[SIGCOMM'25] MegaScale-Infer: Serving Mixture-of-Experts at Scale with Disaggregated Expert Parallelism
ML System
얼마 전 카카오에서 발표한 Kanana-MoE도 그렇고, NVIDIA의 주가를 3% 가량 떨어뜨린 DeepSeek도 그렇고 MoE를 적용한 모델 연구가 계속 이루어지고 있다. 그와 더불어 MoE 자체의 특성을 이용하여 추론에 활용하는 연구도 동시에 진행 되고 있는데, 이 논문도 그러한 종류 중 하나이다.
Large-scale MoE Model Serving
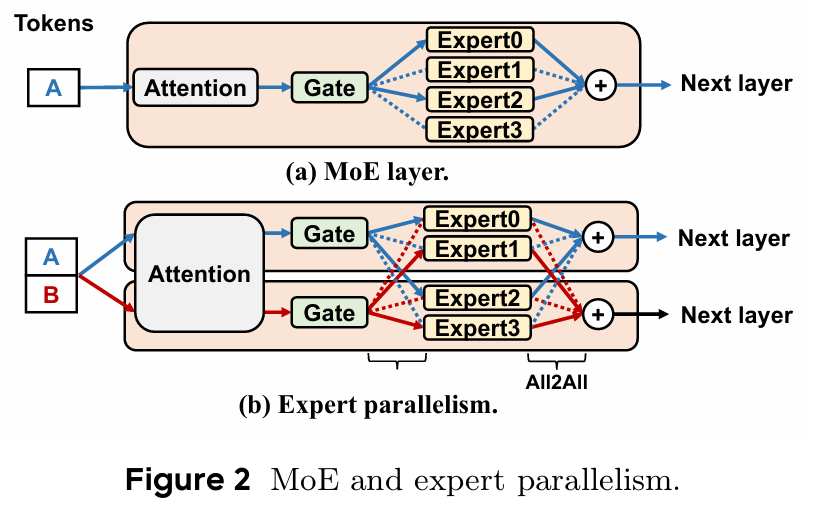
흔히 알려진 사실로, LLM의 성능은 모델의 파라미터 수에 비례하여 증가 된다고 알려져 있다. MoE 모델은 기존의 모델 파라미터를 Dense하게 사용하는 방식 대신에, Expert를 두고, Gate가 토큰을 특정 기준에 따라 Expert로 라우팅 시켜서 추론을 수행하는 방식을 사용한다.
이를 다수의 노드로 확장하는 방식으로는 Expert Parallelism이 있다. 기존의 Model Parallelism처럼 MoE 모델이 너무 클 때, 다수의 GPU에 Expert를 분산 시키는 방식으로, 2번의 All-to-All communication을 GPU 사이에서 수행해야 한다. 어느정도 통신에 대한 오버헤드가 존재하기 때문에, NVLink 같은 GPU-to-GPU 장비가 없다면 추론 시에 지연 시간이 꽤 발생하게 된다. 또한 MoE의 고질적인 문제인 Token의 load-balancing 문제도 존재 할 수 있다.
그럼에도, 각 GPU의 Expert는 Tensor Parallelism과 다르게 하나의 완전한 GEMM을 수행하기 때문에 Tensor Parallelism에 비해서 GPU 연산 효율은 뛰어나다는 장점이 있다.
MoE Sparsity 증가의 문제점
MoE 구조가 가지는 장점으로 인해 모델 파라미터의 크기가 증가 하더라도, 모든 레이어로 route 되는 것이 아니기 때문에 계산복잡도가 부분적으로 감소하는 경향을 많이 관측하게 되었다. 하지만 계산복잡도가 줄어든다고 해서 실제 서빙 환경에서까지 계산 비용이 줄어든다는 것은 아니다.
