Deep Learning
1.[NeurlPS'17] Attention Is All You Need
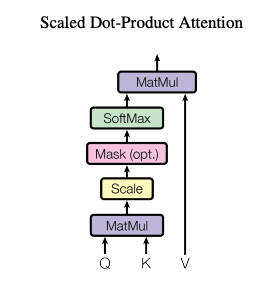
LLM에 대한 공부를 하면서, 언젠가 한 번 Transformer에 대해서 제대로 리뷰를 해야겠다고 생각했었다. ML System 필드로 현업에서 일하다 보면, 가끔 모델에 대한 이해도가 높아야 하는 순간이 있었다. 그 때마다 수박 겉핧기로 들은 내용으로 대처하다 보면
2.[ICML'23] Fast Inference from Transformers via Speculative Decoding

오늘 소개 할 논문은 LLM의 inference latency를 크게 개선 할 수 있는 Speculative Decoding이다.
3.[NeurIPS'25] Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Thinking
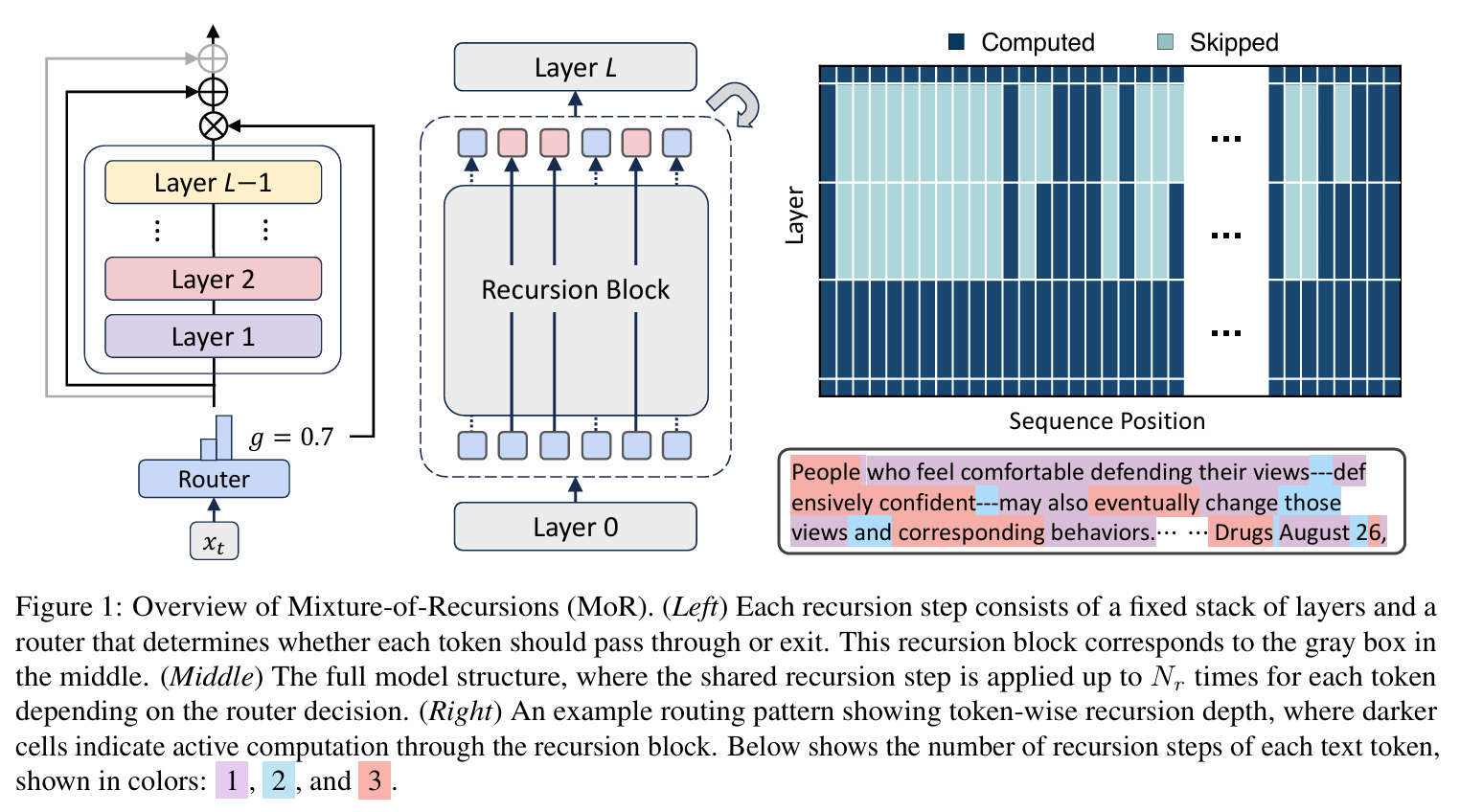
예전에 다니던 연구실 단톡방에서 그 당시 내 사수였던 형이 논문 하나를 올렸다. 그 논문이 지난 달에 구글에서 발표(근데 1저자는 카이스트 다니는 한국인 분들이다.)한 새로운 LLM 아키텍쳐에 관련 된 내용인데, 이름이 Mixture-of-Recursion이라는 구조를
