[NeurIPS'25] GRIFFIN: Effective Token Alignment for Faster Speculative Decoding
Deep Learning
이번에 리뷰 할 논문은 Griffin이라는 논문이다. 예전에 아카이브를 보다가 지나친 기억이 있는데, 이게 올해 NeuIPS 학회에 붙을거라고는 생각하지 못했었다. Speculative decoding의 token alignment 테크닉에 관련 된 논문으로 기억한다.
Token Misalignment 문제
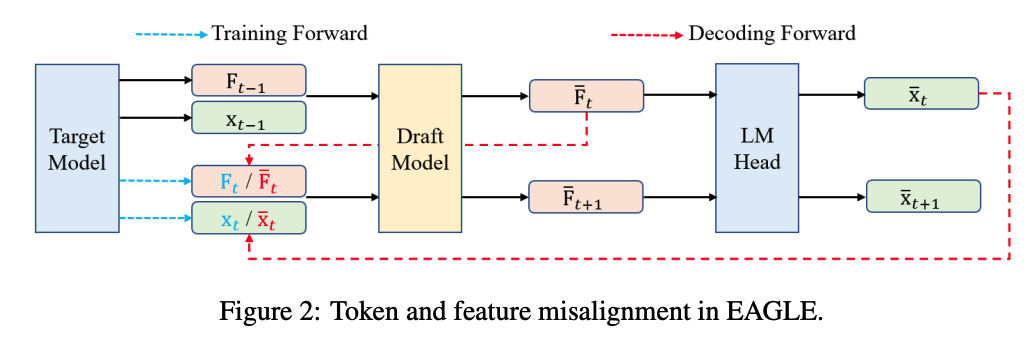
이전 연구인 EAGLE은 draft 모델이 (정확히는 EAGLE head) 토큰을 직접 예측하는 대신, target 모델의 최종 레이어에서 발생하는 hidden state feature를 근사시키는 중간 feature를 생성하는 방식이다.
위 그림은, 어떤 시점 에서 는 번째 ground-truth 토큰이고, 는 draft 토큰이라고 할 때,target 모델의 hidden state 와 draft 모델이 예측한 hidden state인 를 나타낸다. EAGLE은 와 를 draft에서 사용하는 방식으로 다음 시점의 토큰과 hidden state인 , 을 예측한다. 하지만 문제는 decoding 과정에서 draft 모델이 이전에 생성한 , 에만 의존하게 된다. 이것 때문에 2가지 misalignment 문제가 발생한다.
- Feature misalignment: decoding에서는 training에서 사용 된 대신 를 사용해야 한다.
- Token misalignment: decoding에서 사용되는 가 training 중에 보았던 ground-truth 토큰 와 달라진다.
즉, training에서 를 예측하라고 배웠는데, 실제로 예측을 할 때는 엉뚱한 토큰을 예측해버리는 현상을 말한다.
이 중에서 2번 문제에 대해서는 많은 연구가 이루어지지 않았다. EAGLE-2와 HASS 모두 forward pass의 수가 늘어날수록 token misalignment 비율이 급격하게 증가한다. 이는 아래 (c) 그래프를 통해 확인 할 수 있다.
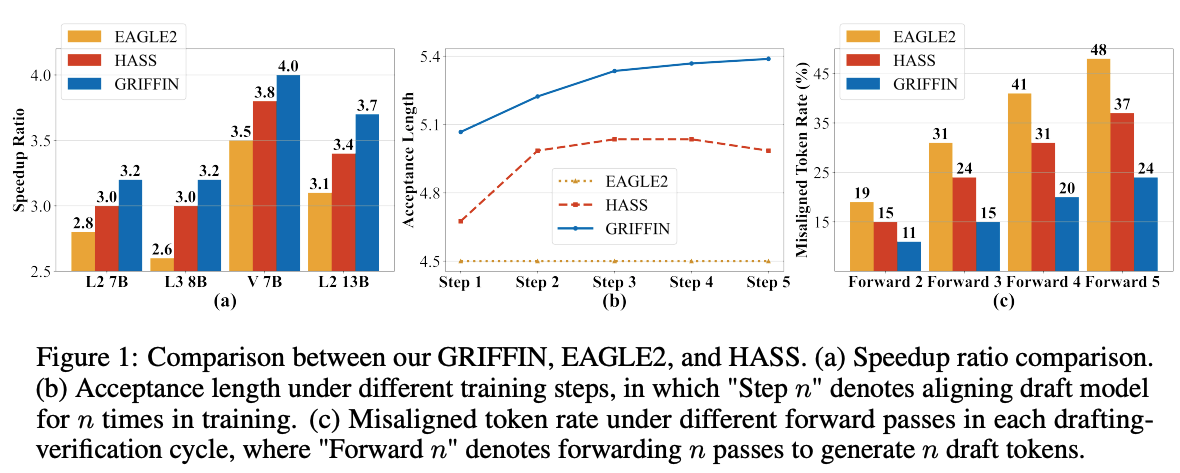
이러한 경향성이 나타나는 이유는, forward pass를 계속 수행하게 되면 오차가 지속적으로 누적이 되기 때문이다. HASS의 경우, EAGLE에서 발생하는 feature misalignment를 완화시키긴 했지만, 그럼에도 37%의 misalignment가 발생한다.
