논문명 : Constrastive Vision-Language Alignment maskes Efficient Instruction Learner
링크 : https://arxiv.org/abs/2311.17945
출간일 : 2023.11.29
저자 : Lizhao Liu, Xinyu Sun, Tianhang Xiang, Zhuangwei Zhuang, Liuren Yin, Mingkui Tan,
소속 : South China University of Technology, PengCheng Laboratory, Duke University
인용 수 : 1
코드 : https://github.com/lizhaoliu-Lec/CG-VLM (coming soon..)
Abstract
- 주제 : LLM 모델을 vision-language instruction-following 모델로 확장 = LLM이 이미지를 더 효과적으로 이해하고 처리할 수 있게끔 한다
- Challenge
- 텍스트만 학습된 LLM에 어떻게 이미지 정보를 효과적으로 학습시키는가
- 핵심 Task
- ViT와 LLM 간의 표현을 최대한 일치시키기
- Generative image caption loss를 활용하여 Visual adapter 학습
→ 이미지 세부 사항을 학습하기 어려움 - ViT와 LLM의 표현을 최대한 일치시켜 세부적인 연관성에 대해 학습한다
→ Contrastive + Generative
→ 이미지 patch 수준의 특징과 텍스트 토큰 수준의 임베딩 정렬 - Image-caption dataset에서 패치-토큰 관계가 제공되지 않음