4.Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
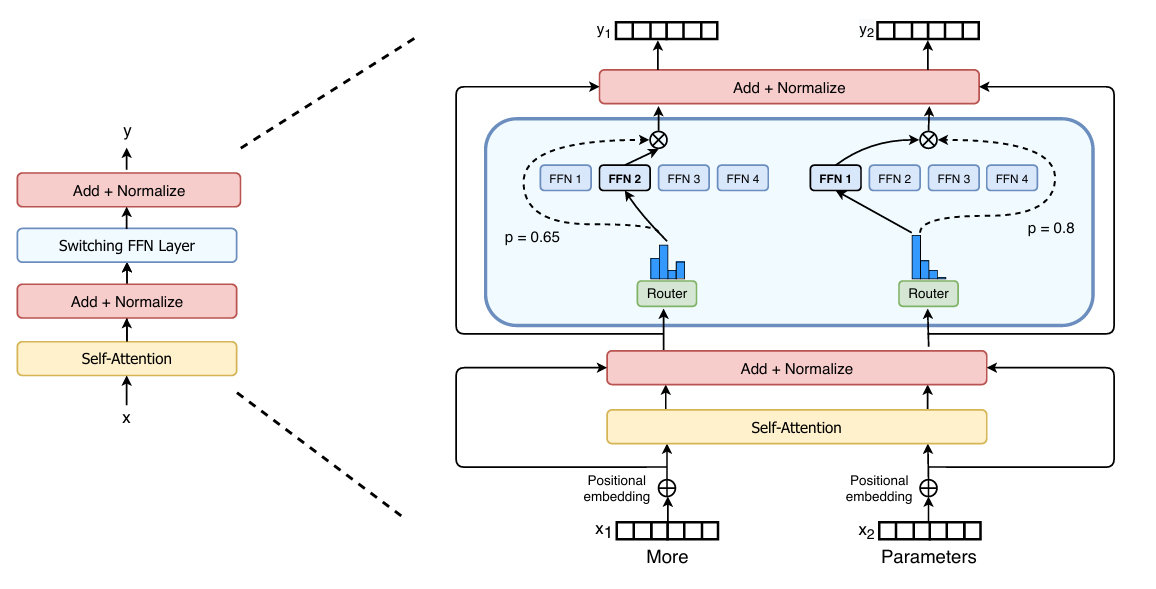
오늘 리뷰할 논문은 Switch Transformer로 MoE와 관련된 논문이다. Mixtral과 DeepSeek의 등장으로 인해 MoE 구조에 대한 연구가 ML System 분야에서도 많이 이루어지게 되었는데, 오늘은 우선 그 논문들을 이해하기 전에 MoE에 대한 지
5.Qwen 3 Technical Report
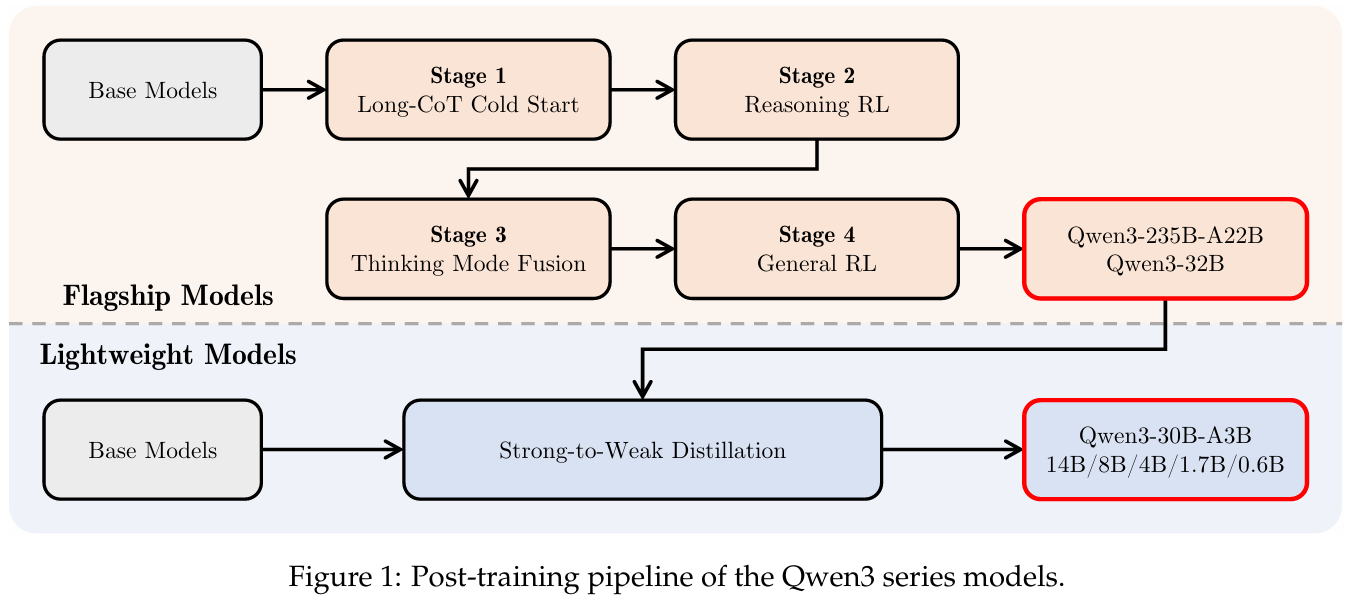
최근에 사내에서 Function call이랑 Think 모드를 추가한 sLLM을 따로 만들어서 나한테 serving 요청을 한 적이 있었다. 내가 따로 호기심에 무슨 모델을 기반으로 만든거냐고 물어보니까 Qwen 3를 이용해서 만들었다고 전달 받았었다. 그래서 예전에
