[논문 리뷰] ViterbiNet: A Deep Learning Based Viterbi Algorithm for Symbol Detection - 1편
Abstract
Symbol detection은 digital receiver의 구현에 있어서 매우 중요한 역할을 한다. 본 논문에서는 channel state information (CSI)를 필요로 하지 않는 data 기반 symbol detector인 ViterbiNet을 제안한다.
ViterbiNet은 Viterbi 알고리즘에 deep neural networks (DNNs)를 적용시켜 만든 것이다. 저자는 channel model에 의존하는 Viterbi 알고리즘의 특정 부분을 식별하여 DNN으로 하여금 해당 연산만 하도록 설계했고, 그 외의 부분은 건들이지 않았다.
추가로 저자는 receiver가 매 coherence block 마다 새로운 training sample 없이 dynamic channel conditions를 추적하게 함으로써, 최근의 decision을 바탕으로 ViterbiNet을 실시간으로 학습하는 meta-learning 기반 approach를 제안한다.
논문의 실험 결과에 의하면 CSI를 모르는 상태에서의 ViterbiNet 성능이 CSI를 아는 상태에서의 Viterbi 알고리즘과 거의 비슷했고, 이를 통해 추가적인 training data나 순간 순간의 CSI 필요 없이 time-varying channel을 추적할 수 있다는 것을 알았다.
즉 기존의 Viterbi detection과 달리 ViterbiNet은 CSI uncertainty에 강인하고, 제한된 계산 복잡도를 사용해도 complex channel model에 대해 안정적으로 구현될 수 있다.
더 넓게 보면 논문의 결과를 통해, 기존에 있던 알고리즘에 DNNs를 합쳐 communication system을 설계하는 컨셉의 이득을 설명할 수 있다.
Introduction
Digital receiver의 가장 근본적인 task는 관찰한 channel output으로부터 송신 symbols를 잘 복원하는 것인데, 보통 이러한 task를 symbol detection 이라고 한다.
Maximum a-posteriori probability (MAP)를 기반으로 한 기존의 symbol detection 알고리즘은 underlying (내재된) channel 모델 및 그 parameter들에 대한 완전한 정보를 필요로 하는데, 그 결과 channel 모델이 매우 복잡하거나 system의 물리적 특성을 잘 반영하고 있지 않는 경우 잘 적용될 수 없다.
또한 channel 모델을 알고 있는 경우, 대부분의 detection 알고리즘은 detection을 위한 순간적인 channel state information (CSI) 즉, channel model의 순간적인 parameter들에 의존한다. 그러므로 기존의 방식을 사용하기 위해서는 순간적인 CSI를 잘 예측해야 하는데, 이를 위한 process는 overhead를 수반하여 data 전송 속도를 감소시키고 만약 추정한 CSI 값이 정확하지 않다면 detection performance를 떨어트리게 된다.
가장 잘 알려진 CSI 기반 symbol detection 방법 중 하나는 흔히 Viterbi algorithm 으로 알려진 iterative scheme 인데, 이는 Markovian input-output 확률 관계를 만족하는 channel (실제로 대부분의 channel이 이를 만족한다)에서 송신 symbol을 복원하는 것에 대한 error를 최소한으로 줄일 수 있는 효과적인 symbol detector 이다. Viterbi algorithm에서는 receiver가 channel의 input과 output에 대한 통계적 관계를 정확히 알아야 하기 때문에, full instantaneous CSI를 가지고 있어야 한다.
이를 대신할만한 data-driven 방식은 machine learning (ML), 그 중에서도 deep neural networks (DNNs)를 기반으로 한다. 기존의 model-based 방식에 비해 ML scheme을 사용하는 것에는 몇 가지 장점이 있는데, 이들은 다음과 같다.
