최근 팀에서 냈던 논문이 끝나면서 팀원들이 다음 주제를 찾고 있다. (나는 거의 끝무렵에 들어와서 대충 간 보는 상태) 이전에는 주로 KV cache에 대한 내용을 주제로 연구를 했었는데, 좀 더 연구를 다양화 시켜보자는 취지에서 나도 가급적이면 speculative decoding에 추가로 여러 워크로드를 보고 있었다. 그 중에서도 AI agent 정도에 관련된 내용을 보고 있었는데, 예전 경험에 의하면 reasoning 모델이 AI agent 워크로드에서 주로 계획을 세우는데에 용이하게 쓴 경험이 있었다. 그래서 speculative decoding을 reasoning 모델을 타겟으로 한 논문이 NeurIPS'25에 있어서 가져왔다.
LLM Reasoning
LLM reasoning은 ChatGPT나 Gemini, 또는 DeepSeek와 같은 AI 어플리케이션에 대해서 종종 사용자가 주어진 문제를 해결하기 위해, LLM이 연쇄적인 추론을 이용할 때 관찰 할 수 있다. 보통 재작년, 작년에 유행하였던 CoT(Chain-of-Thought)처럼 최종 답을 도출하기 위해서 중간 추론 단계들을 연속적으로 생성하고, 문제를 점진적으로 해결해나가는 방식이다. 그렇기 때문에 각 추론 단계를 의미하는 가 있다고 가정을 한다면, 는 일반적으로 이전 단계를 의미하는 에 조건부로 의존하게 된다. 저자들은 이를 LLM의 autoregressive decoding과 유사하지만 한단계 더 높은 개념적인 단위를 가진다고 보았다.
Lookahead Reasoning
본질적으로 reasoning inference는 토큰보다는 큰 여러개의 의미 단위로 나눌 수 있다. 나눠진 단계의 특이한 점은, 정확한 정답을 찾기 위해서 모든 token seqeunce가 strict하게 동일 할 필요가 없고 의미적으로만 올바르면 된다는 점이다. 그렇기 때문에 몇 개의 토큰을 draft가 추측하는 것이 아니라 몇 개의 추론 단계를 추측하고 검증하는 방식을 사용 할 수 있다.
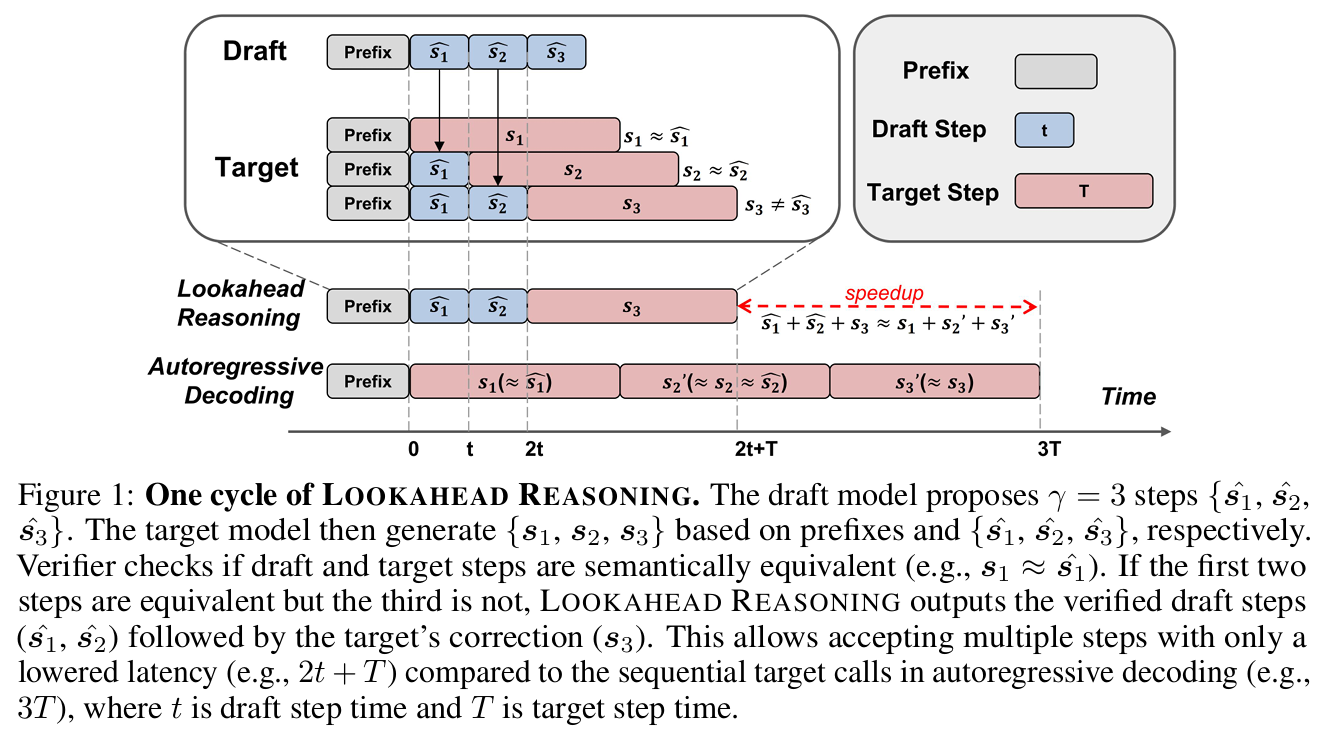
위 그림은 reasoning 모델에 대한 인사이트를 이용하여 CoT의 추론 단계를 draft로 추측하는 reasoning 모델 전용 speculative decoding인 lookahead reasoning 방식을 나타내는 그림이다. 동작 순서는 다음과 같다.