6.[ICLR'25] MagicDec: Breaking the Latency-Throughput Tradeoff for Long Context Generation with Speculative Decoding
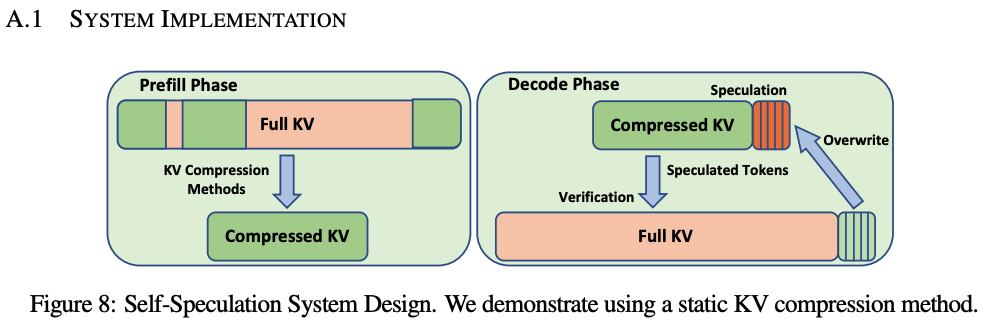
예전에 speculative decoding에 대한 글을 쓴 적이 있다. 아마 7월 쯤이였나? 그 때 조사하면서 알게 된 speculative decoding의 단점 중 하나가 batch size가 클 수록 효과가 떨어진다는 것이였다. 그러다가 이전 회사를 퇴사하고 지
7.[ICML'24] MEDUSA: Simple LLM inference acceleration framework with multiple decoding heads
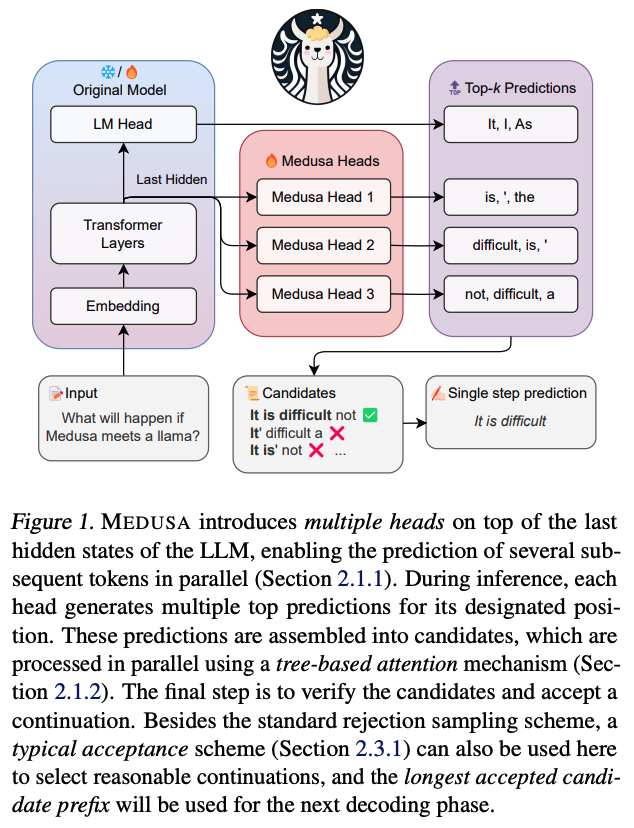
요즘 회사에서 Speculative decoding 관련 업무를 맡게 되면서 원래 자주 읽던 ML system 논문보다 fine-tuning 관련한 논문을 좀 더 많이 보게 되는 것 같다. 특히 speculative decoding의 경우, 조건에 따라 디코딩 단계에서
8.[ICML'24] EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