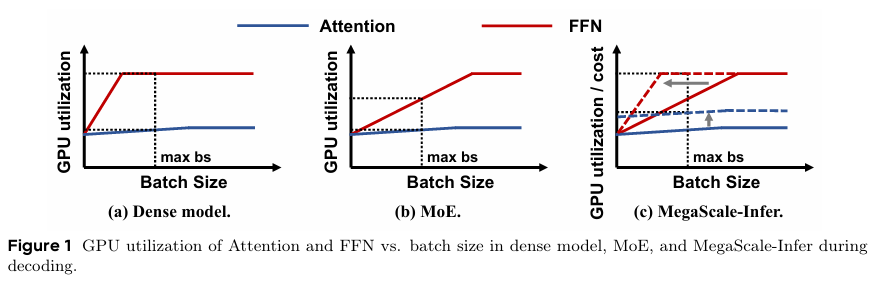
보통 Attention layer의 경우, decoding 단계에서 KV cache를 접근하는 memory-bound 작업이기 때문에 GPU의 utilization이 낮은 편이다. 반면, FFN은 토큰 수 (또는 batch)가 많아질수록 GPU utilization이 높아진다.
하지만 이는 모델의 상황에 따라서도 조금씩 다른데, 그 예시로 위 그래프를 보면 Dense model은 각 Transformer 하나마다 FFN이 하나라서 최대 batch size를 밀어 넣었을 때, FFN의 GPU utilization이 최대로 활용 될 수 있다.
반면 MoE의 경우, 모델이 커질 수록 Expert의 수가 증가하고, 이로 인해 Expert 사이의 communication도 많아지게 되면서 더이상 FFN이 computation-bound 작업이 아니게 된다. 그래서 최대 batch size를 밀어 넣어도 GPU utilization이 최대로 활용 되지 못함을 보인다.
MegaScale-Infer
결국 Expert의 Sparsity로 인해, Batch size의 증가로만 해결하지 못하는 GPU utilization의 문제를 저자는 Attention과 FFN을 분리 시키는 방식으로 해결하고자 했다. 이런 방식을 채택하는 경우, 저자는 다음과 같은 2가지 이점을 발견했다고 한다.
- Independent Scaling
Attention 모듈만 사용하는 독립적인 instance만 scaling이 가능하지고, FFN은 decoding 요청을 집계하여 실행만 하면 된다. 그렇게 되면 FFN의 GPU utilization이 증가하는 효과를 볼 수 있다.
- Heterogeneus Deployment
Attention과 FFN을 서로 다른 자원에 배포를 하게 하여 각 모듈에 좀 더 비용 효율적인 자원을 할당하는 것이 가능해진다.
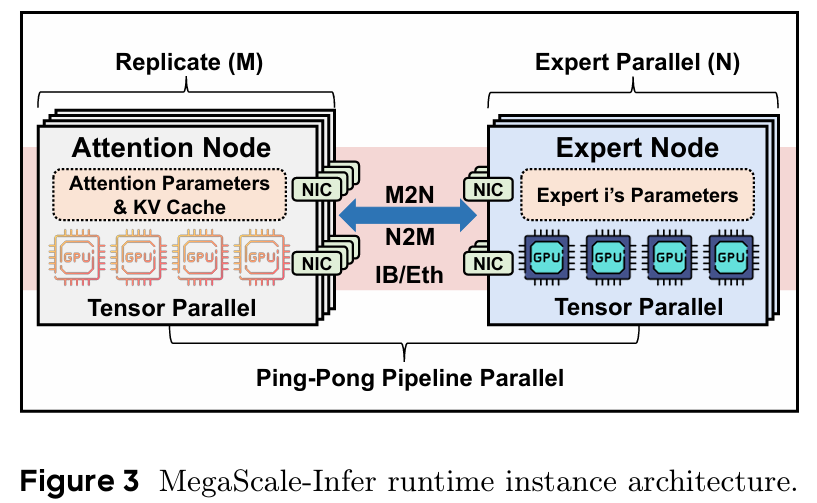
위 그림은 Decoding 단계에서 하나의 model replica에 대한 구조를 나타낸다. 기존의 Transformer는 Attenion와 FFN이 1:N의 mapping으로 이루어져 있었지만, MegaScale-Infer는 M:N의 매핑으로 구성 되어 있다.
각 Expert 노드는 단일 서버 내 1~8개의 GPU에 할당이 되고, 각 노드마다 하나의 Expert 파라미터만 저장한다. 그리고 모든 Expert를 묶어서 하나의 Expert 그룹을 형성한다.