1. Draft step generation
우선 draft 모델에 입력 토큰 가 주어지면, 여러개의 연속 된 추론 을 생성한다. 각 추론 단계를 구분하기 위해서 특정한 구분 토큰을 사용하는데, 보통 CoT에서 많이 보이는 '\n\n' 토큰을 사용한다고 되어 있다.
2. Parallel target step generation
후보가 되는 추론 단계들이 개 만큼 생성이 완료 되면, target 모델은 이에 대응 되는 실제 추론 단계인 를 병렬로 생성한다.
3. Verification and output construction
그 다음, accept이 될만한 draft 추론들 중 가장 긴 prefix를 찾는다. 각 draft 단계 와 target 단계 사이의 검증은 특정한 verifier를 이용하여 수행 되는데, 이에 대한 기준은 가 $를 의미적으로 대체 가능한 추론인가를 이용하여 판단한다.
Verifier Selection
Lookahead reasoning에서 중요한 요소 중 하나는 verifier를 선택하는 것이다. 이상적인 verifier는 의미 기반으로 정확도 손실을 완벽하게 방지 할 수 있어야 하지만, 실제 구현 상에서는 2가지 trade-off가 발생한다.
- Verifier의 판단 정확도를 끌어올리기 위해서는 좀 더 파라미터가 큰 모델을 사용해야 하는데, 이에 따라서 추가적인 계산 비용이 들어간다.
- 검증하는 기준에 대한 threshold 기준이 높을 수록 잘못된 추론 단계를 허용할 확률은 낮아지지만, 동시에 speculative acceptance가 낮아지면서 속도 향상이 어려워진다.
이에 대해서 lookahead reasoning은 LLM-as-a-Judge, embedding-based verifier, target model scoring, 이렇게 3가지를 고려하였고, 이를 실험으로 평가하였다.
Multi-branch Drafting
Lookahead reasoning 역시 speculative decoding에서 방식을 착안했기 때문에 acceptance ratio에 따라서 성능 향상이 이루어진다. 그렇기 때문에 accept이 되는 reasoning 단계 수를 늘리는 것이 관건이기 때문에, EAGLE, SpecInfer 같은 트리 기반의 draft 방식도 적용을 했다. 방식은 다음과 같다.
- draft 모델은 각 위치 에서 단일 후보가 아니라 개의 후보를 생성한다.
- 각 후보 단계는 다음 후보 단계인 에서 다시 개의 하위 후보를 생성한다.
- 이를 최대 단계까지 반복하고 나면 후보 reasoning 단계 수는 개가 완성이 된다.
- target 모델은 각 위치 에 대해 단일 단계만 생성한다.
verifier는 위치에 대해서 개의 draft 후보 중에 하나라도 target 단계와 의미적으로 일치하면 해당 branch를 accept하고 나머지는 버린다. 이러한 트리 방식은 speculative acceptance 확률을 증가 시킬 수 있지만 draft가 생성에 필요한 계산량이 증가하는 문제가 있다.
Lookahead Reasoning의 속도 향상 분석
lookahead reasoning으로 인해 이론적으로 얼마나 reasoning 모델이 속도 향상을 얻을 수 있는지 분석하기 위해서, 우선 3가지 가정을 세웠다.
- 검증에 필요한 비용은 무시할 수 있을 정도로 작다.
- 한 단계를 생성하는데 필요한 비용은 일정하다.
- 각 단계에서 draft 모델은 단일 step만 생성한다. (즉, 트리 구조를 사용하지 않는다.)
Sync 버전 분석
이에 따라서 lookahead reasoning의 동기화 버전인지 비동기화 버전인지에 따라서 속도 향상 수식이 달라지게 된다. 동기화 버전의 경우, draft가 먼저 생성을 하고 target 모델은 draft의 추론 단계 생성이 모두 끝날 때까지 기다렸다가 한꺼번에 검증을 하는 방식이다. 그래서 속도 향상 수식이 다음과 같이 유도가 된다.