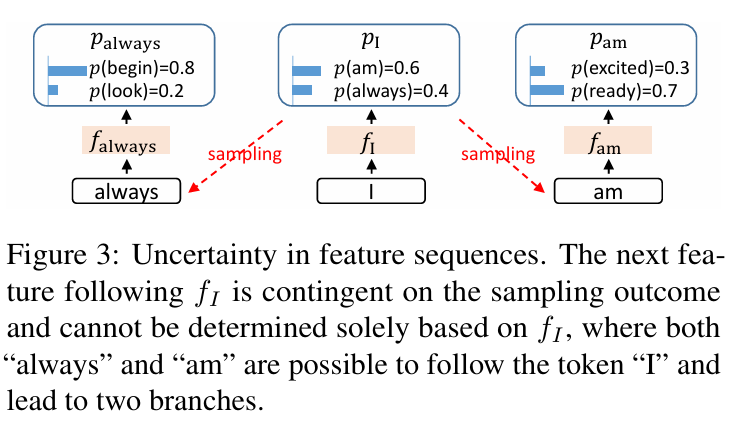
요즘 회사에서 speculative decoding 연구를 하면서 Eagle을 기반으로 논문을 작성하는걸 보았다. 같은 팀 박사분께 Eagle을 기반으로 만드는 이유가 뭔가 하고 여쭤보니, Eagle이 seculative decoding 관련 시리즈 중에 아직까지 제일
9.[NeurlPS'25] MoESD: Unveil Speculative Decoding's Potential for Accelerating Sparse MoE

사내에서 speculative decoding을 연구하면서, 문득 생각보다 MoE를 타겟으로 하는 논문을 본적이 없는 것 같았다. 그나마 최근에 봤던 Eagle 논문에서 Mixtral을 이용했었는데, 성능 자체는 1.5배 더 좋아졌다고 하지만 expert의 활성화 문제
10.Jakiro: Boosting Speculative Decoding with Decoupled Multi-Head via MoE
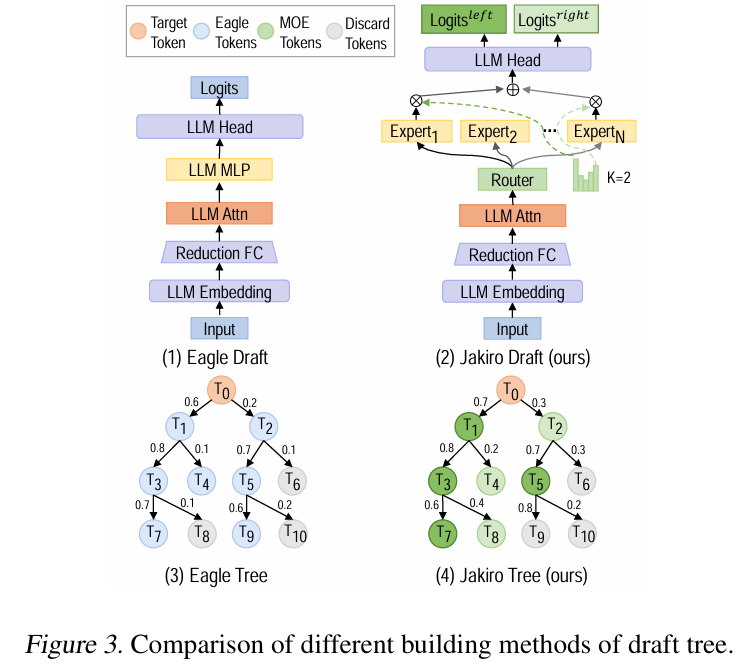