마찬가지로 Attention 노드 역시 여러 GPU에 분산이 된다. 다만 Expert 노드와의 차이점은 Expert 노드는 서로 다른 파라미터를 가지지만, Attention 노드의 경우, DP처럼 모델이 복제 된 상태기 때문에 동일한 Parameter를 가지게 된다. 또한 각 노드마다 KV를 캐싱한다.
마지막으로, Attention 노드와 Expert 노드는 NVLink를 통해 메모리가 부족한 경우, Tensor Parallelism을 적용 할 수 있다.
Ping-Pong Parallelism
Disaggregated 된 Attention과 Expert 구조는 한 가지 문제점이 존재한다.
Atttention 노드가 활성화 되어 계산을 수행 중에는 Expert 노드가 Attention을 기다려야 하기 때문에 idle 상태가 될 수 있다. 그리고, GPU 노드끼리 M:N 통신을 수행하고 있을 때도 GPU가 idle 상태가 된다.
MegaScale-Infer에서는 이러한 문제점을 해결하기 위해 Ping-Pong Parallelism이라는 방식을 제시한다.
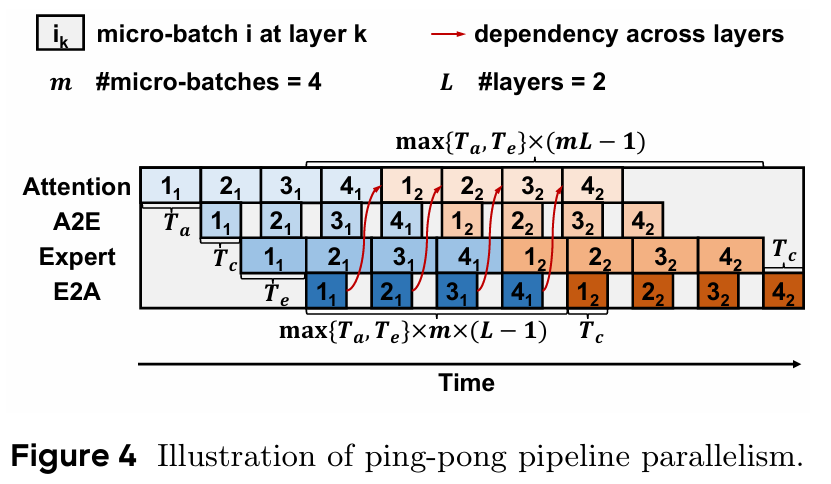
Ping-Pong parallelism은 요청이 들어온 배치를 여러 개의 마이크로 배치로 쪼갠다. 각 노드는 마이크로 배치에 대해서 Attention 연산을 먼저 수행 하고, Attention -> Expert 방향으로 연산이 완료 된 마이크로 배치를 전송한다. 그 사이, Attention 레이어는 다음 마이크로 배치에 대한 연산을 수행한다.
이러한 방식으로 Attention 연산 - M:N 통신 - Expert 연산 - 다음 Attention으로 전송 방식을 pipeline화 하여 overlap을 시키는 것이 ping-pong parallelism 방식이다.
다만, 이러한 ping-pong parallelism을 최적화 시키기 위해서는 몇가지 조건이 필요하다.
-
하나의 마이크로배치에 대해 Attention 연산에 소요 되는 시간과, Expert 연산에 소요 되는 시간이 거의 비슷해야 한다.
-
통신에 소요되는 시간이 Attention이나 Expert의 forward 시간보다 작아야 한다.
-
전체 마이크로 배치의 수가 충분히 커야 한다.
3번 조건에 대해서 수식으로 좀 더 자세히 보자면, 다음과 같이 최소 마이크로배치 크기를 정의 할 수 있다.
여기서 는 마이크로 배치 연산 사이의 통신 시간, 그리고 는 Attention과 Expert의 forward에 소요 되는 시간 중 큰 값이다.
Deployment Plan Search
앞서 ping-pong parallelism을 최대한 활용하기 위해서 필요한 조건 중 하나는 Attention 연산과 Expert 연산에 소요 되는 시간을 거의 비슷하게 맞춰 줘야 한다는 점이다.