위 수식에서 은 draft가 만든 단계가 accept이 될 확률을 의미한다. 은 병렬로 생성이 되는 target 단계의 개수를 의미하고, 이 값은 연속적으로 생성 되는 draft 단계의 최대 개수와 동일한다. 의 경우, draft 모델이 단계 하나를 생성 할 때 소요되는 비용을 의미한다.
Async 버전 분석
반면 비동기 버전은 draft 모델이 step을 계속 생성 할 때, target 모델은 생성되는 매 step마다 그때그때 검증하는 방식이다. 그렇기 때문에 draft의 생성 속도의 상대적인 관계에 따라 2가지 경우가 존재 한다.
우선 어떤 번째 단계에서 연속적으로 accept 되는 draft 단계 수를 로 표기한다. 그렇게 되면 기대 할 수 있는 단계 수는 다음과 같다.
만약 로, draft가 개의 draft 단계를 생성하는 것이 target 단계 하나를 생성하는 것보다 느린 경우에는 속도 향상이 다음으로 수렴하게 된다.
반대로 경우로, draft가 충분히 빨라서 개의 draft 단계를 어떤 시간 안에 생성 할 수 있다면, 최대 깊이값인 이 speculative 단계 수를 제한하는 요인이 된다. 이에 따라 수식은 다음과 같이 변한다.
수식에 대한 자세한 유도는 논문의 Appendix에 등장한다. 하지만 내용이 좀 복잡하기 때문에, 결론만 말하자면 sync 방식과 async 방식 모두 당연히 draft가 생성한 추론 단계가 accept이 많이 될수록 속도 향상이 이루어진다. 하지만 async 방식의 경우, draft의 속도가 느린 경우에 ㅅtarget이 생성하는 값의 제약을 받지 않는다.
Optimal Speculative Strategy under Parallel Budget
Lookahead reasoning은 step 단위의 speculative decoding인데, 이를 기존에 사용하던 토큰 단위의 speculative decoding과 동시에 적용 할 수 있다. 하지만 적용하는 것과, 실제로 적용을 했을 때 성능 이득이 존재 하는지에 대한 여부는 별개다.
만약 draft 모델이 추가로 추론하는 토큰의 수를 , 그리고 draft 모델과 target 모델의 실행 시간 비율을 라고 한다면, 토큰 레벨에서 발생하는 speculative decoding의 속도 향상률은 acceptance rate 에 따라 다음과 같이 계산이 된다.
이에 따라서 step 단위와 token 단위를 동시에 적용 한다고 가정 했을 때, 속도 향상은 서로 곱해져서 전체 속도 향상을 만든다.
하지만 실제 시스템에서는 GPU 메모리와 연산 유닛은 무한으로 퍼다 쓸 수 있는 자원이 아니다. 그래서 만약 어떤 parallel budget 값이 주어진다고 했을 때를 가정해야 하고, 이에 따라 각 speculative decoding에 필요한 병렬성의 곱이 값 보다 작아야 한다. 그래서 다음과 같이 수식이 변한다.
위 식에서 나타내는 각 speculative decoding의 병렬성 차원은 다음과 같이 사용 된다.
만약 이라면, 토큰만 speculative decoding이 적용이 되는 것이고, 반대로 이라면, reasoning step만 speculative decoding이 적용 되는 것이다.
이에 따라서 다음과 같은 조건이라면 async 방식의 lookahead reasoning을 적용 했을 때, 두 레벨에서 동시에 speculative decoding을 적용하는 것이 최적이 된다.
- acceptance rate가 인 경우. 이 경우는 보통의 speculative decoding 기법에서 일반적인 값이다.
- draft 모델의 효율이 각각 일 때. 이는 draft가 target보다 3배에서 5배까지 빠른 경우인데, 이는 충분히 현실적이다.
- parallel budget 인 경우인데, 보통 하나의 GPU에서 draft와 target을 같이 올리고, 노드 하나에 GPU가 8대를 사용하기 때문에, 이것 역시 하나의 노드에서 충분한 크기이다.
따라서 위와 같이 일반적인 조건에서는 lookahead reasoning이 토큰 레벨의 일반적인 speculative decoding과 동시에 사용하는 것이 최적이라고 설명한다.
실험 결과
실험에서는 주로 lookahead reasoning의 속도 향상과 정확도가 기존 target 모델과 동일하게 유지되는지 평가한다. 이를 위해서 다음 reasoning 모델과 draft 조합 2개를 사용했다.
- DeepSeek-R1-Distll 1.5B + 32B
- Qwen-3 1.7B + 32B
그리고 LLM-as-a-Judge를 위해서 Qwen-2.5-7B instruct 모델이 추가로 사용 되었다. 모델 서빙을 위한 GPU로는 H100이 사용이 되었다. 32B 모델의 경우 2TP 설정으로 2대의 H100이 사용 되었고, 나머지는 1대의 H100에 올라갔다.
