[논문 리뷰] Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks - 1편
오랜만에 하는 논문 리뷰이다.
어떤 주제로 포스팅을 할까 하다가 최근 들어 meta learning 이라는 용어를 많이 접하기도 했고, 실제로 요즘 주목받고 있는 기술이라는 생각이 들어 meta learing의 기본이 되는 논문을 찾아보았다.
그렇게 해서 찾은 논문을 이번 포스팅에서 다뤄보려고 하는데, 이번 리뷰에서는 논문에 대한 세세한 정리보다는 '그래서 meta learning이 무엇인가?' 에 최대한 초점을 맞춰볼 것이다.
따라서 생략하는 부분이 많을 수 있는데, 글을 읽다가 더 자세한 내용이 알고 싶다면 reference 논문을 꼭 찾아보도록 하자. (논문에 명시된 실험에 대한 setting이나 내용 설명 등이 친절한 편인 것 같다.)
글에 앞서서 'Model-Agnostic' 의 의미는 무엇일까?
Agnostic: [명사] 불가지론자
...? 침착하자.
(나무위키를 참고한 결과) 불가지론 이란, 신 (절대자)의 존재를 논할 때 취할 수 있는 두 가지 입장; '신은 존재한다 (유신론) vs 신은 존재하지 않는다 (무신론)' 에 대해 모두 고려해 본 결과 판단을 미뤄 놓은 상태를 의미한다. 다시 말해 해당 명제에 대해 현재로서는 답할 수 없다는 결론을 낸 중간적인 입장 을 뜻한다.
이를 고려하여 Model-Agnostic 이라는 용어를 의역해보면, '모델이 정확히 어떤지는 모르겠는데 그냥 신경 안 써도 되는' 정도로 해석할 수 있을 것 같다.
Abstract
본 논문에서는 model-agnostic 한 상황에서 적용할 수 있는 meta-learning algorithm을 제안한다. 여기서 model-agnostic 이라는 표현을 사용한 이유는 두 가지인데 먼저 gradient descent를 사용하여 학습하는 모든 model들과 호환될 수 있기 때문이고, 두 번째로 classification이나 regression, reinforcement learning (RL) 등을 포함한 다양한 learning 문제들에 적용할 수 있기 때문이다.
한편 meta learning의 목표 는 모델을 다양한 learning task들에 대해 학습하여, 적은 수의 학습 sample 들만을 사용하더라도 새로운 learning task를 해결할 수 있도록 만드는 것 이다.
논문에서는 이를 위해 model의 parameter들을 학습시켜, 새로운 task로부터 학습 데이터를 조금 받아오더라도 몇 번의 gradient steps만 거치면 해당 task에 대한 일반화를 잘 할 수 있도록 한다.
사실 논문의 방식은 model이 쉽게 fine-tune 될 수 있도록 학습하는 것인데, 논문에서는 해당 방식을 사용하여 앞서 언급한 classification / regression / RL 등에서 SOTA 수준의 성능을 낼 수 있음을 입증하였다.
Introduction
빠르게 학습하는 것은 '인간 지능'의 큰 특징이다. 예컨대 사람은 적은 수의 예시를 보고도 해당 물체가 무엇인지 정확히 판단할 수 있으며, 새로운 기술을 몇 분 남짓 배워도 금방 익힐 수 있다. 그런데 과연 artificial agent (기계)도 인간처럼 적은 수의 예시로부터 빠르게 학습하여 적응하는 이러한 능력을 얻을 수 있을까?
앞서 언급한 빠르고 유연한 학습은 상당히 어려운 주제이다. 왜냐하면 agent 입장에서 적은 정보만을 가지고 학습한다면 이전의 경험에 의존할 수 밖에 없는데, 이렇게 되면 새로운 data에 대처할 수 없도록 쉽게 overfitting 될 수 있기 때문이다. 또한 task에 따라 이전 경험과 새로운 data의 형태는 달라진다.
따라서 적용 가능성을 최대로 만들기 위해서는 meta learning에 사용하는 mechanism이 task와 task 완성에 필요한 계산 형식에 일반화 되어야 한다.
(여기서 meta learning을 learning to learn 이라고도 표현했다. 학습을 위한 학습을 진행한다 정도로 이해하면 좋을 것 같다.)