Attention 연관과 Expert 연산의 경우, 모델에 따라서는 완전히 다른 레이어 구성으로 동작하고, MegaScale-Infer의 경우, heterogenuity를 가지고 Attention 노드와 Expert 노드를 분리하기 때문에 이에 대해 적절한 자원을 가진 노드를 선정하여 배포하는 것이 중요하다.
그래서 MegaScale-Infer의 Deployment Plan Search Space는 다음과 같은 요소들이 고려된다.
- Attention 노드의 Tensor Parallelism 크기 ()
- Expert 노드의 Tensor Parallelism 크기 ()
- Attention 노드의 수 ()
- 마이크로 배치 크기
- 전체 배치 크기 ()
MegaScale-Infer는 모델의 설정과 하드웨어의 구성에 따라서 최적으로 어떤 노드에 Attention과 Expert를 배포할지 결정하게 된다.

알고리즘을 살펴보면, 모든 expert와 attention에 대해서 OOM이 발생하지 않는 조건 하에 완전 탐색을 수행하게 된다. 알고리즘의 시간 복잡도는 을 따른다. 얼핏 보면 search space가 굉장히 크게 보이지만, 값은 하나의 노드에 장착 된 GPU의 수를 의미하며, 보통 많아봐야 8개가 장착 되기 때문에 그다지 큰 값은 아니다. 또한 마이크로배치를 나타내는 값도, 무한정 커지면 expert 노드에서 GEMM 연산 효율이 떨어지기 때문에 보통 4로 설정한다고 되어 있다.
Heterogeneous Deployment
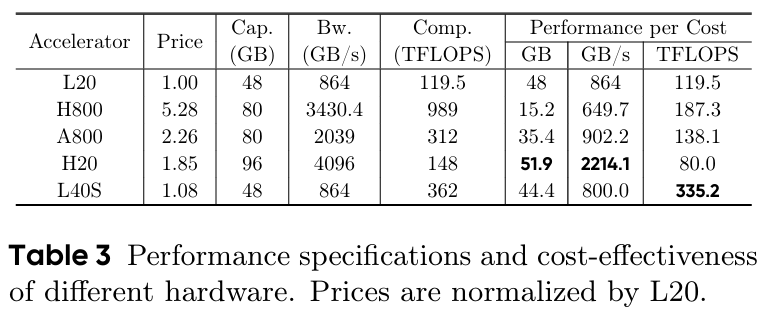
MegaScale-Infer는 Attention 레이어와 Expert 레이어 사이에 이기종 배포를 수행해야 한다.
그렇기 때문에 Attention과 Expert의 특성을 고려하여야 하고, 위와 같은 하드웨어 정보를 기반으로 고려 해볼 수 있을 것이다.
Attention의 경우, memory-bound 특성이 있기 때문에 H20과 같은 memory bandwidth나 memory size가 큰 GPU를 사용하는 것이 좋을 것이다. 반면 Expert는 compute-bound 특성이 있기 때문에 L40S와 같이 연산이 빠른 GPU를 사용하는 것이 좋을 것이다.
M2N Communication
Attention - Expert 사이에서 중요한 전제 조건 중 하나는, 두 레이어 사이의 통신에 대한 최적화였다. 이를 실현하기 위해서, MegaScale-Infer 저자들은 NCCL 대비 최적화 된 M:N 통신을 추가로 개발했다.
NCCL의 단점
보통 NVLink나 InfiniBand 같은 HW 스택이 아닌 SW 스택에서 GPU 사이의 통신 라이브러리를 꼽으라고 한다면 가장 먼저 NCCL이 나올 것이다. CUDA 버전이 올라감과 동시에 이것도 많은 개선이 이루어지긴 했는데, 이것이 Attention과 Expert 통신에서 사용 되기에는 몇가지 문제가 있다.
