오늘도 지난번에 이어서 MoE 관련 내용을 가져왔다. 이전에는 MoE의 배포에 관련한 내용을 기반으로 작성 된 논문이였다면, 오늘 가져온 FlashMoE는 FlashAttention처럼 MoE에서 사용 되는 커널과 관련 된 내용으로, 2025년도 NeurIPS에 붙은 논문이다.
MoE Communication Overhead
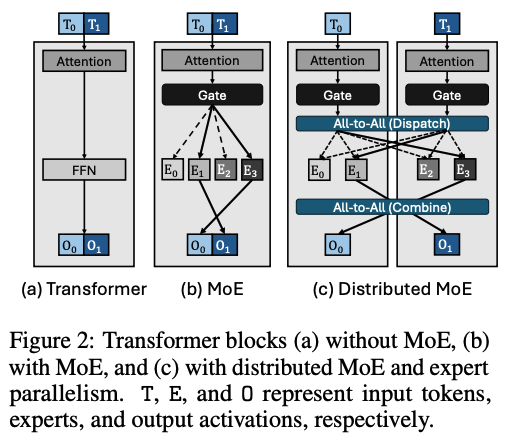
대부분 MoE에서 발생하는 오버헤드를 꼽으라고 한다면 통신과 관련 된 오버헤드를 가장 먼저 이야기 할 수 있을 것이다. MoE는 기존의 dense 모델을 나타내는 (a) 그림과는 달리 (b) 그림처럼 attention 연산 후에 gate routing을 거쳐서 선택 된 expert가 연산을 하는 구조이다. 하지만, dense 모델 대비, expert가 차지하는 파라미터의 수가 많기 때문에 보통 (c) 그림처럼 분산 형태로 MoE를 배치하는 편이다.
그림 (c)와 같이 배치 되는 경우, MoE는 2번의 통신이 필요하다. 토큰이 attention 연산 후, gate를 지나고 다면, routing 타겟이 된 expert 방향으로 연산 결과를 전송해야 한다. 이 때, dispatch all-to-all 통신을 한 번 수행하게 된다. expert 연산이 완료 되면, 순서가 섞인 토큰들을 sequence 내 원래 순서로 되돌린다. 이 때 다시 combine all-to-all 통신이 필요하다.
NCCL의 경우, all-reduce 통신은 최적화가 잘 되어 있는 편이지만, all-to-all은 이에 비하면 미진한 수준이고, 상대적으로 최적화가 까다롭다는 문제가 있다. GPU 하나가 지연을 일으키면 전체가 마비되는 현상도 빈번하기 때문에, 전체 실행 시간의 최대 68%까지 통신에 소비가 되는 경우도 있다고 한다.
MoE Kernel Launch Overhead

또다른 MoE의 오버헤드 중 하나는 빈번한 kernel lauch 문제가 있다. 이런 문제는 대개 통신 관련 문제를 해결하기 위한 파이프라이닝을 도입했을 때 나타난다. 위 표는 이전에 통신 오버헤드를 피하기 위해 도입한 기법들이 발생 시키는 GPU kernel operation의 수를 보여준다. 위와 같이 kernel 실행이 많아지면 다음과 같은 순서로 성능 저하 문제가 발생한다.
- GPU 사이의 kernel 시작 시점이 non-deterministic으로 달라지기 때문에 GPU straggler 문제가 심해진다.
- 불필요한 동기화 지점들이 발생하면서 GPU나 CPU를 기다리게 된다.
- kernel의 경계마다 반복적인 global memory 이동이 발생한다.
만약 dense 모델이라면 1번으로 발생하는 문제는 CUDA graph를 통해 부분적으로 완화가 가능하다. 하지만 MoE의 경우 동적으로 expert routing을 사용하기 때문에, 이는 호환 되는 방식이 아니다.