(b) 그래프에서는 token misalignment가 높아지면 training 효과를 약화 시키는 것을 보여준다. HASS의 경우, forward pass가 3번을 초과하게 되면 training을 계속 하더라도 acceptance lenght가 더이상 증가하지 않는 것을 볼 수 있다. 이는 draft가 accept 할 수 있는 토큰을 충분히 생성하지 못하기 때문에 speculative decoding으로 얻을 수 있는 성능 이득을 볼 수 없게 만든다.
그렇다면 간단하게 training 중에 토큰 대신 로 대체하면 안될까?
위와 같은 간단한 해결책을 생각 해볼 수 있지만, 이게 가능했다면 이 논문이 나올 이유가 없다. 우선, EAGLE이나 HASS는 training 전에 모든 에 대한 를 미리 계산해서 저장한다. 이는 training 데이터 생성을 반복 계산하지 않기 위한 것인데, 이를 로 바꿔버린다면 feature와 입력 된 토큰 사이의 일관성이 깨지면서 loss 계산부터 무너지게 된다. 그렇기 때문에 위와 같은 해결책은 acceptance length를 오히려 크게 낮춰버리는 문제가 생긴다.
Token Alignment Training
결국 Griffin의 핵심은 draft가 실제 decoding에서 동작하는 방식과 동일한 조건을 training 중에도 재현하는 시키는 것이다. 다시 말해, 추론 중에 draft가 유추하는 내용과 training으로 학습한 예측 토큰을 일치 시키는 것을 말한다. Griffin은 학습을 여러 단계로 구성을 해서 각 training 단계 에서 draft 모델은 개의 토큰을 예측하기 위해 forward pass를 번 수행하게 된다. 이 forward pass가 늘어날수록 모델은 ground-truth 대신 자신이 이전 forward pass에서 생성한 토큰과 feature을 조건으로 사용하여 학습을 한다.
첫번째 forward pass ()
기본적인 autoregressive decoding처럼, draft 모델()은 draft 토큰을 예측하고, target 모델 ()가 이를 검증한다. 어떤 시점 에서, draft 모델과 target 모델의 LM head 는 feature embedding인 와 draft 토큰 를 예측해야 한다. 이를 수식으로 다음과 같이 쓸 수 있다.
이 때, draft 모델에 들어가는 와 는 각각 training 데이터의 ground-truth 토큰과 target 모델이 생성한 ground-truth feature를 의미한다. 첫번째 forward pass에서는 misalignment가 일어나지 않는다. training과 실제 decoding 모두 ground-truth의 prefix인 을 기반으로 하기 때문이다. 즉, draft 모델이 생성한 토큰을 아직 입력으로 쓰는 단계가 아니기 때문에 draft 모델이 보는 입력과 target 모델이 보는 입력이 100% 동일하기 때문이다. 그래서 특별한 마스킹을 할 필요는 없다. 이에 따라 첫번째 forward pass의 loss는 다음과 같이 계산한다.
위 수식에서 ℓ은 feature-level의 와 token-level의 를 결합한 것이다.
n번째 forward pass ()
forward pass를 n번을 하면 당연히 draft 모델은 n개의 토큰을 예측하게 된다. 이에 따라 두 번째 forward pass부터는 misalignment가 발생하는 상황이 생긴다. 만약 draft가 만든 토큰이 target 모델에서 accept이 되지 않는다면 이후에 발생하는 모든 토큰은 폐기가 된다. training 중에도 만약 가 예측이 제대로 되지 않는다면, 그 이후의 draft 토큰 들은 misalign이 되어 의미있는 학습이 되지 못한다.