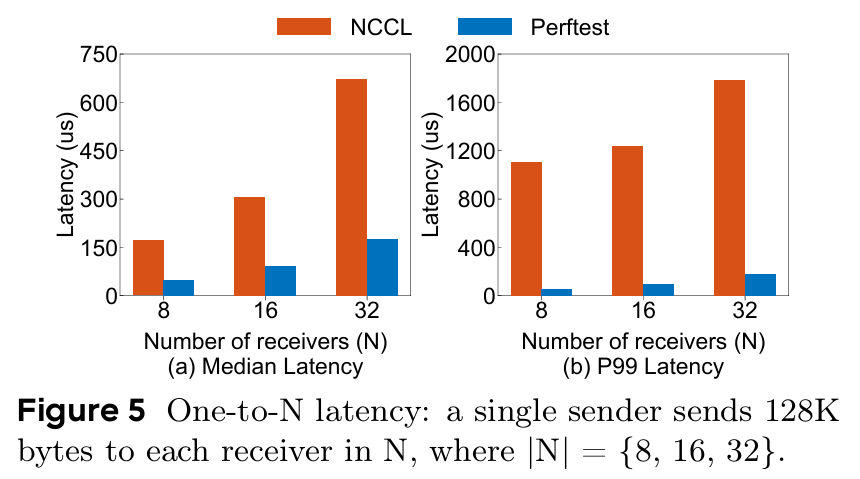
위 그림에서 NCCL과 PerfTest 사이의 latency를 비교했다. PerfTest의 경우는 네트워킹 micro-benchmark 도구로, 간단한 CPU 클라이언트 입장에서 latency와 throughput을 측정하도록 설계되어 있다. 그렇기 때문에 PerfTest는 달성 가능한 최저한의 지연 시간을 의미하는데, NCCL의 중간값이나 pertile 99%까지의 값들이 PerfTest에 비해 많은 오버헤드를 갖고 있음을 발견했다.
이에 대한 원인이 조금 복합적으로 작용하는데, 하드웨어의 발열 같은 외부적인 요인들은 둘째치고, 3가지 원인을 주 원인으로 꼽을 수 있다고 한다.
-
NCCL은 P2P 그룹 작업을 최대 8개까지만 한번에 작업이 가능하다. 따라서 receiver가 8 이상으로 늘어날수록 지연이 커진다.
-
NCCL은 GPU 메모리 -> CPU 프록시로 메모리 복사를 수행 한 후, 네트워크 작업을 수행한다.
-
NCCL은 범용 라이브러리기 때문에 그룹 연산 초기화 및 내부 처리, 검증등 추가 작업을 수행한다.
M2N Sender
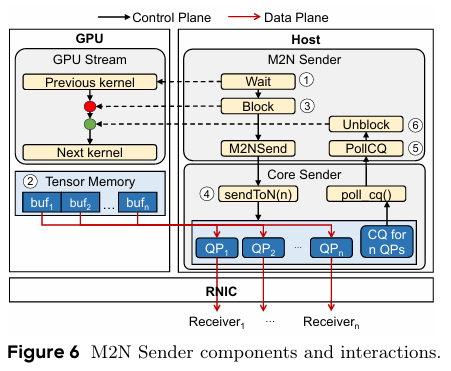
우선 Sender의 동작 방식을 먼저 살펴보자.
-
MegaScale-Infer의 Sender는 우선 GPU stream 내에서 CUDA event를 통해 이전 커널 동작이 끝날때까지 대기를 한다.
-
이후, 송신할 사전 등록된 tensor가 Tensor memory에 정상적으로 채워졌는지 확인한다.
-
전송이 끝난 후에 다음 커널이 실행되도록 보장하기 위해, M2N Sender는 CUDA 드라이버 연산을 사용해 GPU stream을 정지 시킨다.
-
CPU 통신 라이브러리가 RDMA write with immediate 방식을 통해 tensor를 전송한다.
-
tensor가 정상적으로 전송되었는지 확인하기 위해, Sender는 해당하는 completion queue에서 전송 완료 여부를 polling 한다. 이를 통해 데이터가 remote buffer에 제대로 쓰였는지 검증한다.
-
M2N Sender는 shared memory flag를 업데이트하여 GPU stream을 차단 해제하고, 이 후 커널들이 등록된 메모리를 재사용할 수 있도록 한다.
이와 같은 Sender의 과정은 다음과 같은 지연의 원인을 개선 할 수 있다.
