오늘 소개 할 논문은 LLM의 inference latency를 크게 개선 할 수 있는 Speculative Decoding이다.
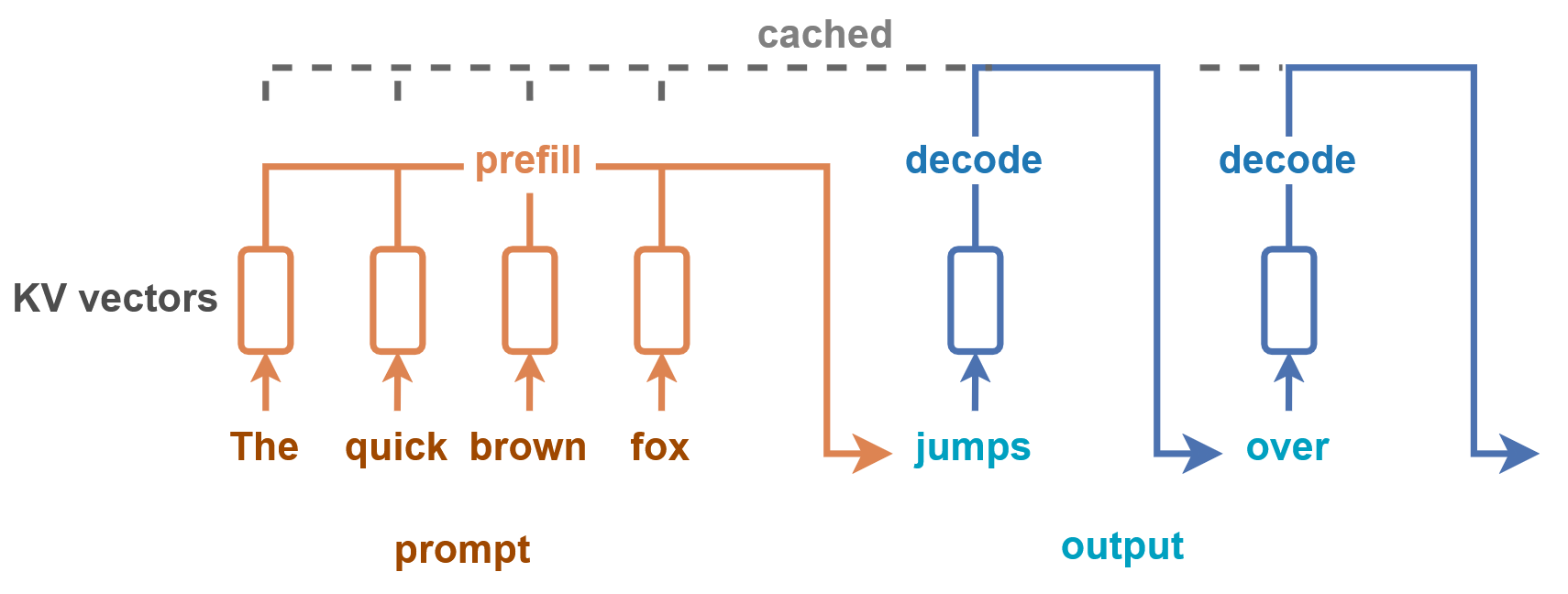
Prefill과 Decoding
 출처: https://huggingface.co/blog/tngtech/llm-performance-prefill-decode-concurrent-requests
출처: https://huggingface.co/blog/tngtech/llm-performance-prefill-decode-concurrent-requests
Transformer의 Inference 동작 방식은 Prefill과 Decoding, 2가지로 나눌 수 있다.
1) Prefill 단계는 초기 입력 시퀀스인 input prompt 전체를 한 번에 모델에 넣고, 이에 대한 attention 계산을 수행한다. 그리고, KV Cache 기능을 사용한다면, 이를 생성한다.
2) Decoding 단계는 Prefill 단계 이후, 하나씩 토큰을 생성해서 output을 만들어내는 단계이다. 이 단계는 autoregressive 하기 때문에, 이전에 생성한 토큰들에 의존해서 한 토큰씩 반복적으로 수행한다.
Decoding 단계의 경우, 토큰을 하나씩 순차적으로 만들어내기 때문에 GPU의 최대 장점인 병렬 처리가 어렵고, 이에 따라 연산 효율이 낮아지기 때문에 전체 Inference 시간에서 상당히 많은 부분을 차지 한다. 즉, 개의 토큰을 생성하기 위해서 N번의 디코딩을 순차적으로 실행해야 한다.
Speculative Decoding은 이러한 Transformer의 decoding 과정의 구조로 인한 문제점을 해결하고자 했다.
Speculative Decoding

Speculative Decoding의 아이디어는 다음과 같다.
-
우선 두 개의 모델 과 를 준비한다. 이 때, 모델 는 모델 의 근사 모델이어야 한다. 실제 경우에서 보통 모델 은 기존에 추론을 수행하고자 하는 모델을 사용하고, 근사 모델 는 모델 M의 파라미터를 대폭 줄인 fine-tuning 된 sLLM을 사용 하는 것이 보편적이다.
-
근사 모델 는 사용자가 지정한 만큼 개의 후보를 만든다.
-
이 후 모델 을 이용해 근사 모델이 만든 개의 후보를 병렬적으로 평가하고, 모델 과 동일한 분포를 만들어 낼 수 있는 후보를 선택한다.
-
거절 된 첫 번째 후보를 모델 을 이용해 보정하거나 모든 후보가 수락 된 경우, 보정 된 분포로부터 추가 토큰을 생성한다.