→ 이미지 패치 특징과 텍스트 토큰 임베딩 간의 평균 유사도 최대화
- Generative image caption loss를 활용하여 Visual adapter 학습
- ViT와 LLM 간의 표현을 최대한 일치시키기
Introduction
- 기존 연구
- pre-trained ViT와 LLM을 결합하여 복잡한 비전 지시 작업을 수행
(CLIP의 pre-trained ViT를 주로 이용) - Image-Text 정렬 단계가 필수적, vision adapter를 학습하여 정렬
- ViT의 vision 특징 → vision adapter → LLM embedding space → LLM input → caption loss로 최적화
- Heavy-weight adaption
- Q-Former
- Light-weight adaption
- MLP layer
- Heavy-weight adaption
- ViT의 vision 특징 → vision adapter → LLM embedding space → LLM input → caption loss로 최적화
- 한계
- 디테일 부족
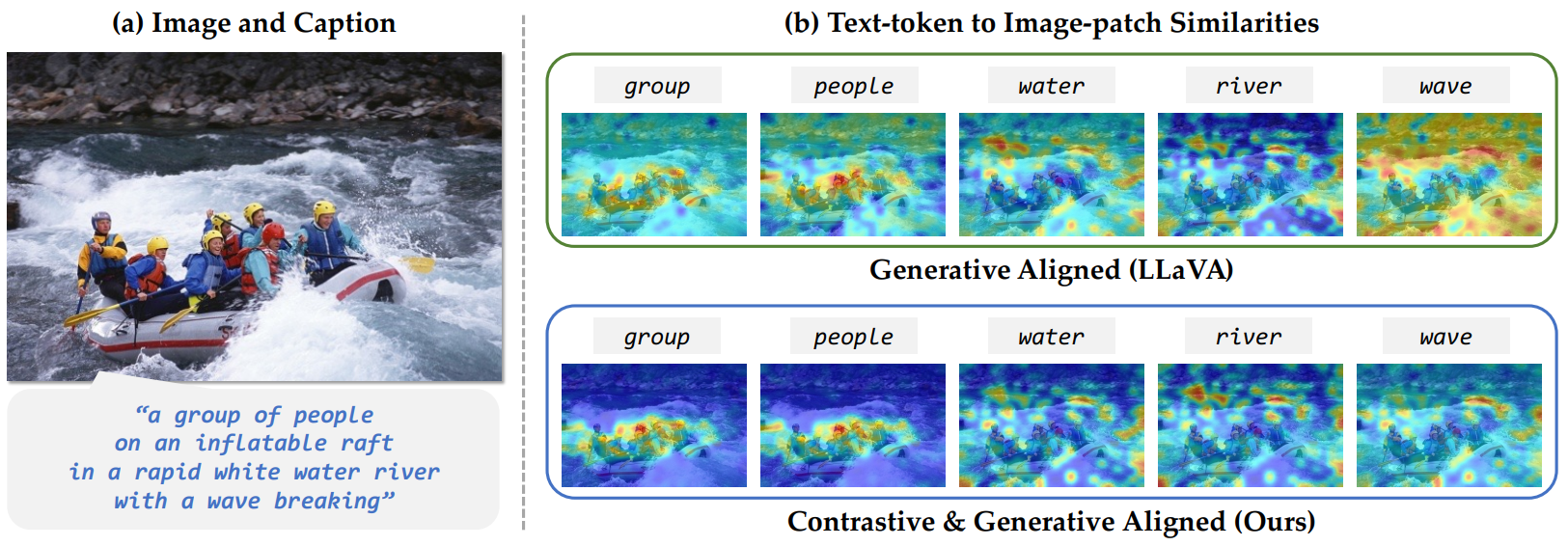
- 디테일 부족
- pre-trained ViT와 LLM을 결합하여 복잡한 비전 지시 작업을 수행
- 제안 : Contrastive and Generative Aligned VLM
- Vision-Language 정렬 문제를 분석한 최초의 연구
- Vision-Sentence 유사도에서 Contrastive + Generative 사용