첫 번째로 ML 방식은 내재된 (underlying) 확률 모델에 독립적이다. 따라서 모델을 모르거나 그것의 parameter를 정확히 추정할 수 없을 때 효과적으로 적용될 수 있다. 두 번째로 내재된 모델이 매우 복잡할 때, ML 알고리즘을 통해 관찰한 data로부터 유의미한 semantic information을 추출 및 분리될 수 있다는 것이 입증되었다. 이는 기존의 model-based 접근으로는 매우 해결하기 어려운 task 이다. 마지막으로 ML 기법은 model을 아는 상태에서 적용하는 iterative model-based 방식에 비해서도 종종 더 빠른 수렴 속도를 보일 때가 있다.
(그 외에도 DNNs을 활용하여 receiver design을 시도한 여러 논문들이 본 논문에서 소개되었는데, 관심이 있다면 직접 찾아보는 것을 추천한다.)
본 논문에서 저자는 Viterbi 알고리즘에 기반하여 finite-memory causal channels를 위한 ML-based symbol detector를 설계하는 것에 대해 연구한다. 설계는 일반적으로 model-based iterative 알고리즘으로부터 ML architecture를 얻기 위해 사용되는 deep unfolding 기법에 영감을 받았는데, 논문에서 활용한 방법과 기존의 방법에 근본적인 차이가 있다면 여기서 unfolding을 사용한 주된 이유는 알고리즘의 각 iteration을 layer로 변환하기 위함이었다는 것이다. (다시 말해, model-based 알고리즘에 비추어 DNN을 설계하는 것 혹은 이 대신 알고리즘을 DNN에 통합하는 것이 사용 이유)
저자는 CSI-based 연산을 특정 DNNs로 대체하여 channel에 대한 dependence를 제거함으로서 symbol detection을 위한 Viterbi channel-model-based 알고리즘을 구현한다.
ML을 Viterbi 알고리즘에 통합.
제안한 알고리즘의 이름은 ViterbiNet 으로, DNN 기반 sequence classifier의 특성들을 활용하여 CSI에 의존하는 Viterbi 알고리즘의 특정 연산을 구현한다. 구조 전체를 대체하는 등의 기존 ML 응용 방식과는 달리 Viterbi 알고리즘의 방식을 그대로 살릴 수 있다는 것이 특징인데, network의 구조가 간단하여 상대적으로 적은 수의 training samples로 학습될 수 있도록 구성되어 있다.
다음으로 저자는 meta-learning을 사용하여 channel의 통계적 모델이 바뀔 때마다 실시간으로 새로운 training data를 요구하는 것 없이, dynamic channel 환경에 ViterbiNet을 적용시키기 위한 방법을 제안한다. 제안한 방식은 각 decoded block으로부터 meta-training을 생성하기 위해 channel coding을 이용하는 것인데 이는 뒤에서 알아보도록 하자.
마지막으로 본 논문에서는 실험을 통해 ViterbiNet이 CSI-based Viterbi 알고리즘과 거의 같은 성능을 낼 수 있음을 실험으로 보였다. (그 외에도 Viterbi 알고리즘을 적용하기 어려운 특정 상황에서 ViterbiNet이 더 좋은 성능을 내는 것을 확인하는 등 network의 성능 검증을 위한 다양한 실험이 진행되었다.)
본문에 앞서 본 논문에서 사용될 notation을 정리하면 다음과 같다.
Notation
- Upper case letters for random variables (RVs): e.g.
- Boldface lower-case letters for vectors: e.g. (deterministic vector), (random vector), ( th element of )
- Probability density function (PDF) of an RV evaluated at :
- Set of integers: , positive integers: , real numbers:
- All logarithms are taken to base 2.
- For any sequence (can be multivariate) e.g. and integers :
is the column vector, and .
System Model and Preliminaries
본 section에서는 저자가 제시하는 system model과 기존의 Viterbi 알고리즘에 대해 리뷰해 볼 것이다.
System Model
본 논문에서는 finite-memory stationary causal channel을 따라 송신된, 개의 symbols로 이루어진 block을 복원하는 문제에 대해 다룬다.
