앞서 만들어보았던 GAN에 CNN을 적용할 수 있다
이를 위해서는 약간의 수정이 필요하다.
def crop_centre(img, new_width, new_height):
height, width, _ = img.shape
startx = width//2 - new_width//2
starty = height//2 - new_height//2
return img[starty:starty+new_height, startx:startx+new_width, :]이미지를 임의의 사이즈로 crop해주는 일을 해주려고 한다.
def __getitem__(self, index):
if (index >= len(self.dataset)):
raise IndexError()
img = np.array(self.dataset[str(index)+'.jpg'])
img = crop_centre(img, 128, 128)
return torch.cuda.FloatTensor(img).permute(2, 0, 1).view(1, 3, 128, 128) / 255.0
def plot_image(self, index):
img = np.array(self.dataset[str(index)+'.jpg'])
img = crop_centre(img, 128, 128)
plt.imshow(img, interpolation='nearest')데이터셋을 구성할 때, crop 시켜주는 부분을 활용하고
CNN 커널을 이용하기 위해 4차원 형태(batch_size, channels, height, width)로 데이터를 구성한다
permute를 이용해 height, width, channels 형태로 구성된 기존 데이터를 channels, height, width 형태로 재배치하고,
view를 이용해서 맨 앞에 배치 크기 1을 추가해 차원을 추가한다
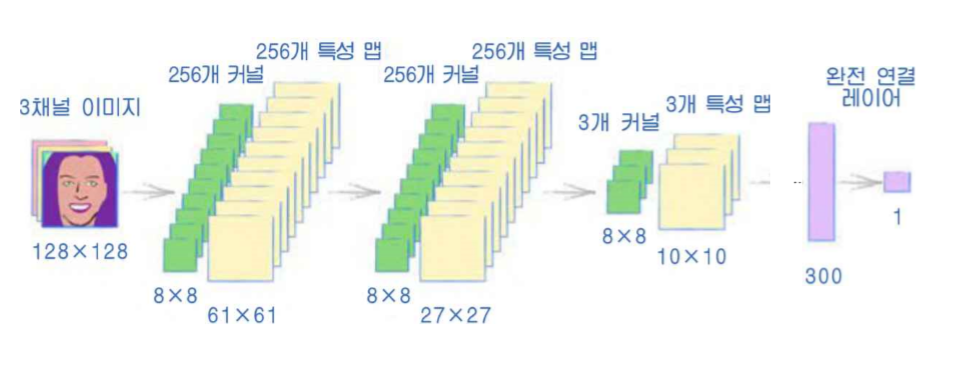
위 이미지는 이번에 구성할 CNN으로 구성된 GAN 구조도이다.
구조도대로, 이전에 구성한 판별기의 레이어를 다음과 같이 수정한다.
self.model = nn.Sequential(
nn.Conv2d(3, 256, kernel_size=8, stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 256, kernel_size=8, stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 3, kernel_size=8, stride=2),
nn.LeakyReLU(0.2),
View(3*10*10),
nn.Linear(3*10*10, 1),
nn.Sigmoid()
)이제 생성기를 수정해야하는데,
생성기는 거울처럼 판별기의 반대방향으로 작동해야한다.
합성곱의 반대방향을 전치 합성곱(transposed convolution)이라고 한다.
nn.ConvTranspose2d를 이용하면 된다.
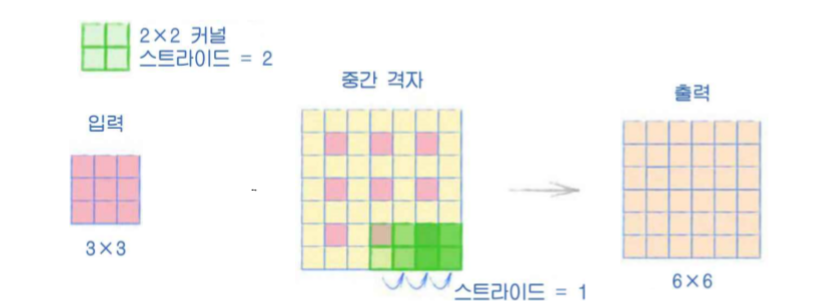
원본 입력을 커널 사이즈와 스트라이드를 고려하여 패딩(padding)을 진행한다. (커널의 스트라이드만큼 떨어뜨려놓고, 0으로 입력의 주변을 둘러 싼다)
그리고 이렇게 만들어진 중간 격자에 커널을 사용하여 출력 값을 만들어내는데, 이때의 스트라이드는 2가 아니라 1이다.
이렇게 구성해야하는 생성기의 구조는 다음과 같다.