- 복잡한 GPU 동기화
- GPU에서 CPU로의 복사
- 그룹 초기화 오버헤드
M2N Receiver
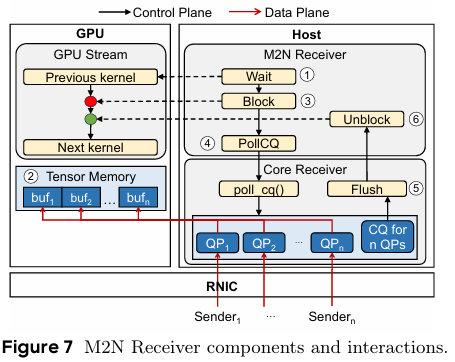
Receiver 역시 1번부터 3번까지의 흐름은 Sender와 유사하다. 사용 중이던 CUDA stream을 이전 kernel 실행이 끝날 때까지 기다렸다가 차단을 시켜 통신 작업이 완료 될 때까지 다음 커널 실행이 차단 되는 환경을 보장 시킨다.
-
Receiver는 먼저, 연결 된 Sender로부터 데이터가 성공적으로 전송되었는지를 completion queue를 polling하여 확인한다.
-
이후, GPU 수준에서 데이터 일관성을 확보하기 위해, Core Receiver가 GDRCopy를 활용하고, flush 연산을 수행한다.
-
마지막으로, M2N Receiver는 shared memory flag를 업데이트하여 GPU stream을 차단 해제하고, 이 후 커널들이 등록된 메모리를 재사용할 수 있도록 한다.
이와 같은 Receiver의 과정은 다음과 같은 효과를 볼 수 있다.
- GPU-to-GPU copy가 불필요해짐
- 수신 측 GPU 사용률의 오버헤드가 효과적으로 감소
vs DeepEP
이 논문에서는 DeepSeek에서 사용 된 DeepEP와도 비교를 한 부분이 있었다. 이것 역시 대규모의 Expert layer serving을 위한 통신 라이브러리를 최적화 한 부분인데, MegaScale-Infer와 어느 부분이 다른지 정리가 되어 있었다.
우선 DeepSeek의 경우, CPU 프록시 없이 GPU 간 직접 통신을 사용하지만, MegaScale-Infer는 CPU를 활용한 노드 간 통신으로 구현 되어 있다. 그렇기 때문에, DeepSeek는 통신에서도 Sender와 Receiver가 GPU 연산 자원을 사용하게 된다. 반면 MegaScale-Infer는 GPU 연산 자원을 통신에 사용하지 않기 때문에 computation kernel이 온전하게 GPU 자원을 사용 할 수 있다.
추가로 DeepEP는 통신이 GPU 연산 커널과 자원을 서로 사용하기 위해 contention을 일으키는 것을 방지하기 위해 커스텀 PTX 명령어라는 low-level 최적화를 수행하였다. 이를 통해 통신이 GPU의 L2 캐시를 사용하는 것을 최소화 시키고 가급적 연산 커널에 할당 되도록 유도했다고 한다.
만약 RDMA가 단일 QP를 사용하는 구조라면, CPU의 클럭속도가 더 빠르기 때문에 GPU보다 더 낮은 latency가 발생한다고 한다. 다만 GPU는 병렬 처리에 특화가 되어 있어, 각 SM마다 독립적인 QP 관리가 가능하기 때문에 Expert가 굉장히 많은 상태에서 패킷이 충분히 작다면 DeepEP가 더 유리하다고 되어 있다.