이때 를 time index 에 송신된 symbol로 두자. 참고로 각 symbol은 개의 constellation points에 대해 uniform 하게 분포되어 있음을 가정하고, 이다. 또 는 time index 에서의 channel output을 의미한다.
앞서 channel이 causal 하고 finite memory를 갖는다고 가정했기 때문에 channel memory를 이라 했을 때, 를 와 확률적으로 mapping 할 수 있다. 이를 conditional PDF 식으로 정리하면 다음과 같다.
여기서 channel이 stationary 하다는 것은 와 각각에 대해 conditional PDF 가 index 에 의존하지 않는다는 것을 의미한다. 아래의 Fig 1 은 해당 system을 그림으로 나타낸 것이다.
Fig 1. System model.
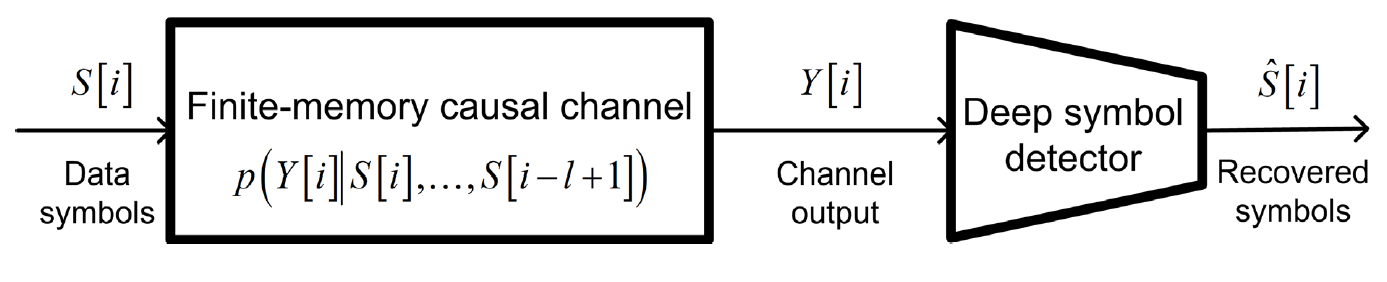
논문의 목표는 channel output 로부터 를 복원할 수 있는 DNN을 구성하는 것이다. 우리는 channel 등에 대해 앞서 가정한 것들 이외로 receiver 측에서 constellation 를 알고 있지만 conditional PDF는 모르고 있음 (= CSI 없음)을 가정한다. 한편 finite-memory channels만 생각했을때, 가장 optimal 한 detector는 Viterbi 알고리즘이다. 그러므로 DNN 설계에 앞서 Viterbi detection이 무엇이었는지 review 해보자.
Viterbi Detection Algorithm
앞서 constellation points가 나올 확률이 모두 동일함을 가정했기 때문에 error probability를 최소화 시키기 위한 optimal decision rule은 (MAP가 아닌) maximum likelihood decision rule을 따르면 된다.
즉 given channel output 에 대한 estimated output은 다음과 같다.
이때 다음을 정의하자.
그렇다면 의 log-likelihood 함수는 이전 subsection 에서의 conditional PDF 식을 활용하여 아래와 같이 표현할 수 있다.
이제 optimization problem은 다음과 같이 표현된다.
위의 최적화 문제는 dynamic programming을 각 time instance 에서의 가능한 송신 symbols 조합을 states 로 두고, 각 state에 대한 path cost 값을 반복적으로 update 하는 방식으로 적용하면 풀 수 있다.
Dynamic programming?
(동적계획법이름에 큰 의미를 부여하지 말자. 더 헷갈리는 듯하다.)
간단하게 말하면, 하나의 문제는 딱 한 번만 풀도록 만드는 알고리즘이다.