요약 하자면, Draft Model을 이용해 어느정도 가능한 후보 토큰을 생성 하고, Main Model이 이를 검증 및 보정을 하는 방식이다. 그렇다면 Main Model은 어떻게 검증 및 보정을 하는걸까?
Standardized Sampling
우선 논문에 적힌 Standard Sampling에 대해 알아보자.
일반적으로 언어 모델이 여러 후보 중에서 다음에 올 토큰을 예측하고, 그 중 하나를 뽑을 때 (Sampling) 다양한 방식들이 있다. 논문의 경우, argmax, top-k, nucleus (top-p), temperature 와 같은 예시들이 있다고 소개한다.
해당 방법은 sampling을 수행하는 방식이 다르고 복잡해보이지만, 확률 분포를 조정하여 샘플링 하는 방식 하나로 통일 할 수 있다고 주장한다.
결국 Draft Model과 Main Model의 샘플링 방식이 달라서 확률 분포가 다르더라도, 샘플링을 표준화 하는 방식으로 동일하게 확률 분포를 맞춰 줄 수 있다는 뜻이다.
Speculative Sampling
그러면 이제 Draft Model과 Main Model이 표준화를 통해 확률 분포가 맞춰지게 되었다.
이 후에 할 일은 Speculative Sampling을 이용해, 다음에 발생 할 토큰을 샘플링 하는 방식이 필요하다.
이는 논문의 Speculative Sampling 파트에서 다루고 있다.
Model에서 다음 단어를 선택 할 때, Speculative Decoding은 Draft Model에서 단어를 먼저 샘플링 한다.
이를 수식으로 나타내면, 로 표현 한다. 그리고 이 결과를 2가지로 분기한다.
- 인 경우, 샘플을 유지한다.
- 인 경우, 확률로 샘플을 거절하고 조정 된 샘플링을 수행한다.
2번째의 경우 샘플링 조정을 다음과 같은 수식으로 진행한다.
이 수식에 대해 조금 자세히 설명하자면, Speculative Decoding에서 Draft Model이 샘플링 한 토큰이 거절 되는 때는 Draft Model이 너무 낙관적으로 예측한 경우이다.
그런 경우, Main Model이 그러한 부분을 덜 낙관적인 나머지 부분으로만 보정하여 다시 샘플링을 시도한다.
좀 더 직관적인 예시를 들어 보자면, 토큰 A, B, C, D가 있고, 각각이 발생할 확률을 아래와 같이 정의했다.
| 토큰 | ||
|---|---|---|
| A | 0.4 | 0.3 |
| B | 0.3 | 0.5 |
| C | 0.2 | 0.1 |
| D | 0.1 | 0.1 |
그러면 Draft Model의 는 에 비해 토큰 B가 발생 할 확률을 낙관적으로 생각하고 있다.
따라서 여기에 를 적용 해주면, 테이블은 다음과 같이 바뀐다.
| 토큰 | ||
|---|---|---|
| A | 0.1 | 0.1 |
| B | -0.2 | 0 |
| C | 0.1 | 0.1 |
| D | 0 | 0 |
이렇게 되면 토큰 B가 나올 확률은 조정 된 확률 분포에서 샘플링 확률이 0이 된다.
즉, 조정 되는 샘플링 방식은 Main Model이 판단 했을 때, 유망하지 않다고 생각되기 때문에 버려지는 것을 나타낸다.
왜 빠른걸까?
처음에 Speculative Decoding을 접했을 때, 외부에서 봤을 때 Draft Model의 도입이 오히려 모델 추론을 2번 하게 되는 셈이기 때문에 왜 inference time이 감소하는 것인지 의아했다. 논문에서는 이를 Wall-time Improvement 파트에서 설명하고 있다.
결론부터 말하자면, 병럴 처리 자원이 충분하다는 전제 하에,
- Main Model의 Decoding 횟수는 감소하고,
- 도입 되는 Draft Model 추론이 굉장히 빠르기 때문이다.
Speculative Decoding에서 성능에 영향을 줄 수 있는 파라미터는 2가지가 있다.
-
값은 Draft Model이 Main Model을 얼마나 잘 근사하는가를 나타낸다. 당연히 Draft Model의 근사 분포가 Main Model과 거의 유사하다면, 발생 할 다음 토큰의 확률이 거의 Main Model과 유사해지기 때문에, 거절 되는 토큰의 수가 줄어들 것이다.
-
값은 Draft Model이 생성하는 후보 토큰의 수를 의미한다. Draft Model이 한 번에 고려 할 수 있는 후보 토큰을 많이 만들수록 Main Model은 기대 할 수 있는 토큰의 수도 증가한다.
이 파라미터를 토대로 논문에서 유도한 Speculative Decoding을 적용 했을 때의 Main Model의 호출 횟수의 배율을 아래와 같은 수식으로 작성 할 수 있었다.
결국 Draft Model이 Main Model을 더 잘 근사하고, 한 번에 많은 후보 토큰을 생산 할수록 Main Model의 호출은 저 수식 값의 배율만큼 호출 횟수가 줄어든다.
결론 및 소감
Speculative Decoding은 현재 Huggingface의 Transformers 패키지나 vLLM등 다양한 inference 라이브러리에서 기능을 지원하고 있다. 대략적인 개념 (Draft Model이 후보 뱉으면 Main Model이 검토하는 것) 정도는 알고 있었지만 막상 왜 빠른지, 왜 Draft Model을 동일한 LLM family의 sLLM을 사용하는지 알고 나니까 좀 더 이해하기가 편했다.
사내에는 아직 공식적으로 Speculative Decoding을 활용한 서비스는 없는 것으로 안다. 내가 이걸 적용해서 첫 사례가 되었으면 좋겠다.
