논문명 : Classification Done Right for Vision-Language Pre-Training
링크 : https://arxiv.org/abs/2411.03313
출간일 : 2024.11.06
저자 : Zilong Huang, Qinghao Ye, Bingyi Kang, Jiashi Feng, Haoqi Fan
소속 : ByteDance Research
인용 수 : 0
코드 : https://github.com/x-cls/superclass
Vision encoder를 사전 학습할 때 사용되는 컴퓨팅 자원을 줄이는 방법에 대한 연구
Abstract
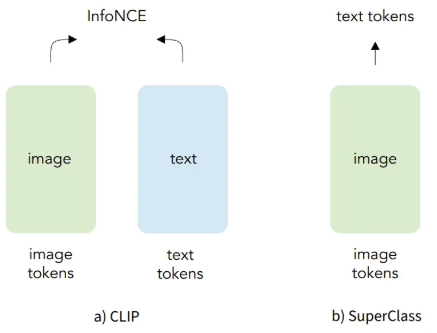
- SuperClass
- Vision-Language Pre-Training을 위한 매우 간단한 image-text 데이터 분류 방법
- 토큰화된 raw text를 분류 라벨로 사용
- Contrastive를 위한 text encoder를 필요로 하지 않음
- Batch size에서도 이점을 가짐
- Vision-Language Pre-Training을 위한 매우 간단한 image-text 데이터 분류 방법
- 평가
- Benchmarks와 downsteam tasks를 수행한 지표
- CLIP과 계속 비교하면서 더 나은점을 찾아감
Related Works
- Text를 분류 라벨로 사용
- 명사를 추출하여 단어를 카테고리로 사용
- Gold Label 필터링
- 예시) Tag2Text, RAM, CatLIP
- Image-Text Contrastive learning
- CLIP
- Image-Text을 Contrastive하는 pre-train model
- 강점
- Zero-Shot, Recognition, Finetuning에 이점
- 학습 데이터량에 비례한 성능
- 이미지와 텍스트를 연관지어 이해하는 Vision Backbone
- 단점
- 대규모 Batch-size 필요
- Text encoding을 위한 자원 필요
- 예시) SigLIP, InternVL
- CLIP
- Autoregressive target으로 text 활용
