LLM에 대한 공부를 하면서, 언젠가 한 번 Transformer에 대해서 제대로 리뷰를 해야겠다고 생각했었다.
ML System 필드로 현업에서 일하다 보면, 가끔 모델에 대한 이해도가 높아야 하는 순간이 있었다.
그 때마다 수박 겉핧기로 들은 내용으로 대처하다 보면, 나중에 와서 아쉬워지는 부분들이 많았다.
Background
기존에 자연어 관련 모델들은 복잡한 RNN이나 CNN을 사용하는 encoder-decoder 구조를 가졌다.
특히 RNN의 경우, 멀리 떨어진 단어 사이의 관계를 잘 기억하지 못하고, 단어를 하나씩 순서대로 처리하기 때문에 학습 속도도 느리다는 문제가 있었다. 대표적으로는 seq2seq, LSTM, GRU가 있다.
Transformer 아키텍처는 이러한 문제를 해결하기 위해 다음과 같은 특징을 가지고 있다.
- 병렬화를 통해 모든 단어를 동시에 처리
- 멀리 떨어진 단어도 참조
- 단순한 구조를 통한 빠른 학습 속도 (RNN, CNN 사용 X)
Transformer Architecture
Transformer 모델의 아키텍처는 다음 그림과 같이 생겼다.
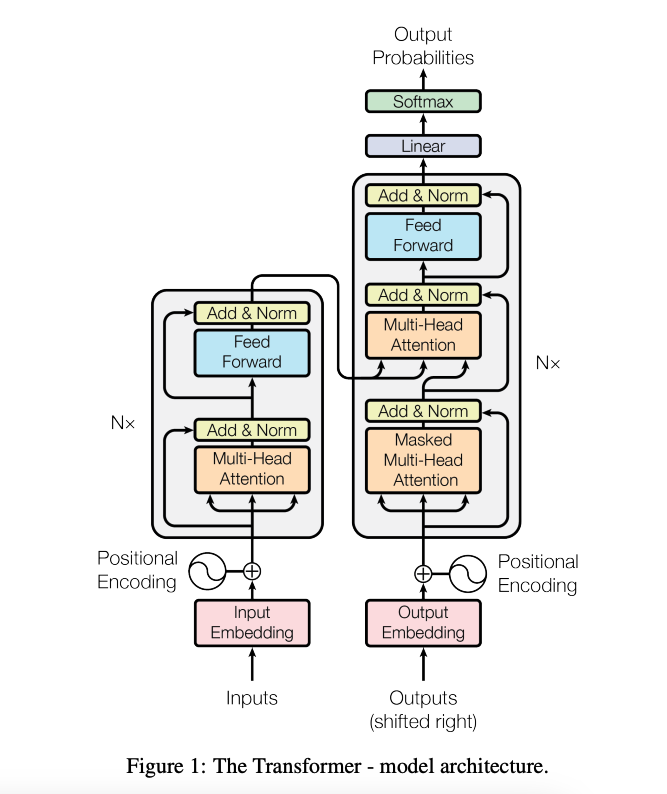
대부분의 당시 SOTA 모델들이 그랬든, Transformer도 Encoder-Decoder 구조로 되어 있다.
위 그림에서 왼쪽이 Encoder, 오른쪽이 Decoder고, N=6으로 구성 된 스택 구조이다.
Positional Encoding
먼저 자연어 input이 들어가는 부분부터 살펴보자.
가장 먼저, 자연어 input 값은 embedding 과정을 통해, 숫자로 구성 된 vector로 변환된다.
그리고, Positional Encoding을 통해 각 단어의 위치 정보를 넣어준다.
아래와 같이 단어의 순서가 바뀌면 의미가 달라지기 때문에, 단어의 순서는 문장에서 아주 중요하다.
1) The dog bit the man.
2) The man bit the dog.
기존의 RNN이나 CNN의 경우와 다르게 Transformer는 입력된 데이터를 한 번에 병렬로 처리한다.
그렇게 때문에 입력의 순서가 단어 순서를 보장하지 않고, 되려 단어 순서가 사라져 버린다.
Transformer는 이를 해결하기 위해, Positional Encoding을 이용하여 단어의 위치 정보를 추가한다.