요즘 계속 speculative decoding을 MoE 모델에 적용 시킬 아이디어를 찾아보면서, draft 모델을 구하는데 꽤 고생을 좀 했었다. 비교적 신규 모델인 Qwen3 235B나, Phi-4 MoE의 경우, draft 모델이 생각보다 MoE의 분포를 따라오지
11.POSS:Position Specialist Generates Better Draft for Speculative Decoding
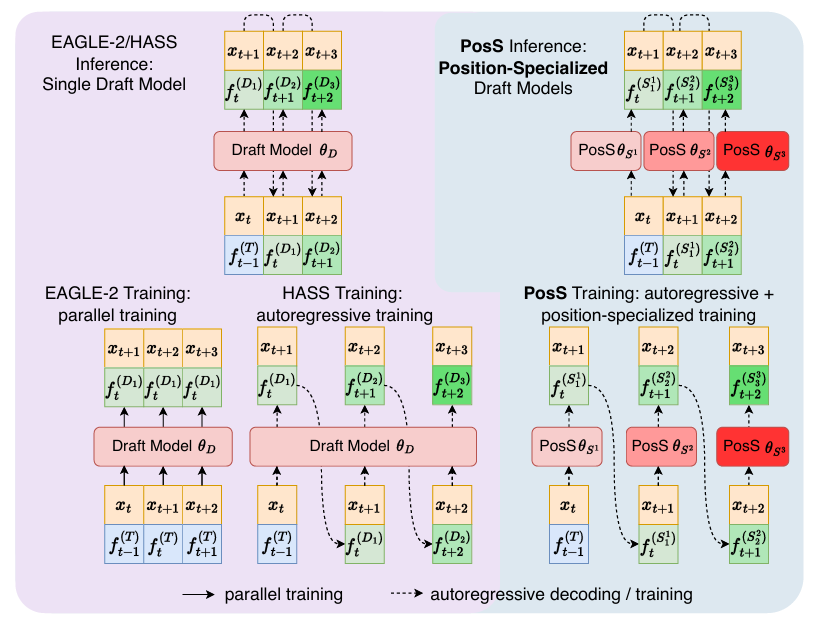
오늘 리뷰할 논문은 POSS라는 논문이다. 이 논문은 사내에서 speculative decoding 스터디를 할 때 소개 받은 것인데, 내 뒷자리에 앉아 있는 분이 이 논문에서 많은 영감을 받은 것 같았다. 그 분이랑 아이디어 얘기를 하면서 이 논문을 한 번 읽어 봐야
12.[NeurIPS'25] GRIFFIN: Effective Token Alignment for Faster Speculative Decoding
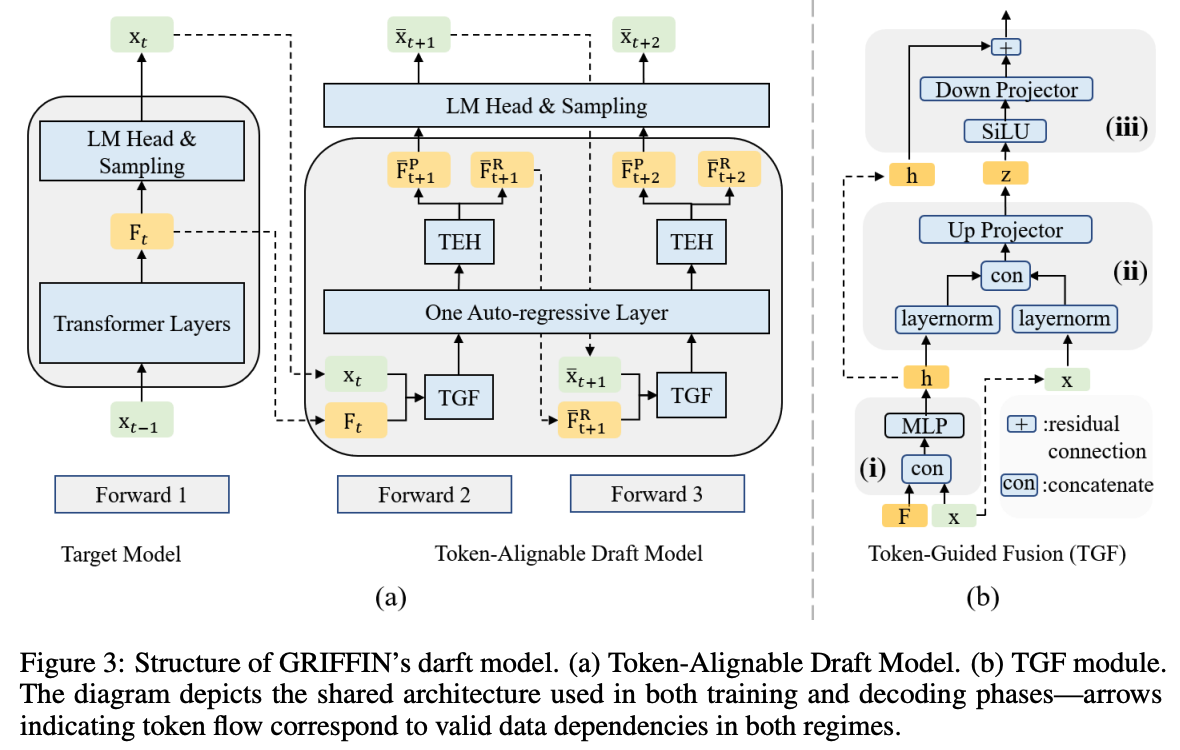