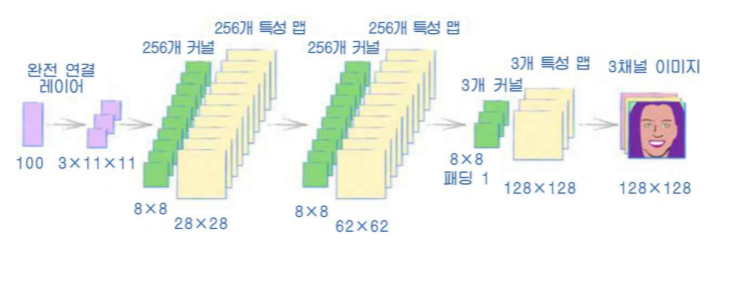
마지막 출력의 크기 128 x 128을 얻기 위해서 몇가지 고려해야할 사항이 있다.
- 맨 앞단의 시드값 100개로부터 3x11x11로 매핑하는 점
-> 설명이 부족하고, 검색해도 이유를 찾기 힘들었다. 그러나 앞에서 전치 합성곱의 원리를 생각하면 다음과 같은 이유일 것이다.
O : 패딩
X : 원본 입력
이라고 할 때,
입력을 한 라인만 보면,
OOOOOOOXOXOXOXOXOXOXOXOXOXOXOOOOOOO
와 같이 구성되어 있을 것이다.
이를 커널의 이동을 진하게 표시해보면
OOOOOOOXOXOXOXOXOXOXOXOXOXOXOOOOOOO
OOOOOOOXOXOXOXOXOXOXOXOXOXOXOOOOOOO
OOOOOOOXOXOXOXOXOXOXOXOXOXOXOOOOOOO
OOOOOOOXOXOXOXOXOXOXOXOXOXOXOOOOOOO
...
와 같이 이동해서 출력 레이어를 구성할 것이고,
이렇게 이동시키면 28의 사이즈가 나온다.
즉, 28x28 사이즈를 갖추기 위해서 11x11 사이즈를 선택한 것이다.
만약 커널의 사이즈가 바뀐다면 이또한 다른 사이즈로 설계되어야 할 것이다.
실제로 이러한 합성곱 네트워크를 정확한 사이즈로 설계하려면 몇번의 시도가 필요하다.
- 마지막 전치 합성곱 레이어에 패딩을 1 추가해야 한다.
이는 전치 합성곱 레이어가 중간 격자에서 바깥 테두리를 없앴기 때문에 보충해주어야 하는 것인데, 이런 과정을 추가해야 1, 3, 128, 128 형태를 얻을 수 있다.
위와 같은 과정없이 그냥 마지막에 완전 연결 레이어로 출력 크기를 맞추는 방법을 이용하지 않는 이유는, 이미지를 지역화된 특성, 즉 특성맵으로 만들고자 함이다.
다음은 생성기의 신경망 구성이다.
self.model = nn.Sequential(
# 먼저 입력 시드를 확장하고
nn.Linear(100, 3*11*11),
nn.LeakyReLU(0.2),
# 4차원 형태로 변환
View((1, 3, 11, 11)),
nn.ConvTranspose2d(3, 256, kernel_size=8, stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(256, 256, kernel_size=8, stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(256, 3, kernel_size=8, stride=2, padding=1),
nn.BatchNorm2d(3),
nn.Sigmoid()
)생성기로 임의의 이미지를 만들어 잘 만들어지는지 테스트하려면,
앞서 데이터셋을 구성할 때 파이토치 함수에 집어넣기 편하도록 permute를 이용해 행렬 구조를 바꿔주었던 것 처럼,
batch_size, channel, height, width 구조를
다시 batch_size, height, width, channel 구조로 바꾸어 준다.
G = Generator()
G.to(device)
output = G.forward(generate_random_seed(100))
img = output.detach().permute(0,2,3,1).view(128,128,3).cpu().numpy()
plt.imshow(img, interpolation='none', cmap='Blues')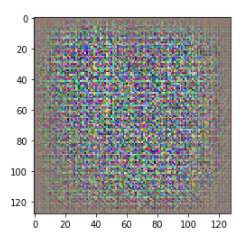
학습되지 않은 상태로, 임의의 이미지가 만들어진 모습인데,
임의의 이미지라기엔
가장자리가 어둡고, 체커보드 패턴(체스판 같은 패턴)이 나타난다.
전치 합성곱을 통한 이미지 생성에는 특성 맵이 겹치는 부분이 있어서, 이러한 형태가 나온다고 한다.
이제 1 에포크만 학습을 돌린 후, 임의의 시드값에 대해서 얼굴을 몇개 생성해보면 다음과 같은 결과를 얻을 수 있다.