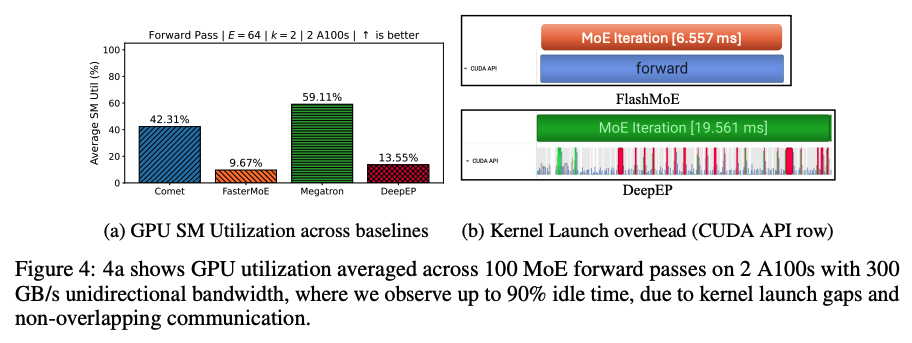
위 그림에서 (a)는 각 MoE 통신 kernel마다 GPU에서 사용하는 SM utilization을 나타낸 그래프이고, (b)는 DeepSeek에서 사용되었던 DeepEP의 Nsight Profiler를 이용하여 분석한 CUDA kernel의 발행 빈도를 나타낸 그림이다. 많이 사용되는 DeepEP의 GPU utilization이 13.55%에 그치는 것을 저자들은 확인 했다. 또한 DeepEP는 매우 많은 작은 CUDA API 호출을 보이며, 개별 연산자 사이에 잦은 정체가 발생하기 때문에 GPU idle time이 빈번하게 발생한다.
FlashMoE
앞서 보았듯, 기존 MoE kernel들은 중요한 경로에 존재하는 all-to-all 통신과 이를 방지하기 위해 설계 된 파이프라이닝으로 인한 작은 커널들의 빈번한 실행이 문제였다. FlashMoE는 이러한 문제점을 해결하기 위해서 기존 kernel을 융합시켜서 단 하나의 kernel을 실행하는 것으로 오버헤드를 피하기 위한 설계를 고안했다.
Actor-based Model

FlashMoE는 GPU 스레드 블록과 워프를 3가지의 actor 역할로 분리하여 구현되어 있다. 위 그림에 나오는 Processor, Subscriber, 그리고 Scheduler가 있다. 각 역할은 다음과 같다.
- Processor: GEMM 연산 및 다른 component별 연산과 tile communication을 수행한다. BLAS 연산을 위해서는 CUTLASS가 사용이 되었고, kernel 통신을 위해서는 NVSHMEM이 사용 되었다.
- Scheduler: 사용 가능한 스레드 블록에 계산 작업을 할당한다. 스케줄러는 multi-threading으로 구현이 되어 있기 때문에, 높은 스케줄링 throughput을 확보 할 수 있다. 또한 work-conserving 방식으로 설계 되어 GPU SM utilization을 지속적으로 높게 유지시킨다.
- Subscriber는 다른 GPU로부터 받은 tile 패킷을 task descriptor로 인코딩 시킨다.
GPU 상의 총 개 스레드 블록 중, 개는 processor 역할을 수행한다. 마지막 남은 하나의 블록은 내부에서 3개의 워프를 subscriber, 1개의 워프를 scheduler 역할로 각각 특화한다.

위 알고리즘은 FlashMoE kernel의 동작 방식을 나타낸다. input값인 와 는 각각 입력과 출력 토큰이 변환 된 행렬을 의미한다. 는 expert의 weight을 담고 있다. 와 는 각각 sequence 길이와 embedding dimension을 의미하고, 와 는 각각 local expert 수와 FFN의 중간 dimension을 의미한다.

위 그림은 FlashMoE에서 actor 사이의 상호작용이 어떻게 이루어지는가에 대한 그림이다. FlashMoE는 MoE에서 계산과 통신을 tile이라는 특정 크기로 정해진 tensor 분할 단위를 사용한다. 이에 따라 병렬 실행과 작업 사이에서 overlap이 가능해진다. 각 tile은 task discriptor를 이용하여 독립적인 작업 단위와 대응된다. subscriber는 다른 GPU로부터 받은 tile 패킷으로부터 task discriptor를 디코딩 한다. 이와 동시에 scheduler는 사용 가능한 작업에 대한 알림을 받고, 해당 작업을 processor에게 dispatch 시켜서 FFN 및 expert combine 연산을 수행 시킨다.
Tile 크기는 어떻게 결정되는가?
FlashMoE의 성능에 영향을 미칠 수 있는 요소는 tile의 크기가 될 것이다. 만약 너무 작은 크기로 설정하게 되면 GPU utilization이 낮이질 수 있고, 반대로 큰 크기를 사용하면 register에 포화 상태가 되어 오히려 성능을 저하시키는 local memory로의 register spill이 발생할 것이다.