그렇게 푼 연산 결과를 어딘가에 저장한 뒤 필요할 때마다 불러 사용하는 구조인데, 이 블로그를 참조하여 구체적인 예시를 보면 더 빠르게 이해될 것이다.
Algorithm 1 은 이러한 Viterbi 알고리즘의 순서를 정리한 것이다.
Algorithm 1. The Viterbi Algorithm.

Error probability를 최소화 할 수 있다는 것 외에도 Viterbi 알고리즘에는 몇 가지 장점이 존재한다.
-
A1: 를 푸는데 필요한 computational complexity는 blocklength 에 대해 linear 하다.
(만약 직접 푼다면 complexity는 에 대해 exponential 하게 증가한다.) -
A2: 연속적으로 추정값을 그때그때 생성할 수 있다. 의 식을 보면 estimated output 는 received block 를 모두 이용해야 계산될 수 있는데, Algorithm 1 에서는 를 받으면 를 계산할 수 있다.
Algorithm 1 의 구현을 위해서는 모든 와 각 에 대해 를 계산할 수 있어야 하는데, 이는 결과적으로 channel의 conditional PDF를 알아야 한다는 것과 같다. (=Full CSI)
그런데 full CSI를 얻는다는 것은 매우 어렵기 때문에 다음 section에서는 CSI가 필요없는 Viterbi 알고리즘 기반 ML-based symbol decoder, ViterbiNet 을 알아보자.
ViterbiNet
Integrating ML into the Viterbi Algorithm
ML을 Viterbi 알고리즘에 합치기 위해 주목해야 할 점은 Algorithm 1 의 step 3에서 log-likelihood function 를 계산하는 과정에서만 CSI가 필요하다는 것이다. 각 에 대해 만 계산되면 Viterbi 알고리즘은 memory length가 인 channel에 대한 정보만 필요로 하고, 이는 channel의 input-output 간 통계적 특성을 정확히 (=Full CSI) 아는 것에 비해 훨씬 쉽다.
