요즘 회사에서 speculative decoding 연구를 하면서 Eagle을 기반으로 논문을 작성하는걸 보았다. 같은 팀 박사분께 Eagle을 기반으로 만드는 이유가 뭔가 하고 여쭤보니, Eagle이 seculative decoding 관련 시리즈 중에 아직까지 제일 성능이 좋다는 이야기를 들었다. SOTA 만큼의 스피드를 낼 수는 없어도 LLM의 출력 퀄리티가 크게 떨어지지 않아서 trade-off를 감안했을 때 제일 최적이라고 들었다.
사실 fine-tuning으로 문제를 개선하는 방식은 내가 원하는 방향과는 맞지 않지만, 성능이 좋다고 소문이 난 논문이니까 어쨌든 리뷰를 해야겠다는 생각이 들었다.
Motivation
언제나 그렇듯, speculative decoding의 고민점은 오버헤드가 낮은 적절한 draft 모델을 찾는 것과 acceptance rate를 높여야 한다는 것이다. 하지만 대부분 Eagle 이전의 논문들은 draft 모델의 정확도가 낮다는 문제가 있었다.
Eagle의 저자들은 2가지 핵심적인 내용을 관찰했다.
- feature 수준에서의 auto-regression은 token 수준에서 autoregression을 하는 것보다 단순하다.
- 샘플링 과정에서의 randomness가 다음 feature의 예측 성능을 제한 한다.
우선 feature라는 것은 LLM 구조에서 마지막 Transformer 레이어 이전에 존재하는 Transformer 레이어를 의미한다. 즉, 입력 레이어 -> N개의 Transformer 레이어 -> 출력 레이어 순서로 모델이 구성 되어 있다면, feature 수준에서의 autoregression은 N-1번째 Transformer에서 발생하는 것을 의미한다. token sequence는 LLM 입장에서는 자연어의 복잡한 변환 형태이지만, feature sequence는 이에 비해 규칙적인 구조를 가진다. 그래서 이 단계에서 autoregressive를 처리 하고 LLM의 LM head를 통해 토큰을 만드는 것이 직접 토큰을 예측하는 것보다 효율적이다.
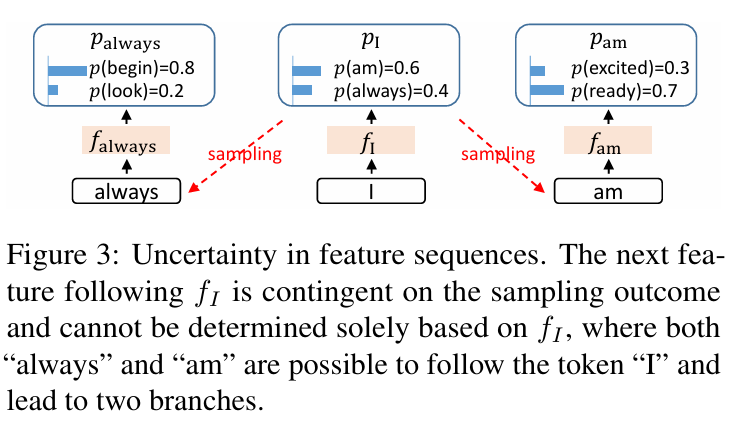
토큰 확률 분포를 예측하고 LLM이 이를 샘플링 할 때, 랜덤성이 존재한다. 그에 비해 feature는 토큰보다 연속적이고 차원이 크기 때문에 확률로 샘플링 하기 어렵다. 위 그림처럼 "am"이라는 토큰을 샘플링 할 때랑, "always" 토큰을 샘플링 하면 사람이 봤을 때 문법적으로는 차이가 없다고 느껴지지만, feature 단위에서는 서로 다르게 표현이 된다. LLM은 미래에 나올 토큰의 정보를 알 수 없기 때문에 다음 토큰이 뭔지 모르는 상태에서 다음 feature를 예측해야 하는 상황이 발생한다. 이에 따라 불확실성이 발생하고, 예측이 부정확해질 수 있다.
EAGLE
Eagle은 다른 speculative sampling 기반 논문들처럼 후보들을 생성하는 drafting 단계와 이를 검증하는 verification 단계로 나누어져있다.
Drafting Phase

위 그림은 다른 draft 방식과 Eagle의 차이를 보여주는 그림이다. Speculative sampling이나 Lookahead는 토큰을 기반으로 다음 토큰을 예측한다. Medusa의 경우, 베이스가 되는 LLM에 추가적인 head를 붙여서 독립적으로 토큰을 예측한다.