Attention
Attention의 경우는 사실 이 논문에서 처음으로 소개 된 개념은 아니다.
이전에 ICLR'15에 발표 된 Neural Machine Translation by Jointly Learning to Align and Translate 라는 논문에서 처음 소개 되었고, 이는 나중에 추가로 리뷰를 할 예정이다.
Attention의 개념을 간략하게 소개하자면, 어떤 문맥에서 어느 단어를 집중해서 볼지 결정하는 방식이다.
Attention은 어떤 Query(Q)에 대한 Key(K)의 Value(V)들 사이의 연산으로 값이 결정 된다.
이들은 모두 Vector 형태의 행렬로 구성 되어 있다.
Transformer는 Attention을 다음 3가지 방식으로 나누어서 사용한다.
- Encoder-Decoder에서는 Query는 이전 decoder layer에서 발생하고, Key와 Value만 encoder layer에서 발생하는걸 사용한다.
- Encoder에서는 Self-Attention을 사용한다. 이는 Attention을 자기 자신에게 취하는 것으로, 단어와 단어 사이의 연관성을 나타낸다.
- Decoder에서는 현재 단어에 대해 미래의 단어를 참고하여 토큰이 생성 되는 것을 방지하기 위해, softmax 입력값 중에서 잘못 연결 된 값을 마스킹하여 처리한다.
위 3가지 내용 중에, 처음 봤을 때 이해가 되지 않았던 것이 3번이였다.
논문에 적힌 내용에서는 "leftward information flow" 라고 표현이 되어 있었는데, 용어가 조금 어려워서 찾아보니 미래의 단어를 참조하여 현재 단어가 처리 될 수 있다는 내용이였다. 즉, 문장을 autoregressive 하게 생성 할 때, RNN이나 LSTM 같은 time-sequence에서 문제 되지 않았던 방식이 전체 문장의 Attention을 볼 때는 문제가 된다는 것이였다.
Scaled Dot-Product Attention
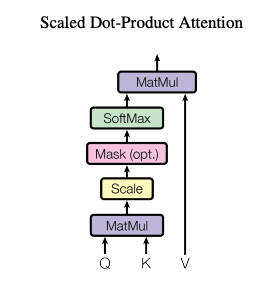
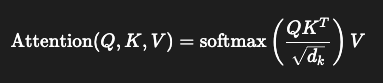 Transformer에서 Attention을 계산하기 위해서, Scaled Dot-Product Attention이라는 계산 방식을 통해 Attention score를 계산한다. 여기서 값은 Query와 Key의 dimension을 의미한다.
Transformer에서 Attention을 계산하기 위해서, Scaled Dot-Product Attention이라는 계산 방식을 통해 Attention score를 계산한다. 여기서 값은 Query와 Key의 dimension을 의미한다.
연산에서 보면 알다시피, Matmul을 이용하기 때문에 기존의 Feed-Forward를 이용하는 additive attention에 비해 굉장히 빠르게 attention 값을 계산 할 수 있다.
Multi-Head Attention
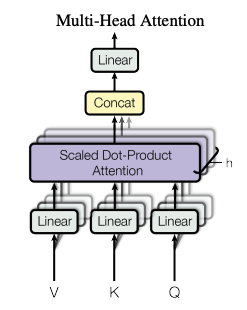 Transformer는 위에서 설명 된 Attention을 한 번의 계산만 수행하지 않는다.
Transformer는 위에서 설명 된 Attention을 한 번의 계산만 수행하지 않는다.
Transformer 내에 Multi-Head Attnetion은, head의 값만큼 Scaled Dot-Product Attention 연산을 병렬로 수행하고, 각각의 병렬 연산을 통해 발생 한 Attention 값들을 연결시킨다. 이는 한 번의 Attention을 보는 것보다, 여러 head가 Attention을 계산하고, 이를 종합하는 것이 더 효과적임을 나타낸다.
Self-Attention vs RNN vs CNN
이 부분은 Transformer를 읽으면서 내가 제일 흥미롭게 본 부분이였다.
기존의 RNN, CNN과 비교하여 time complexity나 장단점을 비교한 부분인데, 논문에서 제시 된 표는 다음과 같았다.