Channel은 stationary 하다고 가정했기 때문에 만약 이면, 각 에 대해 이다. 결론적으로 log-likelihood function 는 time index 가 아닌 오직 와 의 값으로만 결정된다. 따라서 저자는 제안한 모델에서 log-likelihood function을 계산하는 부분을, training data로 cost function을 평가하는 법을 학습하는 ML-based system으로 대체했다.
이때 system의 input은 이고, output은 의 추정값 이다. 또한 Viterbi 알고리즘의 나머지 부분은 그대로 둔다. 즉 detector는 를 계산하는 부분만 ML로 대체하고 나머지는 Algorithm 1 을 따른다. Fig 2 는 이를 그림으로 표현한 것이다.
Fig 2. Proposed DNN-based Viterbi decoder.
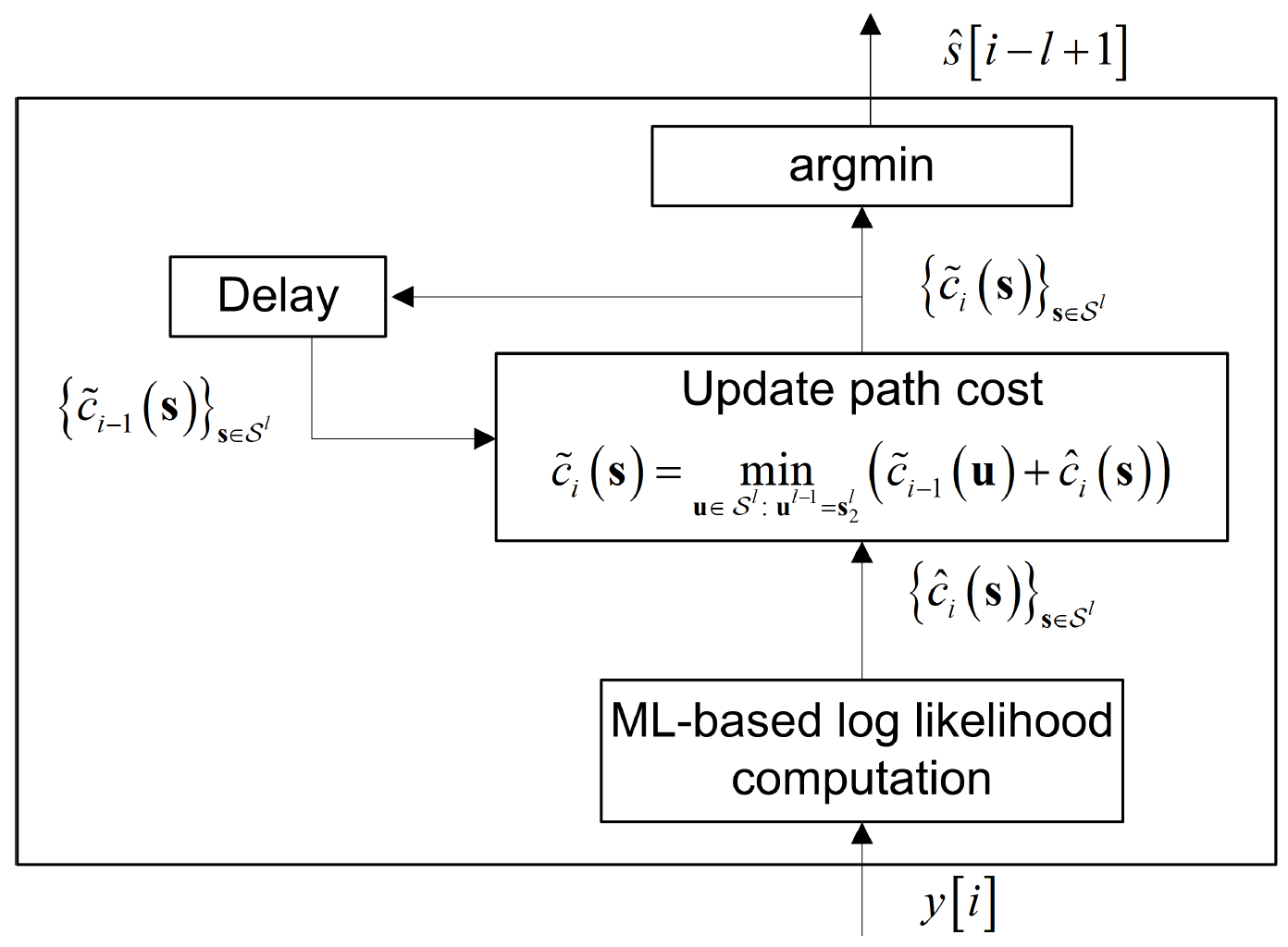
한편 를 이용하여 를 계산할 수 있는 network를 만드는 것은 매우 어렵다. 이는 가 given 에 대한 log-likelihood를 표현하기 때문인데, 일반적으로 cross entropy loss를 최소화 하도록 학습한 DNN에서는 given 에 대한 conditional distribution 즉, 를 출력한다.
e.g. Classification task in DNNs with input
Distribution of the label conditioned on the input
Distribution of the input conditioned on all possible values of the label
Viterbi 알고리즘을 구현하는데 필요한 정보는 이다. 이때 신경써야 할 점은 은 성립하지만 우리가 원하는 conditional PDF에 대해서는 이라는 것이다. 그러므로 여기선 softmax output layer를 적용한 기존의 DNN 구조는 적용할 수 없다.
이러한 어려움을 해결하기 위해 Bayes' theorem 을 생각해보자. Channel inputs에 대한 확률은 동일하므로 desired conditional PDF는 아래와 같이 표현할 수 있다.
따라서 우리는 각 에 대한 과 의 추정값만 주어진다면, 를 계산할 수 있다.