Eagle의 경우, feature sequence와 한 시점 앞으로 이동 된 토큰 sequence를 입력으로 사용하여 feature 자체를 예측한다. 그리고, 이를 LM head에 입력 시켜서 확률 분포를 만든 뒤, 그 확률 분포를 통해 다음 토큰을 샘플링 한다.
EAGLE Architecture
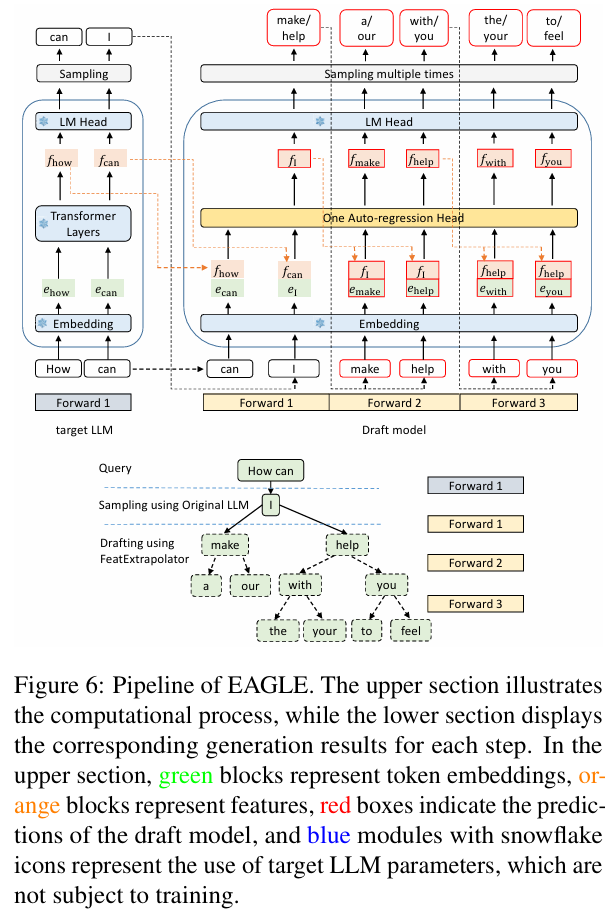
Eagle의 draft 모델은 embedding, LM head, autoregression head 3가지로 구성이 되어 있다. 이 중 embedding과 LM head는 target LLM의 파라미터를 그대로 사용한다.
우선 draft 모델은 2가지를 입력으로 받게 된다.
- feature sequence
- 앞당겨진 토큰 sequence
이를 기반으로 draft 모델은 입력값들을 다음과 같이 처리하게 된다.
- 먼저 토큰 sequence의 형태를 embedding seqeunce와 맞춰 주어야 한다.
- 이 후, embedding이 된 seqeunce를 feature seqeunce와 연결 시켜서 하나의 seqeunce로 만든다.
- Autoregression head는 하나의 fully-connected(FC) layer와 decoder layer로 구성 되어 있는데, FC layer는 결합 된 sequence를 받아서 dimension을 줄이고, decoder가 이를 받아서 다음 feature를 예측한다.
- 예측 된 feature는 LM head가 받아서 확률 분포를 예측하고, 이를 기반으로 다음 토큰을 샘플링 한다.
- 예측 된 feature와 샘플링 된 토큰은 다시 입력값으로 들어가서 autoregressive를 이어나간다.
Tree-based Drafting
Eagle은 tree attention 메커니즘을 이용하여 tree 구조의 draft를 생성한다. 이를 통해 depth를 가진 tree draft를 번의 forward pass만으로 생성 할 수 있다. 이를 바꿔 말한다면 forward pass는 번만 하는데, 동시에 예측 가능한 토큰의 수는 개보다 많다는 말이 된다.
위 그림에서 forward pass는 3번만 이루어졌는데, 토큰 tree는 10개를 생성해낸다.
Eagle Training
다음 feature를 예측을 하는 것을 Eagle에서는 regression의 일종으로 보고 있다. 그래서 다음 수식과 같은 Smooth L1 loss를 이용한다.
하지만 이는 feature 예측에만 국한되는 loss이다. 최종적으로는 토큰을 예측하여 sequence를 생성해야 하기 대문에, classification loss도 함께 사용 된다.
따라서 regression loss와 classification loss를 결합하여 autoregression head를 학습 할 때 다음과 같이 결합 된 loss function을 이용하여 학습한다.
일반적으로 classification loss는 수치적으로 regression loss보다 약 10배 정도 크다. 그렇기 때문에 이에 대해 가중치를 부여해야 하며, 보통 로 설정해서 학습한다고 한다.