Top-K 기반 Predicatable Masking
이전 연구인 EAGLE은 decoding 중에 top-k의 트리를 생성한 후에, top-1만 사용했다. Griffin은 이로부터 top-k 후보 트리 생성을 학습에 반영시켰다. 그래서 ground-truth 토큰 가 draft 모델의 top-k 예측 리스트 안에 존재한다면, 그 위치를 predicatable하다고 결정한다.
EAGLE의 경우, top-1만 취급하기 때문에 정답이 토큰 트리의 top-2나 top-3에 있어도 오답 취급이 되는 문제가 있었다. 그래서 Griffin은 이를 개선하여 draft 모델이 뽑은 top-k 후보 안에 정답이 있으면 이를 예측이 가능한 위치로 보고, 만약 포함이 되지 않는다면 이 후 예측되는 토큰부터 잘못된 예측이므로, 토큰을 마스킹 시켜서 학습에서 제외시켜야 한다. 그래서 Griffin은 마스킹을 다음과 같이 정의했다.
위 수식은 단일 토큰에 대한 마스킹이기 때문에, 해당 시점의 토큰 뒤에서 발생하는 토큰 역시 마스킹이 가능하도록 누적 방식으로 alignment masking을 정의해야 한다.
결론적으로 이러한 마스킹이 된 토큰들은 loss에 포함이 되지 않는다.
추가로 Griffin은 학습을 할 때부터 target의 feature 대신에 draft 모델이 스스로 생성한 feature를 입력으로 넣어보게 함으로써 training을 실제 decoding 환경처럼 만들어준다. 이를 self-conditioning이라고 하고, 다음과 같은 수식으로 표현한다.
최종적으로 forward pass 횟수가 2 이상부터 사용하는 loss는 다음과 같이 계산하게 된다.
위 loss가 앞서 첫번째 forward pass에서 사용되는 loss와 다른 점은, 앞에 항에 부터 까지의 마스킹을 전부 더해서 정규화로 사용하는 항이 있다는 점이다. 이는 batch, 길이, pass별로 loss의 스케일이 안정되도록 하는 역할을 한다. 즉, learning rate이나 scheduling이 미치는 영향을 완화시킨다. 또한 마스킹을 표현하는 항이 있는데, top-k 안에 들지 못한 예측 토큰은 마스킹 값이 0이 된다. 이 경우, 해당 토큰의 loss 값이 전체적으로 0이 되면서 loss 계산에서 빠지게 된다.
Token Alignment Draft Model
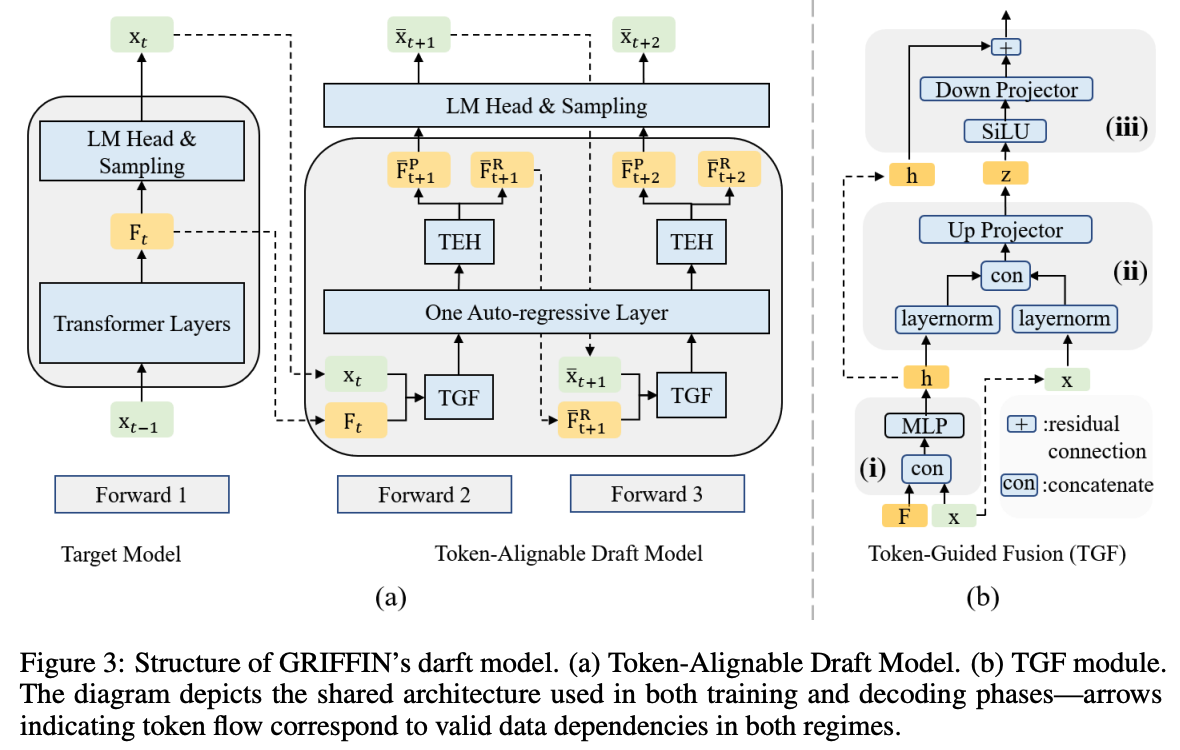
Griffin은 draft 토큰의 정확도를 높이면서 동시에 토큰 misalignment 문제를 해결하기 위해서 feature misalignment까지 체계적으로 해결 할 수 있는 token-alignable draft model을 제안했다. 위 그림과 같이 EAGLE의 draft를 기반으로, 2가지 모듈이 추가가 되어 있다.