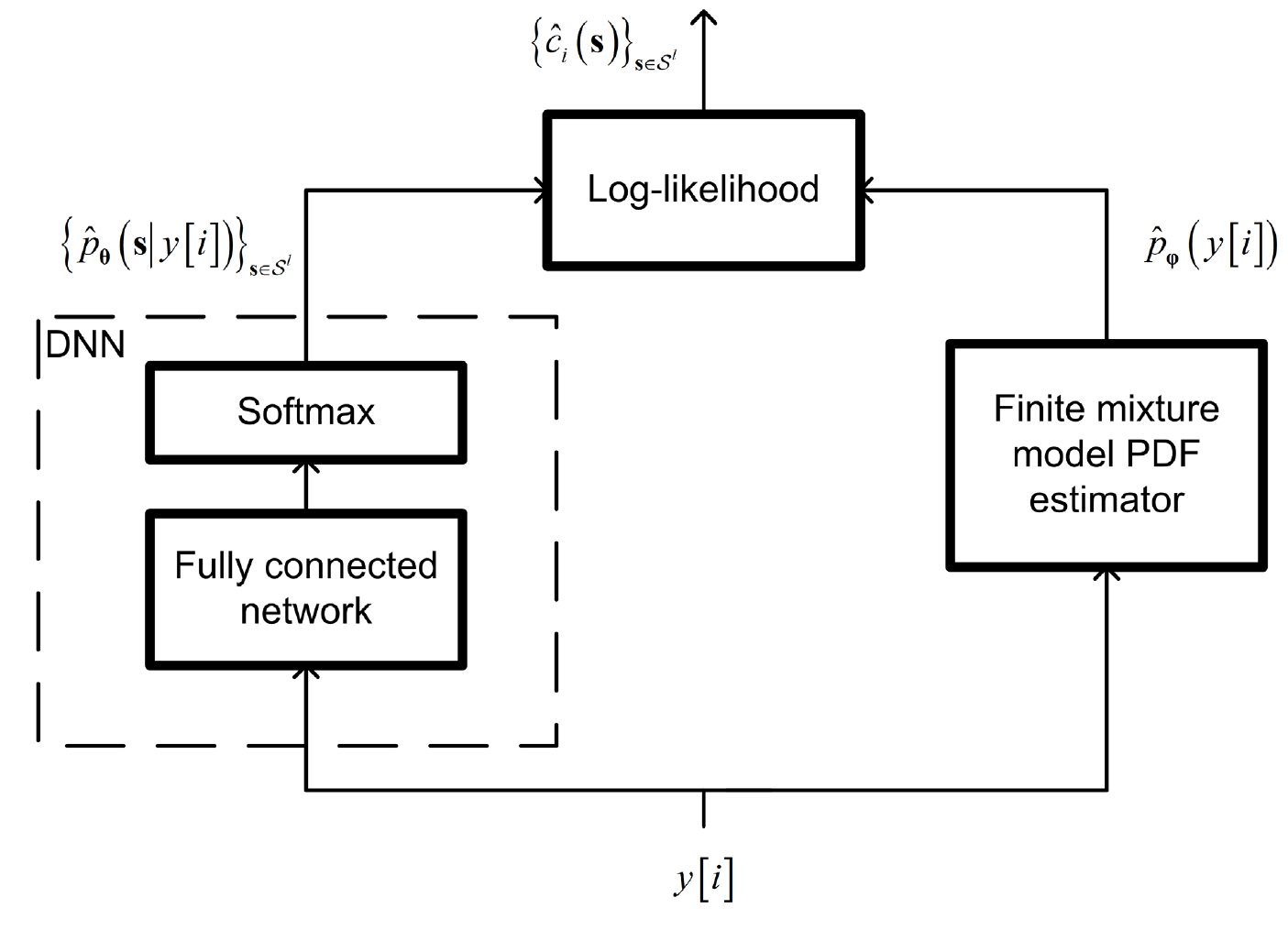
먼저 의 parametric estimate 는 softmax output layer를 사용하는 standard classification DNNs를 사용하면 training data를 통해 잘 얻어낼 수 있다. 마찬가지로 의 marginal PDF는 conventional kernel density estimation을 사용하면 training data를 통해 추정될 수 있는데, 가 를 이용한 stochastic mapping 이므로 해당 분포는 개의 kernel functions를 사용한 mixture model로 근사할 수 있다. (이 내용은 참조 논문을 직접 읽어봐야 할 것 같다. 결론은 의 parametric estimate 도 training data로부터 얻어낼 수 있다는 것이다.)