- Caption을 pretraining에 사용
Introduction
-
문제점
- Image-Text 데이터를 이해하기 위한 Text encoder
- Contrastive를 위한 대규모 Batch-size
-
주요 과제
-
대규모 Image-Text 쌍의 pre-train을 위한 분류 방법
⇒ 컴퓨팅 자원에 대한 부담 감소
-
Method
-
개요
- 이미지 분류 기반의 pre-training 방법 구축 (간단함, 확장성, 효율성)
-
ViT backbone - Vision encoder
-
Global average pooling layer
-
Linear layer for Logit vector ()
-
Classification loss with IDF
-
Text as Labels
- 학습 데이터로 쓸 라벨을 만드는 과정
- Tokenizer → Sub words → ID vector → K-hot label
- Tokenizer
- CLIP, BERT에서 사용되는 sub word level tokenizer
- Sub words
- “unhappiness” → “un”, “happi”, “ness”
- K-hot label
- 어휘 사전에서 Sub word에 있으면 1, 없으면 0
-
Classification Head
-
Global average pooling
- 패치 단위로 추출한 특징 벡터를 average pooling
-
Linear layer
-
Logit vector
-
각 Subword에 대한 예측
-
Softmax로 변환하여 확률값 계산
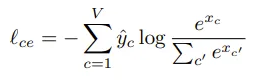
- Softmax > BCE, soft margin, ASL, two-way loss
-
데이터의 노이즈, 텍스트 데이터가 완벽하지 않은 한계
-
-
-
IDF
- 모든 서브워드가 동일한 영향력을 가지지 않음
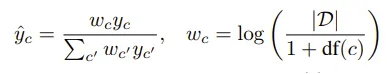
- 모든 서브워드가 동일한 영향력을 가지지 않음
-
Experiment
-
Set-Up
- datacomp dataset : 1.3B image-text
- Batch: 16k(Classification), 90k(CLIP)