- Token-Guided Fusion (TGF)
- Token-Enhanced Head (TEH)
(a) 그림과 같이 autoregressive 레이어 이전에 TGF 모듈이 들어간다. 이 모듈을 통해 input feature 와 토큰 embedding 를 합친다. 그리고, 하나의 autoregressive 레이어를 통과하면, dual-head 구조를 가지는 TEH 모듈을 이용하여 2가지 결과값을 생성한다.
- : 다음 토큰 예측을 위한 feature (predict feature)
- : 다음 forward pass를 위한 feature (regress feature)
따라서 TEH는 토큰의 예측과 feature 생성이라는 서로 상충되는 목적을 모델 내부에서 분리 시킨다. 이에 따라 draft 토큰의 정확도가 올라가게 된다.
Token-Guided Fusion (TGF)
TGF는 draft 모델이 생성한 feature가 target 모델의 feature와 잘 맞지 않는 feature misalignment를 해결하는 것을 목적으로 갖고 있다. 실제로는 feature-level loss는 완전히 0으로 만들기 어렵고, 이로인해 draft 모델의 토큰을 예측하는 정확도가 떨어져서 misalignment가 발생한다. TGF는 이런 문제를 해결하기 위해 feature 생성 과정에서 토큰의 embedding을 우선적으로 반영하여 생성된 feature가 target 모델의 토큰 분포를 더 잘 반영하도록 한다.
위 그림 (b)와 같이, TGF는 3단계로 나눠서 동작한다.
1. Embedding fusion (b-i)
그림 (b-i)에서, 입력 feature 와 토큰 embedding 를 결합 한 뒤, 가벼운 MLP를 통과 시킨다. 그래서 수식이 다음과 같다.
위 수식에서 는 단순한 concatenation function이다. 그리고 과 은 MLP에 해당하는 파라미터값이다. 이 단계는 토큰 정보와 feature 정보를 합친 초기 funsion expression인 를 만드는 역할을 한다. 내가 생각 했을 때는 이 단계가 Griffin의 핵심으로 보인다. token 정보를 이 단계에서 직접 feature에 통합 시키기 때문에, 최종 feature가 target model의 토큰 분포와 더 가깝게 맞춰질 가능성이 커질 것이다.
2. Feature normalization & Expansion (b-ii)
2번째 단계는 그림 (b-ii)에서, 정규화와 더 큰 dimension으로 확장하는 역할을 수행한다. 수식은 다음과 같다.