저자들은 이에 대한 설정을 grid search로 탐색을 했고, 크기가 적절하다는 것을 발견했다. 이보다 tile의 width 값을 늘리게 되면 스레드 당 사용하는 register 양이 크게 증가하여 비용이 큰 spill이 발생할 수 있다. 반대로 tile의 height을 키우고 스레드 수를 조정하지 않으면, 스레드당 작업량이 증가하여 성능이 저하된다. 또는 블록 당 스레드 수를 128 스레드보다 더 늘리면 동시에 실행 가능한 블록 수가 줄어들기 때문에 SM 점유율이 감소하게 된다. 스레드의 블록 크기를 늘리는 것은 블록 내부에 동기화 오버헤드도 증가 시키기 때문에 성능 악화가 발생했다고 한다.
Task Abstraction
우선 Transformer 기반에서 널리 사용되는 FFN은 다음과 같이 계산이 된다.
여기서 과 는 학습 가능한 weight을 의미하고, 과 는 bias이다. 여기서 DeepSeek 같은 아키텍쳐에서 사용 되는 expert-combine 연산은 여러 expert의 출력을 affinity score에 기반하여 weighted-sum 방식으로 결합이 된다. 그래서 다음 수식과 같이 계산이 된다.
위 식에서 값은 입력 토큰의 인덱스를 의미하고, 는 토큰 에 대해 선택 된 번째 expert를 의미한다. 즉, 는 토큰 가 expert 와 얼마나 관련이 있는지를 나타내는 affinity score가 된다.
FlashMoE의 목표는 위 두 연산을 하나의 kernel로 결합시키는 것이다. 이를 위해서, subscriber, scheduler, processor 사이에 tile-level의 작업을 전달하기 위한 통일된 방식이 필요하다. FlashMoE는 작업을 discriptor로 지시를 하는데, 다음과 같이 튜플로 표현이 가능하다.
은 device ID나 tile 인덱스 같은 메타데이터의 집합을 의미한다. 행렬의 곱연산이나 각 행렬의 원소끼리만 곱하는 행렬 곱셈인 아마다르 곱연산을 의미한다. 그리고 는 ReLU 같은 activation function을 의미한다. 이에 따라 입력 텐서 에 대해서 작업 가 실행 되어 출력 텐서 를 만들어내는 과정을 다음과 같이 표기하였다.
FlashMoE는 위와 같은 식을 CUDA 레벨에서 구현을 하였고, processor가 런타임에서 아래와 같은 알고리즘으로 이를 수행하게 된다.

작업 에 대한 kernel fusion은 discrete 연산자인 의 결과를 저장하는 레지스터에 대해 activation function 와 그 뒤에 덧셈 연산을 하는 것을 의마하게 된다. 이에 따라서 FFN 연산과 expert 연산을 FlashMoE는 다음과 같이 수행 할 수 있다.
FFN 연산
Expert 연산
GPU간 통신을 위한 Symmetric Tensor Layout
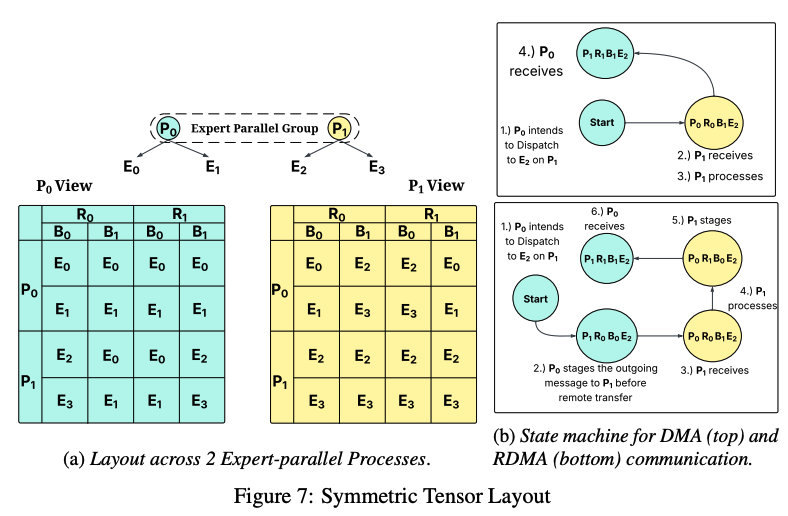
단일 GPU를 사용하는 경우, FlashMoE의 actor들은 GPU 메모리의 sub-system을 이용하여 통신을 한다. scheduler와 subscriber의 경우, actor는 shared memory를 이용하여 빠르게 데이터 교환을 한다. 그 외 actor들은 global memory를 사용하여 통신을 하게 된다.