- 튜닝 데이터가 1/10 수준에서 기존 방법들과 동등한 결과
- LLM layer의 평균 토큰 임베딩은 문장간의 의미를 모호하게 함
= 토큰 임베딩을 평균화할 때 각 토큰의 의미와 문장의 세부 의미가 유지되기 힘들다 - Vision feature와 Sentence token feature 간의 유사도를 평균화 : vision-sentence similarity
- Vision-Sentence similarity 최적화
- 단, 전체 맥락에 대한 집중도 떨어짐
- LLM layer의 평균 토큰 임베딩은 문장간의 의미를 모호하게 함
Method
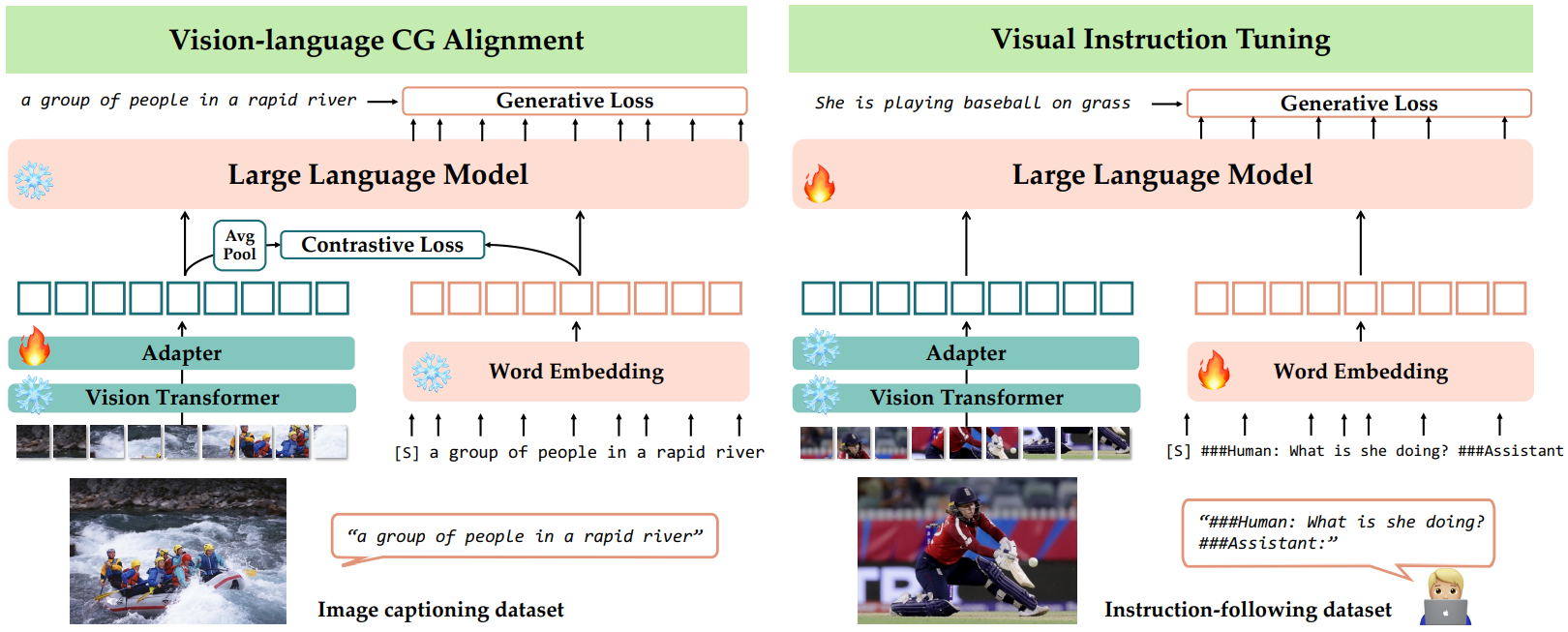
- Vision Adapter 학습
- Generative loss
- Image caption 데이터
- 입력: 시각 특징, 접두어 시퀀스 ()
- LLM 다음단어() 예측
- loss 최적화
- Contrastive loss
- Global descriptor : 각 패치의 특징에 averave pooling 적용 (batch 단위)
- Image descriptor : 이미지 벡터
- Word embedding
- 모든 와 간의 유사도 계산
- Contrastive loss 도출
- Global descriptor : 각 패치의 특징에 averave pooling 적용 (batch 단위)
- Contrastive & Generative alignment loss ( : 최적화 강도 파라미터)
- Generative loss
- ViT를 제외한 전체 모델 튜닝 (vision 명령 이행 능력)