- Backbone - frozen
-
주요 결과
-
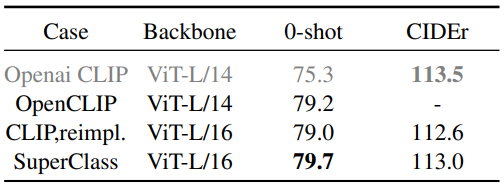
Pre-training 방법들과의 비교
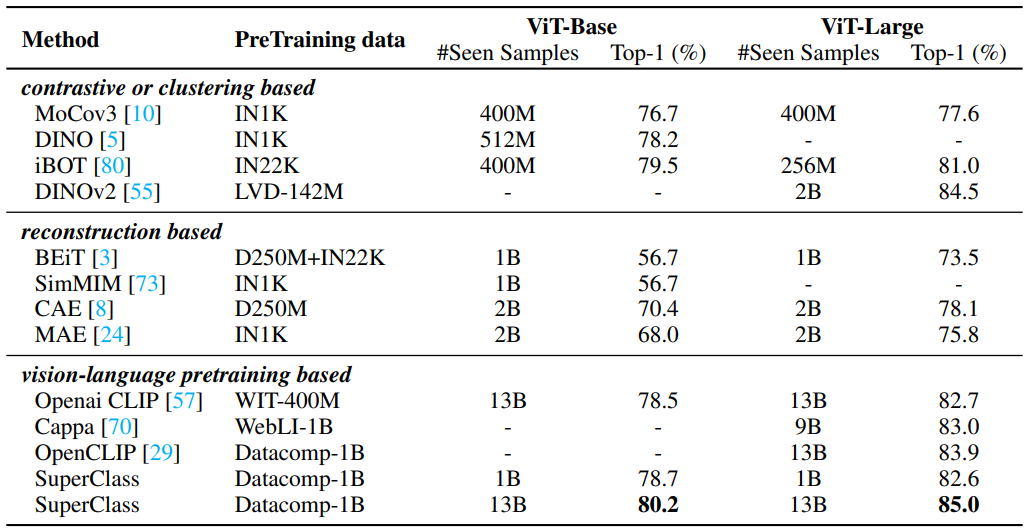
-
CLIP과 비교
-
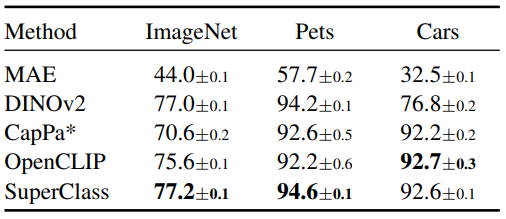
ViT-Base Backbone : SuperClass (80.2), CLIP (78.5)
-
ViT-Large Backbone : SuperClass (85.0), CLIP (82.7)
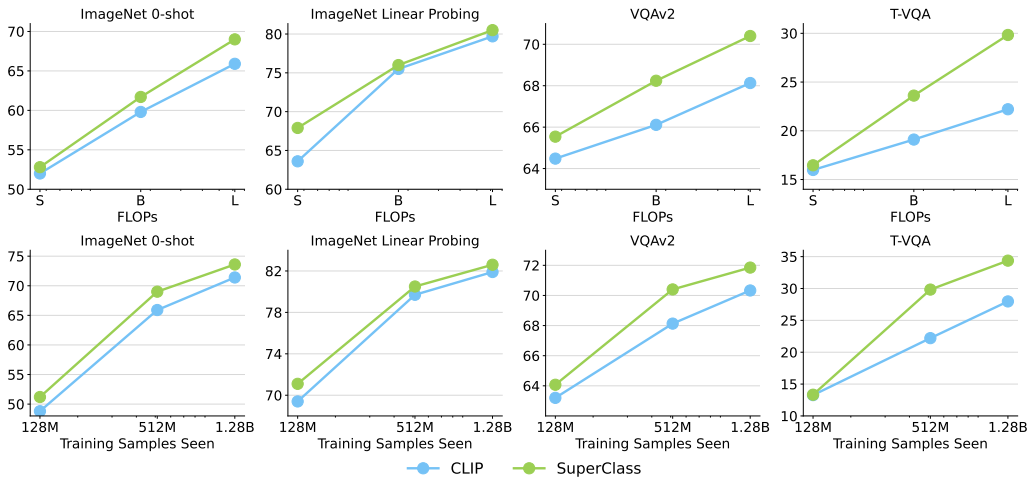
-
상단 : 모델 크기, 계산 비용 비교
-
하단 : 데이터 스케일 비교
-
-
Ablations
-
Word tokenizer VS Subword tokenizer
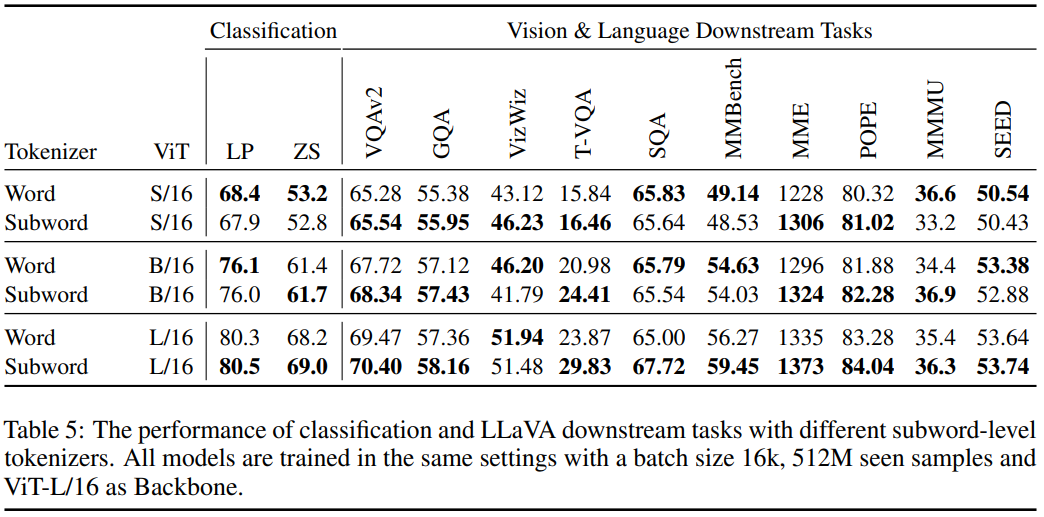
- 모델의 크기가 증가할수록 Subword가 좋다.
- Vision-Language task에서는 subword가 좋다.
-
Subword Tokenizer 비교
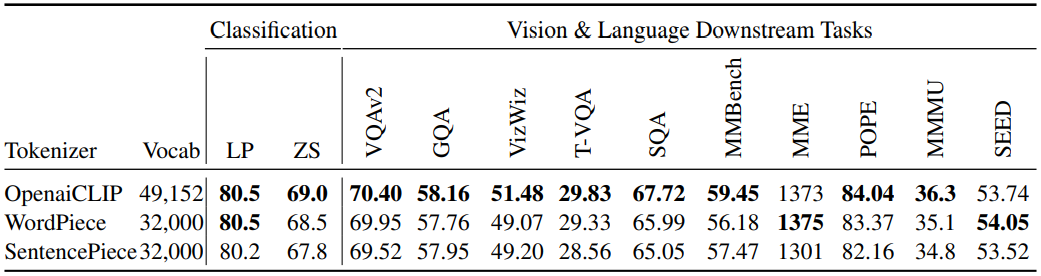
-
Loss

-
IDF & Stopwords
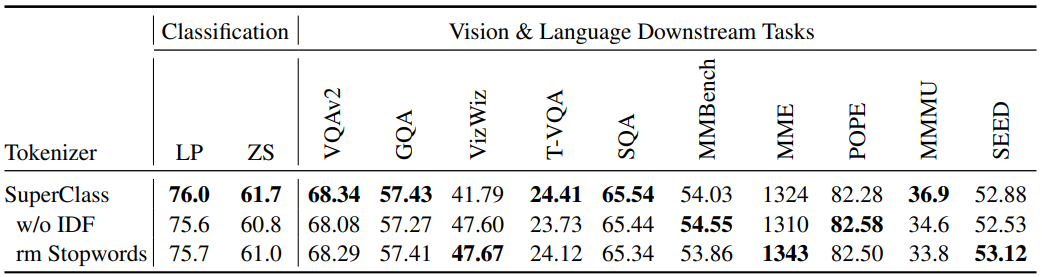
-
-
Limitation & Conclusion
- ‘Classification’을 목표로 pre train한 Vision encoder가 CLIP을 능가한다.
- 텍스트 인코더를 필요로 하지 않아 학습 효율이 높다.
- 단어의 순서와 객체간의 관계를 완전히 무시한다.
한국어 subword tokenizer?
→ Language model의 tokenizer 떼와서 사용하면 된다. Vocab 32k 정도면 충분.
ViT가 예측값을 내는 과정이 나와있지 않음
→ 코드 상에서 proj 으로 나와있음.
ViT가 추출한 전역 특징을 서브워드의 2차원 공간에 투영하나? 그럼 의미를 어떻게 유지하는가.
→ 차원은 vocab 크기. projection으로 많이 한다. CLIP, BERT등 평균적으로 512로 투영함.
