이전 예제에서 활용한 Fully connected layer를 활용했을 때는,
-
이미지가 불명확하다, 픽셀 사이의 이어짐이 명확하지 않다
-
메모리 소비량이 크다
는 문제점이 있다.
또한 이미지 도메인에서는 지역화(localized)된 특성이 있다.
예를 들어 눈과 코를 나타내는 픽셀은 가까이 붙어있을 수 밖에 없고, 이러한 정보는 이미지가 얼굴임을 분류할 때 중요하게 작동한다.
즉, 신경망 분류기에서 이러한 정보를 고려할 수 있도록 디자인할 수 있을 것이다.
지금부터 이러한 지역성을 신경망에서 고려하는 법을 알아보려 한다.
합성곱 필터
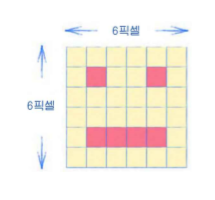
위와 같은 그림이 있을 때, 이를 2 x 2 픽셀 크기의 돋보기로 살펴보는 것이다.
제일 왼쪽 위에서, 돋보기를 겹치지 않게 이동시키면서
돋보기에서 눈, 입이 발견된 개수로 새로운 layer를 만들어내면 다음과 같다
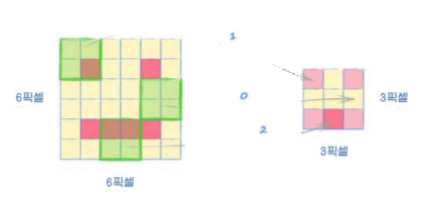
전체 이미지에서, 돋보기를 통해 더 좁은 지역의 정보를 요약하게 된 것이다.
다른 모양에서의 이미지에도 적용해보면 다음과 같다.
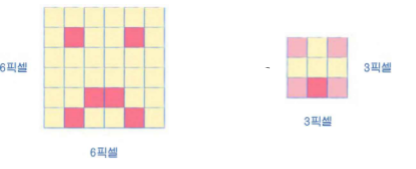
다른 얼굴형태의 이미지에 대해서, 같은 결과를 보이고 있는데 이것이 의미하는 바는
작은 변화에 민감하게 반응하지 않으면서도,
지역 특성은 잘 발견한다는 것이다.
이러한 돋보기를 합성곱 커널(convolution kernel)이라고 하고,
이를 사용하는 방법을 합성곱(convolution)이라고 한다.
그런데 합성곱 커널에도 사용 방법이 있는데,
발견된 픽셀에 가중치를 부여하는 것이다.
예를 들어 아래 그림에서 합성곱 커널은 상단에서 발견된 픽셀에 1을 곱하고 하단에서 발견된 픽셀에는 0을 곱한다.
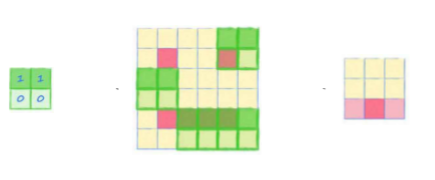
그러면 결과에서는 수평선이 있는 부분만 요약되는 편향이 생기게 된다.
즉, 가중치에 따라 어떤 패턴을 찾을 수 있게 된다.
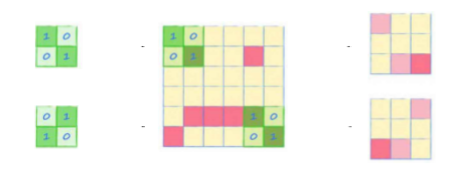
위 두 합성곱 커널의 결과는 각각 다른 대각선을 찾도록 편향되어 있다.
이렇게 합성곱 커널에 의해 요약된 레이어를 특성 맵(feature map)이라고 한다.
이러한 커널을 학습에 사용하면,
여러개의 커널의 가중치를 학습 과정에서 변경해가면서,
해당 문제의 도메인에서 가장 점수가 높은 커널을 찾을 것이다.
또한 커널들은 각각 여러가지 계층적인 수준을 지니고 있는 것이 도움이 된다.
어떠한 합성곱 커널은 간단한 패턴을 찾지만,
어떠한 합성곱 커널은 복잡한 패턴을 찾고
이러한 결과들을 모두 활용해야 한다.
지금 다룰 이야기는 아니지만, 이러한 커널들을 이용해서 신경망을 구성하는 합성곱 신경망(Convolutional neural network, CNN)이 분류 문제에서는 탁월한 효과를 보이고 있다.
cnn-mnist
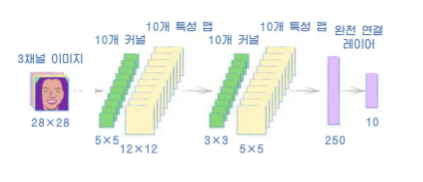
이전에 구현한 mnist 분류기의 모델 부분을 쉽게 합성공 신경망으로 변경할 수 있다.
self.model = nn.Sequential(
# 1개의 필터에서 10개의 필터로
nn.Cov2d(1, 10, kernel_size=5, stride=2),
nn.LeakyReLU(0.02),
nn.BatchNorm2d(10),
nn.LayerNorm(200),
# 10개의 필터에서 10개의 필터로
nn.Conv2d(10, 10, kernel_size=3, stride=2),
nn.LeakyReLU(0.02),
nn.BatchNorm2d(10),
View(250),
nn.Linear(250, 10),
nn.Sigmoid()
)nn.Conv2d 함수를 이용한다.