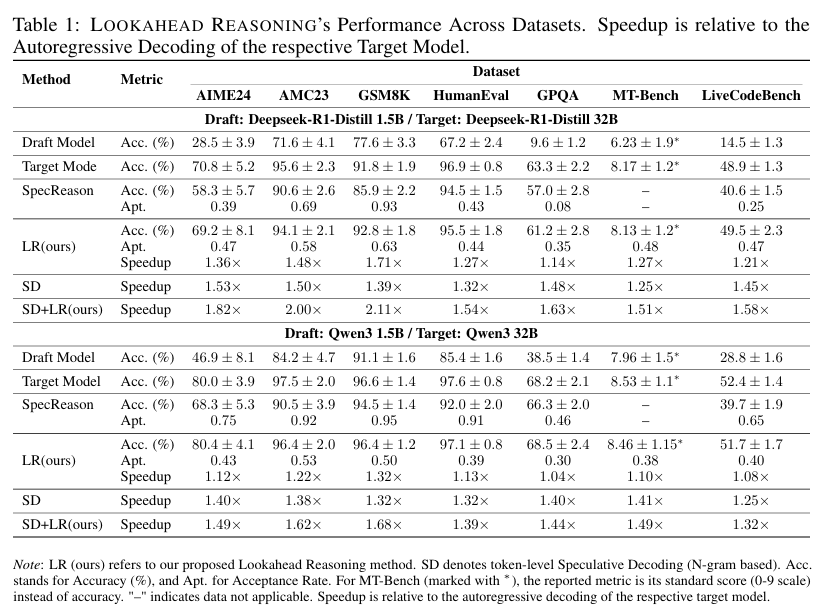
위 표는 lookahead reasoning의 속도 향상과 정확도 보존 측면에서 보여준다. 베이스라인으로 사용 된 SpecReason의 경우, 대부분의 데이터셋에서 정확도가 떨어졌지만, lookahead reasoning의 경우에는 정확도 하락이 거의 미미하게 발생했다. 또한 토큰 레벨에서 speculative decoding을 조합하여 사용한 경우, 더 큰 폭으로 속도 향상이 이루어졌다.

위 그래프는 단순히 lookahead reasoning만 사용하거나, 기존의 토큰 레벨에서의 speculative decoding만 사용한 경우와 비교하여 양쪽 둘 다 사용했을 때 발생한 성능 향상에 대한 그래프이다.
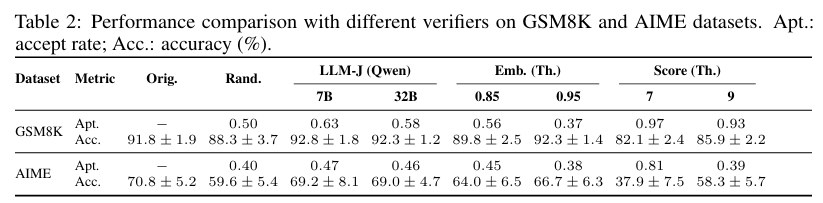
위 표는 각 데이터에서 verifier 전략에 따라 미치는 영향을 분석한 표이다. 사용 된 verifier 전략은 다음 4가지가 있었다.
- draft에서 랜덤하게 accept
- Qwen-2.5 instruct를 이용한 LLM-as-a-Judge
- all-mpnet-base-v2 모델을 이용한 embedding 기반 검증
- target 모델이 0~9 사이의 점수를 부여하는 scoring 방식
이 중 LLM-as-a-Judge의 경우, 정확도가 기존에 비해서 미미하게 하락했지만 거의 영향이 없는 수준이였다. 만면 랜덤 accept과 scoring 방식의 경우 전체적으로 성능이 하락했다. embedding 방식의 경우, accept 되는 유사도 기준을 0.95까지 올린 경우, 정확도 유지가 이루어졌다. 하지만 이 경우, acceptance rate가 감소하기 때문에 이는 trade-off로 작동한다.
결과 및 고찰
정리하자면, lookahead reasoning은 기존의 speculative decoding에서 착안하여 토큰 대신 reasoning step을 추측하는 방식으로 reasoning 모델을 타겟으로 가속하면서 정확도 손실을 최대한 억제시키는 논문이였다. 하지만 이 논문을 읽으면서 들었던 생각은, Qwen의 경우 LLM-as-as-Judge를 사용 할 때 동일한 family model을 사용하기 때문에 bias가 발생해서 상대적으로 후한 acceptance를 보였을 수 있다는 생각이 들었다. 거기다가 verifier 전략마다 발생하는 trade-off가 다르기 때문에 적절한 verifier를 선택하는 것이 해결해야 할 과제라는 생각이 들었다.