우선 토큰 와, 이전 단계에서 발생한 fusion expression인 를 각각 LayerNorm을 적용시킨 후, concatenation으로 묶어준다. 그리고 up-projector를 통해 4배로 확장을 시킨다. 확장을 시키는 목적은 더 복잡한 토큰-feature 관계를 분리시키고 align 시키기 쉬운 구조가 되기 때문이다. 이는 Transformer에서 사용하는 FFN의 중간 dimension과 동일하기 때문에 학습 안정성이 좋아지는 이점도 있다.
3. Refinement & Stabilization (b-iii)
마지막 단계에서는 이전 단계에서 확장 된 에 대해 SiLU를 적용하고, down-projector를 통해 dimesion을 축소 시킨다.
수식은 위와 같은데, 여기서 보면 1번 단계에서 수행했던 초기 fusion 값을 residual connection으로 사용하여 학습에서 안정화 역할을 한다.
결론적으로 TGF는 토큰 embedding을 명시적으로 feature 생성 과정에 통합시키는 역할을 한다. 그래서 draft feature가 target 모델의 feature 분포를 더 잘 일치시키도록 유도를 할 수 있다. 이렇게 되면 speculative decoding을 수행 할 때, misalignment가 감소하면서 draft 토큰의 정확도가 증가한다.
Token-Enhanced Head (TEH)
draft 모델은 한 번의 forward pass에서 2가지 서로 다른 일을 동시에 수행해야 한다. 하나는 다음 토큰을 예측하기 위한 feature를 만드는 것이고, 다른 하나는 다음 forward pass에서 계속 autoregressive를 이어나가기 위한 feature를 만드는 것이다. EAGLE의 경우, 이것을 하나로 통합해서 수행하였지만, 이 둘의 목적은 사실 서로 충돌하는 구조이다. 그래서 EAGLE이 토큰을 예측하는 성능이 떨어지거나 여러번의 forward pass가 진행되면 누적 되는 오차가 커지는 것이다.
위 그림 (a)에서 TEH는 동일한 입력값에 대해서 각각 predict feature와 regress feature를 다루는 LM head를 두 갈래로 분화시켜서 적용한다. TEH가 적용된 후, predict feature는 LM head로 보내서 토큰을 예측하는데 사용 된다. 반면 regress feature는 다음 forward pass의 입력 feature로 사용이 된다.
실험 결과
Griffin의 실험을 위해서 LLaMA-2 chat 7B와 13B, LLaMA-3 instruct 8B와 70B, Vicuna-1.5 7B, Qwen-2 instruct 7B, Mistral 8x7B instruct가 사용이 되었다. 모든 모델을 A100 1대에서 사용이 되었으나, LLaMA-3 70B와 Mixtral은 GPU OOM 문제로 인해 2대가 사용이 되었다. decoding 방식은 모두 autoregressive decoding이 사용이 되었고, MT-bench, HumanEval, GSM8K 데이터를 사용하였다. draft 학습의 경우, ShareGPT를 사용하였다.
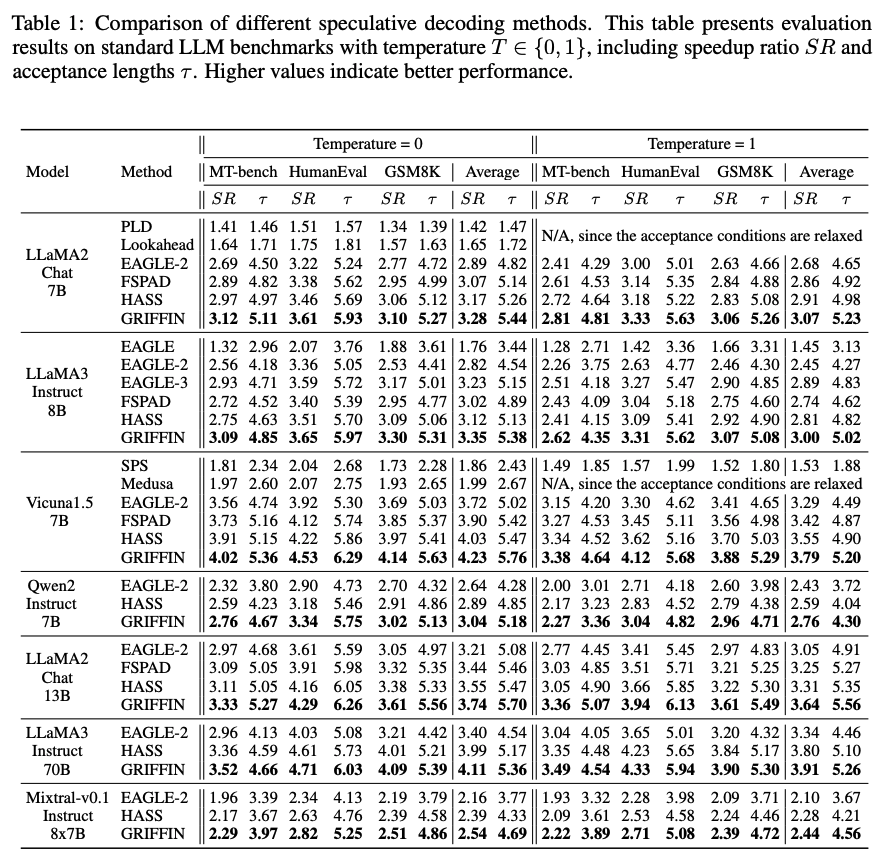
위 표는 타 SOTA 대비 Griffin의 speed-up rate (SR), 그리고 acceptance length ()값을 나타낸다. Griffin은 모든 경우에서 가장 높은 성능을 달성하였다.