실험 결과
Homogeneus GPU 환경
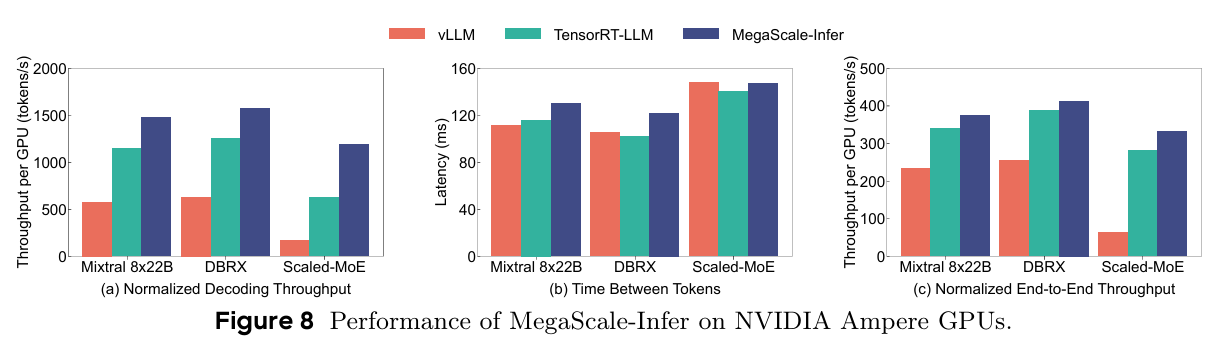
우선 MegaScale-Infer는 A100을 이용하여 vLLM, TensorRT-LLM을 베이스라인으로 단일 GPU 구성에서의 성능을 비교하였다. vLLM과 TensorRT-LLM은 모델 전체를 한 번에 배치하고 서비스를 하기 때문에 Expert 모듈에 들어가는 batch size가 작아지는 경향이 있다. TensorRT-LLM은 커스텀 커널 최적화 기능이 들어가서 vLLM보다 성능이 좋긴 하지만 FFN 모듈에서의 낮은 GPU 활용률 문제를 피할 수는 없었다.
또한 Scaled-MoE는 2개의 노드에 걸쳐서 deploy 되었는데, GPU 노드 사이의 통신 최적화가 이루어지지 않는 vLLM과 TensorRT-LLM는 이 모델에서 decoding throughput 격차가 더 많이 발생했다.
다만 TPOT의 경우 MegaScale-Infer가 제일 높은 경향을 보이는데, 이는 Attention과 Expert를 분리했기 때문에 노드 사이에 발생하는 통신이 원인이다. 그럼에도 성능 격차가 심하지 않은 것은 M:N 통신을 최적화 했기 때문이라고 말한다.
(c) 그림은 Prefill을 포함한 end-to-end throughput이다. 대부분 prefill이 compute-bound 작업이기 때문에 큰 성능 개선은 homogeneous 환경에서 이루어지지 않았지만 그럼에도 최대 1.18배까지 성능 향상이 이루어졌다고 한다.
Heterogeneus GPU 환경
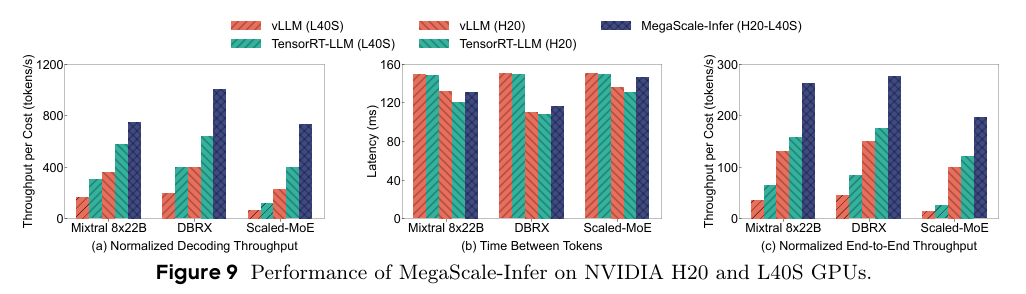
vLLM과 TensorRT-LLM의 경우엔 Heterogeneus GPU를 지원하지 않기 때문에 각 모델을 H20과 L40S에서 비교하였다. MegaScale-Infer는 Attention을 H20, Expert를 L40S에 배치하고 실험을 진행하였다.
L40S의 경우, memory-bound인 decoding 작업에서 약세를 보였고, H20은 decoding에서 상대적으로 효과적인 것을 관측 할 수 있었다. 그리고 이를 섞어서 사용한 MegaScale-Infer는 decoding에서 대부분의 경우 성능 이득을 많이 볼 수 있었다.
특히 Homogeneus 환경과는 다르게 TPOT에서도 성능 개선이 L40S에 비해 이루어졌는데, 이는 L40S가 메모리가 작아서 communication overhead가 더 많이 발생했기 때문이라고 한다.
end-to-end의 경우에서도 Prefill보다는 Decoding이 대부분 overhead가 큰 편이라, L40S의 성능이 제일 떨어졌다고 분석한다.