이번에 리뷰 할 논문은 Griffin이라는 논문이다. 예전에 아카이브를 보다가 지나친 기억이 있는데, 이게 올해 NeuIPS 학회에 붙을거라고는 생각하지 못했었다. Speculative decoding의 token alignment 테크닉에 관련 된 논문으로 기억한다.
13.[NeurIPS'25] Scaling Speculative Decoding with Lookahead Reasoning
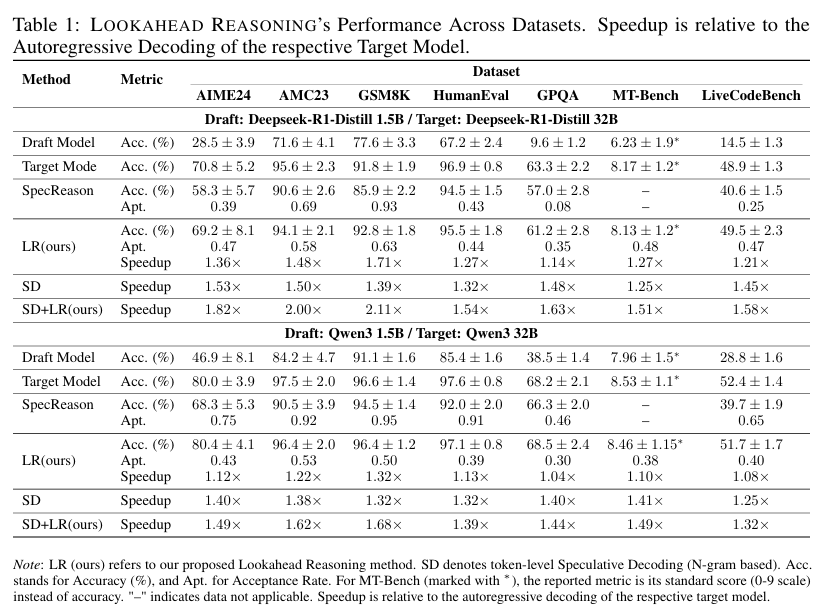
최근 팀에서 냈던 논문이 끝나면서 팀원들이 다음 주제를 찾고 있다. (나는 거의 끝무렵에 들어와서 대충 간 보는 상태) 이전에는 주로 KV cache에 대한 내용을 주제로 연구를 했었는데, 좀 더 연구를 다양화 시켜보자는 취지에서 나도 가급적이면 speculative
14.[NeurIPS'25] FlashMoE: Fast Distributed MoE in a Single Kernel

오늘도 지난번에 이어서 MoE 관련 내용을 가져왔다. 이전에는 MoE의 배포에 관련한 내용을 기반으로 작성 된 논문이였다면, 오늘 가져온 FlashMoE는 FlashAttention처럼 MoE에서 사용 되는 커널과 관련 된 내용으로, 2025년도 NeurIPS에 붙은