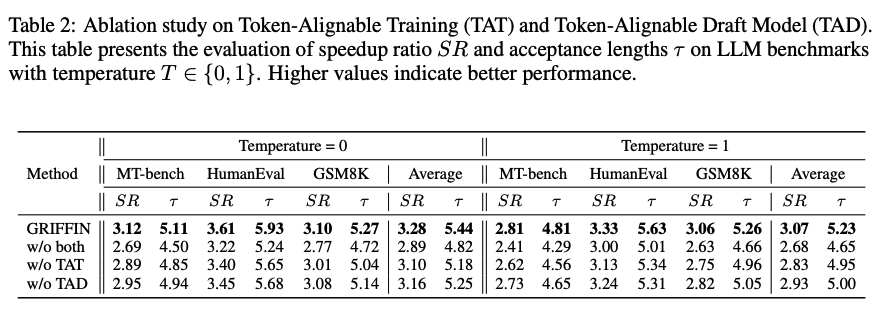
위 표는 각각 token-alignable training이랑 token-alignable draft model을 평가하기 위해, Griffin에서 각 요소들을 제거했을 때 발생하는 성능을 평가했다. 결과적으로 두 요소 중 하나라도 제거를 하면 acceptance length와 speed-up ratio가 크게 감소하는걸 볼 수 있다. token-alignable training의 경우, 학습 중 draft 토큰을 일치시키는 것이 중요하고, 반대로 token-alignable draft model은 decoding 중에서 misalignment를 줄이는 것이 중요하다는 것을 발견 할 수 있다.
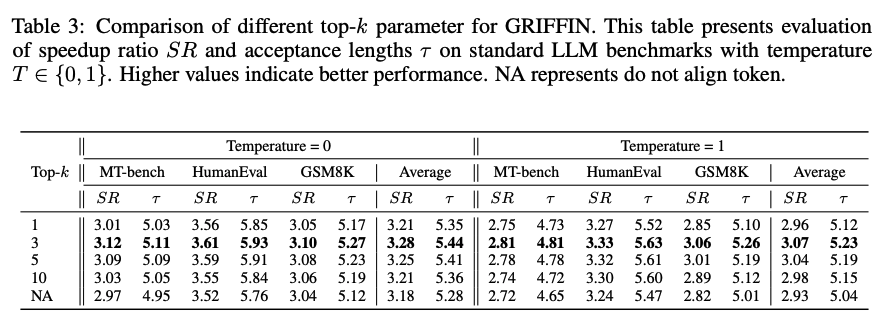
위 표는 token-alignable training에서 하이퍼파라미터로 사용되는 top-K를 사용 할 때의 값을 변화시켰을 때 미치는 영향을 분석했다. 값이 1부터 10까지 모두 align이 적용 되지 않은 (NA) 설정 대비 speed-up ratio가 향상이 되었다. 다만, top-1을 사용 하는 경우는 비효율적인데, 이는 alignment가 필요한 다른 후보 토큰들을 대부분 무시하게 되기 때문이다. 성능이 가장 좋은 구간은 인데, 이 구간에서 alignment와 generalization이 균형을 이루었다.