M2N communication 실험
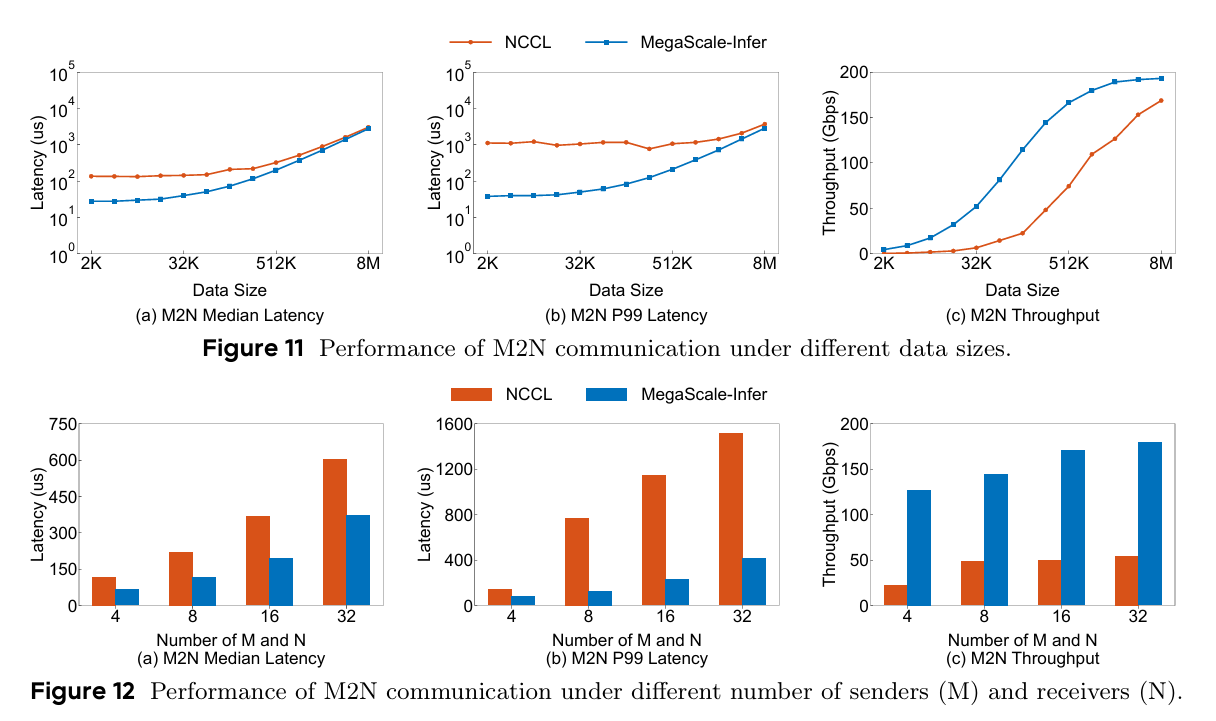
NCCL과 MegaScale-Infer의 M2N 통신을 비교 했을 때, 데이터 사이즈가 커지는 상황이 되면 NCCL과 성능이 거의 비슷하게 나오는 것으로 보인다. 반면 Expert의 수가 증가하는 상황에서는 MegaScale-Infer의 성능이 훨씬 잘 나오는 것으로 보인다.
결론 및 고찰
요즘은 DNN Training 필드에서 Heterogeneus 환경에 대한 관심도가 많이 떨어진 것으로 보였다. 아무래도 예전에 한 번 유망했던 트렌드였는데 한 번 사이클을 돌고 워크로드도 LLM으로 바뀌다보니 최근에는 예전 만큼 연구량이 나오지 않는 것으로 보인다. 그거 연구 하던 사람들이 다 어디로 갔나 했더니 MoE inference로 온 것만 같았다. 아무튼 간만에 Heterogeneus GPU 환경에서 연구를 진행 한 논문을 보니 반가웠다.
회사에서는 딱히 MoE에 대한 관심이 없어 보이는 것 같다. 아직까지 내가 아는 회사에서 나온 모델 중에 MoE로 공개한 곳은 카카오에서 만든 Kanana-MoE 밖에 없다. 아마 Exaone-MoE가 나온다면 회사에서도 관심을 가질 법 한데, 계획이 있는지는 모르겠다.