하지만 MoE의 경우, 여러 GPU에 걸쳐서 expert parallelism과 data parallelism으로 배포가 되는 것이 일반적이기 때문에, device-initiated commnication이라는 것을 사용하며, 단방향의 PGAS (Partitioned Global Address Space) 모델을 사용한다. 하지만 PGAS의 경우, 비용이 큰 동기화 없이 확장이 가능하고 올바르게 단방향으로 메모리 접근을 구현하는 것이 큰 난제로 알려져 있다.
FlashMoE는 이를 해결하기 위해서 non-blocking 메모리 접근을 지원하는 symmetric tensor layout 을 활용하여 해결하였다. 은 다음과 같이 정의가 된다.
위 식에서 각 파라미터는 다음을 의미한다.
- : expert parallel의 world size
- : communication round로 MoE은 expert dispatch와 combine 2 round로 구성 되어 있다.
- : staging buffer의 수
- : local expert의 수
- : up-scale 된 expert capacity
- : 토큰의 embedding dimension
FlashMoE는 non-blocking 통신을 위해서 위 파라미터를 기반으로 temporal buffering을 수행한다. MoE 모델의 경우, 토큰이 가지는 행렬에 대해서 4배의 메모리를 over-provisioning을 수행해야 한다. 이는 MoE가 2번의 commnication round (dispatch와 combine)를 가지고 있고, 각 commnication round마다 송신과 수신이 이루어지기 때문이다. 이에 따라 (b) 그림과 같이 symmetric tensor layout 내에 존재하는 셀들이 DMA 및 RDMA 연산을 수행하게 된다.
write-write conflict
symmetric tensor layout의 특징 중 하나는 하나의 메모리 공간에 두 개의 쓰기 작업이 충돌하지 않는다는 장점이다. 만약 sequence 길이 에 embedding dimesion 를 가진 원본 토큰 버퍼 가 있다고 가정하자. sequence dimension인 를 expert capacity 에 local expert 슬롯 , expert world size가 이렇게 3개의 하위 dimension을 이용하여 재구성이 가능하다.
여기서 이다. 만약 위 그림 (a)와 같이 균일한 expert 설정에서는, 가 되며, 는 전체 expert의 수와 같다. 이 경우, 토큰 버퍼의 크기는 가 된다. FlashMoE 저자들은 여기에 더하여 commnication round와 staging buffer를 추가하였다. 각 commnication round는 송신 토큰용과 수신 토큰용의 두 개 고정된 staging 슬롯을 갖는다. 이에 따라 로 인덱싱 되는 슬롯은 형태의 텐서가 되며, layout 의 전체 크기는 원본 토큰 버퍼가 가지는 크기의 최소 4배가 된다. 이 오버헤드가 생각보다 크게 느껴질 수 있지만, 대부분의 MoE 모델에서는 2% 정도에 해당 되는 크기라고 한다.
In-place padding
MoE 모델에서 토큰을 dispatch 하는 과정에서는 토큰의 분포가 동적이고 불균형하게 이루어진다. 그래서 GPU는 사전에 정의 된 expert의 용량보다 적은 수의 토큰만을 수신하는 경우가 일반적이다. DeepSpeed MoE 같은 MoE 전용 프레임워크들은 계산 전에 이 버퍼들을 null 토큰으로 padding을 시키는데, 이는 통신에서 사용 되는 payload를 불필요하게 증가시키기 때문에 성능 저하가 발생한다.
FlashMoE의 경우에는 in-place padding을 사용한다. 이는 padding 자체를 로컬에 존재하는 symmetric tensor 버퍼 내부에서 수행을 시키는 방식이다. 위 그림의 (a)에서 보이는 것처럼, 각 셀 는 expert 용량 에 맞추어서 크기가 결정 된다. FlashMoE는 이 expert 용량을 로 나누어 떨어지도록 추가 alignment를 수행하여 토큰을 사용하는 processor 스레드들이 메모리 읽기를 안전하게 실행 할 수 있도록 지원한다. 이는 의 메모리 사용량을 약간 증가시키는 오버헤드가 존재하는데, 다음과 같이 표현이 된다.
실험 결과
실험 환경
FlashMoE 실험을 위해서 사용된 베이스라인 프레임워크는 Coment, FasterMoE, Megatron-CUTLASS, 그리고 Megatron-TE가 사용 되었다. 이에 대해서 MoE forward에 걸리는 시간과 GPU utilization, overlapping 효율, throuhgpuht, 그리고 expert의 확장성에 대해서 측정을 하였다고 한다. GPU는 H100 8대가 사용이 되었다.