Fig 3 은 앞서 설명한 ML-based log-likelihood computation을 나타낸 그림이다.
Fig 3. ML-based log-likelihood computation.
이는 real-valued channel 와 complex channel에 대해 모두 적용될 수 있다.
이는 와 의 elements가 어떤 값 (real or complex)을 갖느냐에 따라 달라짐
참고로 complex-valued channel을 다룰때는 의 real & imaginary part로 구성된 real vector를 만들어서 DNN의 input으로 사용하면 된다.
Discussion
ViterbiNet의 구조는 finite-memory causal channel 상황에서 통신할 때의 error probability를 최소화 할 수 있는 Viterbi 알고리즘을 기반으로 한다. ViterbiNet은 data-driven 방식이기 때문에 full CSI 없이 training data로부터 log-likelihood function을 학습할 수 있고, 학습이 잘 되면 기존의 CSI-based Viterbi 알고리즘과 성능이 똑같을 것을 기대할 수 있다. (실제로 이후 section에서 실험을 통해 이를 보였다.)
또한 channel output이 주어진 상태에서의 transmitted symbol에 대한 조건부 확률을 추정하던 기존의 classification DNNs를 그대로 적용하지 않고, transmitted symbols가 주어졌을 때의 channel output에 대한 조건부 확률을 추정하도록 설계되었다는 것이 ViterbiNet의 큰 특징이다. 이러한 조건부 확률 분포는 finite-memory channel의 Markovian structure를 내포하여 원하는 log-likelihoods를 얻는 데 사용된다.
논문에서 강조하는 ViterbiNet의 특징은 다음과 같다.
ViterbiNet는 기존 Viterbi 알고리즘에서 사용하던 detection scheme은 모두 유지한 채 channel-model-based computation이 필요한 부분만, 이를 다루는 전용 ML method로 대체했다.
(그래서 상대적으로 simple 한 DNN 구조를 사용할 수 있기 때문에 overhead가 적다.)
(본 section에는 ViterbiNet의 특징을 적용할 수 있는 몇몇 task 및 논문들이 설명되어 있으니 관심이 있으면 읽어봐도 좋을 것 같다.)
한편 Viterbi 알고리즘을 기반으로 한다는 점으로 인한 drawback 도 분명히 존재한다. 예를 들어 constellation size 과 channel memory 이 매우 큰 상황을 생각해보자. Viterbi 알고리즘에서는 가 가질 수 있는 개의 values 각각에 대한 log-likelihood를 계산해야 되기 때문에, 이에 필요한 computation complexity는 과 이 늘어남에 따라 exponential 하게 매우 높아진다.
Beam search나 reduced-state equalization 같이, Viterbi 알고리즘의 complexity를 줄이기 위한 greedy schemes를 사용하면 약간의 performance degradation 만 발생한다는 것이 알려져 있는데, 저자는 이러한 방법들을 사용하여 ViterbiNet을 살짝 수정한다면 large , 이 주어진 상황에서도 complexity 문제를 해결할 수 있을 것으로 기대했고 이는 future work로 남겨두었다.
Reference
Shlezinger, Nir, et al. "ViterbiNet: A deep learning based Viterbi algorithm for symbol detection." IEEE Transactions on Wireless Communications 19.5 (2020): 3319-3331.