추가로, Eagle의 autoregressive head 학습을 위해 저자들이 몇가지 실험을 통해 알아낸 사실이 있다. 먼저, 원래 학습을 위한 데이터셋은 target LLM이 생성한 텍스트를 사용하는 것이 좋다. 하지만 이는 비용이 매우 크다는 문제가 있다. Eagle이 다행히도 학습에 대한 민감도가 낮기 때문에, LLM이 직접 생성한 내용 대신 ShareGPT 데이터를 사용하였다고 한다.
또한 draft에서 autoregressive로 처리하는 feature가 부정확하면 오차가 누적이 될 수 있다. 이를 방지하기 위해서 uniform distribution에서 샘플링한 랜덤 노이즈를 target LLM의 feature에 추가하여 data augmentation을 사용했다고 한다.
Verification phase
Eagle은 tree attention을 이용하여 target LLM은 tree 구조의 draft 내 모든 토큰의 확률을 한 번의 forward pass만으로 검증을 할 수 있다. draft tree의 각 노드마다 speculative sampling을 하거나 분포를 조정한다. 이를 통해 출력 되는 텍스트의 분포가 target LLM의 분포와 일치하도록 보장 할 수 있다. 이 방식은 후에 리뷰할 SpecInfer (ASPLOS'24 논문) 방식과 유사하다고 한다.
실험 결과
Eagle을 평가하기 위해서 실험 모델로는 Vicuna (7B, 13B, 33B), LLaMA-2 (7B, 13B, 70B), 그리고 Mixtral 8x7B instruct 모델을 사용하였다. 그리고 평가를 위한 데이터셋은 MT-bench, HumanEval, GSM8K, Alpaca가 사용 되었다.
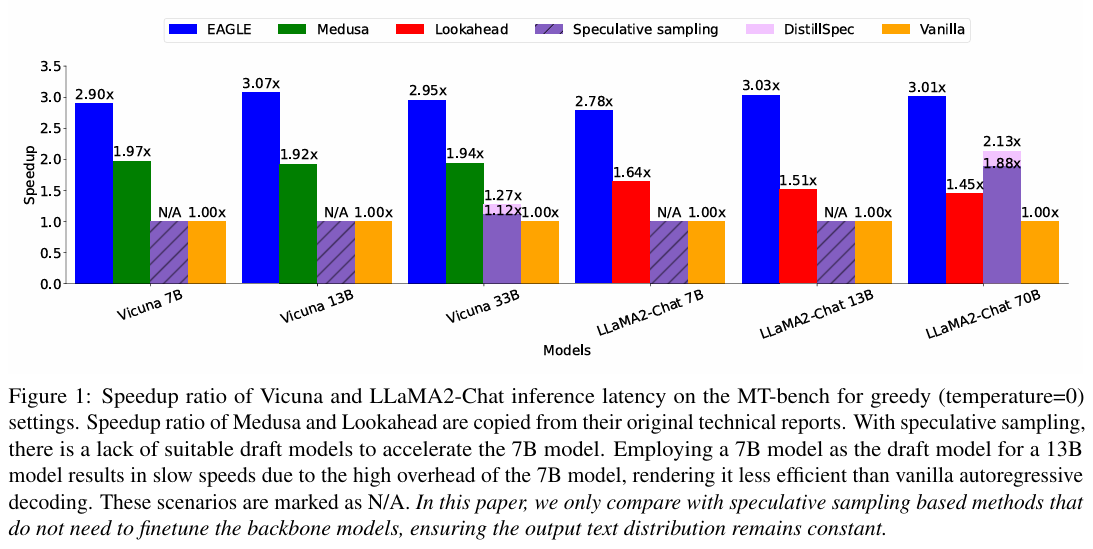
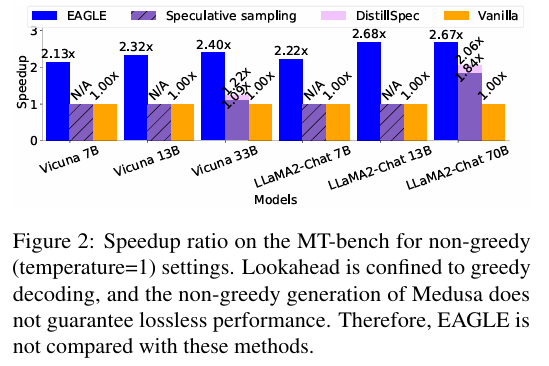
위 두 그래프는 Eagle의 속도 향상 비율을 나타낸다. 두 그래프의 다른점은 temperature인데, 위에는 값을 0으로 했을 때, 아래는 1로 했을 때다. 전체적으로 Eagle이 타 방식들에 비해 성능이 뛰어났는데, temperature 값에 따라서 Eagle의 성능이 다르게 측정 되었다.