본 논문은 general 하고 model-agnostic 한 meta-learning 알고리즘을 제안한다. 이러한 표현은 gradient descent로 학습하는 모델과 모든 learning problem에 바로 적용될 수 있다는 맥락에서 사용되었다. (Deep neural network 즉, DNN 모델에 초점을 맞춤)
Meta learning에서 학습된 모델의 목표는, 적은 양의 새로운 data로부터 새로운 task를 빠르게 배우는 것이다. 논문에서 제안하는 방법의 핵심 idea는 다음과 같다.
Key idea:
새로운 task에서 적은 양의 data를 사용하여 한번 혹은 그 이상의 gradient updates를 진행한 parameter가, 해당 (새로운) task에서 최대한의 performance를 보여줄 수 있도록 model의 initial parameter를 학습하는 것
(이전 연구로는 update function이나 learning rule 등을 학습하는 meta learning 방법들이 있었다고 한다.)
이렇게 몇 번 안되는 (심지어 한번의) gradient steps을 거쳐 새로운 task에 대해 좋은 결과를 내는 model parameter 학습 과정은, feature learning의 관점에서 많은 task들에 대해 광범위하게 적합한 internal representation을 세우는 것으로도 볼 수 있다.
만약 이러한 internal representation이 잘 만들어졌다면, 우리는 parameters를 살짝 fine-tune 해주는 것만으로 좋은 성능을 낼 수 있을 것이다.
실제로 논문의 방식은 fine-tune이 빠르고 쉬운 모델에 최적화 되는데, 학습 process는 parameter에 대해 새로운 task의 loss function이 갖는 민감도 (sensitivity)를 최대화 하는 것으로 볼 수 있다.
Model-Agnostic Meta-Learning
우리의 목표는 빠르게 적응할 수 있는 model을 학습하는 것인데, 이러한 problem setting은 종종 few-shot learning 이라고도 불린다.
이 section에서는 논문의 problem setup에 대해 정의하고, 알고리즘을 general 한 형태로 나타낼 것이다.
Meta-Learning Problem Set-Up
Few-shot meta learning의 목표는 적은 수의 training iteration과 data points 만을 사용하여 새로운 task에 빠르게 적응할 수 있는 모델을 학습하는 것이다. Meta learning problem에서는 전체 task들을 training example로 다루는데, notation을 정의하여 조금 더 자세히 알아보자.
Notation explanation
Model which maps to , Observation, Outputs
Task, Distribution over tasks
Loss function, Episode length
Distribution over initial observation, Transition distribution
본 파트에서의 설명은 일반적인 task에 대한 포괄적인 내용임을 기억하자.
먼저 각 task는 다음과 같이 이루어져 있다.
(cf, I.I.D. supervised learning problem 에서 )
이에 대해 모델은 각 시간 에서 output 를 골라, 의 길이를 가진 sample들을 만들 것이다. 또한 loss 은 각 task에 특화된 feedback을 제공한다.
(e.g., Markov decision process를 따르는 cost function 혹은 misclassification loss function 등의 형태)
한편 저자는 논문의 meta-learning scenario에서, 모델이 적응했으면 하는 task의 분포 를 고려한다.
-shot learning setting을 생각해보면, model은 로부터 뽑힌 개의 sample 과 에 의해 만들어진 feedback 를 이용하여, 를 따라 선택된 새로운 task 를 배우도록 학습된다.
Meta-training의 과정 동안 task 는 로부터 sampling 되고, model 는 개의 sample과 그에 상응하는 loss 의 feedback을 통해 학습되어서 의 새로운 sample들로 test 된다. Model은 이후, 를 따르는 새로운 data에 대한 test error가 parameter들에 따라 어떻게 변화하는지를 반영하여 발전한다. 즉 sampled tasks 에서의 test error는 meta learning process의 training error 역할을 한다.
Meta-training이 끝나면, 로부터 새로운 tasks가 sampling 되고, 개의 sample들을 사용한 학습 이후의 model 성능으로 meta performance가 측정된다.
참고로, 보통 meta testing에 사용되는 task들은 meta training 중에 사용된다.
A Model-Agnostic Meta-Learning Algorithm
논문의 아이디어는 다음의 직관을 바탕으로 한다.
어떠한 internal representations 보다도 더 빨리 바뀔 수 있는 representations가 존재할 것이다.