 값은 seqeunce 길이, 는 dimension, 는 CNN의 커널 크기, 그리고 은 self-attention에서 제한 되는 이웃 토큰의 크기이다. 각 레이어의 Time complexity의 경우, self-attention은 입력 sequence 길이에 대해 매우 민감하게 반응한다. 그러나 RNN과 비교 했을 때, Self-Attention은 병렬적으로 처리하는 것이 가능하고, 상대적으로 먼 거리에 위치한 토큰과 연산이 쉽다. 또한 CNN과 비교 하더라고, 장거리 토큰과의 연관성을 위해서는 kernel 크기에 영향을 받기 때문에 상대적으로 self-attention이 매우 유리하다.
값은 seqeunce 길이, 는 dimension, 는 CNN의 커널 크기, 그리고 은 self-attention에서 제한 되는 이웃 토큰의 크기이다. 각 레이어의 Time complexity의 경우, self-attention은 입력 sequence 길이에 대해 매우 민감하게 반응한다. 그러나 RNN과 비교 했을 때, Self-Attention은 병렬적으로 처리하는 것이 가능하고, 상대적으로 먼 거리에 위치한 토큰과 연산이 쉽다. 또한 CNN과 비교 하더라고, 장거리 토큰과의 연관성을 위해서는 kernel 크기에 영향을 받기 때문에 상대적으로 self-attention이 매우 유리하다.
Position-wise Feed-Forward Network
Encoder와 Decoder에는 Attention 레이어 외에 2개의 Linear와 ReLU로 이루어진 Feed-Forward가 존재한다.
이 FFN은 dimension을 확장 했다가 다시 줄이게 되는데, 이로 인해 얻을 수 있는 효과는 다음과 같다.
- Attention은 단어 사이의 관계성은 잘 나타내지만, 복잡한 패턴이나 비선형적 특성을 이해하진 못한다.
- 독립적으로 적용 되기 때문에, sequence의 토큰의 특징을 개별적으로 강화 할 수 있다.
- FFN 레이어마다 파라미터가 다르기 때문에 더 복잡하고 추상적인 정보 학습이 가능하다.
실험 결과
Transformer는 다른 모델과 비교하여 영어-덴마크어 번역 및 영어-프랑스어 번역을 실험한 결과를 제시했다. 타 모델들에 비해 제일 뛰어난 BLEU 점수를 기록했고, Training cost 또한 가장 적게 사용 되었다. 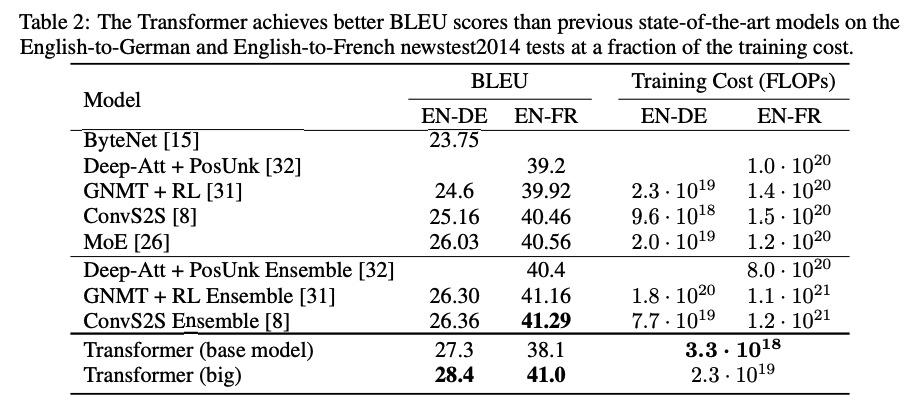
결론 및 소감
Transformer (라고 쓰고, Attention에 대한 공부) 아키텍쳐를 살펴보면서 기존에 Multi-Head Attention 구조를 보면서 이해가 잘 안되었던 부분들이 어느정도 이해가 되는 것 같았다. 내가 현재 가장 관심 있는 부분은 Attention에서 KV Cache에 관한 내용들인데, Transformer 논문을 리뷰해보니 좀 더 이에 대한 인사이트가 생겼고, 후에 소개 할 PagedAttention, CacheBlend 같은 KV Caching 최적화에 대한 논문들을 좀 더 잘 이해할 수 있을 것 같다.