위 표는 다른 task에 대한 Eagle의 속도 향상 비율과 acceptance length (), 즉 target LLM에서 한 번의 forward pass에서 받아들여진 평균 토큰 수를 나타내는 지표를 보여준다.
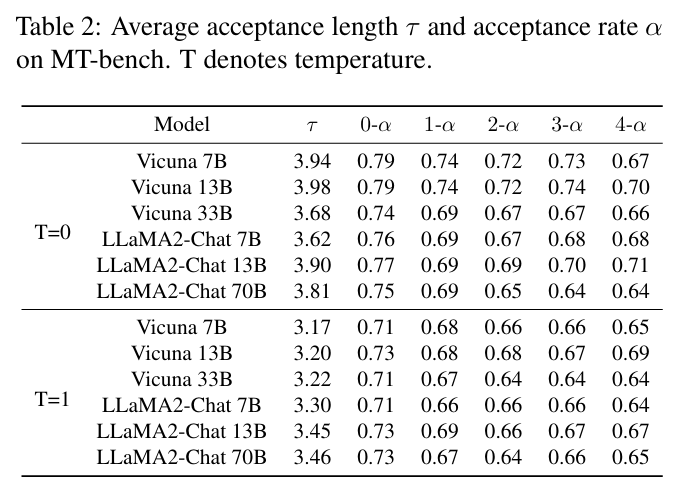
위 표는 acceptance length와 함께 acceptance ratio를 보여준다. 이 때, acceptance ratio는 draft 모델이 예측한 개의 feature 중 발생한 일부 오류를 고려하여 형태로 표기하였다. 는 완전히 정확한 feature sequence를 의미하는데, 단일 오류가 존재하는 와 대비하면 차이가 존재하지만, 그 이후 까지 고려 했을 때, 값의 차이가 거의 없다. 이는 Eagle이 feature 오류에 대해 견고한 성능을 가지고 있고, 오류 누적을 잘 처리할 수 있다는 지표로 해석이 된다.
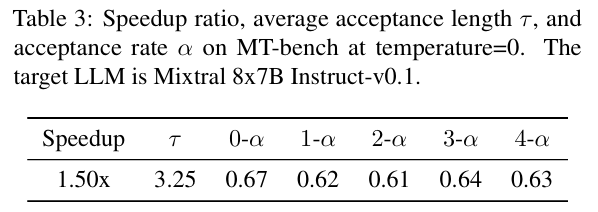
위 표는 Mixtral, 즉 MoE에 적용했을 때를 나타낸다. 1.5배까지 성능이 향상 되긴 했지만, LLaMA와 비교 했을 때 낮은 수치인데, 이는 acceptance length가 짧고, speculative sampling을 통한 MoE 모델을 가속 시키는 것이 복잡하기 때문이다. MoE의 경우, 보통 autoregressive decoding을 할 때, 한 토큰 당 2개의 expert가 가진 weight만 읽으면 된다. 하지만 speculative sampling은 검증 단계에서 여러 토큰을 처리해야 하기 때문에 2개 이상의 expert를 참조해야 한다. 이러한 차이로 인해 dense decoder-only 모델과 차이가 발생한다.

위 그림은 Eagle을 quantization과 compilation을 적용한 GPT-Fast와 결합했을 때의 성능을 보여준다. 이를 통해 Eagle이 다른 가속 기술과 호환이 된다는 것을 증명해냈다.
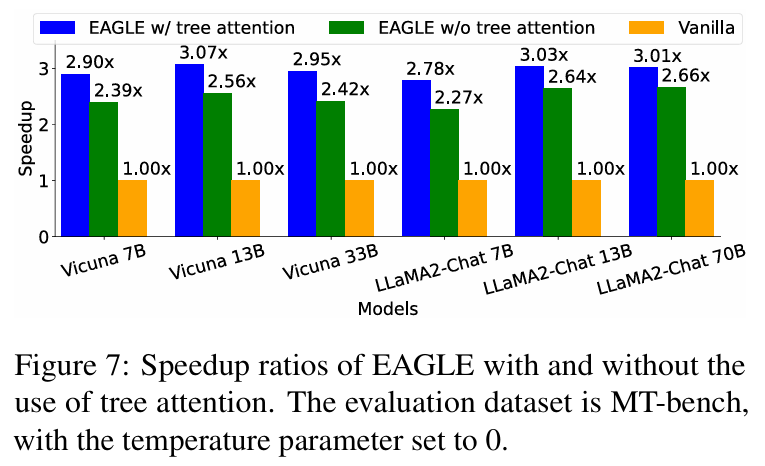

위 그래프와 표는 tree attention을 사용 했을 때의 영향을 비교한 결과이다. speculative sampling과 같은 chain-structured 구조와 비교했을 때, tree draft와 검증은 모델의 forward pass 횟수를 늘리진 않지만 forward pass 한 번에 처리하는 토큰의 수를 증가시킨다. 그렇기 때문에 acceptance length는 크게 증가하지만 speedup 비율은 그만큼 증가하지는 않는다고 한다.