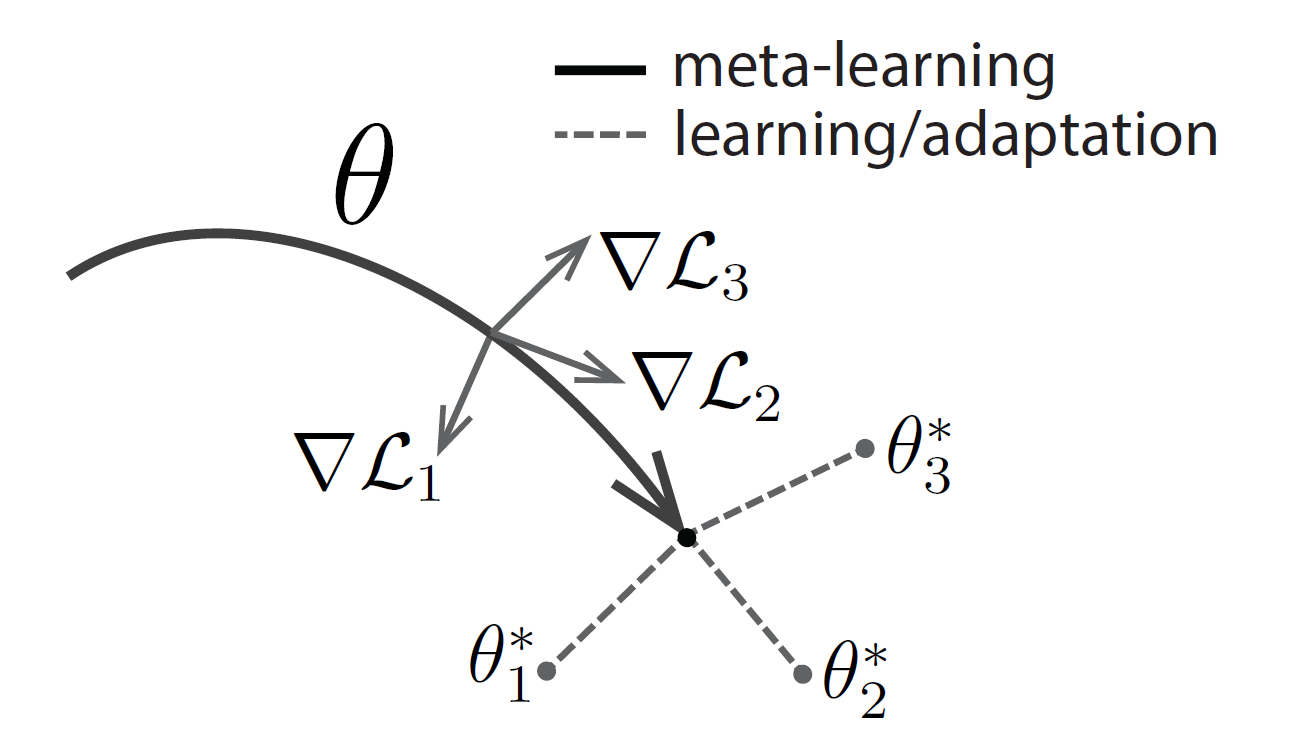
따라서 저자는 로부터 가져온 어떠한 task의 loss function에 대해서도, 해당 loss의 gradient 방향으로 변경될 때, parameter의 작은 변화가 성능의 큰 개선을 만들 수 있는 sensitive 한 model parameters를 찾는 것을 목표로 한다. 아래의 그림을 통해 이를 조금 더 잘 이해해보자.
Fig 1. Diagram of MAML algorithm which optimizes for a representation that can quickly adapt to new tasks.
(이말인즉슨, 새로운 어떠한 task로든 빠르게 적응할 수 있는 representation 를 찾기 위한 최적화가 MAML 알고리즘을 통해 이루어진다는 것)
(1, 2, 3은 각 task를 지칭하는 번호이다.)
이번에는 식을 통해 정리해보자. 설명에 앞서, 저자는 parameter vector 를 사용한 parameterized function 로 model을 표현한다.
만약 model이 새로운 task 로 적응하는 상황을 생각해보면, model의 parameter는 에서 다른 값으로 update 될 것인데 그 변수를 로 두자. 논문의 방식에 의하면 이 updated parameter vector 는 에 대해 한번 혹은 그 이상의 gradient descent updates를 통해 계산된다. 예를 들면 한번의 gradient update를 사용했을 때의 식은 아래와 같다.