Forward latency

FlashMoE는 forward latency 측면에서 토큰 길이 유무에 상관 없이 제일 좋은 성능을 보여주었다. 특이 sequence 길이가 길어질수록 다른 프레임워크에 비해 성능 개선 폭이 크게 증가하였다.
GPU utilization
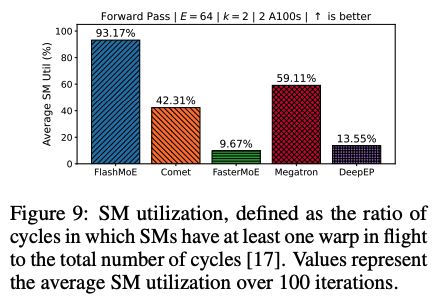
GPU utilization 또한 FlashMoE가 가장 높은 수치를 보여주었다. 이러한 성능 향상은 FlashMoE가 완전하게 하나로 MoE communication kernel과 연산 kernel을 fusion 했기 때문이다. kernel launch로 인해 발생하는 idle time을 제거하고, 내부에서 작업 스케줄링이 가능하기 때문에, FlashMoE는 실행 전반에 걸쳐서 GPU SM들이 지속적으로 유의미한 작업을 수행 할 수 있도록 보장한다.
Throughput
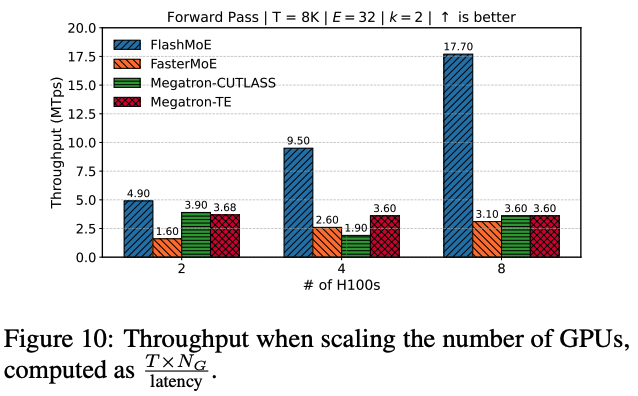
위 그래프는 GPU 개수를 늘려가면서 각 베이스라인과 FlashMoE의 throughput을 측정한 결과이다. FlashMoE는 모든 구간에서 FP32를 사용하고, 다른 베이스라인은 FP16을 사용한다. 그럼에도 불구하고, FlashMoE의 throughput이 제일 높은 성느을 달성했다. 이는 FlashMoE의 설계가 낮은 precision에 의존하는 것이 아니라, 하드웨어의 활용도를 극대화 시키고, host 기반으로 오버헤드를 제거했기 때문임을 시사한다.
Overlap efficiency

FlashMoE의 overlap 효율의 경우에는 GPU의 수를 늘려가면서 weak scaling으로 측정이 되었다. Megatron 계열의 경우에는 성능 저하가 크게 발생했다. FlashMoE는 forward pass에 소요되는 시간이 GPU 수가 늘어나도 거의 동일하게 유지가 된다. 이러한 결과는 결국 FlashMoE가 actor 기반 설계와 비동기 데이터 이동이 거의 이상적으로 overlap이 됨을 보여준다.
Expert scalability

마지막 실험 결과로는 sequence 길이를 16K로 고정한 상태에서 expert의 수를 증가시킬 때 FlashMoE의 scalability를 보여준다. FlashMoE는 expert의 수가 증가해도 거의 일관적인 latency를 보여준다. 이러한 결과는 FlashMoE가 사용하는 워크로드가 sparse한 구성임에도 scalability가 뛰어남을 보여준다.
결론 및 고찰
FlashMoE는 기존에 있었던 FlashAttention처럼, 다수의 kernel들을 하나로 funsion 시켜 이전에 발생했던 MoE의 통신 문제와 파이프라이닝으로 인한 비효율적인 kernel launch를 개선한 논문이였다. 논문을 보면서 조금 아쉬웠던 점은, motivation에서 언급했던 DeepEP와 비교한 결과가 없었던 것이였다. 사내에서 사용되는 MoE의 대부분이 vLLM과 DeepEP로 이루어져 있는데, DeepEP와는 얼마나 성능 차이가 나는지 궁금했었다. 그리고 FP16의 경우, 논문의 limitation 부분에서도 나와있었지만, Hopper의 경우 FP16 연산에 강점이 있기 때문에, FP16에서도 최적화가 이루어졌다면 좀 더 좋은 성능을 달성하지 않았을까 생각이 들기도 했다.