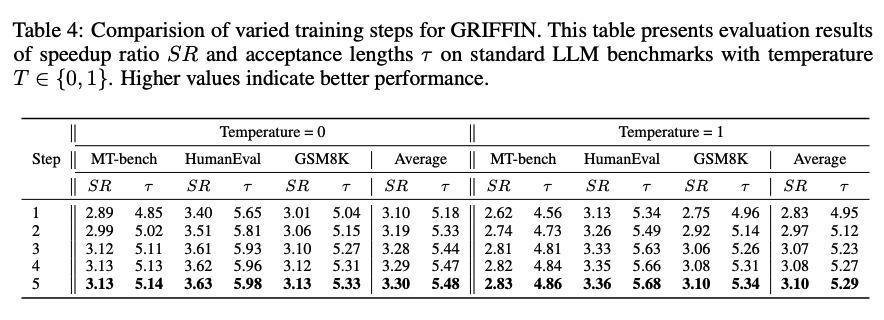
위 표는 Griffin에서 training step 수를 변화했을 때의 영향을 분석했다. 처음 5 step까지는 성능이 꾸준히 향상이 되었다. HASS의 경우에는 3 step 이후로는 성능이 정체되는 경향을 보여주지만, Griffin은 token alignment 덕분에 training을 더 진행해도 성능 개선이 이루어진다. 다만, step이 증가 할수록 alignment가 되는 토큰의 수가 감소하기 때문에 4~5 step 이후로는 개선폭이 줄어든다.
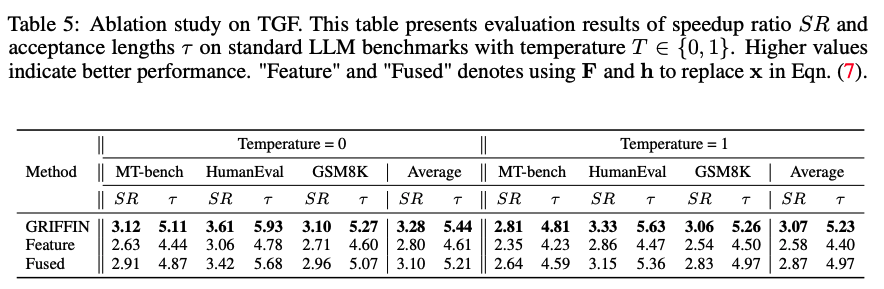
위 표는 TGF가 단순히 파라미터 증가의 영향으로 인해 성능이 증가하는 것인지를 판단하기 위한 평가이다. TGF의 구조에서 2번째 fusion input으로 사용되는 token embedding을 2가지로 바꿔서 실험하였다.
우선 raw feature로 바꿨을 때, acceptance length와 speed-up은 감소하였다. 이는 feature만으로는 불일치를 해결하기에는 부족했음을 의미한다. fused feature를 넣게 되는 경우, 여전히 기존 Griffin에 비해 성능이 감소했다.
번외로, TGF에서 projection 시키는 dimension을 축소하거나 확대 했을 때도 Griffin의 성능이 바뀌는 문제가 있었다. 만약 이를 축소된 dimension을 쓰는 경우, 중요한 정보와 노이즈를 걸러내는 능력이 부족해지기 때문에 성능이 크게 감소한다. 반면 확대된 dimension을 쓰면 표현력의 증가로 인해 acceptance length는 약간 증가하지만, 연산 비용이 커지기 때문에 speed-up ratio는 감소한다.
결론 및 고찰
결론적으로 Griffin은 학습 과정에서 token alignment를 학습 시킴으로써 misalign 되는 토큰을 loss에서 제외 시키고, draft 모델에서 추가적인 구조를 도입하여 decoding에서 발생하는 misalignment를 크게 줄였다. 물론 문제점도 있는데, Griffin의 경우에는 token alignment 학습을 위해서 한 번의 forward pass도 쪼개서 사용하는 multi-step으로 학습을 한다. 그렇기 때문에 EAGLE에 비해 추가적인 학습 오버헤드가 들어가게 된다. 그래도 실제 inference에서의 이득이 더 크기 때문에 학습이 얼마나 더 오래 걸리는지는 모르겠지만 충분히 사용할만한 여지는 있다고 보고 있다.