Experiments
-
Dataset
- LCS558K (이미지-캡션)
- LLaVA1.5에서 생성된 665K의 무작위 1% ~ 10%
-
Pre-trained models
- ViT : CLIP ViT
- LLM : Vicuna 13B
-
A800 8개
-
Training Details
- Visual adapter : MLP module (linear layer x2, GELU 활성함수)
- (최적화 파라미터) : 1.0 고정
- Learning rate : 사전학습(), 미세 조정()
- Scheduling : 0.03 웜업 비율의 cosine scheduler
- Epoch : 1epoch
-
Results
-
Object Detection
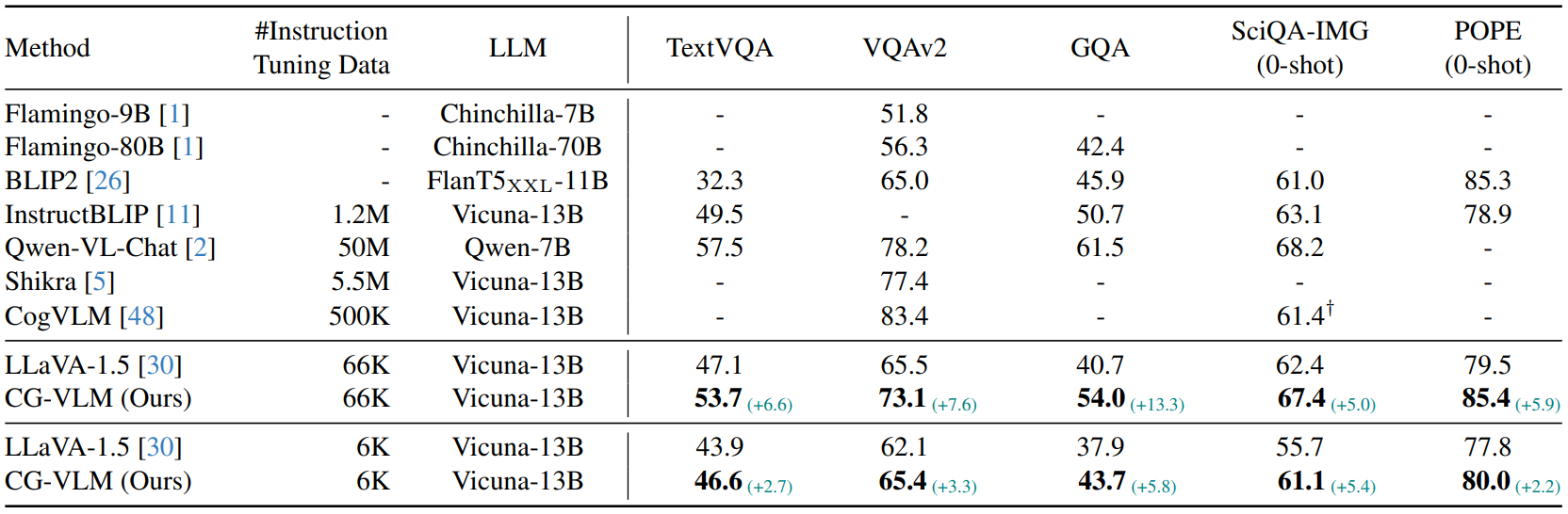
-
Instruction-following
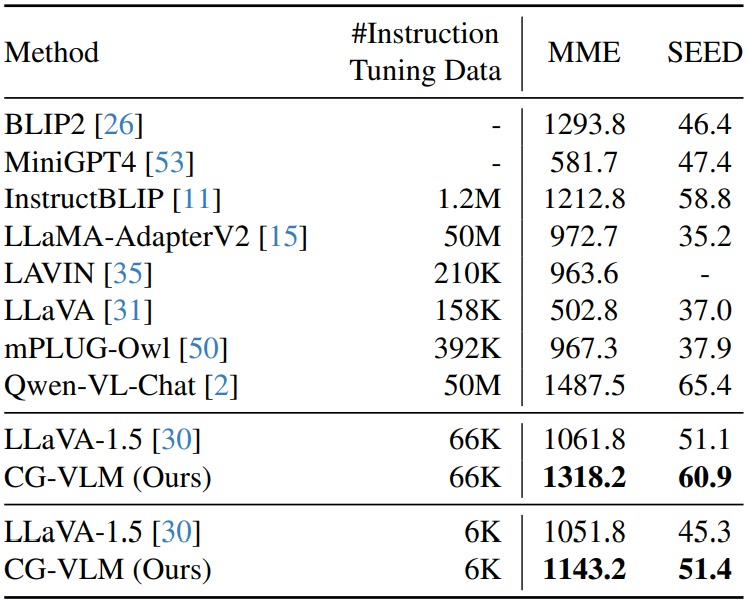
- MME : 인식 점수
- SEED : 이미지셋 정확도
-
Ablation test
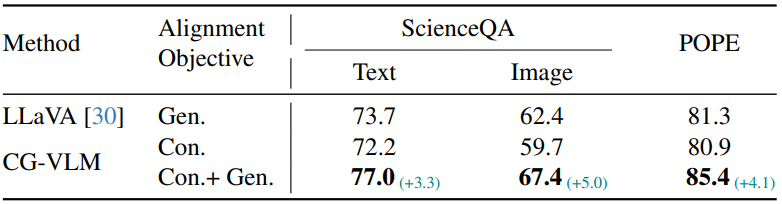
-
Pre-train data amount test
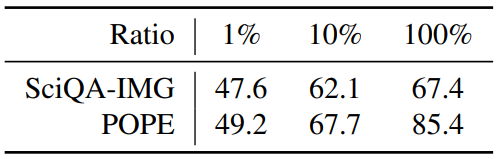
-
Conclusion
- Vision-Language 정렬 문제에 대해 연구함
- Contrastive loss와 Generative loss를 결합하는 형식을 제안함
- 향후 연구
- 이미지 패치와 텍스트 토큰 간의 연결성을 고려하여 Contrastive에 대해 연구

Hey