D.plot_progress()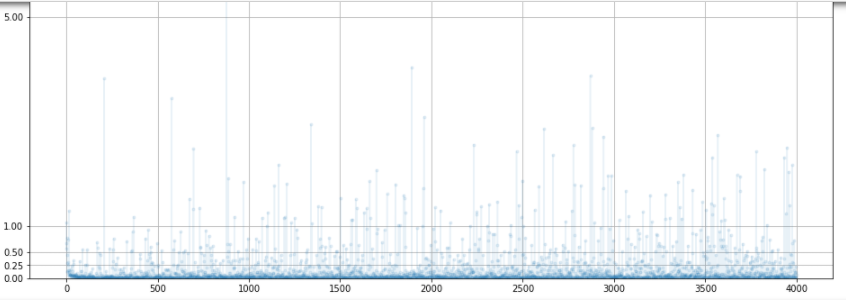
G.plot_progress()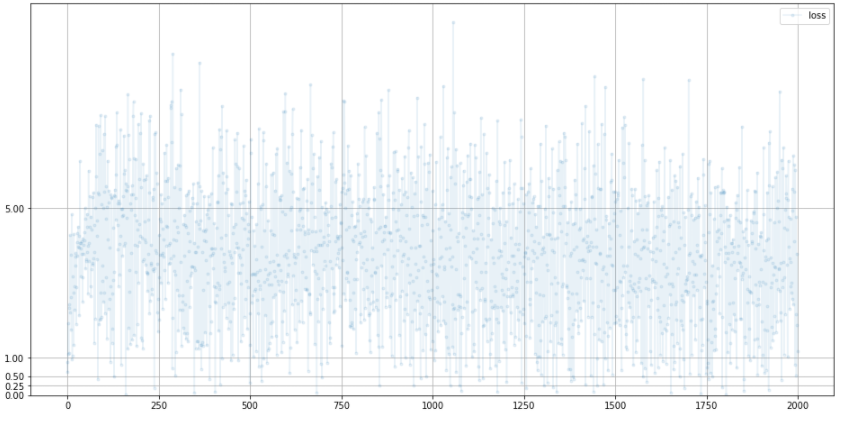
손실값은 BCE의 이상적인 값인 0.693보다 상당히 큰 편이다.
앞서 기본적인 GAN 구조의 얼굴 만들기에서 메모리를 측정하지는 않았는데, 강의 자료 기준에서는 CNN 구조를 추가하여 5배의 메모리 효율 향상을 보였다.
# current memory allocated to tensord (Gb)
print(torch.cuda.memory_allocated(device) / (1024*1024*1024))
# total memory allocated to tensors during program (Gb)
print(torch.cuda.max_memory_allocated(device) / (1024*1024*1024))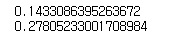
위와 같은 코드로 메모리 사용량을 확인할 수 있다.
모드 붕괴가 일어나지 않았다는 점이 상당히 고무적이다.
에포크를 늘림에 따라서 약간의 향상을 경험할 수 있지만,
간단한 네트워크 구조에서는 한계가 있다.
그리고 이미지가 한쪽 눈이 크다던지, 머리카락의 반이 다른 반대쪽이랑 모양이 다르다던지 하는 문제가 있다.
이는 완전 연결 GAN과는 달리, CNN이 부분적 정보에 집중했기 때문이다.
예를 들어 커널을 돋보기라고 생각하면, 돋보기에 얼굴 전체를 관찰하며 다음 그림을 생성한게 아니고, 한번에 눈 하나씩, 머리카락 반쪽씩만 들어오기 때문에
한쪽에서 만든것이랑 다른쪽에서 만든것이랑 연결, 관계성이 없기 때문이다.
GAN에 LeakyReLU 대신 GELU(Gaussian Error Linear Unit 함수를 사용하면 조금 더 좋은 결과를 얻을 수 있다고 하는데
이는 ReLU와 비슷하지만 조금 더 부드러운 곡선을 지니고 있다.
이 방법은 활성화 함수가 좋은 기울기를 제공하기 위해서는 함수 자체에 뾰족한 부분이 없어야 한다는 데에서 제안되었다고 한다.
다음은 에포크 12, LeakyReLU 대신 GELU를 사용한 결과이다.
아직 부자연스럽긴 하지만 훨씬 품질이 좋아졌다.

이외에도 몇가지 개선가능한 방법들이 있으나,
이번 예제는 GAN에 대한 이해를 하기 위함이므로
추후에 음성 합성까지 넘어갔을 때 적용해보기로 했다.