처음 매개변수는 입력 채널의 개수, 단색 이미지이므로 1이다.
출력 채널의 개수는 10을 지정했는데,
이는 10개의 특성 맵, 10개의 합성곱 커널을 만든다는 뜻이다.
kerner_size는 합성곱 커널의 크기, 즉 5x5 커널이 되며
stride는 보폭을 의미한다. 이미지를 따라 커널을 움직이는 정도를 의미한다.
stride에 대한 이해는 다음 그림과 같다.
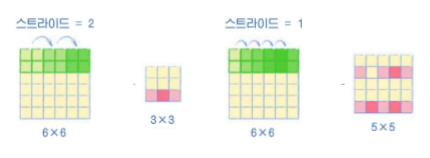
일반적으로 합성곱 출력 레이어에는 비선형 활성화 함수가 필요하다. 그래서 계속 사용하고 있는 LeakyReLU를 사용하고
특성 맵들에 정규화를 적용하는데 이제까지 사용하던 LayerNorm 대신 BatchNorm2d를 사용한다.
이 둘의 차이는
LayerNorm은 각각의 input에 대해서 정규화하는 것이고
BatchNorm은 batch에 있는 모든 input에 대해서 정규화하는 것이다.
즉 BatchNorm은 batch size에 영향을 받는다.
이 두개의 영향에 대해서는 좀 더 공부해봐야할 것 같은데,
일단은 이정도 차이가 있다는 점만 짚고 넘어가자.
첫번째 커널들을 지날때,
28x28 이미지에 대해서 5x5, stride 2 커널을 지나 생성된 특성 맵은 12x12이다.
그리고 이 특성 맵이 3x3, stride 2 커널을 지나
5x5 특성 맵이 생겨난다.
View(250)을 통해 바로 앞까지의 5x5 사이즈의 특성 맵 10개,
즉 10 x 5 x 5 개의 값 250개를 받아 다시 1차원 평탄화를 시키는 것이다.
이제 학습을 시켜야되는데,
이전의 mnist 예제는 픽셀값을 1차원 리스트로 바꿔놓았기 때문에, 이를 합성곱 신경망에 넣기 위해서는 다시 2차원 형태로 변경해야 한다.
파이토치의 합성곱 필터에 입력하기 위해서
batch_size, channels, height, width를 받기 때문에
(1, 1, 28, 28) 4차원 텐서로 변경해야 한다.
image_data_tensor.view(1, 1, 28, 28)
# create neural network
C = Classifier()
# train network on MNIST data set
epochs = 3
for i in range(epochs):
print('training epoch', i+1, "of", epochs)
for label, image_data_tensor, target_tensor in mnist_dataset:
C.train(image_data_tensor.view(1, 1, 28, 28), target_tensor)
이전에 완전 연결 신경망일때보다 더 빨라진 것을 확인할 수 있다.
C.plot_progress()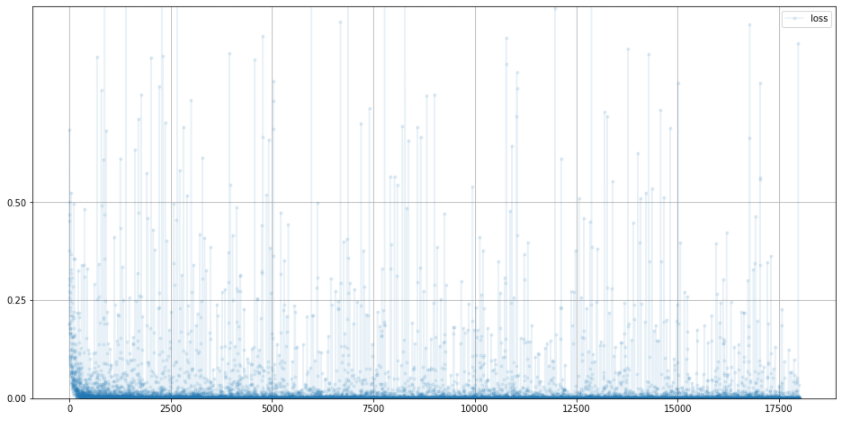
score = 0
items = 0
for label, image_data_tensor, target_tensor in mnist_test_dataset:
answer = C.forward(image_data_tensor.view(1,1,28,28)).detach().numpy()
if (answer.argmax() == label):
score += 1
pass
items += 1
pass
print(score, items, score/items)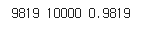
정확도가 98퍼센트로 향상된 모습