위 그래프는 Eagle을 적용할 때, batch size를 증가시켜서 테스트 한 결과이다. 이전까지의 성능 실험에서는 batch size를 1로 사용했지만, 이 실험에서는 그 이상으로 증가시켰다. batch size를 유의미하게 크게 증가 시키진 않았지만 크기를 키울수록 속도 증가 비율이 감소하는 것을 볼 수 있다.
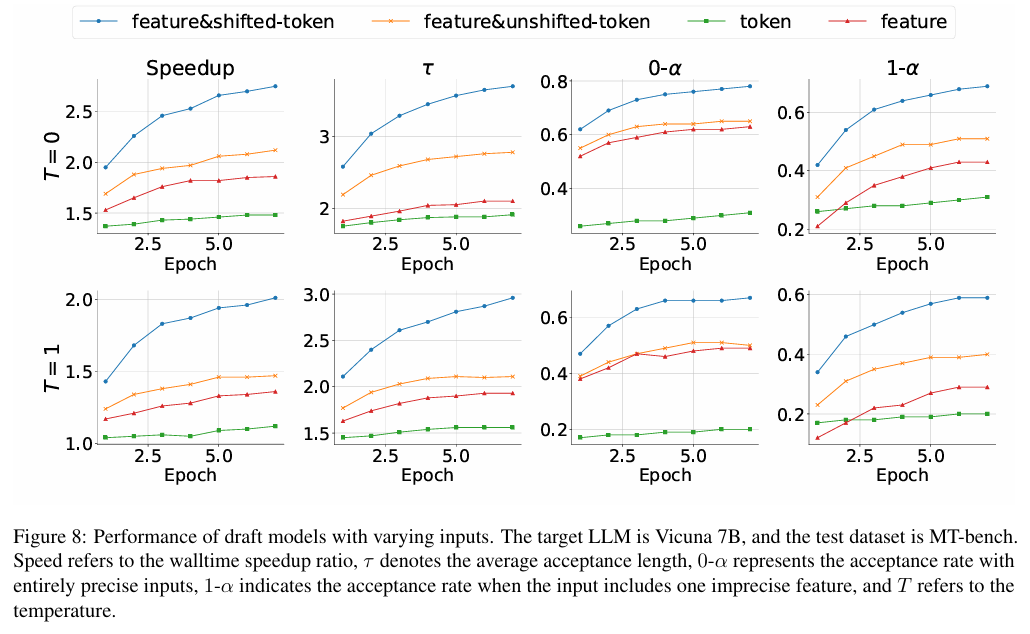
마지막 그래프는 Vicuna 7B에서 입력값을 다음 4가지 타입으로 나누어 테스트 했다.
- feature & shifted-token (Eagle에서 사용하는 방식)
- feature & unshifted-token
- token
- feature
그 결과, 토큰을 한 스텝 앞으로 이동 시켜서 (shifted-token) draft 모델이 샘플링의 랜덤성을 고려 하는 것이 성능을 크게 향상 시킬 수 있음을 확인했다. 또한 모델의 파라미터 수가 제한적인 경우, feature를 사용하는 것이 token만 사용 할 때보다 결과는 약간 더 좋았다. 그리고 이 둘을 결합하면 성능이 다시 향상 되는 이유는 token이 feature에서 누적 되는 오류를 잡아주기 때문이다.
결론 및 고찰
Eagle 역시 Medusa와 유사하게 draft 모델에 특정 레이어를 추가하여 사용하는 방식이였다. 뭔가 system처럼 작동하기 위해서는 이러한 layer 추가나 fine-tuning 없이도 speculative decoding이 가능했으면 좋겠는데, 아무래도 샘플링을 할 때 토큰 분포를 맞춰야 acceptance rate가 잘나와서 그렇게 하긴 어려워 보인다는 생각이 들었다.

학회 이름 오타아닌가요