 복구 도중에도 높은 throuhgput을 유지하며, throughput 감소는 2% 미만 선에서 처리가 되는 것을 볼 수 있다.
다른 Async communication 방식들과 비교
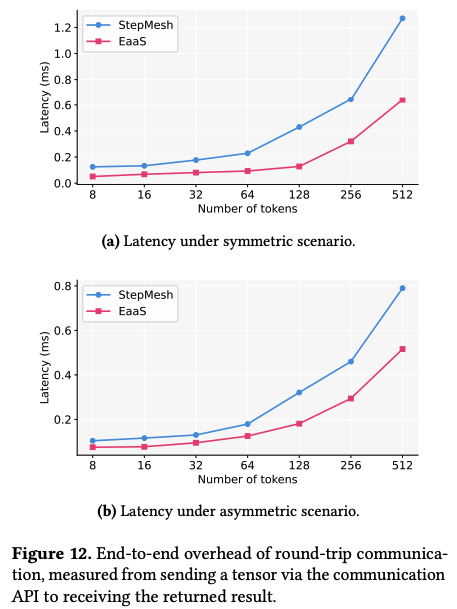
EaaS의 통신 방식을 비교하기 위해서 StepMesh가 사용 되었다. 실험은 2개의 client와 2개의 server를 가지는 대칭 설정과 1 client 3 server로 이루어진 비대칭 설정에서 측정 되었다. EaaS는 두 설정에서 StepMesh보다 더 낮은 latency를 보여준다. 특히 batch가 커질수록 두 프레임워크 사이의 차이가 커지는데, 이는 EaaS가 IBGDA를 활용하여 CPU를 우회함으로써, host memory queue 접근 및 CPU에서 발생되는 제어 명령과 관련된 오버헤드를 제거하였기 때문이다. 또한 전체 과정이 완전히 CPU-free로 수행되기 때문에, CUDA Graph 캡처를 통해 통신 커널의 launch 오버헤드를 추가로 줄일 수 있다.
위 실험을 통해서 StepMesh와 MegaScale-Infer와 같은 기존 시스템들이 아직 제공하지 못하는 CPU-free 통신 라이브러리의 중요성을 분명히 보여주었다. commnication 수준에서의 오버헤드 감소가 대규모 inference 환경에서 end-to-end latency 감소로 직접 이어지며, 실제 배포 환경에서 사용자 체감 응답성을 향상시킨다는 점을 보여준다.
Ablation experiment
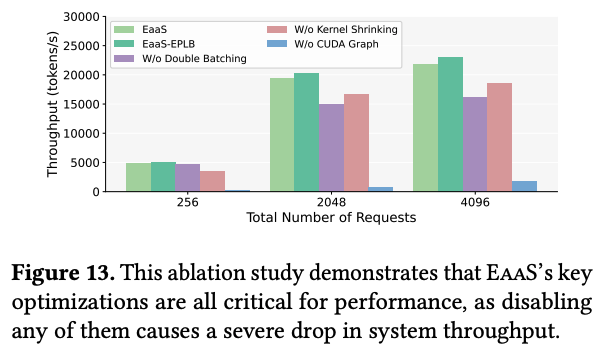
마지막 실험으로, EaaS의 각 컴포넌트의 기여도를 알기 위해서, ablation 실험을 진행하였다. 저자들은 3가지 요소를 비활성화 하면서 최적화를 분석하였다.
- CPU 개입을 제거하여 커널 런치 오버헤드를 줄이는 CUDA Graph 캡처
- 그룹 메타데이터를 압축하여 expert server의 효율을 향상시키는 kernel shrinking
- attention 계산과 communication을 overlap 시키는 DBO 기능
위 그래프 결과처럼, 이들 최적화 중 어느 하나라도 제거할 경우 성능 저하가 발생한다. CUDA Graph를 비활성화하는 경우, CPU 측 kernel launch 오버헤드가 반복적으로 발생하여 throughput이 급감한다. kernel shrinking을 제거하면, sparse expert 그룹에 대한 비효율적인 스케줄링으로 인해 throughput이 감소한다. 마지막으로, DBO를 제거하는 경우, communcation latency가 attention 연산과 겹쳐지지 못해 성능 저하가 나타난다.
또한, DeepSeek에서 사용 된 EPLB를 EaaS와 결합한 평가도 수행하였다. 그 결과 각각 2.4%, 4.4%, 5.1%의 성능 향상이 관측되었다고 한다.
결론 및 고찰
EaaS는 기존에 attention-expert가 강하게 결합 되어 monolithic한 구조로 배포되는 MoE를 stateless인 expert의 특성에 맞게 scalable한 구조로 바꾸어 vLLM이나 SGLang보다 좀 더 robust한 MoE inference 환경을 맞추는 논문이었다.
이 논문을 읽으면서 MegaScale-Infer가 여러번 언급이 되는데, 이 논문을 예전에 한 번 리뷰해보길 잘했다는 생각이 든다. 추가로 DBO 같은 DeepSeek에서 사용 된 최적화 방식들이 vLLM에서도 그렇고 여기저기서 많이 발견이 되는 것 같다. 회사에서 MoE 스터디를 할 때도 이러한 기능들이 지속적으로 언급이 되기 때문에 분석해야 할 여지가 큰 것 같다.
끝으로 결국에는 MoE는 통신 아니면 expert load-balancing을 주제로 개선해나가는 방식 밖에 잘 떠오르지 않는 것 같다. 좀 더 남들이 하지 않았던 방향을 보고 개선하고 싶은 의욕은 있으나... 역시 모티베이션이 대부분 그런 방향에서 나오는 것으로 보아서는 어쩔 수 없나? 라는 생각이 계속 들게 된다.