이때 step size 는 hyperparameter로 고정될 수도 있고, meta learning 될 수도 있다.
(Notation의 편의를 위해, 논문에서는 이후의 모든 section에서 한 번의 gradient update 상황을 가정한다.)
또한 parameter는 에 대한 의 performance를 최적화 함으로써 학습되는데, 이를 아래와 같은 meta-objective로 표현할 수 있다.
주의할 점:
Meta optimization은 model parameters 에 대하여 수행.
반면 objective는 update 된 model parameters 를 이용하여 계산.
Task에 대한 meta optimization은 SGD를 통해 수행되기 때문에 는 아래의 식을 따라 update 된다. 여기서의 는 meta step size라고 한다.
일반적인 경우에 대한 전체 알고리즘은 다음과 같다.

MAML meta gradient update는 gradient를 통한 gradient 계산을 포함하고 있다. 따라서 Hessian vector의 계산을 위해 우리는 에 대한 추가적인 backward pass가 필요한데, 이는 TensorFlow와 같은 DL library 들로 구현했다 한다.
논문 후반부에는 approximation을 사용하여 backward pass를 drop한 경우의 성능도 소개되었다 하니 관심이 있으면 찾아보자.
Species of MAML
Supervised Regression and Classification
Few-shot learning은 supervised task에서 잘 알려져 있는 분야이다. 여기서의 목표는 비슷한 task들로부터 얻은 prior data를 meta learning에 사용하여, input/output pair가 거의 없는 상황에서도 원하는 task를 해결할 수 있는 새로운 함수를 학습하는 것이다.
Classification에 대한 예를 먼저 들면 강아지 사진을 분류하는 것이 목적일 때, 강아지 사진을 한번 혹은 그 이상 (하지만 적게)만 보고 난 후에도 분류를 잘 하는 것이 목적이다. 이때 사용되는 모델은 이전에 다양한 유형의 objects를 많이 보았음을 가정한다.
Regression 예시의 경우, 원하는 연속 함수와 통계적 특성이 비슷한 함수들을 많이 이용하여 학습을 진행한 뒤, 해당 (원하는) 함수에서 sampling 된 data points 몇 개만을 이용하여 output을 예상하는 것이 목적이다.
이제 방금 언급한 두 가지 문제에 앞선 section에서 정의한 meta learning의 정의를 대입해보자. 이를 위해 몇 가지 설정이 수정되는데, 먼저 여기서 이다. 또한 에서 timestep 는 고려할 필요가 없어지는데, model이 input 및 output에 대한 sequence를 받는 것이 아닌 single input/output을 다루기 때문이다. 또한 task 는 로부터 개의 i.i.d. observations 를 생성하고, task loss는 에 대한 model의 output과 target value 사이의 error로 표현된다.
한편, supervised classification 및 regression에 가장 자주 사용되는 두 가지 loss function은 cross-entropy 와 MSE 이다.
Regression tasks에서 사용하는 MSE의 loss 함수 form은 다음과 같다.
이때 와 는 task 로부터 sampling 된 input/output pair를 의미한다.
비슷하게 cross-entropy loss를 사용하는 discrete classification task에서의 loss 함수 form은 다음과 같다.
주어진 distribution 하에서 위의 loss function들은, 앞선 (Fig 1 이 포함되어 있는) section에서 설명했던 일반화 된 형태의 수식에 바로 대입되어 meta learning에 적용될 수 있다.
이에 대한 알고리즘은 아래와 같다.

Reinforcement Learning
RL에서 few-shot meta learning의 목적은 다음과 같다.
Agent가 test setting에서 적은 수의 experience 만을 사용하여, 새로운 test task에 대한 policy를 빨리 획득할 수 있게 만드는 것

본 포스팅에는 알고리즘만 첨부했으니, 보다 자세한 내용은 논문을 참고하자.
Reference
Finn, Chelsea, Pieter Abbeel, and Sergey Levine. "Model-agnostic meta-learning for fast adaptation of deep networks." International Conference on Machine Learning. PMLR, 2017.
Few-shot learning (+-way -shot 문제)에 대해 잘 소개한 블로그: https://www.kakaobrain.com/blog/106

잘 읽고 갑니다. 감사합니다.